
22 Photos and videos


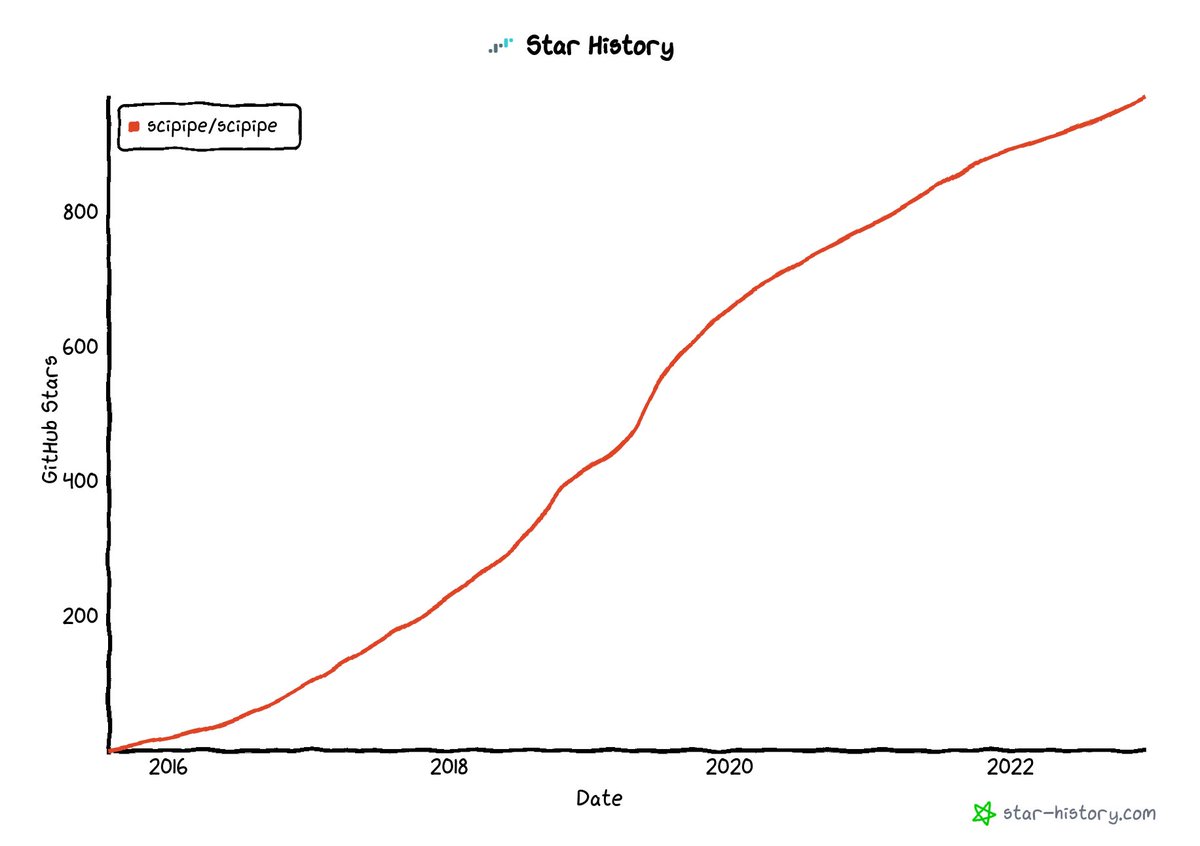







Paper out on the work done at NASA Glenn Research Center, using @scipipe for orchestration and #provenance tracking: bionics.it/posts/scipipe-at-…
1
1
119
The link to the post is unfortunately broken now, but it is now available at livesys.se/posts/scipipe-at-…

Paper out on the work done at NASA Glenn Research Center, using @scipipe for orchestration and #provenance tracking: bionics.it/posts/scipipe-at-…
38
SciPipe retweeted

24 Mar 2025
19 Nov 2024

An Empirical Investigation on the Challenges in Scientific Workflow Systems Development. arxiv.org/abs/2411.10890
1
1
80
SciPipe retweeted

8 Sep 2024
It is mostly about how tasks are generated by a workflow system. In pull based systems, the outputs invoke the steps by dependency matching (e.g make). In push based (dataflow) systems, the inputs trigger the cascade. (for ref : academic.oup.com/gigascience…)
1
2
52
SciPipe retweeted
15 May 2024
🧬 Why didn't Go break into Bioinformatics on a large scale, when it has had a phenomenal growth outside the field? 🧬
I wrote a short post on this question and on using #golang for #bioinformatics in general 👇
bionics.it/posts/golang-for-…
4
16
53
6,490
"Towards Maintainable and Explainable AI Systems with Dataflow"
Interesting PhD Thesis by Andrei Paleyes at @Cambridge_Uni using SciPipe for its analysis. Topic at the heart of SciPipe's motivation too: Handling complex #machinelearning #sciworkflows! repository.cam.ac.uk/items/5…
1
1
106
SciPipe retweeted
13 Apr 2024
Fun to see @scipipe being used at @NASAglenn in a new paper in @npj Microgravity: bionics.it/posts/scipipe-at-…
1
1
1
126
Happy to see SciPipe having been used in this study: "Causal fault localisation in dataflow systems" dl.acm.org/doi/10.1145/35783…
#dataflow #sciworkflows
2
3
217
SciPipe retweeted

27 Aug 2023
Gonomics: Uniting high performance and readability for genomics with Go | Bioinformatics | Oxford Academic academic.oup.com/bioinformat…
22
94
22,344
Exciting to see more work on using #golang in #bioinformatics: "Gonomics: Uniting high performance and readability for genomics with Go" academic.oup.com/bioinformat…
1
45
SciPipe retweeted

19 May 2023
scipipe: Robust, flexible and resource-efficient pipelines using Go and the commandline
⭐️ 998
#golang
github.com/scipipe/scipipe
1
5
14
2,660
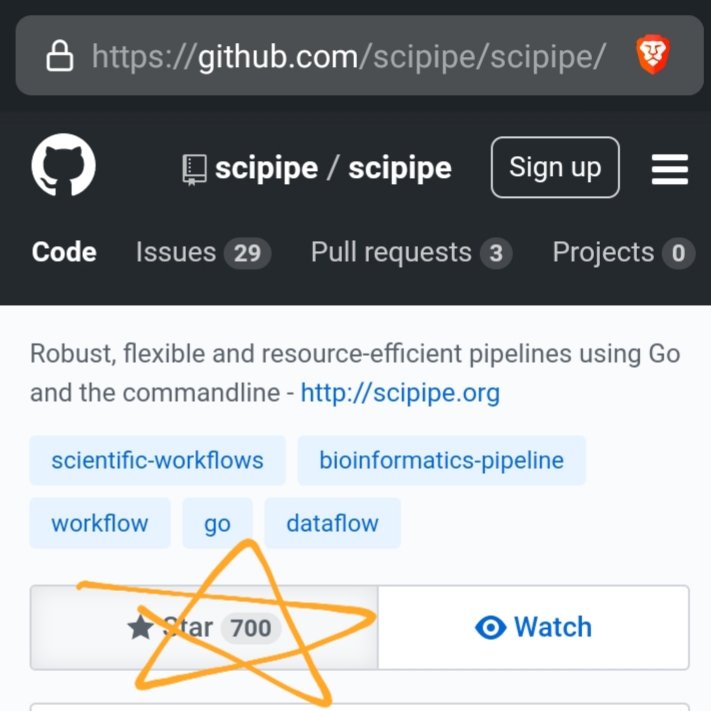
Wohoo! We're happy to see that we just reached 1000 @github ⭐️:s! Thank you all for the support! 🤩 And... expect some work on fixes and improvement in the summer! #sciworkflows github.com/scipipe/scipipe
1
2
119
17 Mar 2023

Looking for #Bioinformatics courses on #GitHub? 🧐 You're in luck! 🍀@choup @P_Palagi and I from @ISBSIB have created #Glittr (glittr.org): a webapp that helps you find and compare awesome training materials. 🎉
How does it work? And how can you join us? Read on! 👇
41
SciPipe retweeted

3 Apr 2023
✨The report for the Workflows Community Summit 2022 has been published: doi.org/10.5281/zenodo.77506…
#SciWorkflows #workflow #HPC #AI #FAIR #QuantumComputing #Science

1
5
244
We're glad to see SciPipe being used to explore properties of #dataflow in this nice paper by Andrei Paleyes & Neil Lawrence @lawrennd
It makes a strong case for how the #dataflow paradigm adds key causal info already at the design stage #sciworkflows
arxiv.org/abs/2304.11987
2
2
110
SciPipe retweeted

28 Apr 2023
“We've generated a humongous amount of data and it's available for everybody in the world” says @KltLab, after analyzing genomes of 240 mammals, in international research project led by @UU_University and @broadinstitute in collaboration with SciLifeLab.
scilifelab.se/news/scilifela…
2
9
15
3,472
SciPipe retweeted

13 Apr 2023
I have found my people. 🥹 What an exciting initiative by @WorkflowsCI!
workflows.community
2
11
2,106
Retweeting these news about our older cousin SciLuigi 😉 #sciworkflows

🎉 Hooray, after learning it is still used at some major companies, I just pushed a new release of SciLuigi [1] tonight, for the first time in ~3 years 🎉
github.com/pharmbio/sciluigi…
[1] Wrapper around @bernhardsson's Luigi, allowing dep defs outside of tasks & more #sciworkflows
1
1
161