
Enterpreneur, database geek and lapsed researcher. Eng lead in Google Cloud databases for Cloud SQL, Bigtable, Firestore, and AI-driven assistive tech for dbs
Joined March 2009
- Tweets 12,974
- Following 4,954
- Followers 1,625
- Likes 314
179 Photos and videos



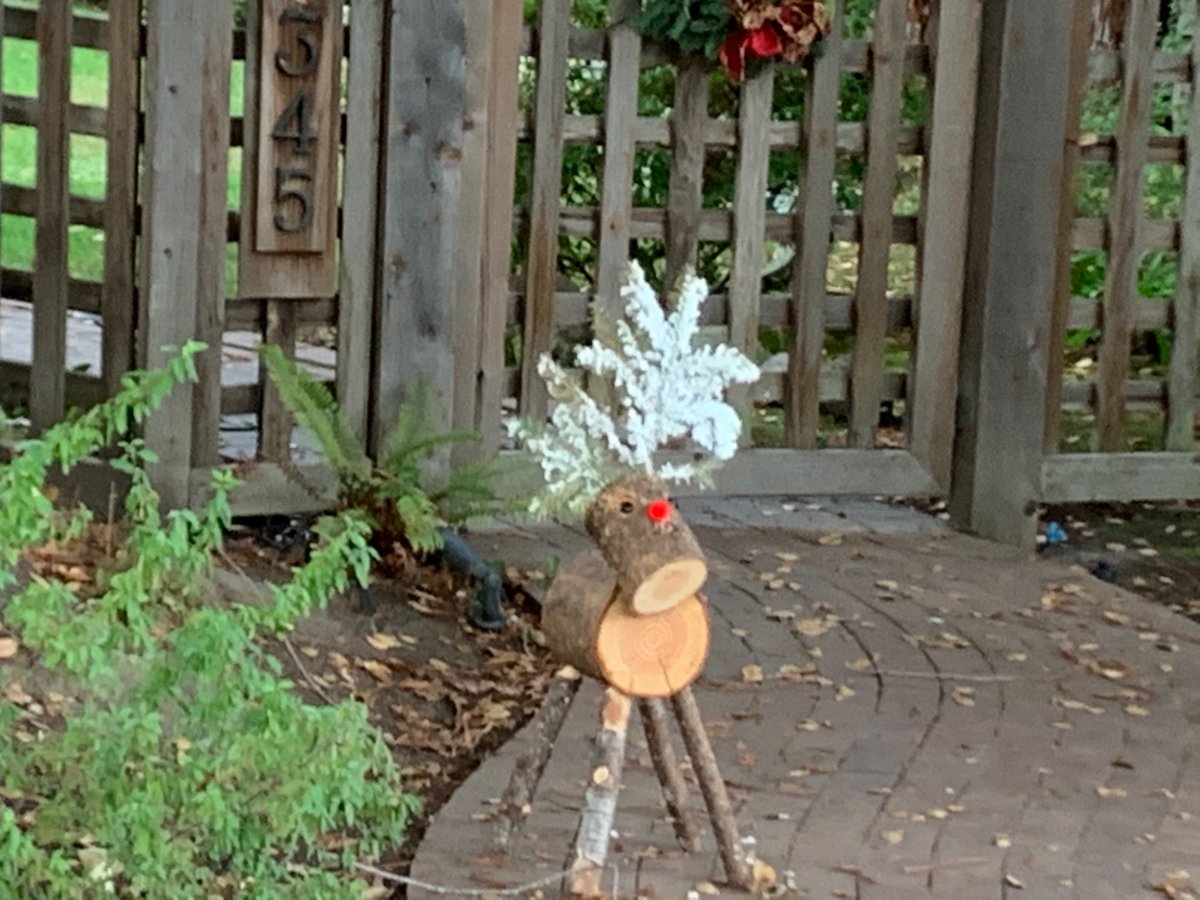








SaileshKrishnamurthy retweeted

Jun 12
🚀 Introducing Gemini-SQL2, our breakthrough text-to-SQL capability powered by Gemini 3.1 Pro! We've achieved state-of-the-art results on the highly competitive BIRD benchmark, translating natural language into execution-ready SQL queries. 🧵👇

129
619
6,667
658,358
SaileshKrishnamurthy retweeted

May 22
Thanks for all of the Antigravity feedback over the last couple of days, especially around the IDE. Our intention was never to remove the IDE support for developers, and we should have been clearer with that in the product from the beginning.
We’ve made it clearer in 2.0 on how to connect to the IDE, fixed issues with opening the IDE on Windows machines, provided instructions to restore IDE settings & extensions, and more.
New releases for the Antigravity IDE and Antigravity 2.0 have rolled out with these changes.
We should have done better so we’re going to reset everyone’s Gemini quota for the week again.
253
102
1,901
254,423
SaileshKrishnamurthy retweeted

Mar 19
167
751
5,809
8,472,164
SaileshKrishnamurthy retweeted

24 Dec 2025
Our version of holiday lights.
61
154
1,652
453,107
SaileshKrishnamurthy retweeted

25 Jul 2025
It was an incredible honor to host the legend @arrahman - a huge idol of mine - at @OpenAI today for a fireside chat and Q&A.
Beyond being an iconic composer, he is also a true innovator—constantly pushing boundaries, from creating the VR film Le Musk to building a metahuman digital band with Secret Mountain.
It was inspiring to hear his thoughts on how AI is reshaping creative expression, his recent projects at the intersection of technology and the arts, and his vision for the future of music and media. Really grateful for this unforgettable conversation!


14
49
1,063
60,565

Announcing The Stargate Project
The Stargate Project is a new company which intends to invest $500 billion over the next four years building new AI infrastructure for OpenAI in the United States. We will begin deploying $100 billion immediately. This infrastructure will secure American leadership in AI, create hundreds of thousands of American jobs, and generate massive economic benefit for the entire world. This project will not only support the re-industrialization of the United States but also provide a strategic capability to protect the national security of America and its allies.
The initial equity funders in Stargate are SoftBank, OpenAI, Oracle, and MGX. SoftBank and OpenAI are the lead partners for Stargate, with SoftBank having financial responsibility and OpenAI having operational responsibility. Masayoshi Son will be the chairman.
Arm, Microsoft, NVIDIA, Oracle, and OpenAI are the key initial technology partners. The buildout is currently underway, starting in Texas, and we are evaluating potential sites across the country for more campuses as we finalize definitive agreements.
As part of Stargate, Oracle, NVIDIA, and OpenAI will closely collaborate to build and operate this computing system. This builds on a deep collaboration between OpenAI and NVIDIA going back to 2016 and a newer partnership between OpenAI and Oracle.
This also builds on the existing OpenAI partnership with Microsoft. OpenAI will continue to increase its consumption of Azure as OpenAI continues its work with Microsoft with this additional compute to train leading models and deliver great products and services.
All of us look forward to continuing to build and develop AI—and in particular AGI—for the benefit of all of humanity. We believe that this new step is critical on the path, and will enable creative people to figure out how to use AI to elevate humanity.
5,383
10,314
59,055
33,923,606
SaileshKrishnamurthy retweeted

4 Nov 2024
THREAD: THE MOST AMAZING COMEBACK IN CRICKET
Cricket has seen many amazing comebacks, ranging from returns from injury and being sacked. But npthing beats a retired player being spotted in a crowd and being asked to play! It happened. July 25, 1i986. Lord's. #Repost

27
52
275
70,657
SaileshKrishnamurthy retweeted

4 Nov 2024
📢 I am recruiting PhD students for Fall 2025 @ Georgia Tech! If you are interested in topics related to DB AI (multimodal & vector databases, data management support for ML, etc.), apply and mention my name in your application: gradapp.gatech.edu/apply/

7
137
495
50,750
SaileshKrishnamurthy retweeted

4 Nov 2024
I'm not at SOSP but this is brilliant news! @AishwaryaGanlat, Ram Alagappan and their students, @LuoStuart, @shreesha00, and Jiyu Hu received a Best Paper Award @sospconf for their work --
"LazyLog: A New Shared Log Abstraction for Low-Latency Applications" !!
dassl-uiuc.github.io/pdfs/pa…
Congratulations! @IllinoisCDS


6
21
173
15,540
SaileshKrishnamurthy retweeted

31 Oct 2024
AI-enabled biology is at an inflection point, with the potential for exponential acceleration over the next decade. I'm excited to join the world class team of scientists and engineers at Arc Institute to advance the frontiers of science!
31 Oct 2024

We are thrilled @davey_burke is joining us as Chief Technology Officer to lead engineering at Arc as we forge ahead at the interface of biology and AI to build a computational model of the cell. Dave most recently led @Android engineering as VP Engineering at @Google.

21
29
339
90,563
SaileshKrishnamurthy retweeted

24 Oct 2024
How I woke up one day and decided to solve a math conjecture from the 1970s ⤵️

33
245
2,736
592,367
SaileshKrishnamurthy retweeted

18 Oct 2024
Simplifying the AI noise by segmenting everything into 3 big use cases: Gods, Interns, and Cogs. dbreunig.com/2024/10/18/the-…
9
31
184
117,078
SaileshKrishnamurthy retweeted

19 Oct 2024
SOSP'24 is upon us! This means you should sign up as a mentor or a mentee (PhD students)! Come help make Systems a friendly and welcoming place for everyone.
Mentors: tinyurl.com/sosp2024mentors.
Mentees: tinyurl.com/sosp2024mentees
1
13
38
5,273
SaileshKrishnamurthy retweeted

11 Oct 2024
Yesterday's joint oversight hearing by the Assembly Education and Higher Education committees had a lopsided set of invitees, and was political theater designed to blame and shame the University of California for upholding the official state-adopted standards for math education, with an agenda filled with inaccuracies and flat out lies. Details of the agenda weren't even posted until 1-2 hours before the actual hearing, seemingly to keep the public from knowing and participating.
Fortunately, the ploy failed. @UofCalifornia leadership came with good answers, and Prof. Brian Conrad of Stanford and myself found out about the hearing and helped changed the tone during public comment.
@AsmMuratsuchi then said exactly the right thing in his closing remarks afterward, visibly deeply contemplative after the public comment he had just heard: "I do want to acknowledge the importance of making sure that we are meeting necessary standards of academic rigor, and that we're not just establishing courses just for the sake of graduating students". 👏🏾👏🏾
Correct!
Thank you Committee Chair Muratsuchi for those important words.
Full hearing: youtu.be/D81SW2EKlOk?si=qrZo…
UC official testimony: youtu.be/D81SW2EKlOk?si=MdKl…
My public comment: youtu.be/D81SW2EKlOk?si=rs5Z… (the printed packet I referenced is uploaded here: drive.google.com/file/d/18jk…)
Brian Conrad's public comment: youtu.be/D81SW2EKlOk?si=B_Me…
Assemblymember Muratsuchi's closing remarks: youtu.be/D81SW2EKlOk?si=oYdY…
2
14
56
7,454
SaileshKrishnamurthy retweeted

3 Oct 2024
The multimodal rocket … 🚀
- Lens has grown to nearly 20B visual searches monthly
- Multisearch has grown 3X in the last 9 months
- Lens queries are one of the fastest growing query types on Search…
- And now you can search w/ pics voice or video voice!
6
5
35
3,735
SaileshKrishnamurthy retweeted

2 Oct 2024
There's three parts.
1. Fitting as large of a network and as large of a batch-size as possible onto the 10k/100k/1m H100s -- parallelizing and using memory-saving tricks.
2. Communicating state between these GPUs as quickly as possible
3. Recovering from failures (hardware, software, etc.) as quickly as possible
1. Fitting as large of a network and as large of a batch-size as possible onto the 10k H100s.
Parallelizing:
1. parallelize over batches
2. parallelize over layers (i.e. split a layer across GPUs)
3. parallelize across layers (i.e. 1 to N are on GPU1, N 1th layer to N 10th layer are on GPU2)
Keep parallelizing until you are able to use all GPUs well, with maximum utilization.
Checkpointing / Compute vs memorize:
* You need to save certain terms from forward to compute the backprop (save_for_backward). However, if the network is sufficiently large, it is more profitable to free these terms in order to fit a larger batch-size, and recompute them again when you need them to compute the backprop.
* Tricks like FSDP discard parts of weights that are held in one GPU (to save memory), and ask for the shards of weights from other GPUs right before they need them.
2. Communicating state between these GPUs as quickly as possible
Communication overlap:
When you need to communicate among GPUs, try to start communication as soon as you can:
* Exampel: when Nth layer is done with backward, while N-1th layer is computing backward, all GPUs with an Nth layer can all-reduce their gradients)
Discover and leverage the underlying networking topology:
Communicating large amounts of state (gradients, optimizer state) across multiple nodes is complicated. with Sync SGD, you have to communicate this state in a burst, as quickly as you can.
we might have multiple layers of switches, and have RDMA (ability to copy GPU memory directly to NIC, bypassing CPU ram entirely), and have frontend and backend NICs (frontend connects to storage like NFS, backend connects GPUs to other GPUs in cluster).
So, it's important to leverage all this info when running communication collectives like all-reduce or scatter/gather. All-reduce for example can be done algorithmically in log(n) if you tree-reduce; and the constant factors that change based on the type of fiber connecting one node to another in the tree of networking fiber is important to reduce overall time and latency.
Libraries like NCCL do sophisticated discovery of the underlying networking topology and leverage them when we run all-reduce and other collectives.
3. Recovering from failures (hardware, software, etc.) as quickly as possible
At 10k GPU scale, things fail all the time -- GPUs, NICs, cables, etc. Some of these failures are easy to detect quickly, some of them you can only detect because one node isn't replying back in time (say a NCCL all-reduce is stuck). We build various tools to monitor and detect fleet health, and remove failed nodes from the fleet as quickly as possible. This is quite hard.
Separately, at this large of a scale you can have silent data corruptions from memory bits flipping randomly (due to basic physics and amplifying the probability at this scale), and you suddenly have loss-explosions for no reason other than this random phenomenon. These happen at small-scale too, but very very infrequently so you barely notice. This is very hard to detect before-hand in software. Some hardware has hardware circuitry that does built-in checksums after it computes things -- this way if bit-flips occur the hardware can throw an interrupt. H100s and previous NVIDIA GPUs don't have this feature.
To counter all these failures, you would want to save your model state as frequently and as quickly as you can; and when a failure occurs, you want to recover and continue as quickly as you can. Usually, we save model state really quickly to CPU memory in a separate thread and in the background we save from CPU memory to disk or remote storage.
We also save model state in shards (this is torch.distributed's checkpointing feature), i.e. not every GPU needs to save all of the model weights; each GPU only needs to save a portion of weights -- and they can recover the other part of weights from other GPU shard checkpoints.
25
167
1,305
241,707

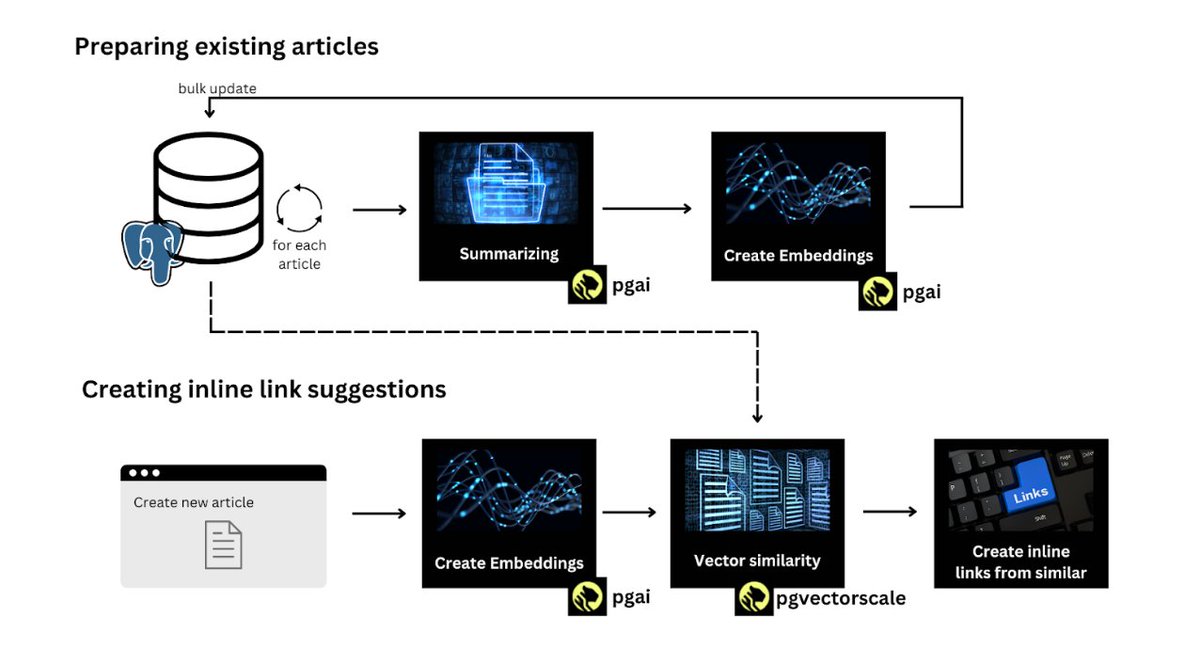
Here's how @techscienceandy built a content recommendation system using just PostgreSQL
"This was the major eureka moment for our company: having modern LLMs available right from our database. No dependency management, no infrastructure, no additional costs.
We do not require any additional infrastructure. We only need PostgreSQL with pgai, pgvector, and pgvectorscale."
👇Full article (and sample code) in next tweet.
2
17
85
8,155
SaileshKrishnamurthy retweeted

2 Oct 2024
The stupidity of the Jones Act incentivizes companies to do insane things

62
404
3,677
264,627
SaileshKrishnamurthy retweeted

30 Sep 2024
We’re blowing through qps right now on a Monday and I have to ask
…are yall listening to Deep Dive at work??
35
6
239
31,958