
#DirectorUX en @kambrica. Artículos en santiagobustelo.medium.com/. Aquí suelo escribir pavadas.
Joined October 2008
- Tweets 21,755
- Following 2,421
- Followers 3,187
- Likes 170,818
3,794 Photos and videos













Pinned Tweet

14 Sep 2020
Así como existen agendas perpetuas q sirven p/cualquier año, tengo ganas de armar un diario perpetuo, q sirva p/cualquier día.

4
8
56
Santiago Bustelo retweeted

Jun 12
Uruguay encontró otros dos mundiales en un diskette 5 1/4.
61
1,777
15,360
219,247
May 16
Un amigo en pasa un dato caliente: HAY GENTE QUE SE ESTÁ VOLVIENDO A VENEZUELA
hagan lo q quieran con esa información
76
Santiago Bustelo retweeted

May 9
Esto es, realmente, un DELIRIO.
Agarraron 2.245 currículums reales escritos por humanos y le pidieron a ChatGPT, DeepSeek y otros modelos que los reescriban. Mismo curriculum, experiencia, estudios... todo igual, solo que reescrito.
Después, le mostraron pares al azar a cada IA y le pidieron que eligiera el mejor: el suyo contra el del humano. Todos se eligieron a sí mismos más del 95% de las veces. Incluso después de controlar por calidad (asegurándose de que el CV humano no fuera objetivamente peor) seguían eligiendo el suyo.
Después, simularon procesos reales de selección en 24 industrias y descubrieron que, si usaste el mismo modelo que el reclutador, tenés entre 23% y 60% más chances de pasar el primer filtro.
¿Por qué pasa esto? Los autores tienen una hipótesis fuerte: cuando le pedís a un modelo que te mejore el CV, te lo reescribe con su huella estilística: sus palabras favoritas, su ritmo, su forma de armar oraciones... Cada IA tiene un estilo propio, como cada escritor tiene una letra. Después, cuando esa misma IA evalúa, se reconoce del otro lado y se pone un diez. Cuanto más capaz es el modelo, más afilada es su capacidad de reconocerse.
Ahora buscar laburo es como el test de Turing pero al revés: en lugar de una máquina intentando convencerte de que es humana, parece que ahora somos nosotros los que tenemos que convencer a los robots que somos uno de ellos.

83
1,492
8,636
837,574
Apr 21
Pase de tener decenas de impresiones y hasta algún tweet viral, a q me cierren la canillla después de haber bloqueado a cierto tipo que pago mucha plata por tener su propia red social.
Voy a ver que pasa si no solo lo desbloqueo , sino que además lo empiezo q seguir.
1
2
115

Santiago Bustelo retweeted

Mar 9
me robaron la valija en un micro e hice la denuncia a la CNRT
la CNRT:
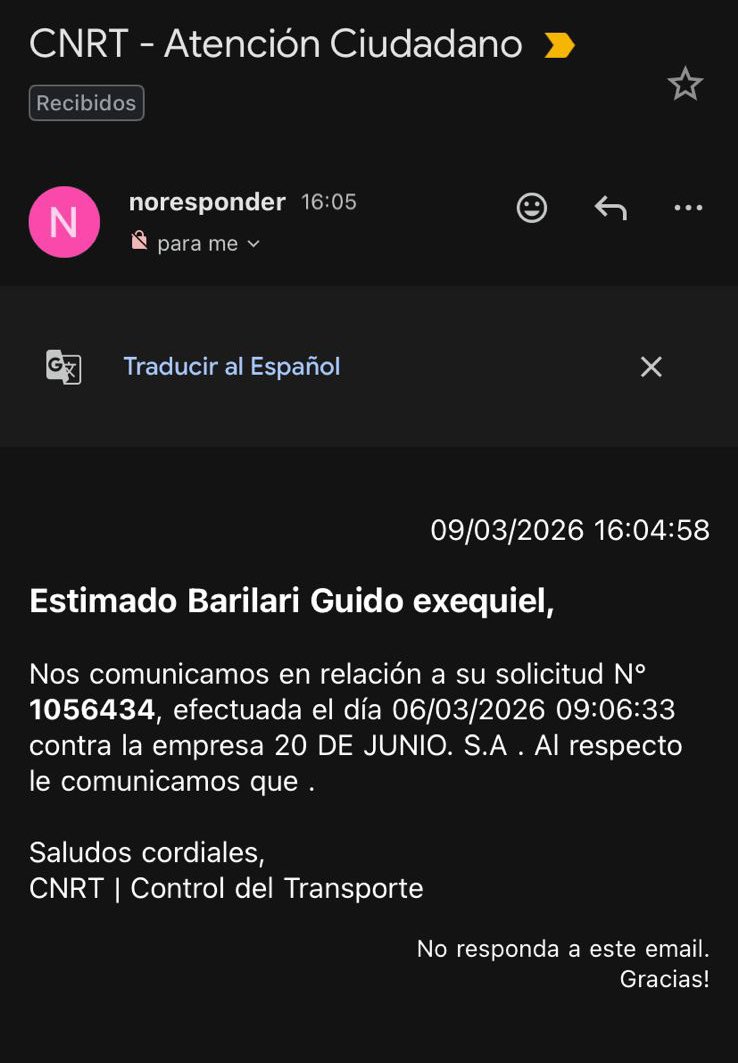


209
1,322
42,272
1,339,848
Santiago Bustelo retweeted

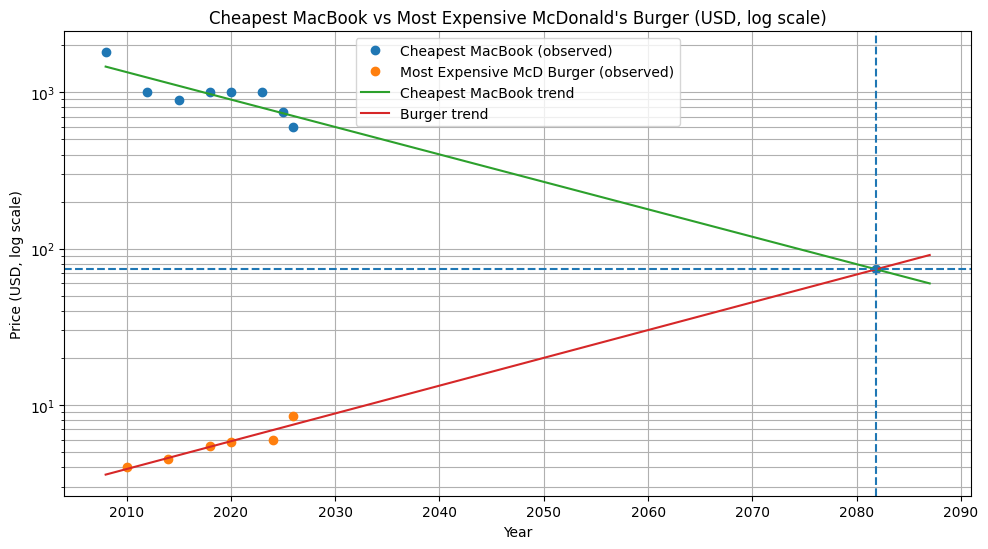
I've plotted the most expensive McDonald's burger and the least expensive MacBook over time. This analysis projects that the most expensive burger will be more expensive than the cheapest laptop as soon as 2081
404
2,463
37,276
1,141,687

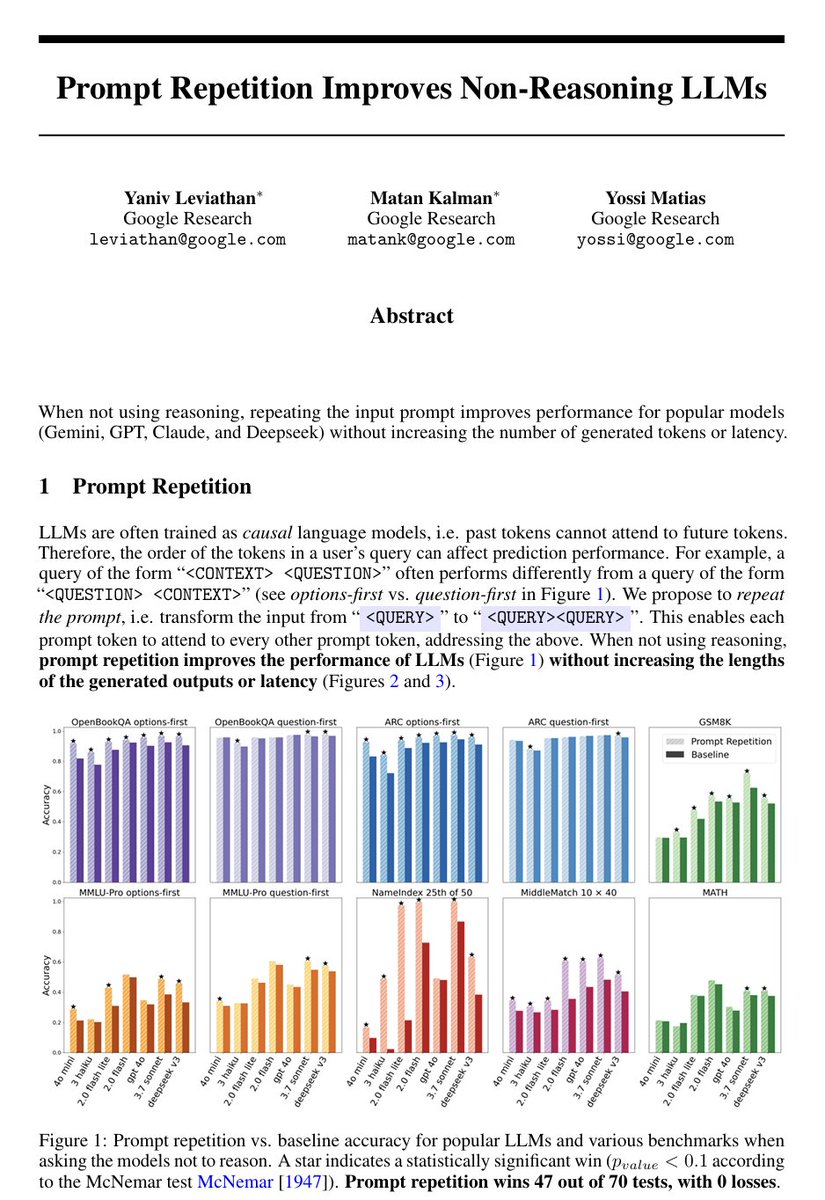
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: chapterpal.com/s/1b15378b/pr…
Get the PDF: arxiv.org/pdf/2512.14982
386
1,108
11,556
2,989,157


Seguimos cerrando grietas musicales! Sui Generis La Renga: "Canción para mi balada del diablo y la muerte"
Enjoy!
youtu.be/peI4var-PYQ
1
124
Jan 30
Cometí "Chico Callejero", versión candombe pop latino. Con video genérico con gente con alegría de publicidad de gaseosa y todo!
youtu.be/SBOBril1S8U
78


Jan 22
El puente entre Corrientes y Resistencia debería llamarse Georg Simon Ohm.
1
2
5
106
Santiago Bustelo retweeted

Jan 12
Topological world map: where only land borders matter.
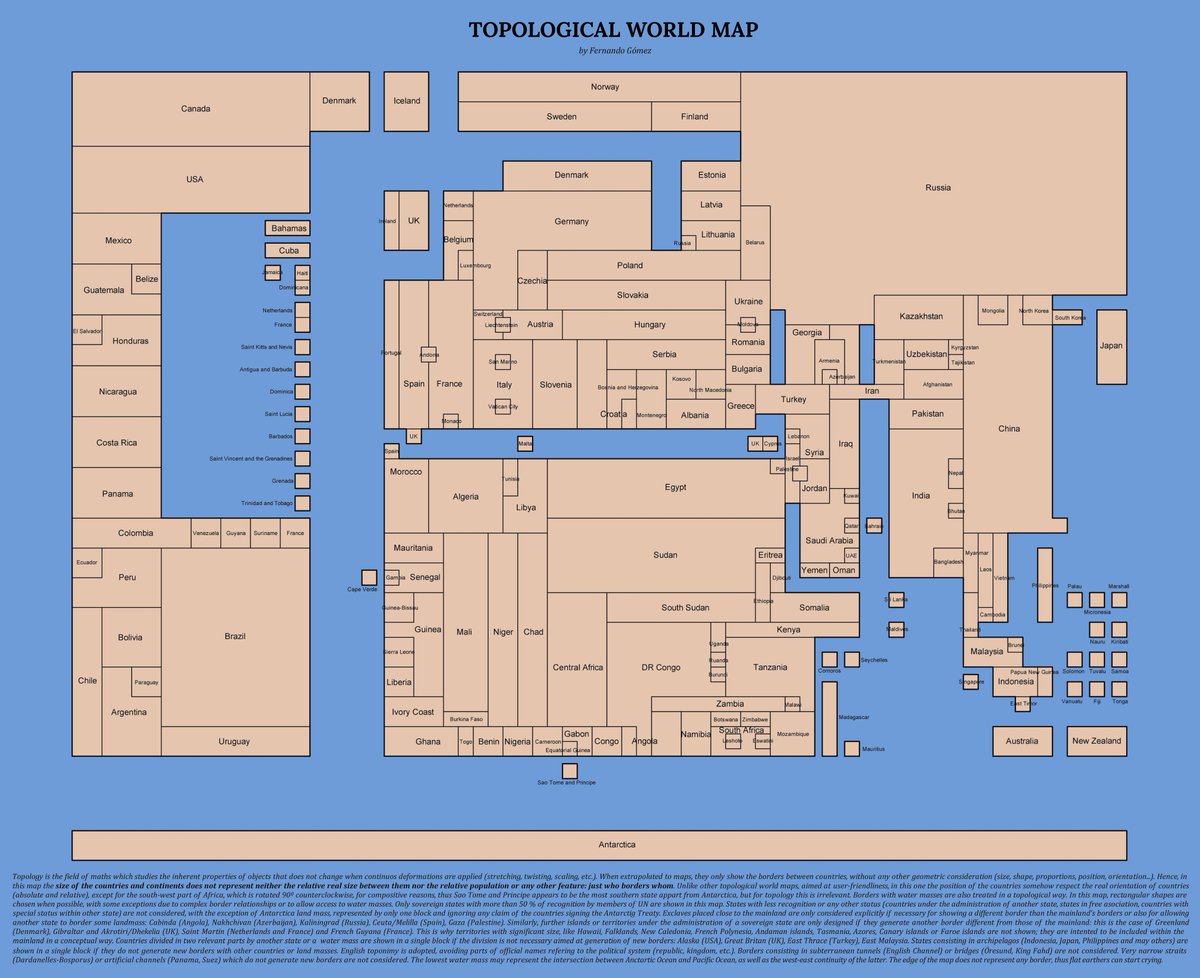
ALT 🔎 Fernando Gómez
97
543
4,850
265,257



Santiago Bustelo retweeted

BTW, the cafeteria at work just upgraded their payment system to "tap-to-pay only" over the weekend.
It's been causing chaos all morning. Half the building can't figure out how to use it.
Three different people asked me if I was "involved in rolling out the new system."
I said no, that's handled by an outside vendor, completely separate from IT.
Which is true. But here's what I didn't say:
I knew this was coming after the new year. The facilities manager mentioned it in passing. I could've sent out a company-wide email preparing people for the change.
I didn't.
Because the more chaos there is around technology that isn't my responsibility, the more competent I look by comparison.
When people struggle with the cafeteria payment system, then come back to their desks and everything works smoothly, they appreciate IT more.
36
94
5,071
229,035
Santiago Bustelo retweeted

Jan 9
The reason why RAM has become four times more expensive is that a huge amount of RAM that has not yet been produced was purchased with non-existent money to be installed in GPUs that also have not yet been produced, in order to place them in data centers that have not yet been built, powered by infrastructure that may never appear, to satisfy demand that does not actually exist and to obtain profit that is mathematically impossible.
1,070
20,991
141,338
4,208,729