
Building end to end machine learning products.
Joined June 2012
- Tweets 1,507
- Following 1,245
- Followers 197
- Likes 22,354
288 Photos and videos














Sambit Sekhar retweeted

16 Aug 2025
Thanks to @silogenai (@AMDSiloAI) & Aku Rouhe for releasing Qwen1.5 7B Odia Instruct — advancing LLMs for the Odia language!
Trained on Odia data fine-tuned with 5 Odia instruct sets released by @OdiaGenAI & 1 English set.
👉 Model: huggingface.co/silogen/Qwen1…
3
8
234
Sambit Sekhar retweeted

29 May 2025
🧠 GenAI Quiz: Test Your Knowledge & Win!
📅 Date: 3rd–5th July 2025
📍 Location: Bhubaneswar, India (Hybrid Mode)
🌐odiagenai.org/workshop-2025
🚀 Get ready to challenge your brain and showcase your expertise at the GenAI Quiz, part of the Three-Day GenAI Workshop

3
5
231
Sambit Sekhar retweeted
29 May 2025
💻 GenAI Hackathon: Build the Future with Generative AI!
📅 Date: 3rd–5th July 2025
📍 Location: Bhubaneswar, Odisha, India (Hybrid Mode)
🌐 Workshop Page: odiagenai.org/workshop-2025
📝 Register here: (to be announced)

2
7
184
Sambit Sekhar retweeted
29 May 2025
🚀 GenAI Pitch Session: Share Your Big Idea in 5 Minutes!
📅 Date: 3rd–5th July 2025
📍 Location: Bhubaneswar, Odisha, India (Hybrid Mode)
🌐 Workshop Page: odiagenai.org/workshop-2025
📝 Register here: forms.gle/CrMMNqReJg5o5jmE7

3
5
154
Sambit Sekhar retweeted
23 May 2025
We are excited to unveil the speaker lineup for the upcoming three-day Generative AI Workshop, jointly organized by @OdiaGenAI , AHRC @iitbbs , and the SCA, KIIT - @KIITUniversity
Workshop page: odiagenai.org/workshop-2025
Registration:forms.gle/bpt78iiVKe1BV3j18

2
7
149
Sambit Sekhar retweeted
18 May 2025
We are delighted to announce that Prof. Amit Sheth will be the keynote speaker at the upcoming three-day Generative AI Workshop, jointly organized by @OdiaGenAI, the AI & HPC Research Center (AHRC) at @iitbbs , and the School of Computer Application at @KIITUniversity.

2
5
118
Sambit Sekhar retweeted
24 Jan 2025
🌟 Glad to share our @indo_nlp workshop #coling2025 paper: OVQA: A Dataset for Visual Question Answering and Multimodal Research in Odia Language
📄 Paper: coling-2025-proceedings.s3.u…
🤖 HF Dataset:huggingface.co/datasets/odia…
🎉 Congratulations to all the authors!
@sambit_ai
2
3
208
Sambit Sekhar retweeted
17 Jan 2025
Excited to share that our open-source initiative @OdiaGenAI by our team @sambit_ai @swateekj @soumendrak_ @Babunisatya has been featured by @timesofindia & @timestechies! 🎉
Check out the article: timesofindia.indiatimes.com/…
Thank you, @timestechies, for the coverage!

1
6
11
291
Sambit Sekhar retweeted
20 Dec 2024
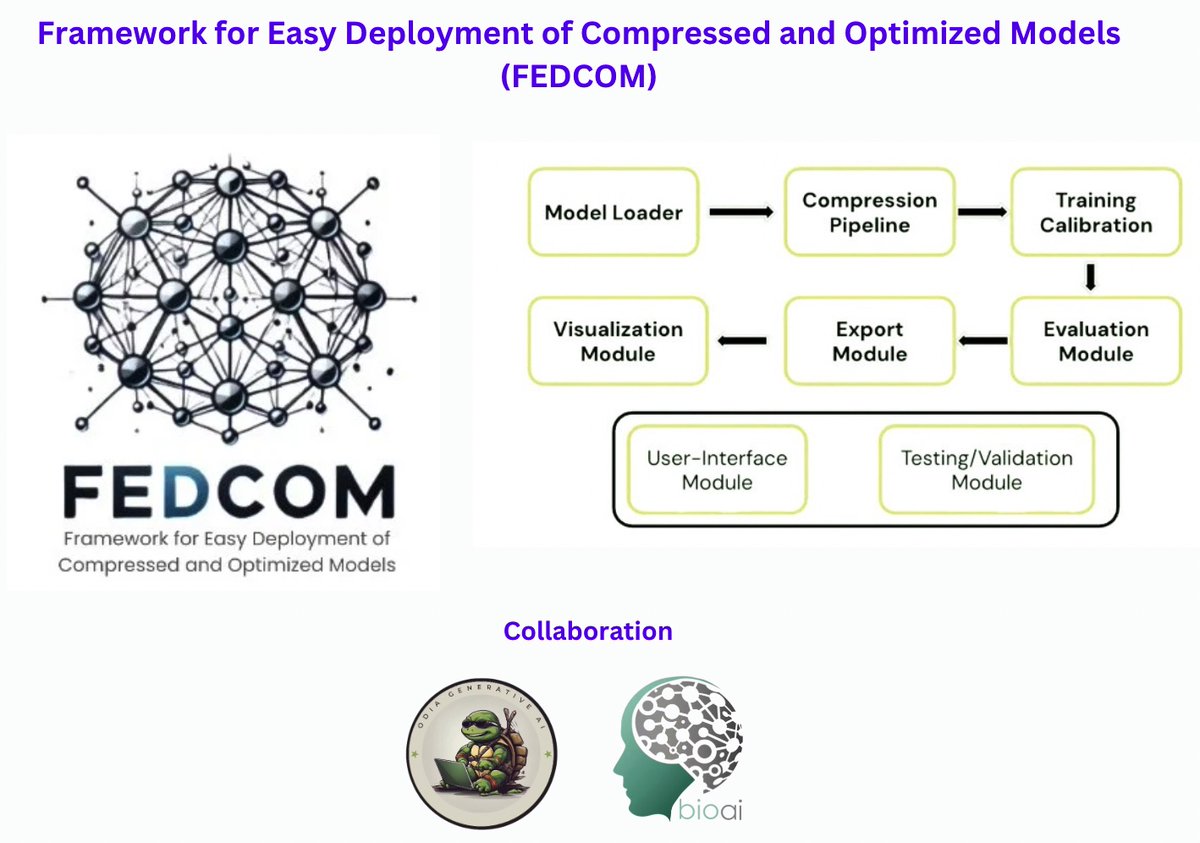
We're excited to share our innovative project addressing the critical challenge of deploying deep learning models in resource-constrained environments. 🌟
For more details, check the project page: odiagenai.org/fedcom
2
3
186
Sambit Sekhar retweeted
17 Dec 2024
We are delighted to welcome our new researchers to the OdiaTreeBank Project – Odia Bhasa Bruksha (ଓଡିଆ ଭାଷା ବୃକ୍ଷ)
✨ Sourav Kumar Behera
✨ Srustiprava Satapathy
✨ Nirmal Naik
✨ Shashikanta Sahoo
Website: odiagenai.org/odiatreebank

1
1
7
222
Sambit Sekhar retweeted
26 Jun 2024
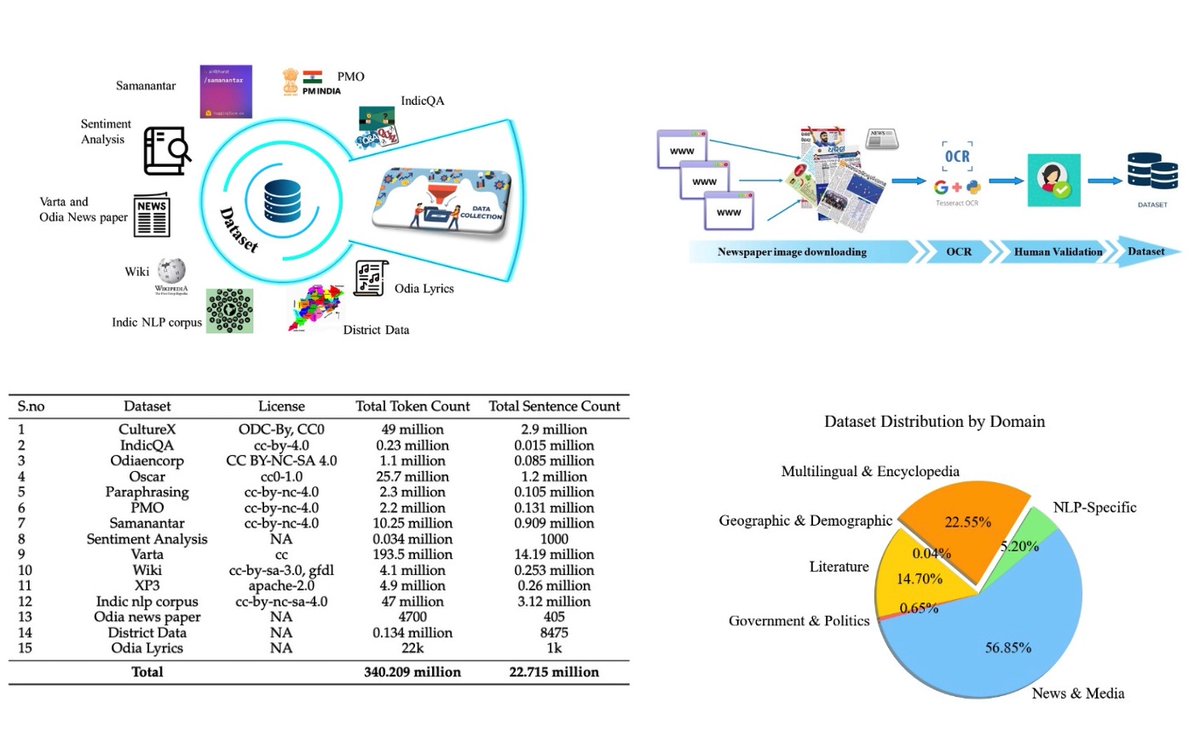
To address the lack of the Indic LLM dataset for pre-training, we have released a 300 million Odia tokens dataset for LLM pre-training.
For more details, check out our blog post:
📄 Blog: odiagenai.org/blog/odiagenai…
🔗 HF Link: huggingface.co/datasets/Odia…
2
9
432
Sambit Sekhar retweeted
22 Jun 2024
We had an outstanding quarter! From organizing an international workshop to launching a unique benchmarking project, all while keeping up with our regular deliveries—our mills are always running.
Read our second newsletter for details: odiagenai.substack.com/p/new…

3
3
203
Sambit Sekhar retweeted

31 May 2024
Had a great time talking at the inaugural ceremony of @OdiaGenAI 3 day workshop hosted with support by @KIITUniversity 🔥.
Thank you @achyuta_samanta @Saranjit72 @Shantipriyapar3 @Babunisatya Sir.
Some great talks are lined up and here is the schedule
odiagenai.org/workshop-2024
Also check out the cool works from the odia gen ai website
odiagenai.org/
2
3
27
3,087
Sambit Sekhar retweeted
28 May 2024
We're excited to announce a poster session at our upcoming Generative AI workshop, focusing on Indic languages
Researchers in this field are invited to showcase their work and compete for the Best Poster award!
For more details, visit our workshop page: odiagenai.org/workshop-2024

2
2
208
Sambit Sekhar retweeted
27 May 2024
Registration is in full swing for our Generative AI workshop!
Join us for an exciting series of events over three days.
Link: odiagenai.org/workshop-2024
@Shantipriyapar3 @sambit_ai @KIITUniversity @soumendrak_ @odias_in_ai @guneetsk99 @ak_panda
3
5
826
Sambit Sekhar retweeted
26 Mar 2024
In the new series of Small Language Models (SLM) for Indic languages, @OdiaGenAI released Hindi-Gemma-2B-instruct, a 2Billion SFT with 187k large instruction sets in Hindi.
Model: huggingface.co/OdiaGenAI-LLM…
Dataset: huggingface.co/datasets/gune…
Blog: odiagenai.org/blog/odiagenai…

1
1
211
Sambit Sekhar retweeted
19 Mar 2024
Our Bangalore-based volunteers - @swateekj & @soumendrak_ , organized a small meet & greet with one of our fellow researchers @guneetsk99, who was visiting Bangalore for a while.
We hope to be regular in doing meetups, across cities in India & outside.
Join us in the next one!

3
10
408
Sambit Sekhar retweeted
19 Mar 2024
One step forward, we upgraded our RAG-based AI Tutor Acharya developed by the amazing @OdiaGenAI team for self-learning subjects in Hindi.
Based on our fine-tuned Mistral-7b Hindi LLM.
@Shantipriyapar3 @sambit_ai @soumendrak_ @guneetsk99
youtube.com/watch?v=IlgcKK9X…

1
3
6
538
Sambit Sekhar retweeted

6 Mar 2024
🔥 𝐑𝐞𝐥𝐞𝐚𝐬𝐢𝐧𝐠 𝐈𝐧𝐝𝐢𝐜 𝐆𝐞𝐦𝐦𝐚 7𝐁/2𝐁 𝐈𝐧𝐬𝐭𝐫𝐮𝐜𝐭𝐢𝐨𝐧 𝐭𝐮𝐧𝐞𝐝 𝐦𝐨𝐝𝐞𝐥 𝐨𝐧 9 𝐈𝐧𝐝𝐢𝐚𝐧 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞𝐬 — 𝐍𝐚𝐯𝐚𝐫𝐚𝐬𝐚 🚀
We are thrilled to share 🌟 𝐍𝐚𝐯𝐚𝐫𝐚𝐬𝐚, a Gemma 7B & 2B instruction-tuned models in 9 Indian Languages - Perhaps this is the first Indic open instruction-tuned model trained in 9 Indian languages additionally English included.
🔥𝐍𝐚𝐯𝐚𝐫𝐚𝐬𝐚 is a Gemma 7B & 2B SFT model using Gemma 7B & 2B base models. Last week we released the Telugu Gemma 7B/ 2B SFT model using curated Telugu datasets from Telugu LLM Labs and we observed really good performance compared to Llama2-based models.
🌐 So, we thought why don’t we scale up Gemma 7B & 2B models to multiple Indian languages and we went ahead with testing tokenizers of the following 9 Indian Languages and English Language.
1. Hindi
2. Telugu
3. Tamil
4. Malayalam
5. Kannada
6. Gujarati
7. Bengali
8. Punjabi
9. Odia
10. English
✨ We found the model to have the following capabilities: (X represents any other Indian language)
1. Instruction and Input in Native X language, Output in Native X language.
2. Instruction and Input in English language prompted to respond in Native X language, Output in Native X language.
3. Instruction in Native X language, Input in English language, and Output in Native X language.
📊𝐓𝐫𝐚𝐢𝐧𝐢𝐧𝐠 𝐃𝐞𝐭𝐚𝐢𝐥𝐬:
1. Single A100 machine which took approx. 36 hours for the 7B model and 15 hours for the 2B model.
2. Platform: E2E Networks Limited
📝 We have shared details on datasets, Examples of Reasoning, Translation, and Question Answering with Context in our blog post.
🤝 The work would not have been possible without huge community effort from different languages and a huge shout out to each one of their work over the past few months showcasing the true OSS power. Following are details of contributors for the languages:
1. Hindi: @SarvamAI
2. Telugu: Telugu LLM Labs
3. Tamil: @abhinand58
4. Kannada: @adarshxs and the team at Tensonic
5. Malayalam: Vishnu Prasad J
6. Odia: @OdiaGenAI
7. Gujarati: Adarsh Shirawalmath and the team at Tensonic
8. Punjabi: HydraIndicLM
9. Bengali: HydraIndicLM
👏 Special thanks to @unslothai for simplifying the training and inference processes!
🔜 As we release these models, the next step is to create romanized datasets and we are working hard on evaluation datasets so that we can benchmark and improve on top of it.
🤝 This work is done in collaboration with @ramsri_goutham as part of the Telugu LLM Labs independent initiative.
𝐁𝐥𝐨𝐠𝐏𝐨𝐬𝐭: shorturl.at/jBQWY
𝐂𝐨𝐝𝐞𝐁𝐚𝐬𝐞: shorturl.at/elxBF

14
47
217
30,703
Sambit Sekhar retweeted
1 Mar 2024
Excited to share Qwen_1.5_Odia_7B, the first pre-trained Odia LLM released from @OdiaGenAI
Go through the blog post for the details.
Model: huggingface.co/OdiaGenAI-LLM…
Dataset: huggingface.co/datasets/Odia…
Blog: odiagenai.org/blog/introduci…

1
6
18
524