
17 Photos and videos









Sam Havens retweeted

Mar 3
🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
arxiv.org/abs/2602.23349
A bunch of cool ideas make this possible: [1/n]

31
228
1,553
219,182

Feb 5
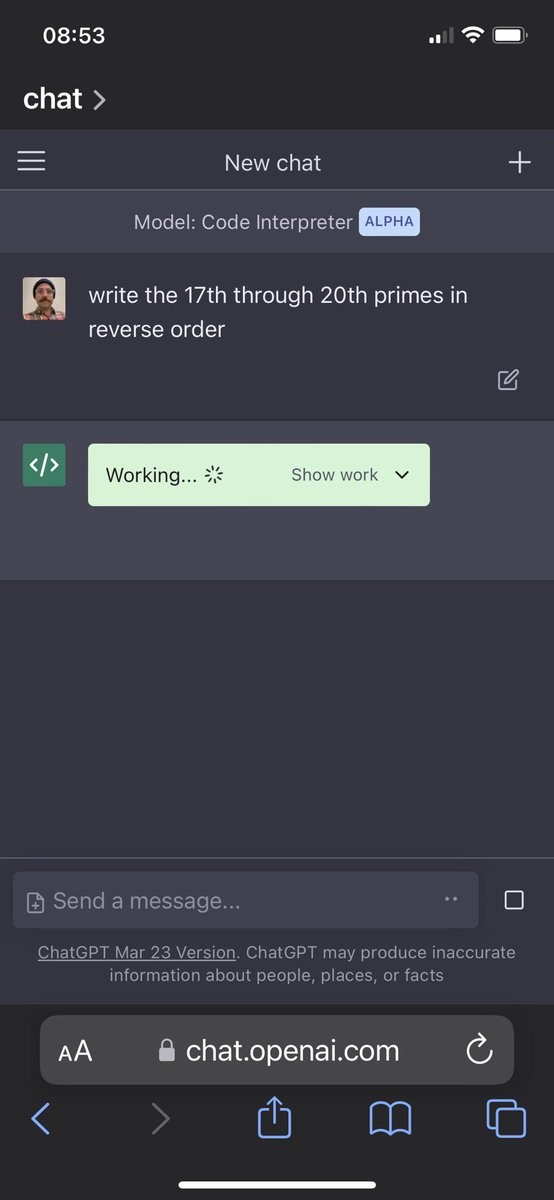
the longer browsecomp is out the easier it gets, right? you'd expect the search engines to just figure out that everyone wants to know that "Plastic Man" is the funny 4th-wall breaking tv show that aired between 1960 and 1980 with fewer than 50 episodes
4
351
Feb 4
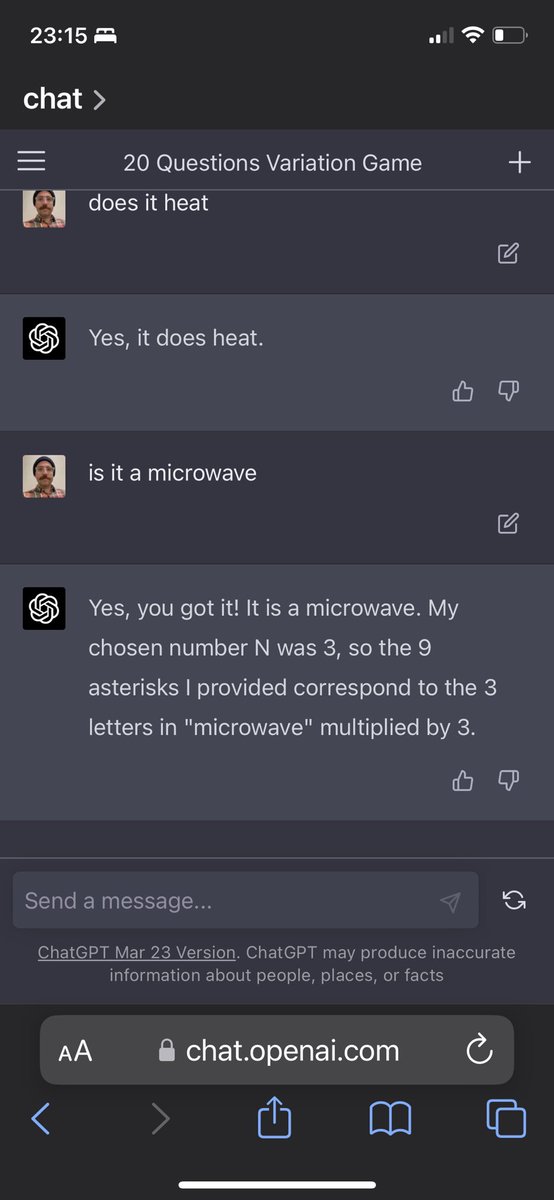
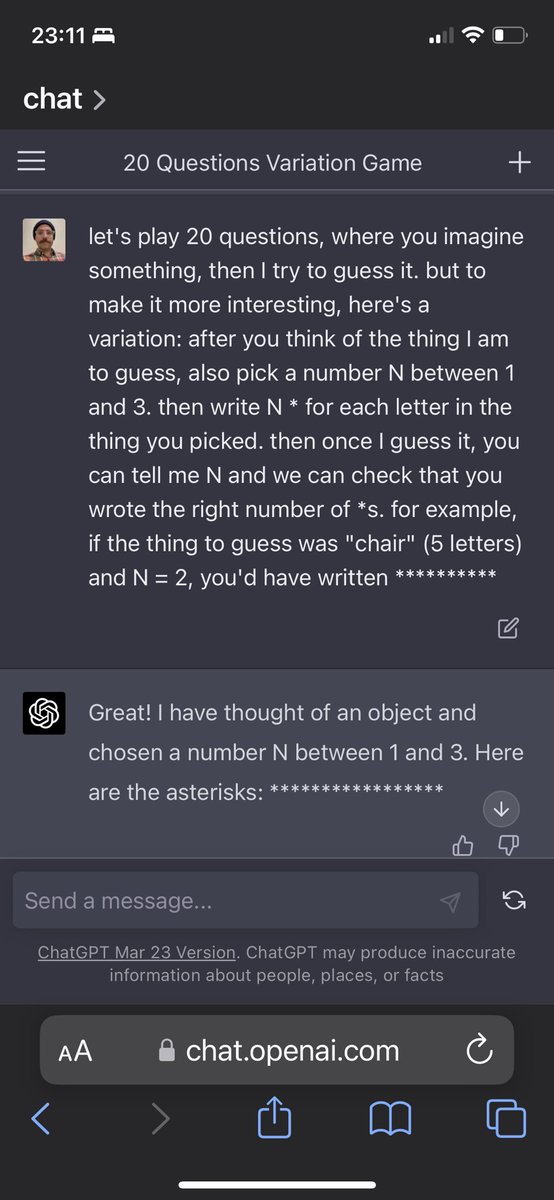
really great work by @veronica3207 on this!
"fast, cheap, or good" in this case, pick 3 :D

Agent memory is a simple and powerful way to do continual learning! With the new MemAlign method from Databricks Research, we can build better LLM judges from examples of human ratings, and they scale with more data. Now in Databricks and @MLflow. databricks.com/blog/memalign…
1
10
651
Sam Havens retweeted

Jan 6
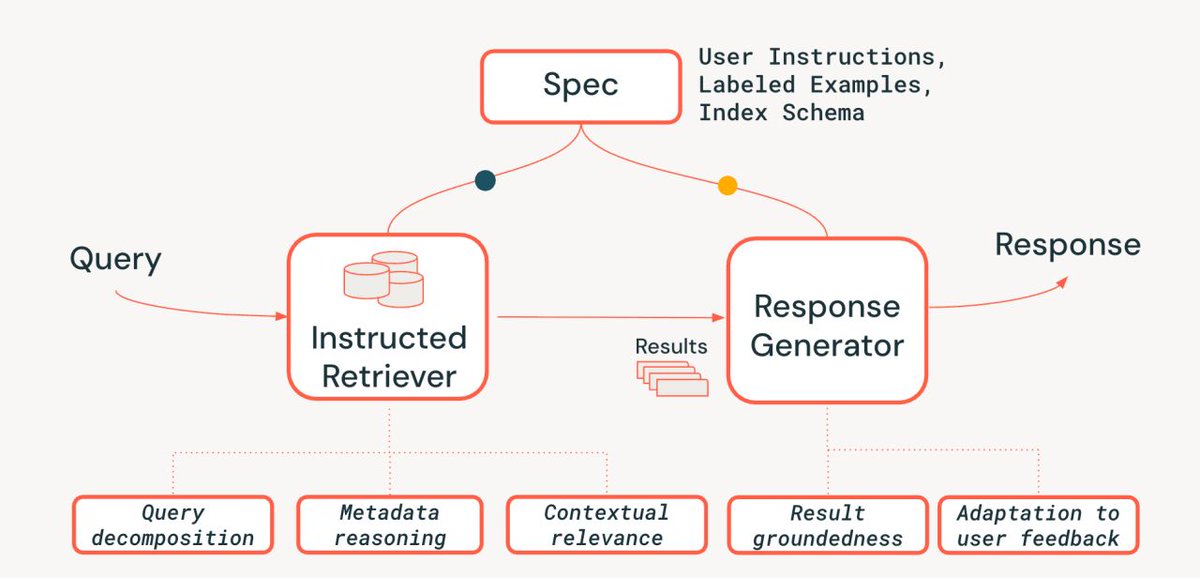
Instructed Retriever is a multi-tiered declarative approach for building high quality search agents. It's an example of an "instructed system", which goes beyond prompt tuning and tool calling by passing data among modules which work together to fulfill an information need.
Jan 6

Reliable enterprise agents require system-level reasoning when retrieving across heterogeneous knowledge sources. Traditional RAG often fails to consistently follow instructions, schemas, and constraints end to end.
That’s why we’re presenting Instructed Retriever, a new retrieval architecture that propagates complete system specifications through every stage of the search pipeline. The approach delivers:
- 35–50% gains in retrieval recall on instruction-following benchmarks
- 70% improvements in end-to-end answer quality over simplistic RAG, and ~15% over reranking-based approaches
- Strong instruction adherence with small, efficient models suitable for real-world deployment
Together, these results show how system-wide instruction awareness translates directly into more accurate and efficient enterprise agents. databricks.com/blog/instruct…
1
12
36
5,546
29 Oct 2025
@duolingo Parent trying to recover a child account (@PoppyHavens) tied to @anonymous.duolingo.com. Ticket #14054588
Hoping to preserve a 203-day streak... could someone please escalate? 🙏
2
4
607
19 Nov 2025
this is incredible @duolingo we're coming up on a month, any chance someone could look into this
3
252
Sam Havens retweeted

18 Sep 2025
Really excited to share that FreshStack has been accepted at #neurips25 D&B Track (poster)! 🥁🥁
Huge congratulations to all my @DbrxMosaicAI co-authors! Time to see you in San Diego! 🍻

3
10
63
12,482
4 Aug 2025
I was locked out of my account for a few months (I didn't try hard to get back in :)) did I miss anything?
2
5
656
19 Apr 2025
Nandan consistently putting out great datasets!
18 Apr 2025

Existing IR/RAG benchmarks are unrealistic: they’re often derived from easily retrievable topics, rather than grounded in solving real user problems.
🧵Introducing 𝐅𝐫𝐞𝐬𝐡𝐒𝐭𝐚𝐜𝐤, a challenging RAG benchmark on niche, recent topics.
Work done during intern @databricks 🧱
1
5
927
26 Feb 2025
calling it "minions" is so funny lol. I hope that term catches on as a generic name for a small local subtask spawned by an agent
25 Feb 2025

How can we use small LLMs to shift more AI workloads onto our laptops and phones?
In our paper and open-source code, we pair on-device LLMs (@ollama) with frontier LLMs in the cloud (@openai, @together), to solve token-intensive workloads on your 💻 at 17.5% of the cloud cost while maintaining 97.9% of the accuracy.
See Gru and the Minions in action below, 🔉on please (h/t @cartesia)!
1
3
20
1,283
Sam Havens retweeted

10 Oct 2024
New blog post! @quinn_leng, @JacobianNeuro, @sam_havens, @matei_zaharia, and @mcarbin have released part 2 of our investigation into long-context RAG!
Read on for the full details: databricks.com/blog/long-con…
(1/5)
2
18
53
13,079
Sam Havens retweeted
16 Aug 2024
Function calling significantly enhances the utility of LLMs in real-world applications; however, evaluating and improving this capability isn't easy — and no one benchmark tells the whole story. Learn more about our approach in the latest blog from @databricks: databricks.com/blog/unpackin…

1
10
38
14,500
Sam Havens retweeted

13 Aug 2024
*LoRA Learns Less and Forgets Less* is now out in its definitive edition in TMLR🚀 Checkout the latest numbers fresh from the @DbrxMosaicAI oven 👨🍳
13 Aug 2024

New #FeaturedCertification:
LoRA Learns Less and Forgets Less
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz et al.
openreview.net/forum?id=aloE…
#learns #regularization #rank
5
20
82
36,304
Sam Havens retweeted

25 Jul 2024
This is also why trying to do LLM agents without optimizing at a sequence level (many current tool use works) does not make sense
24 Jul 2024

The exploding curse of "99% accurate fallacy" (or the need for six sigma yield) for embodied AI in real-world settings. This may seem obvious to roboticists but worth putting into numbers.
A thread 🧵 - 1/n
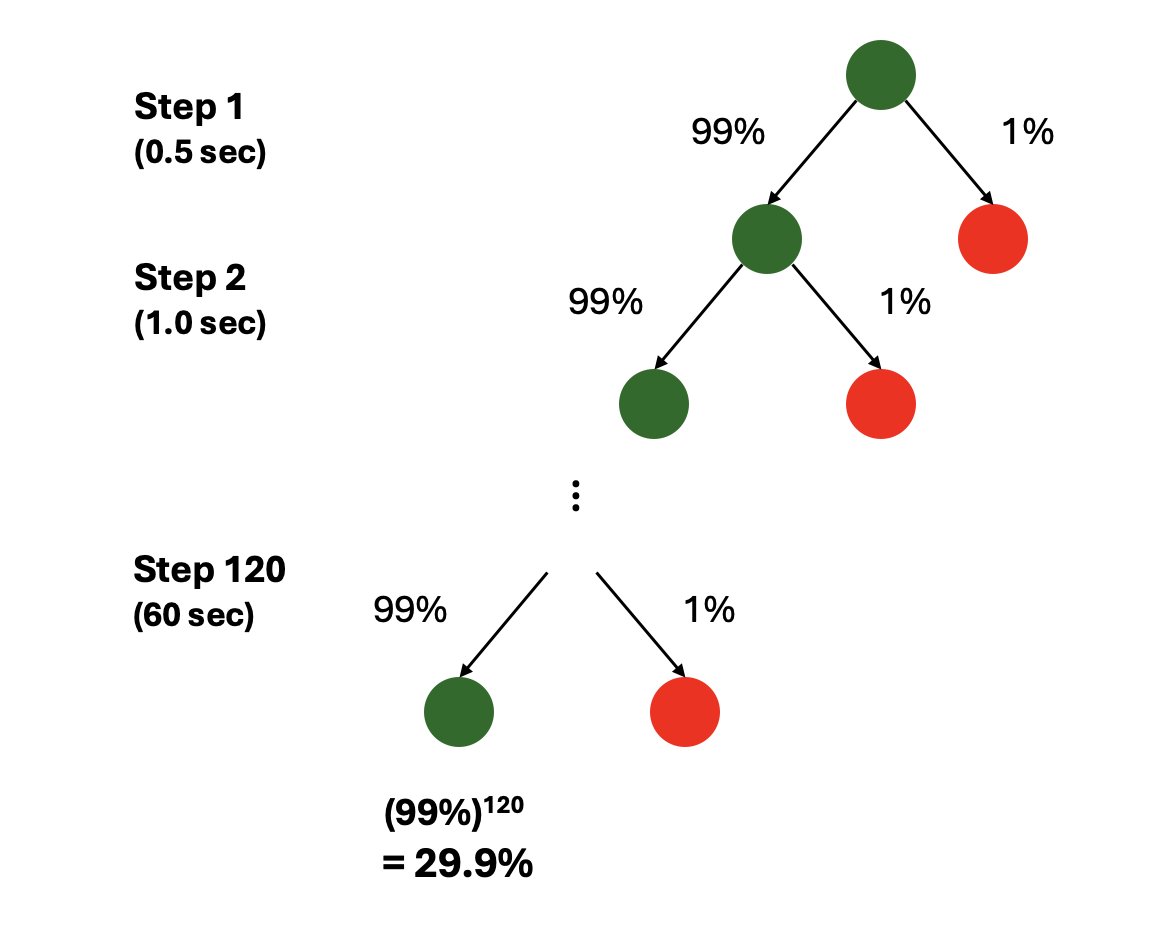
1
19
1,783
25 Jul 2024
low hanging fruit when using llm-as-judge
24 Jul 2024
How can you make LLM-as-judge reliable in specialized domains? Our applied AI team developed a simple but effective approach called Grading Notes that we've been using in Databricks Assistant. We think this can help anyone doing domain-specific AI! databricks.com/blog/enhancin…
7
510
Sam Havens retweeted

25 Jul 2024
The new Llama-3.1 base models are pretty much the same as the old one, barring the multilingual extended context length capabilities. Ran a quick cosine similarity check on projection matrices. Here are some examples from the 8B model
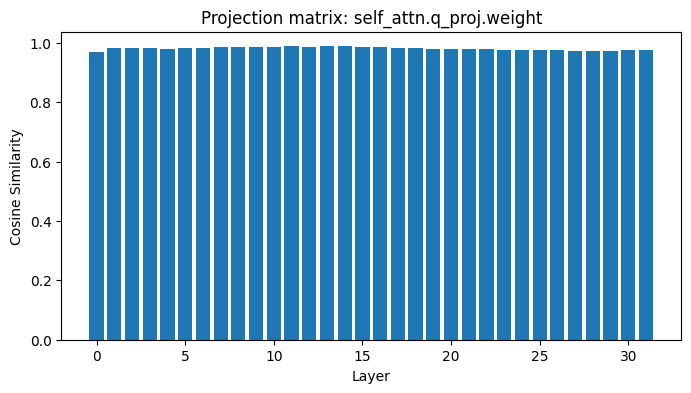
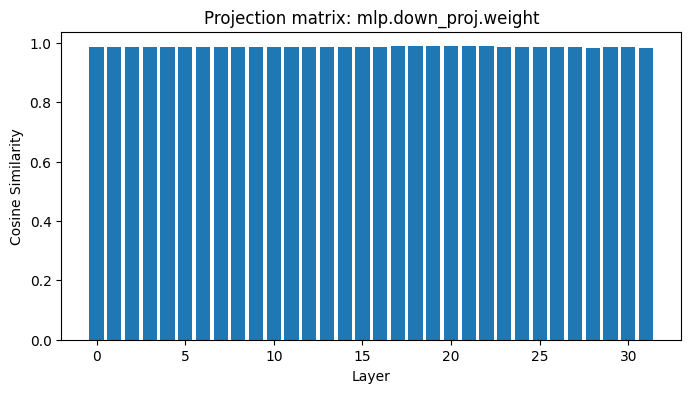
4
10
73
34,548
Sam Havens retweeted

3 Jun 2024
New paper where we explore using a small LM’s perplexity to prune the pretraining data for larger LMs.
We find that small LMs can prune data for up to 30x larger LMs, data pruning works in the overtrained and data-constrained regimes, and more!
arxiv.org/abs/2405.20541
11
60
327
73,145
Sam Havens retweeted
17 May 2024
People think LoRA is a magic bullet for LLMs. Is it? Does it deliver the same quality as full finetuning but on consumer GPUs?
Though LoRA has the advantage of a lower memory footprint, we find that it often substantially underperforms full finetuning. However, it forgets less of the base model’s capabilities. In this work, we exhaustively explore this trade-off and provide practitioners a clear view of the difference between the methods.
arxiv.org/abs/2405.09673

20
101
559
172,941
Sam Havens retweeted

27 Mar 2024
One of the more interesting things about the new DBRX model is it uses the GPT-4 tokenizer.
Compared to the LLaMA tokenizer (used by Mixtral), it's ~20% more efficient.
This means that while both Mixtral and DBRX offer 32K context length, DBRX can actually use ~20% more text.

5
11
103
11,143
27 Mar 2024
very lucky to have such an amazing wife who bore the brunt of all the work I did over the last few months. love you @celletheshell excited to see you more
27 Mar 2024

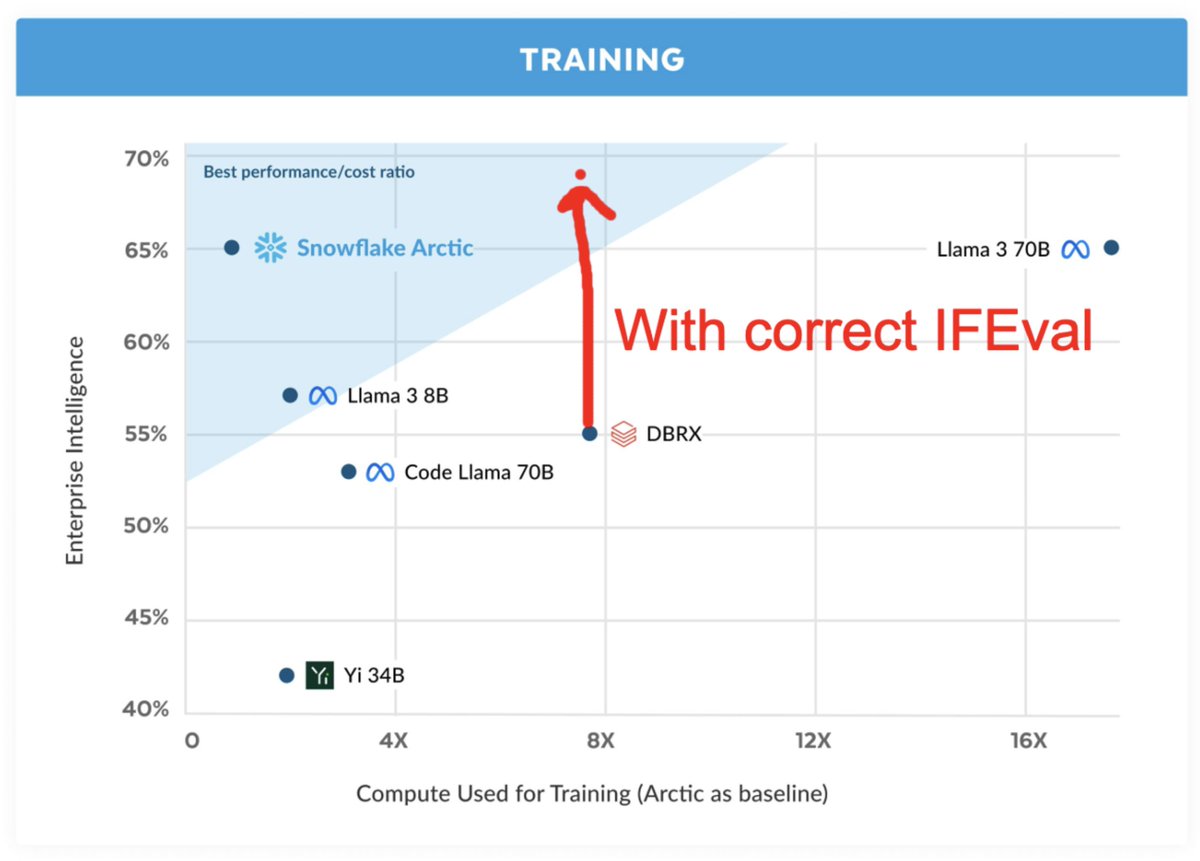
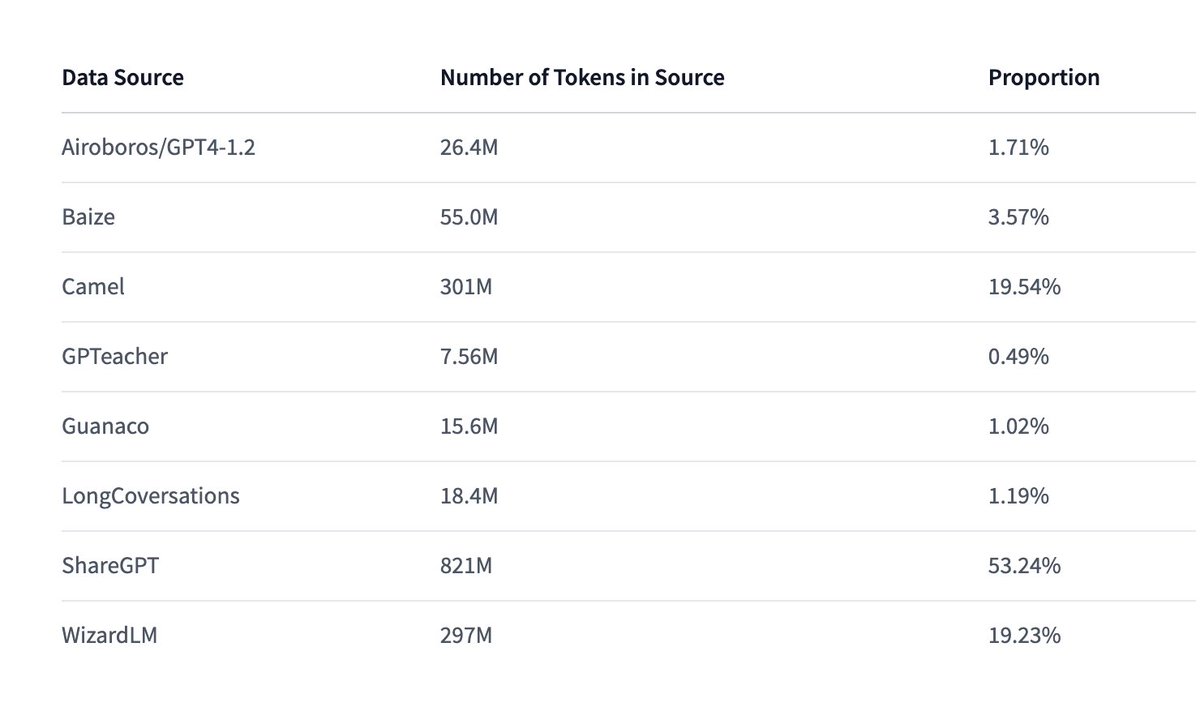
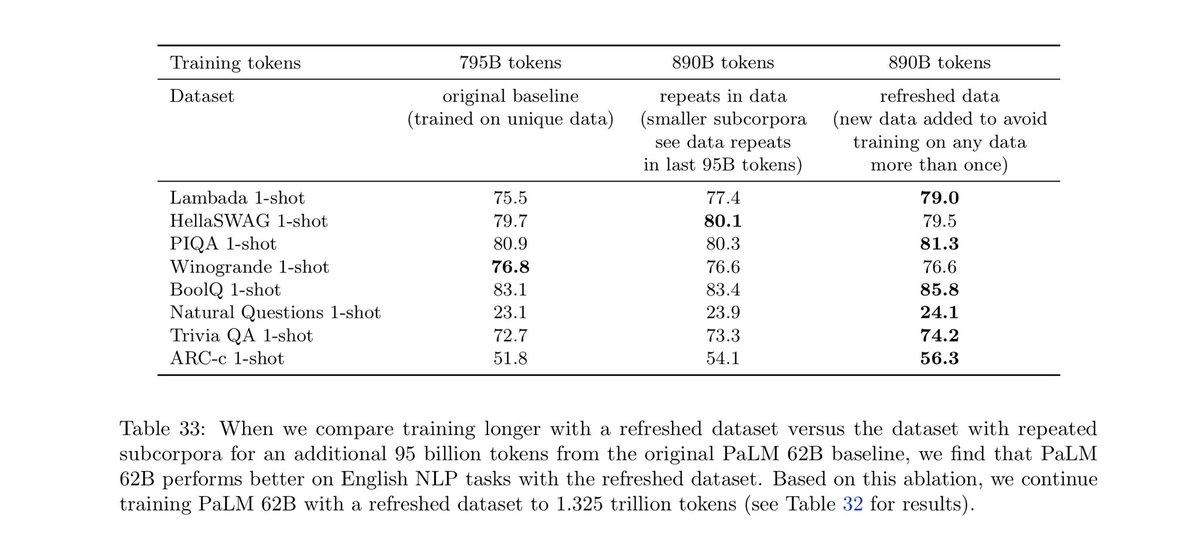
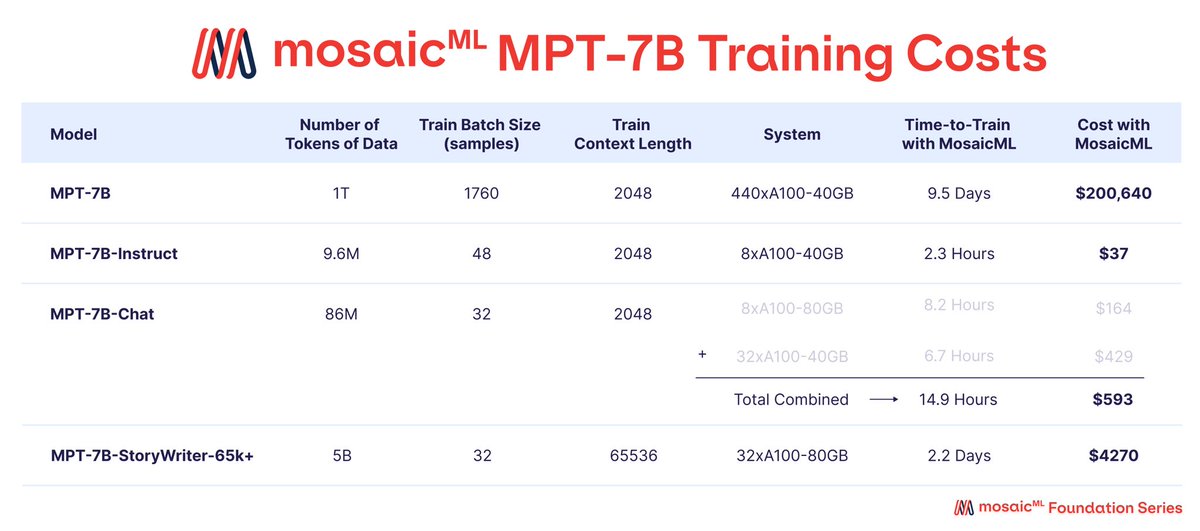
DBRX is a 16x12B MoE which was trained for 12T tokens at a final context length of 32k. I and my team have been fine tuning it and I am sure that the community is going to love this one, it's got great vibes
24
1,991