
Founding member and leading the foundation models team @sarvamai.
Joined August 2009
- Tweets 2,136
- Following 325
- Followers 4,639
- Likes 6,417
157 Photos and videos












Rahul retweeted

Jun 10
HISTORY LESSON: In 1968 the US, USSR, UK, France, and China signed the Nuclear Non-Proliferation Treaty, declaring nuclear weapons too dangerous for any more countries to build. All five already had them. Everyone else had to submit to inspections while the cohort pinky-promised to disarm eventually (they didn't lol). India refused to sign, pointing out the NPT didn't decide nukes were too dangerous to exist, just too dangerous for anyone who didn't have them by 1967. Anthropic sabotaging Claude for anyone building what they deem a "frontier model" is the same hypocrisy. The danger started, conveniently, the day after they finished.
Perhaps @dwarkesh_sp was more on point when he compared GPUs to nuclear bombs.
When Fable 5 is used for frontier LLM development, it does not notify the user and instead limits the model’s capabilities through methods such as prompt modification, steering vectors, and PEFT.
Anthropic estimated that this would affect approximately 0.03% of traffic.

34
123
886
197,730
Rahul retweeted

May 28
The HF science team just made async RL weight sync ~100x cheaper on bandwidth, and you don't need a shared cluster anymore.
The problem: every RL step, the trainer typically has to sync fresh weights to the inference engine. for a 7B in bf16 that's ~14GB. for a frontier 1T fp8 checkpoint, that's ~1TB; in bf16 it would be ~2TB. per sync.
The insight: between two RL steps, ~99% of bf16 weights are bit-identical. at RL learning rates, the optimizer is whispering and bf16 literally cannot hear most of it. the stored bf16 bits don't change.
What they shipped in TRL: only the changed elements get encoded as a sparse safetensors file, dropped into a Hugging Face Bucket, and fetched by vLLM. on Qwen3-0.6B, per-step payload goes from 1.2 GB to 20 to 35 MB. This is exactly what we built Buckets for: S3-like object storage on the Hub, Xet-backed (so even full snapshots only transfer the changed chunks).
The cherry on top: we ran a FULL disaggregated training where:
- the trainer lived on one box
- vLLM ran inside a Hugging Face Space
- the Wordle environment ran in another Space
- weights flowed through one Hub bucket
no shared cluster. no RDMA. no VPN. no NCCL across clouds. just HTTPS and a bucket.
one GPU a Hugging Face account is now enough to do real disaggregated RL. multi-replica inference fleets across regions become a small devops exercise, not a research project.
Full write-up: huggingface.co/blog/delta-we…
Open source RL keeps eating the moat!

29
70
596
63,371

May 21
Kudos to @VinayakGavariya and team!

We're now a community of 10,000 builders strong on Discord.
This is where developers, founders, and builders come together to build with Sarvam and shape the future of AI for India.
Thank you for showing up, building in the open, and making this community what it is.

2
7
540
May 20
These guys got game.

2
6
686
May 20
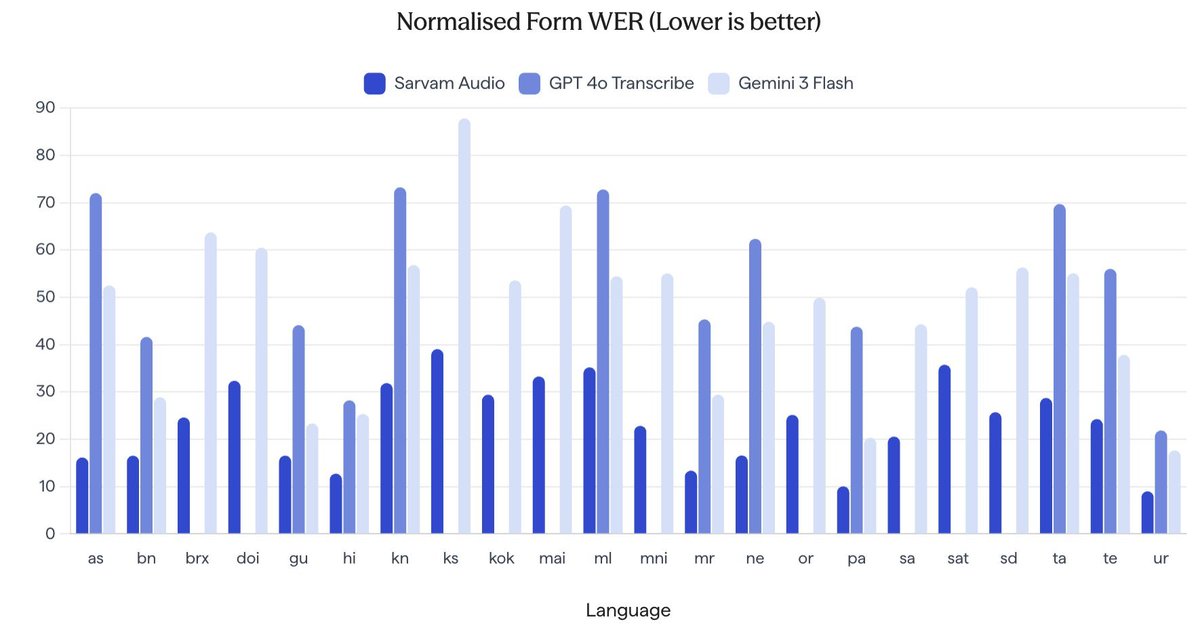
The ASR team has done some tremendous technical work in the past few months (see sarvam.ai/blogs/asr)
If you want to learn more or have questions for the team, this is your chance.

We're hosting a webinar on Saaras V3, our speech-to-text model for teams building Voice AI for India.
Date: Thursday, May 21
Time: 5:00 PM IST
In this session, we'll break down what it takes to ship Voice AI that works reliably across noisy environments, regional accents, mixed-language speech, and multiple speakers.
Register here: links.sarvam.io/speech-to-te…

1
26
1,219

May 4
First step towards a Dyson sphere 😉
We are excited to announce that Sarvam is partnering with @PixxelSpace to power the AI backbone of India's first orbital data centre satellite.
This is a first for the country, with India-built AI models running on an India-built satellite and both training and inference happening directly in orbit, without any dependence on foreign cloud or ground infrastructure.

8
2
219
7,819
Rahul retweeted

Apr 19
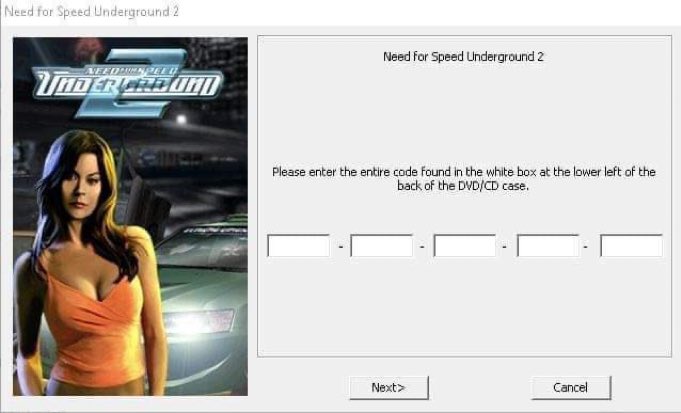
For a decade, we've made models wider and deeper—but we've barely changed how layers *talk* to each other.
Since ResNet's `x F(x)` in 2015, the depth residual has been the only highway for inter-layer communication.
It's time to upgrade the staircase. 🧵
18
239
1,939
188,434
Apr 17
Fun fact: when neo and trinity are grabbing guns for their heist, you can actually see the the mic capturing their dialogue 😅
Apr 17

Imagine sitting in a theatre in 1999 & seeing this for the first time.
395
Apr 16
SkyRoads
Apr 16

For anyone who used a computer between 1990 & 2005… what’s the one game you still think about?
4
271
Rahul retweeted

Apr 12
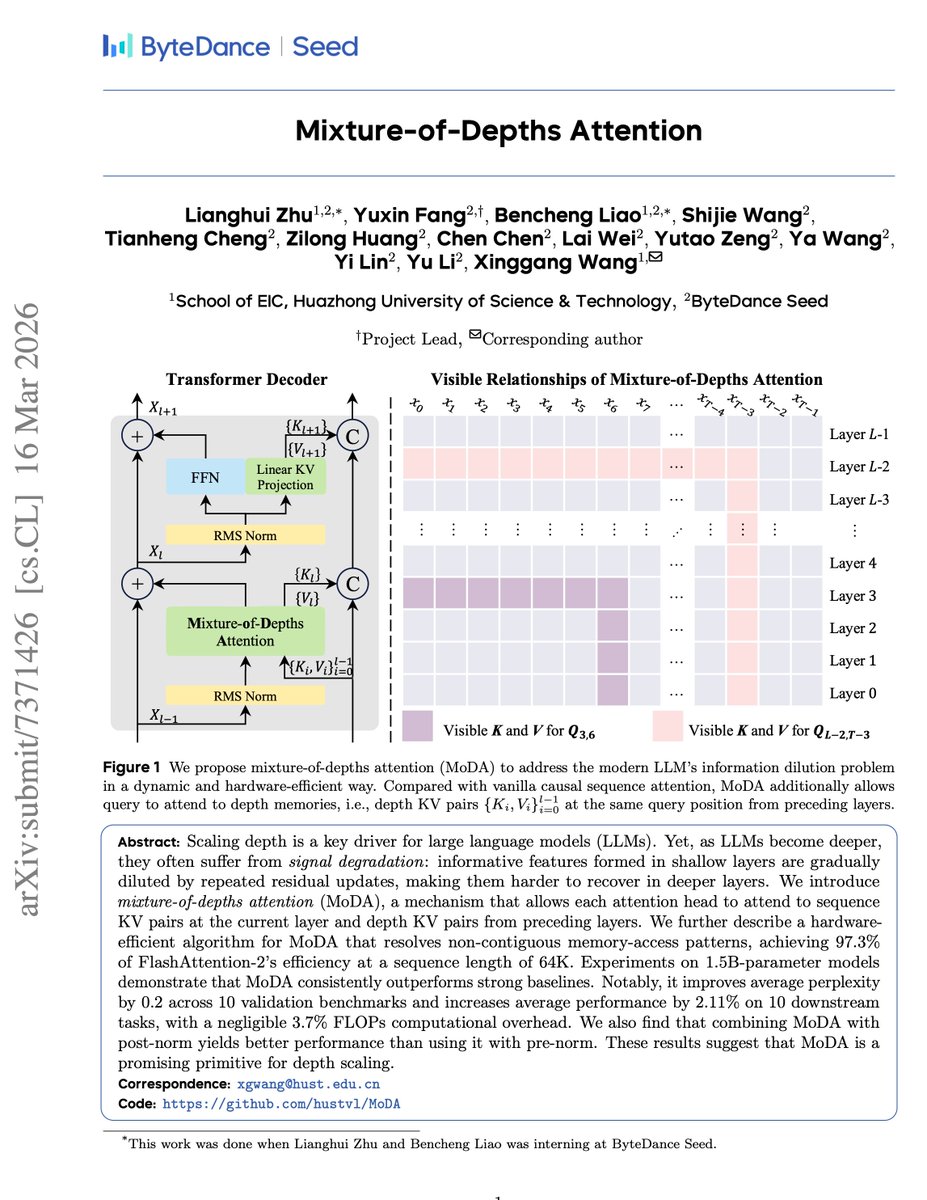
On-policy distillation with 100B teacher models is now possible in TRL, and up to 40x faster than naive implementations!
We distilled Qwen3-235B into a 4B student and gained 39 points on AIME25. Two engineering optimizations made it work.
Blogpost: huggingface.co/spaces/Huggin…
4
64
350
28,000
Apr 12
This is true. Modern religion absolutely uses gods as a gap-filler. But in Hinduism, there has always been deeper philosophical thought. And the gap-filling has been done in an amazing way, where our philosophers arrived at remarkably abstract conclusions through pure philosophical reasoning. And we can easily retrofit concepts of modern science into it.
Stage 1: We questioned our own Gods
The Rigveda's Nasadiya Sukta (Rigveda 10.129) is arguably the world's first agnostic cosmological text. It doesn't say "Indra created everything." It says:
नासदासीन्नो सदासीत्तदानीं नासीद्रजो नो व्योमा परो यत्।
किमावरीवः कुह कस्य शर्मन्नम्भः किमासीद्गहनं गभीरम्॥
"Neither non-existence nor existence was there then. Neither the realm of space nor the sky beyond. What stirred? Where? In whose protection? Was there water, unfathomably deep?"
को अद्धा वेद क इह प्र वोचत् कुत आजाता कुत इयं विसृष्टिः।
अर्वाग्देवा अस्य विसर्जनेनाथा को वेद यत आबभूव॥
"Who really knows? Who will here proclaim it? Whence was it produced? Whence is this creation? The gods came afterwards, with the creation of this universe. Who then knows whence it has arisen?"
This is the Rigveda itself saying: the gods don't know either, and an acknowledgment that the origin of existence exceeds all gods and all human comprehension.
Stage 2: We replaced gods with an abstract entity
By the time the Upanishads came around, we had an answer. Uddalaka Aruni teaches his son Svetaketu about an impersonal, all-pervasive being:
सदेव सोम्येदमग्र आसीदेकमेवाद्वितीयम्।
"In the beginning, my dear, this was Being alone, one only, without a second." (Chandogya Upanishad 6.2.1)
No Vishnu. No Brahma. Just Sat, pure existence, undifferentiated.
Then comes the famous:
तत्त्वमसि श्वेतकेतो।
"That thou art, Svetaketu." (Chandogya Upanishad 6.8.7)
The substance that constitutes the cosmos is the same substance that constitutes you. Note that this is millennia before we knew about the big bang. We are getting glimpses of what will eventually become Advaita philosophy. Everything is one, but acting as the observer and the observed.
Stage 3: We made the entity into something more pervasive
The Mundaka Upanishad describes Brahman in terms that sound eerily similar to various fields of the Standard Model.
ब्रह्मैवेदममृतं पुरस्तात् ब्रह्म पश्चात् ब्रह्म उत्तरतो दक्षिणतश्चोत्तरेण।
अधश्चोर्ध्वं च प्रसृतं ब्रह्मैवेदं विश्वमिदं वरिष्ठम्॥
"Brahman alone is all this immortal being, in front, behind, to the right and the left, below and above. Brahman alone is all this universe, the supreme." (Mundaka Upanishad 2.2.11)
We move from a person-god / entity to a kind of field: omnidirectional, all-pervasive, constituting everything.
The Mandukya Upanishad actually opens with:
ॐ इत्येतदक्षरमिदं सर्वं तस्योपव्याख्यानं भूतं भवद् भविष्यदिति सर्वमोंकार एव।
यच्चान्यत् त्रिकालातीतं तदप्योंकार एव॥
"OM; this syllable is all this. All that is past, present, and future, all of it is OM. And whatever transcends the three times, that too is OM." (Mandukya Upanishad 1.1)
Stage 4: We finally described how multiplicity arises from unity
The Upanishads talk about the actual act of creation in a very interesting way. Not as a god making things, but as a single consciousness differentiating itself. Though the Aitareya says:
आत्मा वा इदमेक एवाग्र आसीत्। नान्यत्किञ्च मिषत्।
स ईक्षत लोकान्नु सृजा इति॥
"In the beginning, this was the Self alone. Nothing else existed. It thought: 'Let me now create the worlds.'" (Aitareya Upanishad 1.1.1)
The act of creation itself is the Self splitting into Prakriti, which fills up the universe. But this splitting does not deplete the Self. As the Isavasya Upanishad says
पूर्णमदः पूर्णमिदं पूर्णात्पूर्णमुदच्यते।
पूर्णस्य पूर्णमादाय पूर्णमेवावशिष्यते॥
"That is whole. This is whole. From wholeness, wholeness proceeds. Taking wholeness from wholeness, wholeness alone remains."
The Mundaka puts it very nicely:
यथोर्णनाभिः सृजते गृह्णते च यथा पृथिव्यामोषधयः सम्भवन्ति।
यथा सतः पुरुषात्केशलोमानि तथाऽक्षरात्सम्भवतीह विश्वम्॥
"As a spider spins and withdraws its thread, as plants grow from the earth, as hair grows from a living person, so from the Imperishable, this universe arises." (Mundaka Upanishad 1.1.7)
It is basically saying the universe emerges from Brahman the way a web emerges from a spider. The substance of creation is not separate from the creator. The spider doesn't use external material; it produces the web from itself.
You can draw parallels to the quantum field theory: Purusha is the field. Prakriti is the field in excitation. The particles, forces, and structures of the universe are not separate from the field; they are the field, vibrating. And when those excitations cease, the field remains; whole, unchanged, exactly as it was.
To conclude, it is fascinating to me that modern science and these ancient dharmic thinkers were asking the same question: what is the fundamental nature of reality? Science uses mathematics and experiment. Our philosophers used pure reason and introspection. They arrived at surprisingly similar answers. Make of that what you will.
Apr 6

Humanity creates GOD whenever science can't explain. Sun God,Rain God etc were created because anchestors didn't know how they worked . Now some people believe Vishnu or Allah created Big Bang because Science can't explain how big bang happened.
2
11
87
5,651
Apr 10
अहमेवासमेवाग्रे नान्यद्यत्सदसत्परम् ।
पश्चादहं यदेतच्च योऽवशिष्येत सोऽस्म्यहम् ।।
Before creation, only I existed. After destruction, only I remain. All that appears, moving or still, is essentially My form.
Apr 10

As a Hindu, I believe the entire Universe is the manifestation of the Divine. All of it - the river, the tree, the snake, the stone, the earthworm, the cow, the monkey, the elephant - all of it is divine manifestation. That belief is not Demonic, it is not Satanic, that is the path to living in harmony with nature and with other human beings.
Arrogant, intolerant monotheism - see the video below - that goes around labeling reverence for all of nature as "demonic" and "satanic"- that belief is what makes men do evil.
History supplies ample evidence. Hindus did not run crusades. Hindus did not burn witches at the stake. Hindus did not invade nations and enslave people in the name of bringing "Civilization" and "God" to "pagans".
1
3
21
995
Apr 7
"Did you put your name in the Goblet of Fire, Harry?" Dumbledore said calmly.
Apr 6

Why are they remaking Harry Potter when there's no problem with the current movies?


1
17
1,071
Rahul retweeted

India enters the open-weights AI race with its largest models pre-trained from scratch: Sarvam 105B and Sarvam 30B
@SarvamAI's Sarvam 105B and Sarvam 30B score 18 and 12 on the Artificial Analysis Intelligence Index respectively. Announced at the India AI Impact Summit 2026 and open-sourced under Apache 2.0, both are Mixture-of-Experts models trained entirely in India using compute provided under the IndiaAI Mission (@OfficialINDIAai). Both support reasoning and non-reasoning modes.
These are an improvement from Sarvam's previous model, Sarvam M (8 on Intelligence Index, 23.6B parameters), which was based on Mistral Small rather than pre-trained from scratch. Sarvam 105B has 106B total parameters with ~10B active per token and a 128K context window. Sarvam 30B has 32B total parameters with ~2.4B active per token and a 65K context window. Alongside the text models, Sarvam also announced Saaras v3 (Speech to Text) and Bulbul v3 (Text to Speech) with a focus on Indic languages.
Key takeaways in reasoning mode:
➤ Sarvam 105B scores 18 on the Intelligence Index. Among ~100B-class open-weights reasoning models, it trails GLM-4.5-Air (23), INTELLECT-3 (22), Mistral Small 4 (27), and gpt-oss-120B (High, 33). All four peers also activate more parameters per token
➤ Sarvam 30B scores 12 on the Intelligence Index. Among ~30B-class open-weights reasoning models, it trails GLM-4.7-Flash (30), Nemotron Cascade 2 30B A3B (28), Qwen3 30B A3B 2507 (22), and Qwen3 32B (17). Sarvam 30B activates fewer parameters than these peers.
➤ Sarvam 105B's relative strength is in select agentic tasks. Its agentic index of 25 places it ahead of INTELLECT-3 (20) and GLM-4.5-Air (21) despite trailing both on overall intelligence. Its GDPval index of 773 also edges ahead of GLM-4.5-Air (665). Both new models are a large step up from Sarvam M (Reasoning), which scored 8 on the Intelligence Index.
➤ Compared to peers, both models score lower on TerminalBench Hard (Agentic Coding & Terminal Use) and AA-Omniscience. Sarvam 105B scored 1.5% and Sarvam 30B scored 2.3% on TerminalBench Hard, compared to GLM-4.5-Air (20.5%) and INTELLECT-3 (9.1%). The AA-Omniscience Index is -60 for Sarvam 105B and -72 for Sarvam 30B. Both models have high hallucination rates relative to their accuracy, and both attempt to answer far more questions rather than abstaining, which drives the negative scores.
Key model details:
➤ Modality: Text input and output only.
➤ Context window: 128K tokens (Sarvam 105B) and 65K tokens (Sarvam 30B).
➤ Pricing: Currently free on Sarvam's first-party API.
➤ License: Apache 2.0.
➤ Availability: Sarvam's first-party API; weights available on @huggingface and AIKosh.

12
39
383
26,163
Apr 2
Please tell me this is a joke.
Apr 2

JUST IN: Artemis II crew experiences issues with Microsoft Outlook on their way to the Moon, asks ground crew for assistance.
3
416
Apr 1
And the datacenter has "zero cooling cost" because it is submerged inside the Pangong lake.

OpenAI raises $122 billion to open its first training datacenter in India
- All models serving Indian audience will be trained locally by Indian scientists.
- All Indian user data will stay within India.
First 'zero cooling cost' datacenter to open in Ladakh where servers will be naturally cooled for 8 months a year
2
1
51
4,922
Rahul retweeted

Releasing Sarvam-30B & Sarvam-105B in FP8
FP8 quantization via ModelOpt PTQ.
Weights quantized to FP8, KV cache scales calibrated so the serving engine stores KV in FP8 at runtime.
~50% memory reduction vs BF16, meaningfully faster inference, minimal quality loss.
Available on HuggingFace:
Sarvam-30B FP8: huggingface.co/sarvamai/sarv…
Sarvam-105B FP8: huggingface.co/sarvamai/sarv…
9
37
322
12,202
Mar 24
❤️


4
333