
Applied AI @MistralAI Previously - @llama_index (LlamaIndex) Focused on LLMs, Agents, RAG, and fine-tuning LLMs.
Joined December 2010
- Tweets 1,410
- Following 851
- Followers 6,061
- Likes 9,072
147 Photos and videos









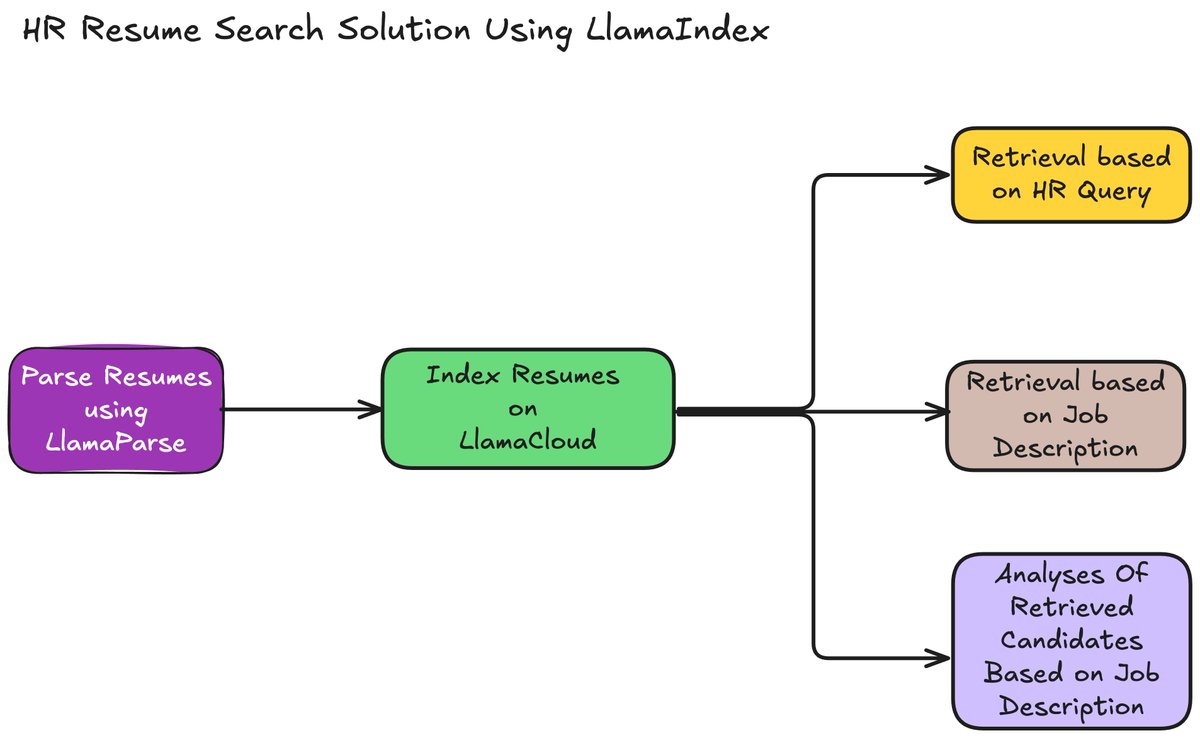
Pinned Tweet

5 Aug 2024
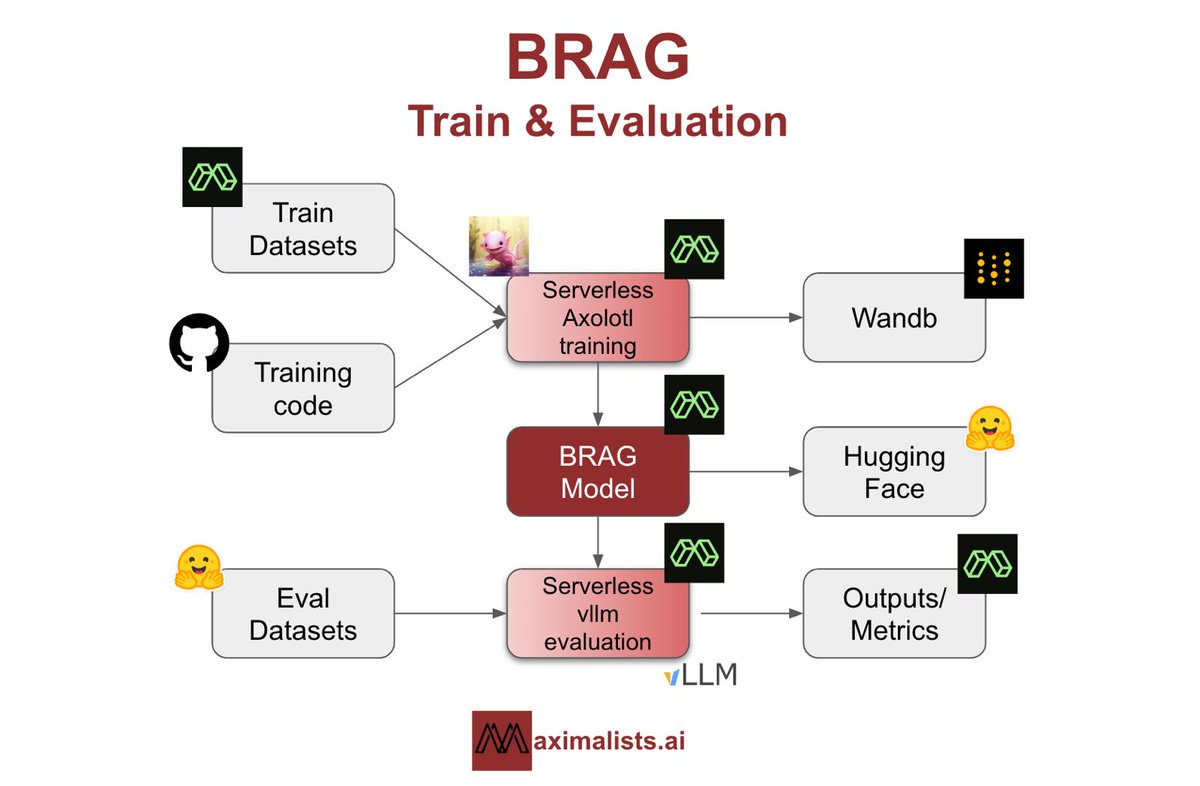
🔥 Releasing BRAG: High-Performance RAG Model Trained In $25
🚀 We’re thrilled to announce the launch of our RAG models, collectively known as BRAG—a series of SLMs (3 SLMs and 1 Ultra SLM) specifically trained for Retrieval Augmented Generation (RAG).
1️⃣ BRAG-Qwen2-7b-v0.1
2️⃣ BRAG-Llama-3.1-8b-v0.1
3️⃣ BRAG-Llama-3-8b-v0.1
4️⃣ BRAG-Qwen2-1.5b-v0.1
🌟 Our models outperform Cohere’s Command R , Qwen2, Llama3.1, and Llama3 Instruct models and closely matched the performance of GPT-4-Turbo and Nvidia’s ChatQA-1.5-8B on ChatRAG-Bench.
💵 Each model was trained in less than $25.
🔍 More interesting details on datasets and training procedure in our release technical report: shorturl.at/IrCE1
🙌 A huge thank you to @HamelHusain, @dan_s_becker, and @charles_irl for the credits on @modal_labs via the LLM Fine-tuning course.
This work is done in collaboration with @nlpguy_ under maximalists.ai
18
82
440
65,938
Ravi Theja retweeted

Jun 7
We are releasing a fully reproducible early preprint of "Prism: Unlocking Language Model Capability Extraction".
A trained language model knows many things at once, but deployment usually asks for one behavior at a time. Enterprise scenarios often have few products, workflows, features, or use-cases matter disproportionately.
Prism asks and answers a simple question - "Is it possible to isolate and deploy only capabilities that are driven by Pareto principle and cut down costs by a huge margin while preserving most of the performance?"
This paper discusses a novel approach to efficiency, understanding model behavior and opens up capability extraction.

21
40
210
21,687
Ravi Theja retweeted

Jun 4
We're presenting ParseBench at CVPR 2026!
ParseBench is the most comprehensive document understanding benchmark for VLMs.
✅ It contains 2k pages of real-world enterprise documents
✅ It has comprehensive evaluation metrics around tables, charts, visual grounding, semantic formatting, and content faithfulness
The core goal is measuring whether models can semantically interpret a document in the right way, without having models overfit to our precise benchmark.
Parsing 100% of PDFs to 100% accuracy is the final boss for document OCR.
In general, the latest frontier models have been tuned for coding, math, and scientific reasoning as opposed to precise visual understanding; hope more benchmarks that these will encourage overall progress towards solving this problem!
Poster is below. If you want to learn more come check out our site or 30-page ArXiv paper:
ParseBench: parsebench.ai/
ArXiv: arxiv.org/abs/2604.08538

Jun 4

We're presenting ParseBench at CVPR 2026 today. 🦙
Come learn why document understanding is an AGI-complete problem (an agent can't act on a doc it can't correctly read, and reading a real enterprise table is harder than it looks).
The first doc-parsing benchmark built for AI agents:
2,000 human-verified pages
167K test rules
5 dimensions: tables, charts, faithfulness, formatting, grounding
Fully open source.
📍 Talk TODAY, June 4, 9–10 AM at CVPR. Come say hi 👇
🤗 huggingface.co/datasets/llam…
💻 github.com/run-llama/ParseBe…
📄 arxiv.org/abs/2604.08538

12
18
115
18,061
Ravi Theja retweeted

May 28
Superintelligence will be built on Self Improvement.
Today @hexoai, we’re excited to release ‘SIA’ - an open-source Self-Improving AI, to achieve any goal through recursive self improvement.
While trying to solve a problem, SIA doesn't just improve it's abilities by updating it's harness, it updates it's own weights as well.
121
134
637
517,049
May 24
In another decade, this might be a robot.
For now, Indian unit economics favor the human version :)
May 23

In Lajpat, you can now pay ₹149/hr for someone to carry your bags, wait in food queues, walk you to the metro, find you a place to sit, and even set up a foldable chair.
interesting biz !!
1
2
785
Ravi Theja retweeted

May 18
For a while, @aakrit & I've quietly done this at Activate: spend time with exceptional operators, CTOs & senior builders before there’s a deck, company, or fully formed idea.
Now opening it up
Mixture of Experts - a small private dinner for people at the edge of founding
First edition tomorrow in Bengaluru
Request below on the Luma to join or DM if someone exceptional should be in the room.
luma.com/1vmm7hq9
6
4
93
18,685
Ravi Theja retweeted
May 7
Ever wondered if you could extract capabilities and behaviors from neural networks and reuse/update/route it as needed?
We introduce low-rank circuit conditioning, a novel approach that preserves the model's output behavior while reshaping how an existing capability is represented. In the base model, standard compact recovery stalls at 29%. After conditioning, the same extraction pipeline reaches 91.33% autoregressive full-answer recovery from 5.05% of MLP channels. The evidence points to a possibility of extracting and using isolated capabilities saving cost, latency and high adaptability.
Read our work to understand more - tokenbender.com/posts/honey-…
28
66
396
44,800
Ravi Theja retweeted
India’s AI future is being built by those who ship, not just study.
Today I’m announcing Activate Fellows - a summer program for 15 of India’s (and the world’s) best student builders to work inside the country’s leading AI startups
Only 15 spots. And 8 days left to apply. Details link 🧵

10
18
182
14,913

ParseBench is now live on Kaggle Benchmarks! 🚀
Developed by @llama_index, this benchmark evaluates PDF-to-structured-data conversion, featuring ~2k human-verified pages from real enterprise docs across 5 capability dimensions.
🥇Gemini 3 Flash: 79.3%
🥈GPT 5.4: 72.9%
🥉Gemma 4 31B: 66.4%
5
20
117
15,555
Ravi Theja retweeted
Apr 13
We’re open sourcing the first document OCR benchmark for the agentic era, ParseBench.
Document parsing is the foundation of every AI agent that works with real-world files. ParseBench is a benchmark that measures parsing quality specifically for agent knowledge work:
✅ It optimizes for semantic correctness (instead of exact similarity)
✅ It has the most comprehensive distribution of real-world enterprise documents
It contains ~2,000 human-verified enterprise document pages with 167,000 test rules across five dimensions that matter most: tables, charts, content faithfulness, semantic formatting, and visual grounding.
We benchmarked 14 known document parsers on ParseBench, from frontier/OSS VLMs to specialized parsers to LlamaParse. Here are some of our findings:
💡 Increasing compute budget yields diminishing returns - Gemini/gpt-5-mini/haiku gain 3-5 points from minimal to high thinking, at 4x the cost.
💡 Charts are the most polarizing dimension for evaluation. Most specialized parsers score below 6%, while some VLM-based parsers do a bit better.
💡 VLMs are great at visual understanding but terrible at layout extraction. GPT-5-mini/haiku score below 10% on our visual grounding task, all specialized parsers do much better.
💡 No method crushes all 5 dimensions at once, but LlamaParse achieves the highest overall score at 84.9%, and is the leader in 4 out of the 5 dimensions.
This is by far the deepest technical work that we’ve published as a company. I would encourage you to start with our blog and explore our links to Hugging Face to GitHub. All the details are in our full 35-page (!!) ArXiv whitepaper.
🌐: Blog: llamaindex.ai/blog/parsebenc…
📄 Paper: arxiv.org/abs/2604.08538?utm…
💻 Code: github.com/run-llama/ParseBe…
📊 Dataset: huggingface.co/datasets/llam…
🎥 YouTube: youtube.com/watch?v=g5p7G-Nw…
31
81
524
107,659
Ravi Theja retweeted

Mar 31
LlamaIndex is proud to be named to the 2026 Enterprise Tech 30, #3 in the Early Stage category.
The ET30 is an annual list by @Wing_VC and Eric Newcomer, voted on by
90 leading investors and corporate development leaders. It recognizes the private companies wi th the most potential to shape the future of enterprise technology.
Thank you to Wing Venture Capital and Eric Newcomer, and congratulations to all the companies honored this year.

3
6
24
5,827
Ravi Theja retweeted

Mar 30
I wanted to share a bunch of my favorite hidden and under-utilized features in Claude Code. I'll focus on the ones I use the most.
Here goes.
546
2,512
23,149
3,951,991
Ravi Theja retweeted

Mar 11
Mistral AI is headed to San Jose for @NVIDIA GTC! 🚀
We’re demoing our newest frontier models, sharing our vision for the future of enterprise AI, and unveiling some big news you won't want to miss.
📍 Visit us to see the latest innovations in action.
🗓️ Check out our sessions and book a meeting: link in 🧵

11
25
219
22,699
Ravi Theja retweeted

Mar 6
📢 Open-sourcing the Sarvam 30B and 105B models! Trained from scratch with all data, model research and inference optimisation done in-house, these models punch above their weight in most global benchmarks plus excel in Indian languages.
Get the weights at Hugging Face and AIKosh. Thanks to the good folks at SGLang for day 0 support, vLLM support coming soon. Links, benchmark scores, examples, and more in our blog - sarvam.ai/blogs/sarvam-30b-1…
206
1,244
6,795
746,230
Ravi Theja retweeted

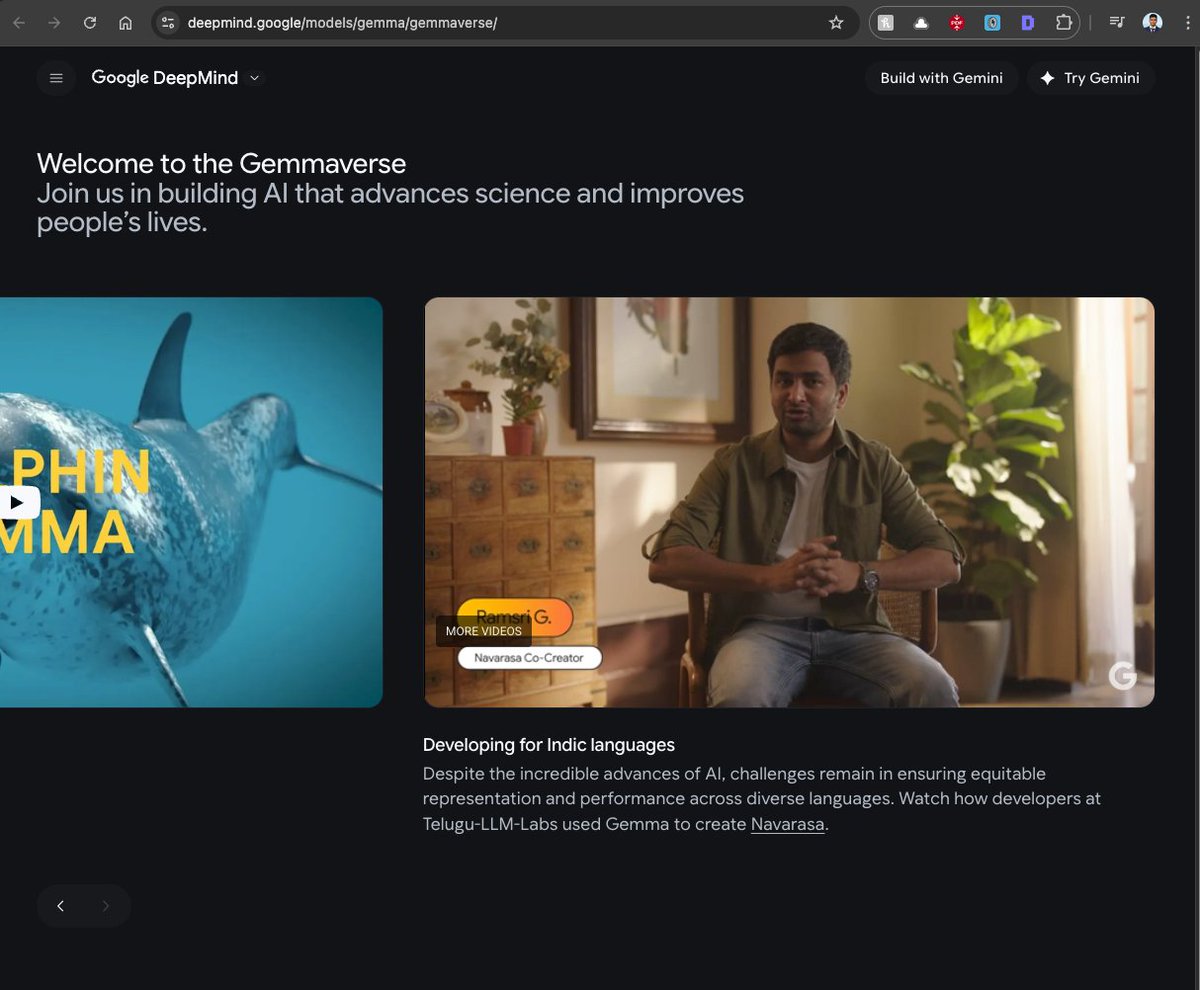
Navarasa in Deepmind's Gemmaverse 🚀
The work @ravithejads and I did in building Navarasa, an Indic instruction-finetuned model on top of Google's Gemma catering to 15 Indian languages, has been featured in Deepmind's Gemmaverse!
5
2
22
1,466

Feb 20
Looks solid and properly grounded in sources.
Congratulations, team @SarvamAI.
Feb 20

Drop 14a/14: Over the past few days, we’ve been putting our models, products, and research out there. The positive feedback has helped more people agree with our long held belief that #IndiaCan be a builder in this space.
Today, we are rolling out Indus - a chat interface to experience Sarvam 105B. Here is what all you can do:
3
3
38
2,147
Ravi Theja retweeted
Feb 18
Drop 13/14: The 30B and 105B models, benchmarks, and HF links will all come. But today it is a drop about people. About how our team of just 15 folks gave it their all to do what many doubted as not doable - ie train usefully large, globally competitive models from scratch in India. This team of 15 has now firmly launched @sarvam into its second innings. Yes, we can!
@_mohit_singla
@anand_404
@kediaharshit9
@AashaySachdeva
@sumanthd17
@ArpitDwivedi100
@HarveenChadha
@rkal4
@sushil_khyalia
@ManavSinghal157
@sohampetkar
missing in the pictuere -
@selfawareatom
@AnnaUpreti
Anand
@MeghMakwan33973
Utkarsh

198
726
5,242
310,356
Ravi Theja retweeted
Feb 17
Drop 12/14: Models, products, impact - today something different, very different. Launching Sarvam Kaze, our foray into getting our models into the your hands with our devices - designed and built here in India!
127
556
3,332
348,925
Ravi Theja retweeted
Feb 13
Drop 9/14: Today we are introducing Sarvam Studio, our product to help creators go multilingual. One piece of content, every corner of India.
With AI video dubbing, Studio generates high-fidelity dubs in 11 Indian languages. In an expert study, participants preferred Sarvam Studio for overall quality and production readiness.
With agentic document translation, Studio excels in contextually translating long-form content across genres. Our evaluations demonstrate that readers strongly preferred the output from Studio across different genres.
79
330
1,791
255,540
Ravi Theja retweeted

Feb 13
I selected one of the most challenging Telugu dialogues, widely celebrated for its powerful delivery, and it absolutely nailed it 🔥 @SarvamForDevs
18
41
314
21,528