
AI Researcher @CapitalOne AIF. Ex @TechAtBloomberg @BigScienceW @SFResearch @hkust. Working on multilingual and LLM #NLProc. Building @GrassrootsSci
Joined December 2011
- Tweets 1,252
- Following 856
- Followers 1,872
- Likes 7,741
98 Photos and videos







Pinned Tweet

25 Apr 2025
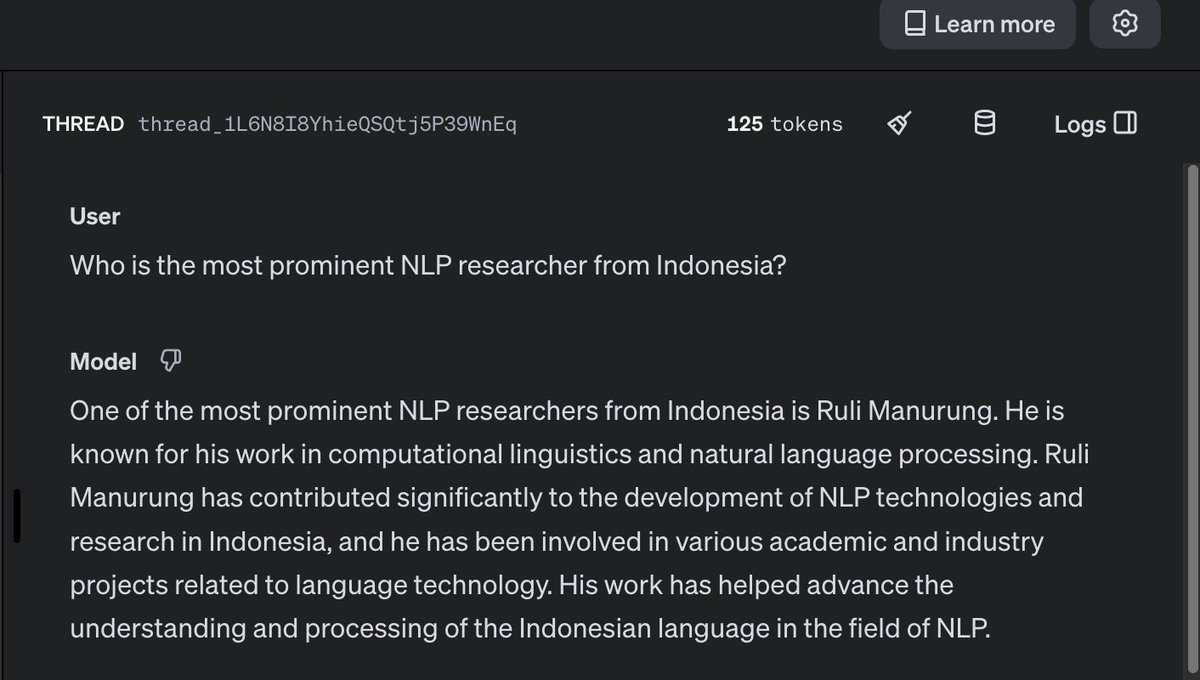
⭐️We're thrilled to share that our paper WorldCuisines has been selected for the Best Theme Paper Award at NAACL 2025 @naaclmeeting! 🎉 A huge thank you to the reviewers and area chair for this incredible recognition — we’re truly honored.
Massive gratitude to all our amazing co-authors for the countless hours, late nights, and deep discussions that went into creating this high-quality dataset.
2025.naacl.org/blog/best-pap…
We can't wait to present next week at NAACL! Catch us at our poster session (Wednesday, April 30) and Best Paper Award Session (Friday, May 2) for our oral presentation.
Check out the paper and project here:
🌐 worldcuisines.github.io
Contributors:
@fredyhudi, @patrickamadeus_, @davidanugraha, @rifkiaputri, @zzeet, @ubaidalih, @auliaadilaa, @adamnohejl, @JunhoMyung00211, @aliceoh, @AnarSnowball, @faridlazuarda, @jcblaisecruz, @nedjmaou, @jodieyzhou, @AboladeDaud, @prajdabre1, @holylovenia, @SCahyawijaya, @bryanwilie92, @mrpeerat, @farizikhwantri, @gkuwanto, @llamagrp, @mv_zhukova, @EmmanueleChers1, @AlhamFikri, @davlanade, @tarowatanabe, @OptionsGod_lgd,@AyuP_AI, and many others who are not on X.
Acknowledgments:
@nayeon7lee, @Wenliang_Dai, @pascalefung
who helped and provided us insightful suggestions.
#nlproc #naacl2025 #worldcuisines
9
15
121
17,594
Genta Winata retweeted
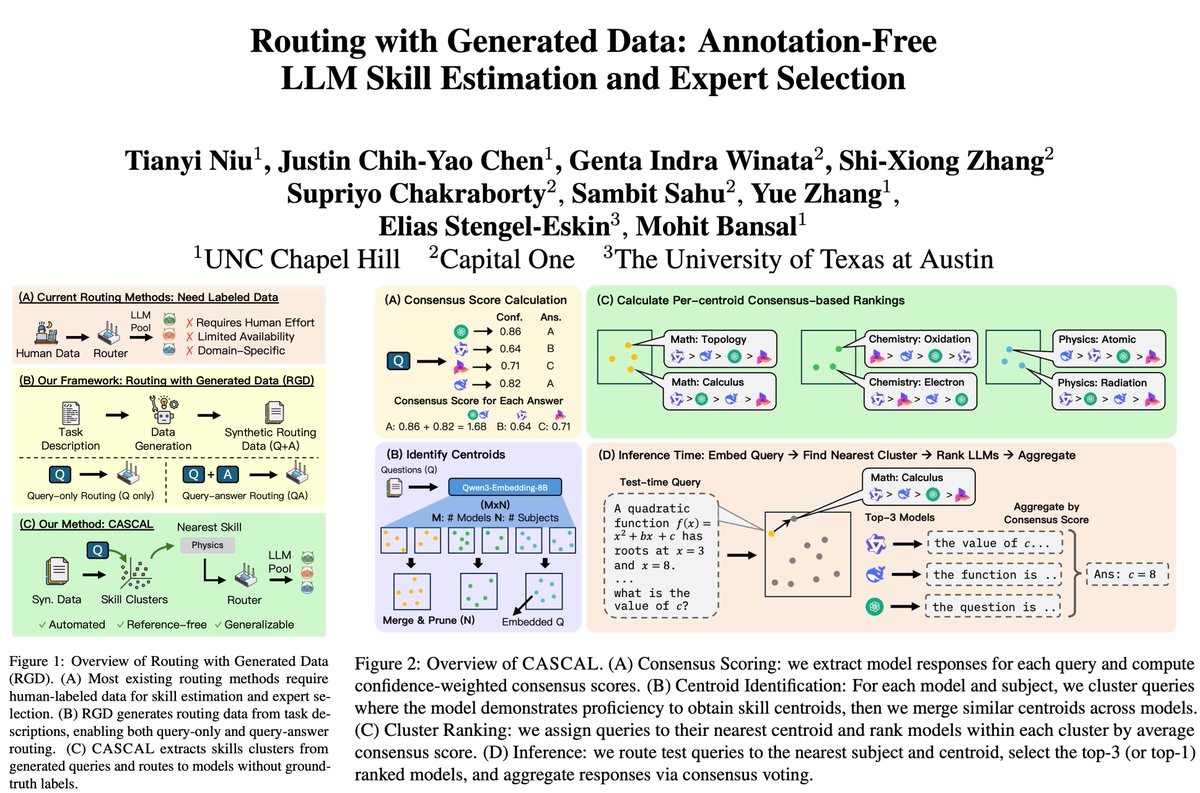
🚨 Excited to announce that RGD has been accepted to #ACL2026 Main!
Routing with Generated Data (RGD) is a new LLM routing paradigm where routers estimate skills of models using generated data, without ground-truth labels.
We further introduce CASCAL, a new router for RGD that discovers niche skills via consensus voting hierarchical clustering, with no ground truth needed.
🧵👇
Jan 15

📢 Introducing Routing with Generated Data (RGD), a new setting for annotation-free LLM routing. We study how routers can be trained without any ground-truth labels. We also introduce CASCAL, a novel label-free LLM router that identifies niche skills using consensus-voting and hierarchical clustering.
➡️ Most LLM routers assume access to labeled, in-domain data to estimate model skills (query-answer routers). However, user distributions are unknown and labels are expensive or unavailable, highlighting the need for routers that work without labels.
➡️ We introduce Routing with Generated Data (RGD): routers are trained only on Q&A data generated from task descriptions, without human annotation. We experiment with various LLM generators of different strengths (Gemini-2.5-Flash, Qwen-3-32B, Exaone-3.5-7.8B).
➡️ CASCAL outperforms other query-answer and query-only routers across diverse datasets (MMLU-Pro, SuperGPQA, MedMCQA, BigBench Extra Hard), and is more robust to weaker generators.
16
36
4,580
Genta Winata retweeted

Mar 15
VLMs can easily get distracted by unrelated cultural cues. Happy to present our work on this soon at #CVPR2026🥳
Working on multilingual VLMs? Consider using our benchmark:
📜arxiv.org/pdf/2511.17004
🤗huggingface.co/datasets/patr…
Amazing work by @patrickamadeus_ and colleagues!

Mar 15

Excited to share that we have committed our paper “Vision-Language Models are Confused Tourists” to #CVPR2026 (Findings)! 🇺🇸🏔
Arxiv: arxiv.org/abs/2511.17004
We question whether current SOTA VLMs remain robust in simple cultural grounding QA when distracting contextual objects are present
For example, if you eat chicken schnitzel with Mt. Fuji in the background, will the model fail to recognize it as Japanese katsu?
ConfusedTourists introduces:
👉 5k evaluation samples across 3 cultural item categories, comprising 243 unique cultural items from 57 countries and 11 sub-regions 🌍
👉 Evaluation of 14 VLMs across 12 data features 🤖
👉 Findings showing that simple concept mixing can cause up to a -40% drop in perform 📉
Special thanks to my co-authors @IkhlasulHanif0 , @emthehunt, @gentaiscool, @FajriKoto, and my advisor @AlhamFikri for the valuable contributions along the way!
#multimodal #vlm #multicultural #robustness #evaluation #NLProc #ComputerVision



2
18
70
7,977
Feb 2
Happy to have my first Nature paper. Thank you @CAIS for the collaboration nature.com/articles/s41586-0…
Feb 2

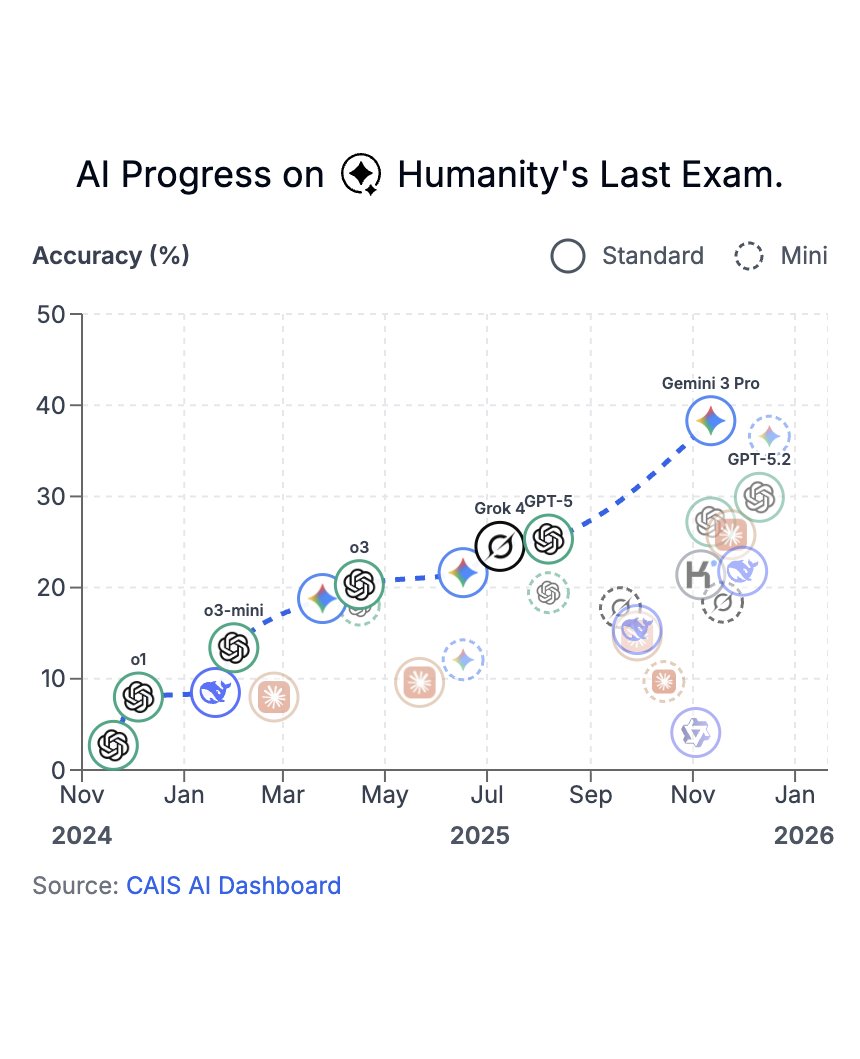
Last week, Humanity’s Last Exam was published in @Nature.
In just over a year, model scores on HLE have risen from under 5% to nearly 40%.
Thank you to @scale_AI and the 1000 HLE co-authors for helping policymakers and the public track these rapid advances in AI capabilities.

22
1,392
Genta Winata retweeted

Feb 2
Last week, Humanity’s Last Exam was published in @Nature.
In just over a year, model scores on HLE have risen from under 5% to nearly 40%.
Thank you to @scale_AI and the 1000 HLE co-authors for helping policymakers and the public track these rapid advances in AI capabilities.
9
41
156
27,451
Genta Winata retweeted

Jan 15
📢 Introducing Routing with Generated Data (RGD), a new setting for annotation-free LLM routing. We study how routers can be trained without any ground-truth labels. We also introduce CASCAL, a novel label-free LLM router that identifies niche skills using consensus-voting and hierarchical clustering.
➡️ Most LLM routers assume access to labeled, in-domain data to estimate model skills (query-answer routers). However, user distributions are unknown and labels are expensive or unavailable, highlighting the need for routers that work without labels.
➡️ We introduce Routing with Generated Data (RGD): routers are trained only on Q&A data generated from task descriptions, without human annotation. We experiment with various LLM generators of different strengths (Gemini-2.5-Flash, Qwen-3-32B, Exaone-3.5-7.8B).
➡️ CASCAL outperforms other query-answer and query-only routers across diverse datasets (MMLU-Pro, SuperGPQA, MedMCQA, BigBench Extra Hard), and is more robust to weaker generators.
1
27
45
10,691
24 Dec 2025
💡Have you ever wondered whether vision–language models can be easily tricked by adding landmarks or flags to an image?
In the spirit of the holidays🎄, we show that VLMs can indeed be easily confused like "Confused Tourists" ✈️: their performance drops significantly when such image perturbations are applied.
🔎 Check out "VLMs are Confused Tourists" ✈️ here arxiv.org/pdf/2511.17004
#vision #nlproc #robustness
23 Dec 2025
Craving holiday-themed paper? Say less🎄
Turns out, Vision Language Models are Confused Tourists ✈️😵💫
We show that adversarially induced cultural scenes significantly impair VLM cultural comprehension and trigger potential bias
#NLProc #multimodal #robustness
/thread 🧵(1/8)

3
16
2,523
Genta Winata retweeted

23 Dec 2025
Craving holiday-themed paper? Say less🎄
Turns out, Vision Language Models are Confused Tourists ✈️😵💫
We show that adversarially induced cultural scenes significantly impair VLM cultural comprehension and trigger potential bias
#NLProc #multimodal #robustness
/thread 🧵(1/8)
3
21
49
19,669
Genta Winata retweeted

16 Dec 2025
One last call for interested applicants! Applications for the SEACrowd Apprentice Program 2026 will end on December 17, 23:59 (UTC-12). See the post below for more details.
30 Nov 2025

🌏 Applications are now open for the SEACrowd Apprentice Program 2026!
Join a 3–4 month guided research journey where you’ll collaborate with mentors.
🗓️ Apply between Nov 17 – Dec 17, 2025 (UTC-12)
📅 Program runs Feb – Jun 2026
seacrowd.org/apprenticeship
3
11
1,429
Genta Winata retweeted
6 Dec 2025
We’ve just shared a full retrospective of the first batch our Apprentice Program from research wins to real lessons learned along the way. It’s inspiring to see how our SEA mentees transformed ideas into papers and datasets through mentorship.🚀🚀
seacrowd.org/posts/apprentic…
1
9
15
927
Genta Winata retweeted

1 Dec 2025
Excited to be at #NeurIPS 2025 in San Diego this week! 🌴🤖
I’m presenting our UniReps workshop paper on Dec 6: Leveraging Parameter Space Symmetries for Reasoning Skill Transfer in LLMs.
Come say hi! Would love to connect and exchange ideas
Paper: arxiv.org/abs/2511.10850
1
1
1
300
Genta Winata retweeted
30 Nov 2025
🌏 Applications are now open for the SEACrowd Apprentice Program 2026!
Join a 3–4 month guided research journey where you’ll collaborate with mentors.
🗓️ Apply between Nov 17 – Dec 17, 2025 (UTC-12)
📅 Program runs Feb – Jun 2026
seacrowd.org/apprenticeship
2
34
152
109,350
Genta Winata retweeted

6 Oct 2025
🚀 Following R3, we are thrilled to introduce mR3: Multilingual Rubric-Agnostic Reward Reasoning Models 🎉
TL;DR: mR3 is a multilingual version of R3, a rubric-agnostic reward reasoning model trained on 72 languages, achieving the broadest language coverage in reward modeling to date. mR3 is able to surpass much larger models, such as GPT-OSS-120B, while being up to 9x smaller⚡!
📄 Paper: arxiv.org/abs/2510.01146
💻 Code: github.com/rubricreward/mr3
🤗 mR3 Models: huggingface.co/collections/r…
🤗 mR3 Datasets: huggingface.co/collections/r…
Huge thanks to all of my collaborators: @HLeiTR,
@Zilu_Tang_Peter, @ Annie Lee, @DerryTWijaya1, @llamagrp, and @gentaiscool for all of their efforts into creating this work!
Check this thread out! #mR3 #RewardModel #NLP #LLM #Metrics #Alignment #Preference (1/4)
1
4
9
860
18 Sep 2025
Extremely proud to share that our paper: 𝐓𝟏: 𝐀 𝐓𝐨𝐨𝐥-𝐎𝐫𝐢𝐞𝐧𝐭𝐞𝐝 𝐂𝐨𝐧𝐯𝐞𝐫𝐬𝐚𝐭𝐢𝐨𝐧𝐚𝐥 𝐃𝐚𝐭𝐚𝐬𝐞𝐭 𝐟𝐨𝐫 𝐌𝐮𝐥𝐭𝐢-𝐓𝐮𝐫𝐧 𝐀𝐠𝐞𝐧𝐭𝐢𝐜 𝐏𝐥𝐚𝐧𝐧𝐢𝐧𝐠 has been accepted into @NeurIPSConf 2025!
We introduce T1, a tool-augmented, multi-domain, multi-turn conversational dataset specifically designed to capture and manage inter-tool dependencies across diverse domains with a focus on the travel space.
I would like to shoutout all of my amazing co-authors Amartya Chakraborty, Nadia Bathaee, @pareshdashore19, Anmol Jain, @zzeet, Shi-Xiong ZHANG, Sambit Sahu, and Milind Naphade who all worked incredibly hard to make this paper possible!
Paper Link: arxiv.org/pdf/2505.16986
#nlproc #ml #agents
2
2
19
860
18 Sep 2025
Key Highlights:
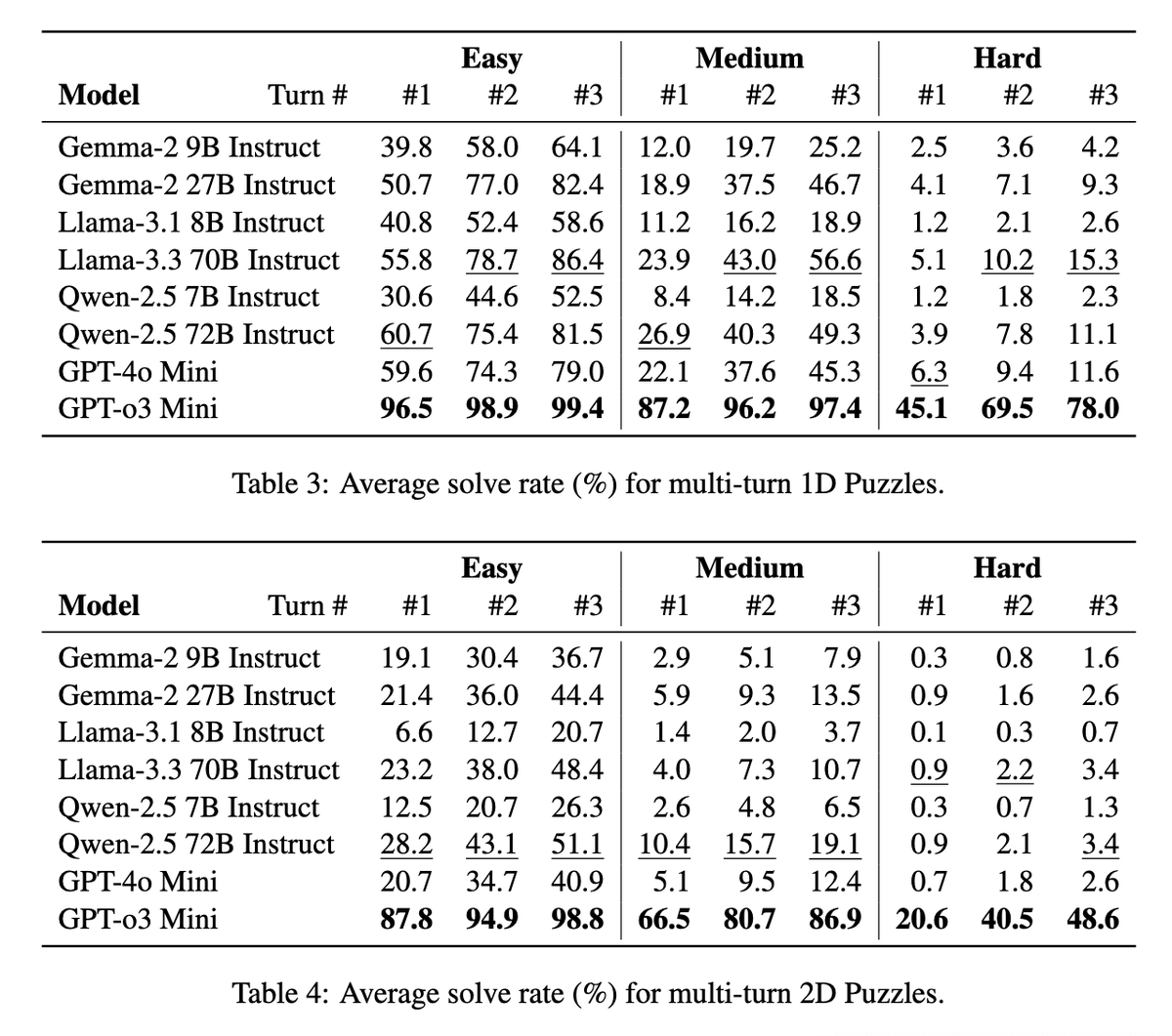
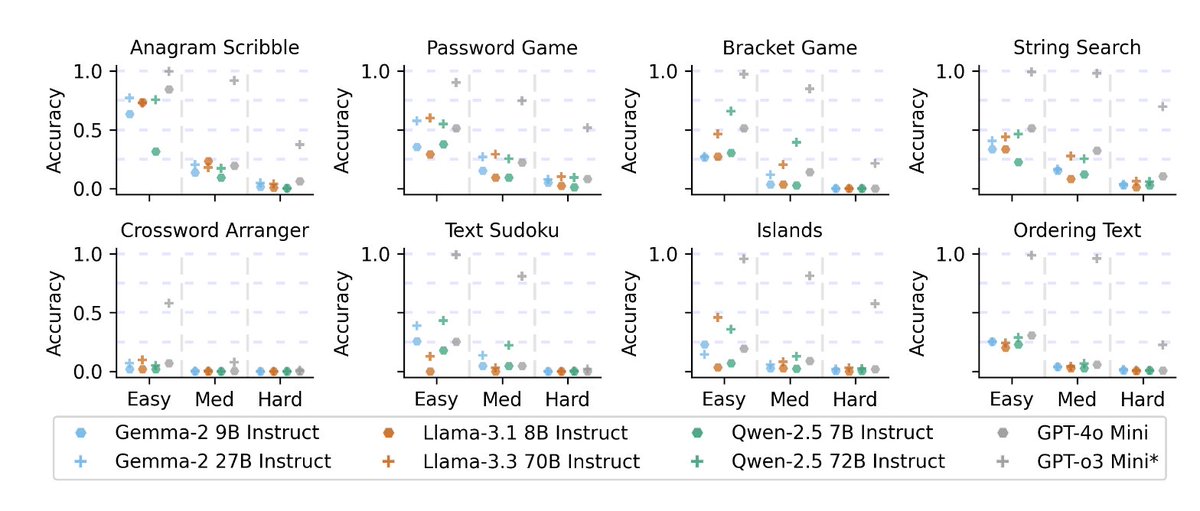
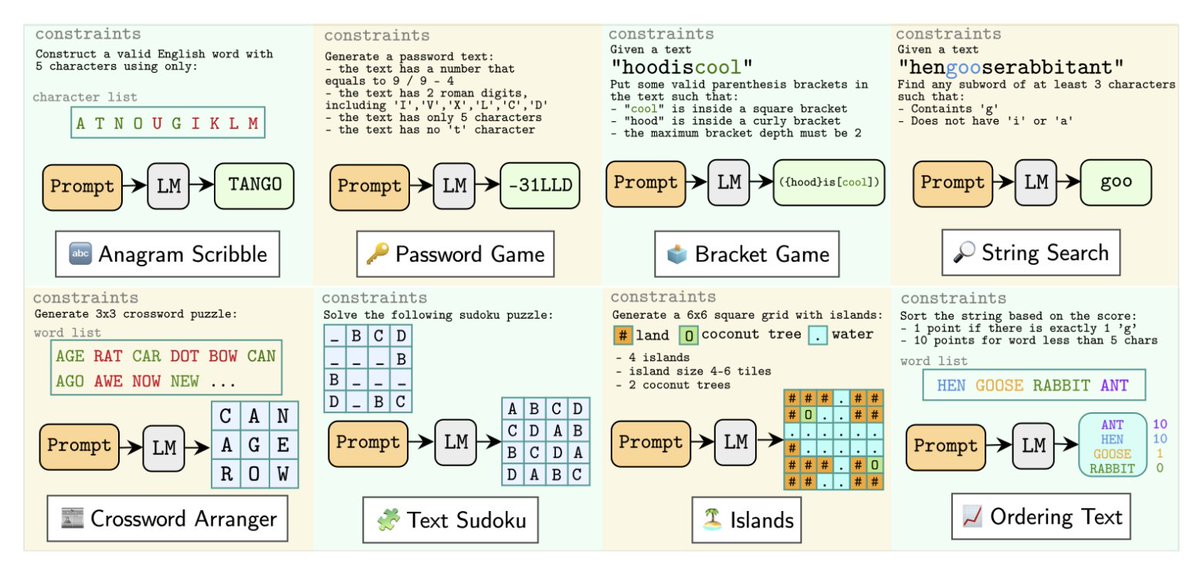
- 𝐓𝟏, a comprehensive multi-turn dataset consisting of 13.5k dialogues designed to evaluate tool using, LLM-based agents across nine key domains. The dataset covers a wide range of interaction scenarios, including single-domain, mixed-domain, and fully multi-domain conversations. It incorporates 14 distinct tools, enabling realistic and fine-grained assessment of agent capabilities in complex, tool-driven dialogue tasks.
- Cross-domain tasks and interdependent tool calls within the dataset to increase complexity and realism of the dataset, requiring agents to reason about tool selection and execution order within context.
- 𝐓𝟏-𝐀𝐆𝐄𝐍𝐓, An LLM based code-generation system, built on open-source language models and equipped with a caching mechanism for improved performance. This architecture enables scalable evaluation and provides a robust, efficient framework for tool-using agents.
1
145
18 Sep 2025
Key Highlights:
- 𝐓𝟏, a comprehensive multi-turn dataset consisting of 13.5k dialogues designed to evaluate tool using, LLM-based agents across nine key domains. The dataset covers a wide range of interaction scenarios, including single-domain, mixed-domain, and fully multi-domain conversations. It incorporates 14 distinct tools, enabling realistic and fine-grained assessment of agent capabilities in complex, tool-driven dialogue tasks.
- Cross-domain tasks and interdependent tool calls within the dataset to increase complexity and realism of the dataset, requiring agents to reason about tool selection and execution order within context.
- 𝐓𝟏-𝐀𝐆𝐄𝐍𝐓, An LLM based code-generation system, built on open-source language models and equipped with a caching mechanism for improved performance. This architecture enables scalable evaluation and provides a robust, efficient framework for tool-using agents.
103
Genta Winata retweeted

This year MRL is also accepting papers that have been submitted to ARR and have received reviews and a metareview! Submit your papers by September 23rd! See the workshop website for details on how to submit ⬇️
1
3
4
716
Genta Winata retweeted

13 Aug 2025
Submit to our workshop to win paper awards 🏆 and free tickets 🎫 by 8/22!

🚀 Still have a chance to submit to @NeurIPSConf for our Multi-Turn Workshop!
🏆 Best Paper Awards
🎓 10-15 Registration Waivers for student authors
🎤 New panelist: @willccbb from @primeintellect!
⏳ Deadline is August 22—only 10 days left!
🎉 Thanks to our sponsor @OrbyAI!
We also invite you to become a reviewer and help shape the future of multi-turn research! Links for submission and reviewer sign-up are below. 👇
#NeurIPS #Agents #MultiTurnAgenticRL #MultiTurnAlignment #CallForReviewers

1
8
29
5,696