
A SaaS-preneur chasing dollars by day, sneaking out of my cave occasionally to teach, and secretly indulging in my gacha addiction (shhh, don't tell my wife!)
Joined May 2008
- Tweets 791
- Following 261
- Followers 217
- Likes 199
54 Photos and videos







Jun 1
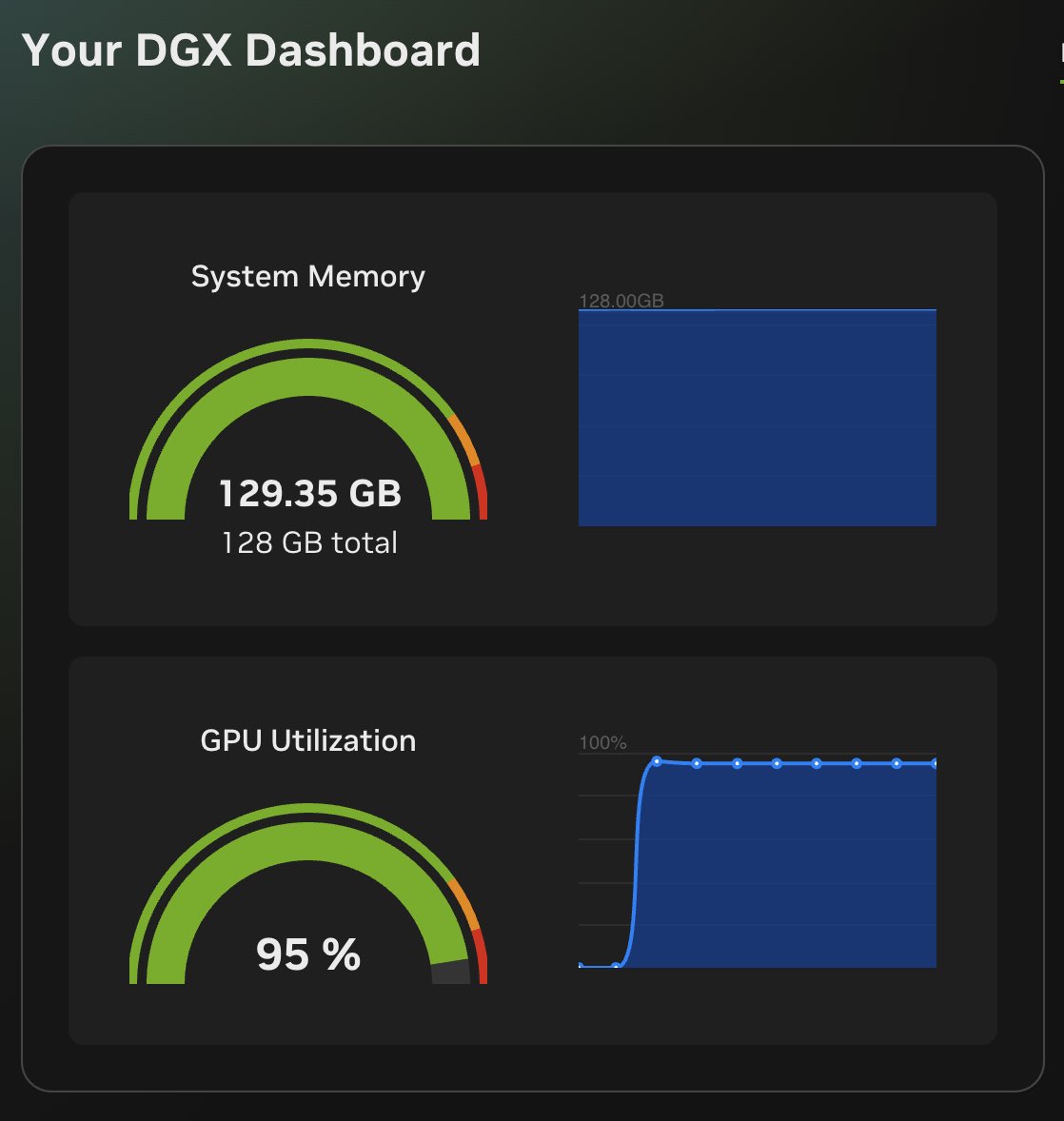
First time benchmarking rust-based inference engine by atlas (@AtlasInference)
Model tested:
Qwen3.6 27B FP8 with MTP enabled
Things noted:
- startup speed, OMG, it's much much faster than other inference engines I've tried!
- token generation speed is great but I think it can be faster, let me play with it more and will keep this posted
- memory consumed more than vllm, probably the default KV cache is 16bit?
- crashed with long context input, yes, it crashed my DGX Spark and force shutdown without a reboot 😭
Anyway, i think the future is quite interesting for this inference engine, will playing more with it!
2
7
400
May 30
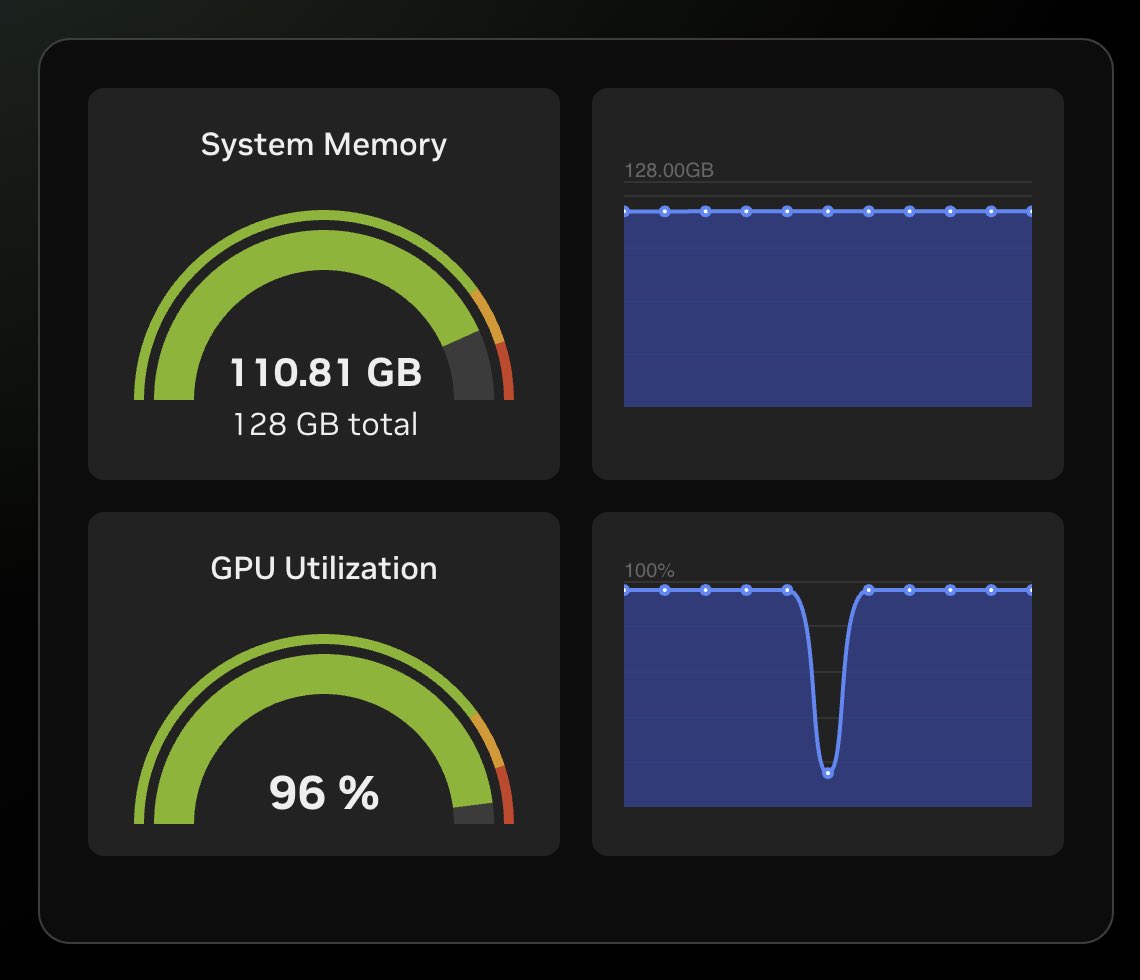
Wait, my DGX Spark was cooked! 🔥🔥🔥

1
74
May 28
It's NOT about not having enough compute.
It's about what we're WASTING on the harnesses!
We desperately need smarter harness optimization, not just throwing more power at the problem!
#AITalks
2
36
May 27
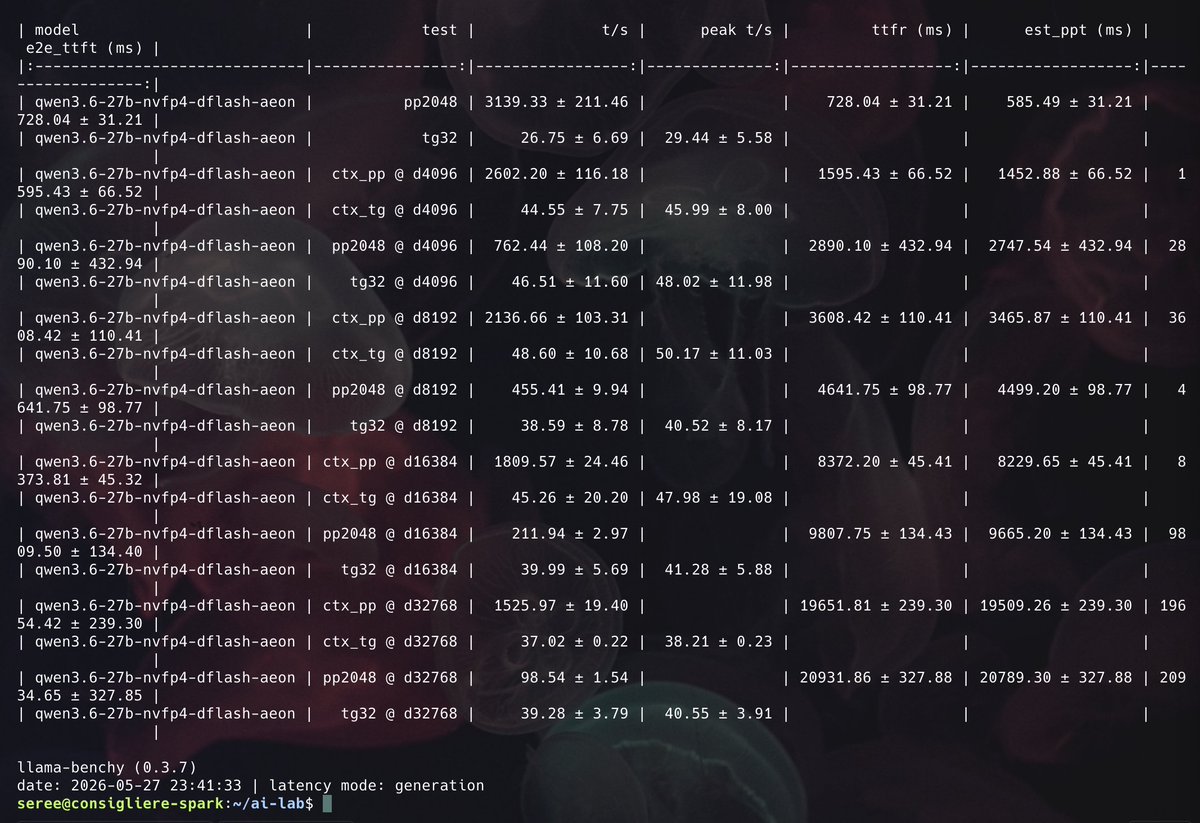
AEON Ultimate Qwen3.6 27B NVFP4 DFlash - benchmarked!
Quite nice speed compared to the base model or even the MTP one. 🔥🔥
#DGXSpark
2
171
May 27
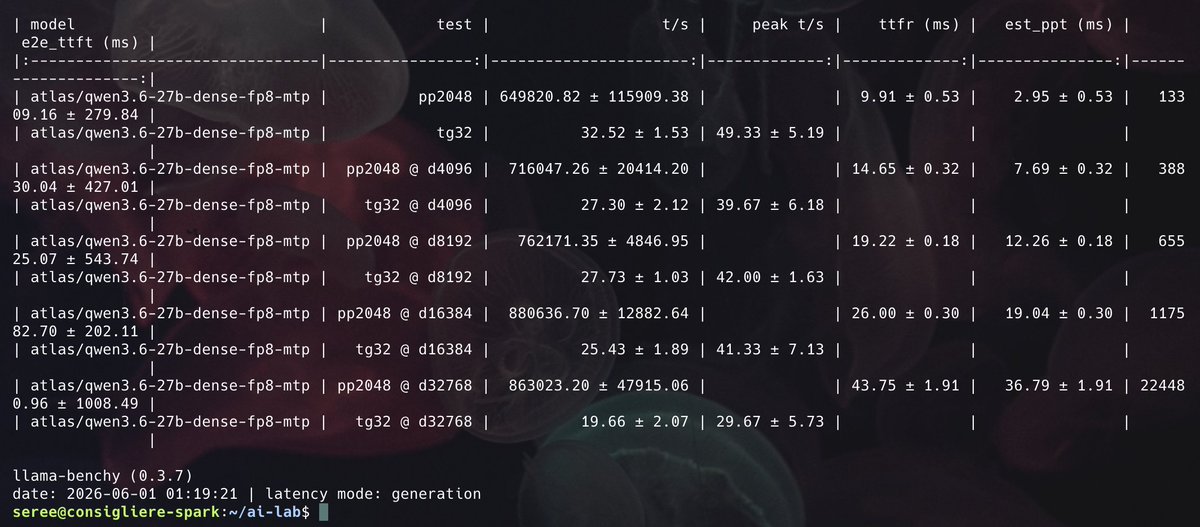
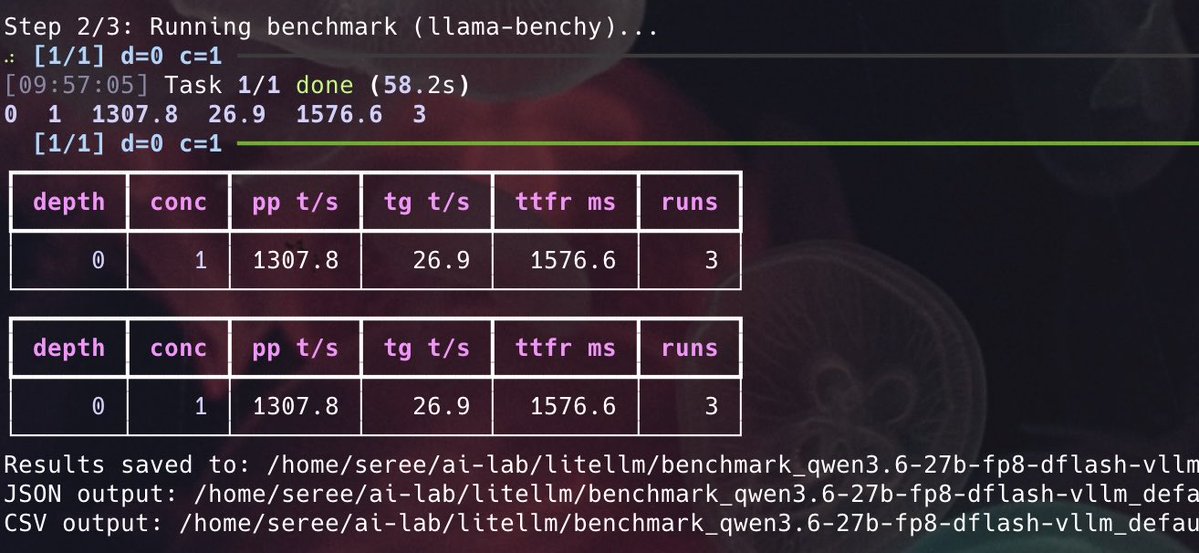
Benchmarking the famous Qwen3.6 27B FP8 DFlash on my DGX Spark.
Speed boosted from 16.2 tps (MTP) to 26.9 tps (DFlash). 🔥🔥
Now testing with OpenCode to see if it will broke at tools calling or not.
Will try AEON’s NVFP4 DFlash version very soooooon!
1
1
3
257
May 13
Invested 3 days to build AI-ready infrastructure for our new business unit.
The rest will be much easier, less token consumption, very high brand consistent and less human-in-the-loop works.
Believe the Yoda, first structuring, your best padawans, the AI will be!
1
23
Apr 17
Last feel years, I feel great when I turn on my Windows device just to run Windows Updates.
Now?
I feel even greater when I turn any of my Windows/MacOS devices just to click on "Relaunch to update" button in Claude Desktop.
It updates even more often than Windows. lol
2
67
Apr 13
Local open-weight models now really good, one shot turn from amateur UI to professional UI.
Can’t wait to crush the store again! @ifourth 🔥🔥🔥
1
2
71
Apr 13
Never expect Qwen3.5 122B on DGX Spark is this smooth for iOS app development!
3
82
Mar 20
ผมคือผู้ผิดหวังจาก Forza Horizon 6
เพราะเกมไม่ดี?? เปล่า…
เพราะกรูดูวันเปิดตัวผิด! เค้าเขียนว่า 19 May ชัดมาก แต่สมองสั่งการเป็น 19 Mar เฉย 😂
แล้วคือรอมาเกือบเดือนอย่างใจจดใจจ่อ 🤣
สงสัยต้องออกจากหน้าคอมบ้างละ! 😤
1
2
74
Mar 11
ข้อความ รูปภาพ วีดีโอ เสียง
ทุกอย่างสามารถ Embed มาเก็บอยู่ในโลกใบเดียวกันได้แล้ว โคตรคูลลลลลล

3
62
Mar 8
เปิดศึก 3 ก๊ก Qwen CLI vs Cline CLI vs OpenCode CLI
ด้านหลังใช้ Qwen3-Coder-Next 80b ตัวเดียวกันรันบน DGX Spark
ใครจะอยู่ ใครจะไป มารอดูหลัง 24 ชม.กันจ้าาาาา
#localLLM #DGXSpark #AICodingAgent
4
4
191
Mar 9
16ชม. ผ่านไป
- DGX Spark ตายหยังเขียด ดับ กำลังหาสาเหตุ ระหว่าง Thermal กับ OOM เหมือนเห็น OOM ใน Log ตอนนี้ปรับ Config ใหม่ให้เหลือ Mem มากขึ้น
- Cline CLI ตอนนี้คือยืนหนึ่งเรื่องบริหารจัดการ Context รันได้ยาวจริงจัง บริหาร Context คอย Compact ได้ดีมาก ไม่มีติดเรื่องนี้เหมือนตัวอื่น
- OpenCode CLI จัดว่าใช้ได้เลย รันยาวได้ดี แต่ไม่ยาวนานเท่า Cline ยังมีติด Context length บ้าง แต่ไม่บ่อยเท่า Qwen CLI
- คืนนี้จะเพิ่ม Pi Coding Agent เข้าไปในการทดสอบต่อ เพราะรักใน Concept เค้ามากๆ
46
Mar 9
อัปเดท 6 ชม.แรก:
- DGX Spark ยังทำงานได้ราบรื่นดี ไม่เจอ OOM
- qwen CLI หยุดทำงาน พัง แต่ไม่ใช่เพราะตัวมันเอง เป็นเพราะผมลืม ไปรัน qwen CLI ผ่าน VibeTunnel และสิ่งที่พังคือ VibeTunnel OOM ทำให้ qwen CLI ต้องหยุดทำงานไปก่อนเพื่อน
- OpenCode CLI หยุดทำงานเป็นตัวที่สอง เพราะติดเรื่อง Context length ไม่สองคล้องกับที่ตั้งค่าไว้ที่ฝั่ง DGX Spark ตอนนี้นั้งค่าให้เหมาะสมแล้วรันต่อละ (เมื่อคืนคือใช้ default settings เลย ซึ่งมันไม่ auto compact)
- เซอร์ไพร์สสุดคือ Cline CLI ตื่นเช้ามายังทำงานอยู่เลย คุณคือผู้รอดตายใน 6 ชม.แรก จงทำงานแบบนี้ต่อไปๆๆๆ
2
95
Mar 8
3
123
Mar 7
หลังจากอยู่กับ qwen3.5 35b มา 24 ชม. ผ่านการใช้งานกับ qwen-code CLI บน DGX Spark…
ตอนนี้ซมซานกลับไปหา qwen3-coder-next 80b เรียบร้อย 😂😂
สิ่งที่สัมผัสได้
- qwen3.5 35b ทำ reasoning/thinking ได้ค่อนข้างดีมาก ดูจาก CoT แล้วดีกว่า qwen3-coder-next แน่นอน
- qwen3.5 35b สะดวกดีเพราะเป็น multi modal
- ปัญหาเดียวเลยคือ qwen3.5 35b มันไม่ได้ถูกเทรนมาให้ทำงานแบบ Agentic coding loop คือพอเอาไปใช้กับ CLI แล้วมันจะไม่ค่อยสั่ง tools calling ต่อ ค้างไปดื้อๆเลย
ตอนนี้เลยต้องกลับมาใช้ qwen3-coder-next 80b ในการทำงานเขียนโค้ด
เอาเป็นว่า ถ้า qwen3.5-coder-next ออกมาเมื่อไหร่ จะมาทดสอบอีกที
ปล. แต่ Container ของ qwen3.5 35b ก็ยังเก็บไว้ใช้กับ Open WebUI นะ เพราะชอบ Reasoning ของมันมากๆ ทำ Swap เวลาใช้งานเอา 👌👌
#DGXSpark
3
124