
A computer scientist from Bangkok, Thailand. Research Scientist @GoogleDeepmind. Previous: @GoogleAI, @ShaLabUSC at @CSatUSC, & @BrownCSDept. He/Him. 🏳️🌈
Joined November 2016
- Tweets 492
- Following 645
- Followers 404
- Likes 6,293
37 Photos and videos











Pinned Tweet

21 May 2023
Looking for a multilingual visual question answering dataset to test your model? Here's MaXM. English, French, Hindi, Hebrew, Romanian, Thai, and Chinese!
github.com/google-research-d…
1
11
32
4,264

1/ Today at #GoogleIO, we’re releasing Gemini 3.5, our latest family of models combining frontier intelligence with action.
We’re starting by releasing 3.5 Flash, which is built to help you execute complex, long-horizon agentic workflows.
Gemini 3.5 Flash is our strongest model for coding and agent yet.It outscores 3.1 Pro on agentic and coding benchmarks like Terminal-Bench and MCP Atlas, while running 4x faster than other frontier models.
Used in Google Antigravity, 3.5 Flash is even further optimized to be up to 12x faster. It’s a powerful engine to deploy sub-agents that collaborate, run high-frequency iterative loops, and solve real-world problems at scale.
Some highlights we’re excited about 🔽

85
195
1,488
132,926
One of my favorite projects I get to be a part of! 🚀 Josh Woodward just showed off our new Neural Expressive design on the Google I/O 2026 stage.
🔗youtu.be/wYSncx9zLIU?t=4323
1
1
2
259
If you want to see our multimodal models in full flow, check out how we bring Roman aqueducts to life with custom interactive images and timelines. Honestly, it’s such a fun way to dive into history (and other topics) without a dusty textbook! 🏛️✨
40
Soravit “Beer” Changpinyo retweeted

11 Sep 2025
i just realized that i already have everything 18-year old eric ever wanted in life. that’s really nice. i shouldn’t be so stressed all the time
177
199
7,278
862,510
Soravit “Beer” Changpinyo retweeted

27 Aug 2025
A conversation with some of the research folks behind nano-banana 🍌 (aka Gemini 2.5 Flash Image) on how we got here, what it took to build this model, and where we go next!
So much fun to hang with: @19kaushiks @robertriachi @m__dehghani @nbrichtova
76
112
1,128
229,183
26 Aug 2025
🍌 🍌 🍌
26 Aug 2025

Image generation with Gemini just got a bananas upgrade and is the new state-of-the-art image generation and editing model. 🤯
From photorealistic masterpieces to mind-bending fantasy worlds, you can now natively produce, edit and refine visuals with new levels of reasoning, control and creativity.
A quick dive into Gemini 2.5 Flash’s capabilities 🧵
93
Soravit “Beer” Changpinyo retweeted

23 Jul 2025
Our Aeneas AI model gives historians valuable new insights into ancient inscriptions & ancient history that may have taken years to uncover otherwise. Published in @Nature today: deepmind.google/discover/blo…
47
170
1,265
79,054
Soravit “Beer” Changpinyo retweeted

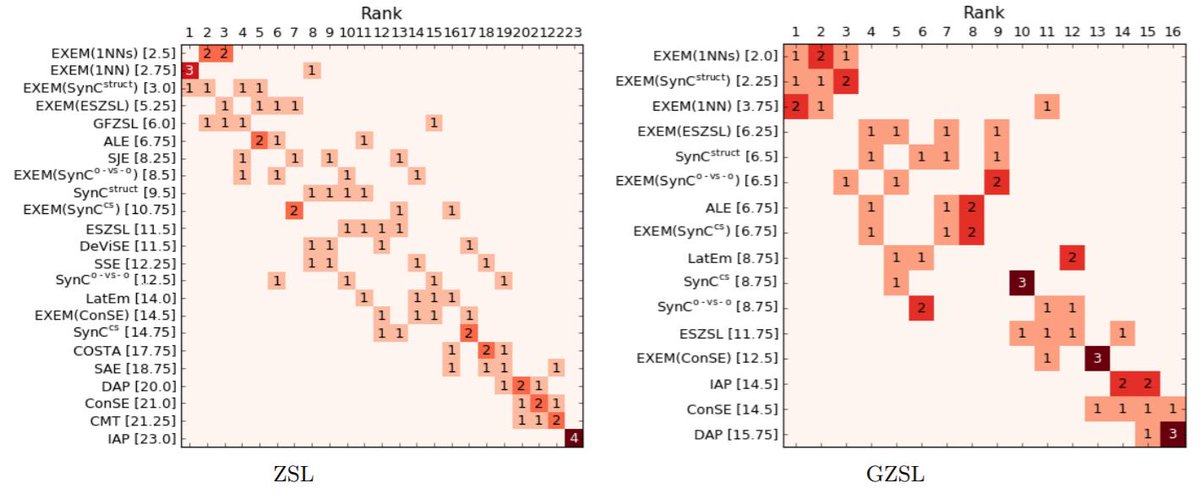
2 Apr 2025
Big update to our MathArena USAMO evaluation: Gemini 2.5 Pro, which was released *the same day* as our benchmark, is the first model to achieve non-trivial amount of points (24.4%). The speed of progress is really mind-blowing.

36
143
976
304,308
I'm delighted to have joined my good friend and colleague @NoamShazeer for a 2 hour conversation with @dwarkesh_sp about a wide range of topics (early Google, ML hardware, training trillion token LLMs in 2007, model sparsity, continual learning, and more).
Thanks for a fantastic conversation, Noam and Dwarkesh! 🙏

12 Feb 2025

The @JeffDean & @NoamShazeer episode.
We talk about 25 years at Google, from PageRank to MapReduce to the Transformer to MoEs to AlphaChip – and soon to ASI.
My favorite part was Jeff's vision for AGI as one giant MoE that is grown in bits and pieces over time like a forest, rather than trained all at once.
Specialization, distillation, inference time scaling all emerge organically rather than by design.
Noam bites every bullet: 100x world GDP soon; let’s get a million automated researchers running in the Google datacenter; living to see the year 3000.
Links below. Enjoy!
Timestamps
0:00:00 - Intro
0:03:29 - Joining Google in 1999
0:06:20 - Future of Moore's Law
0:11:04 - Future TPUs
0:13:56 - Jeff’s undergrad thesis: parallel backprop
0:15:54 - LLMs in 2007
0:25:09 - “Holy shit” moments
0:27:28 - AI fulfills Google’s original mission
0:32:00 - Doing Search in-context
0:36:12 - The internal coding model
0:37:29 - What will 2027 models do?
0:43:20 - A new architecture every day?
0:49:10 - Automated chips and intelligence explosion
0:53:07 - Future of inference scaling
1:02:38 - Already doing multi-datacenter runs
1:08:15 - Debugging at scale
1:12:41 - Fast takeoff and superalignment
1:20:51 - A million evil Jeff Deans
1:24:22 - Fun times at Google
1:27:51 - World compute demand in 2030
1:34:37 - Getting back to modularity
1:44:48 - Keeping a giga-MoE in-memory
1:49:35 - All of Google in one model
1:57:59 - What’s missing from distillation
2:03:10 - Open research, pros and cons
2:09:58 - Going the distance
75
216
2,018
231,898
Soravit “Beer” Changpinyo retweeted

16 Dec 2024
Gemini 2.0 Flash Experimental has the ability to produce native audio in a variety of styles and languages - all from scratch. 🗣️
Here’s how this is different to traditional text-to-speech systems ↓ aistudio.google.com/live
78
252
1,440
125,769
Soravit “Beer” Changpinyo retweeted

11 Dec 2024
Storytime with Gemini 2.0 Flash!
8
15
150
27,869
Soravit “Beer” Changpinyo retweeted

11 Dec 2024
Gemini 2.0 Flash ⚡️ has arrived!
2.0 Flash > 1.5 Pro (again!) 📈
Interacts with a browser 🤖
Native image generation 🖼️
and much more!
Try it out aistudio.google.com/prompts/…
As a preview of what is possible, wishing you all a Drastic Holiday powered by 2.0!
12
57
352
41,274
Soravit “Beer” Changpinyo retweeted

26 Nov 2024
A super useful blog.
"7 examples of Gemini’s multimodal capabilities in action"
1. Detailed Image Descriptions - Can analyze and describe images, adjusting style and format based on prompts
2. Long PDF Understanding - Processes 1000 page PDFs, including tables, layouts, charts, diagrams, and handwritten text
3. Real World Document Reasoning - Extracts information from receipts, labels, signs, notes, and whiteboard sketches
4. Webpage Data Extraction - Extracts structured data from webpage screenshots, including text and visual content
5. Object Detection - Detects objects and generates bounding box coordinates in images
6. Video Summarization - Processes 90-minute videos, generating transcripts, summaries, and answering questions
7. Video Information Extraction - Extracts structured data from videos for cataloging and entity detection, though currently limited by 1FPS sampling

26 Nov 2024

7 examples of Gemini's multimodal capabilities in action (with code and prompts) 🤯🧵
5
16
3,769
Soravit “Beer” Changpinyo retweeted

16 Nov 2024
✨SEA Gathering at @emnlpmeeting
Celebrating SEACrowd paper and future collaboration 🎉🥳👏🍾
Good food and good collaboration 🏝️🐟
#emnlp2024 #seacrowd #worldcuisines




1
9
43
3,361
A nice new benchmark for long video understanding by Tobias Weyand @0xtob and others. This is likely to be one of the new frontiers of capabilities for large-scale multimodal models, and it's great to have a new benchmark to assess others in this area.

Can #AI truly understand long videos? Tobias Weyand & the Google Research team are testing the limits w/ Neptune, an open-source benchmark for long video understanding. Dive into the details & see how AI tackles temporal reasoning, cause & effect, & more →goo.gle/4esTTNM
4
17
168
41,846
Soravit “Beer” Changpinyo retweeted

11 Nov 2024
The #AlphaFold 3 model code and weights are now available for academic use. We @GoogleDeepMind are excited to see how the research community continues to use AlphaFold to address open questions in biology and new lines of research.
github.com/google-deepmind/a…
13 May 2024

We love the excitement & results from the community on AlphaFold 3 and are doubling the AF Server daily job limit to 20. Happy to also share that we're working on releasing the AF3 model (incl weights) for academic use, which doesn’t depend on our research infra, within 6 months.
21
257
1,041
186,790
Soravit “Beer” Changpinyo retweeted

4 Nov 2024
🚀 Join the Gemini Multilinguality team @GoogleDeepMind 🌐 We’re looking for researchers passionate about making LLMs helpful for all. Dramatically improve model quality, coverage, and cultural relevance across hundreds of languages. #NLProc #MultilingualAI #i18n #LLMs boards.greenhouse.io/deepmin…
4
36
182
28,275
Soravit “Beer” Changpinyo retweeted

1 Nov 2024
🚀 New Scale Product 🚀
Today, we're launching Expert Match!
Expert Match enables AI developers to connect with Experts (doctors, lawyers, PhDs) to collaborate on their AI projects:
🔎 Advanced Search
💼 View Qualifications
⭐️ Streamlined Screening Selection
Read more 👇
32
51
724
115,912
29 Oct 2024
I didn’t realize we speak that slowly…🇹🇭

All languages covey information at a similar rate when spoken (39bits/s).
Languages that are spoken faster have less information density per syllable!
One of the coolest results in linguistics.
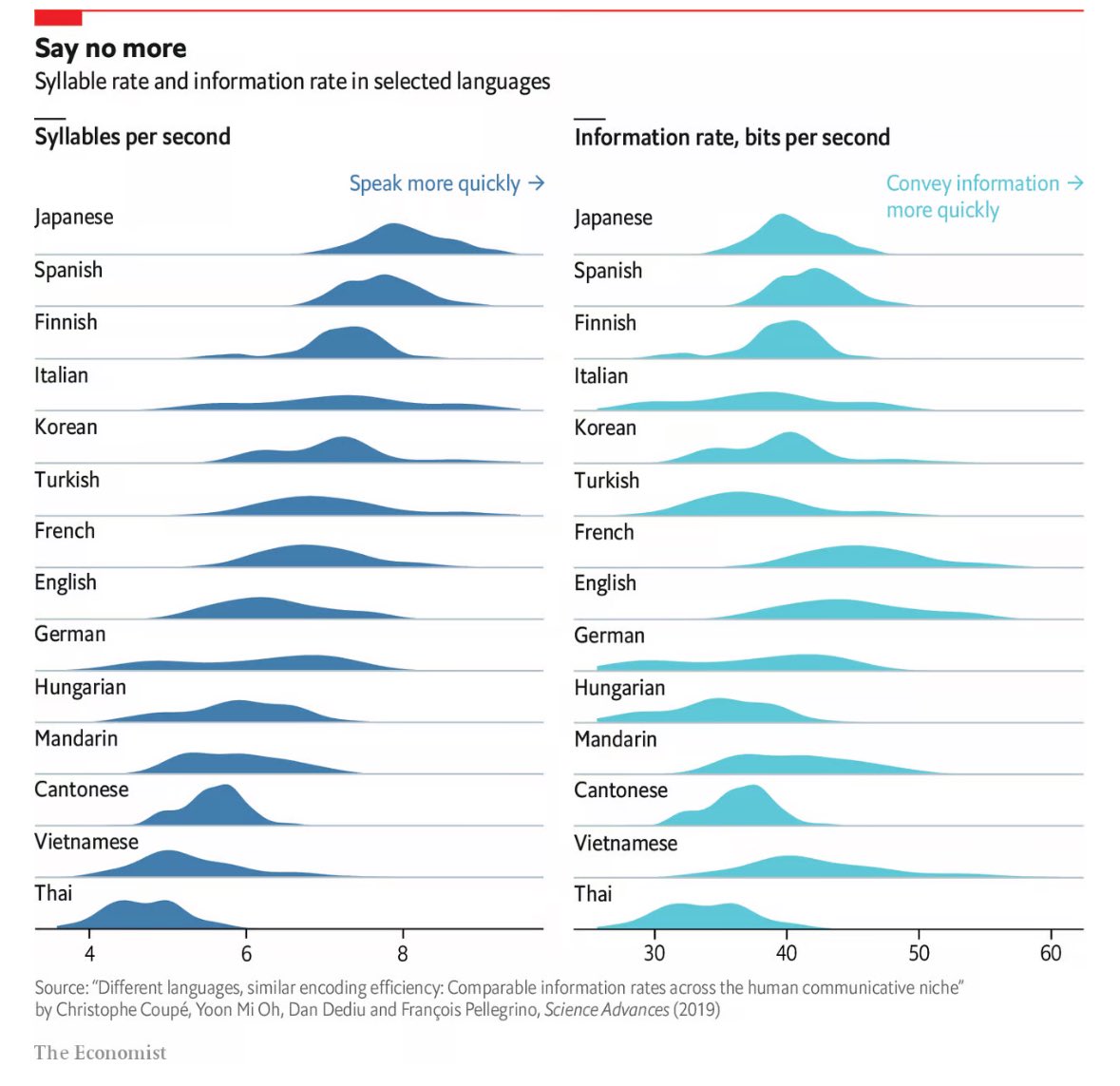
1
5
387
Soravit “Beer” Changpinyo retweeted

15 Oct 2024
ICLR 2025 will have another blogpost track!
If you have new intuitions on past work, noticed key implementation details for reproducibility, have insights into the societal implications of AI, or an interesting negative result, consider writing and submitting a blogpost. Accepted entries will have the opportunity to be presented as a poster at ICLR2025 (in Singapore)! Deadline: Before Nov. 16 2024
More info: iclr-blogposts.github.io/202…
7
86
618
83,437