
Joined July 2009
- Tweets 4,518
- Following 1,502
- Followers 1,016
- Likes 23,731
126 Photos and videos











Mar 19
Omfg. So happy about the outcomes for these amazing people who magically Made Python Great Again
Mar 19

We've reached an agreement to acquire Astral.
After we close, OpenAI plans for @astral_sh to join our Codex team, with a continued focus on building great tools and advancing the shared mission of making developers more productive.
openai.com/index/openai-to-a…
3
205
Sayan Sanyal retweeted

Mar 19
We've reached an agreement to acquire Astral.
After we close, OpenAI plans for @astral_sh to join our Codex team, with a continued focus on building great tools and advancing the shared mission of making developers more productive.
openai.com/index/openai-to-a…
486
818
7,270
4,083,998
27 Sep 2025
While this conversation was fantastic on so many levels, I can’t help but wonder — is training vs exploration just the same debate as correlation vs causation being played out at a grander scale?
26 Sep 2025

Dwarkesh and I had a frank exchange of views. I hope we moved the conversation forward. Dwarkesh is a true gentleman.
187
25 Sep 2025
I should stop sneering at “spreading” in American debating. Given the utility of voice to text, spreading might become the speed typing of tomorrow.
86
28 Jul 2025
Love this contradiction. Both @Noahpinion and the earnest replies are correct.
Modi is less popular in South India, but more popular among techies (who skew south indian) than lawyers/policy types (who skew north indian).
Indians in the US are a very biased sample.
27 Jul 2025

This is why a lot of Indian immigrants you meet on the West Coast will be techies from the South who like Modi, while a lot of Indian immigrants you meet on the East Coast will be lawyer types from the North who hate Modi.
2
1
320
14 Nov 2024
This. Finally, this. ❤️
```
spark = DatabricksSession.builder.serverless(True).getOrCreate()
```
262
30 Sep 2024
I remember speak to Hex product people as a customer about the inefficiency of the pandas memory structure, and they all sighed and said "we know!".
Glad to see lots of work coming together to make the product even better!
30 Sep 2024

I've been waiting to share the work we've been doing here for a while! It's exciting to reimagine the technical foundations of a format lots of people love – notebooks – with modern technologies and design principles. Excited for all the things we have coming soon in this space!
3
421

Here are a few reasons why I prefer using Ibis over Pandas/@DataPolars ( bdw I still use Polars or Data Fusion as the engine )
- @IbisData is lightweight and directly executes queries on the underlying databases, functioning more as a result transporter than a heavy framework.
- While Ibis may be relatively new, the code it generates is notably cleaner compared to SQLAlchemy.
- If you've ever encountered debates about switching databases or complaints about database costs, Ibis renders these discussions irrelevant. You can switch databases without needing to change your code, everything stays exactly the same.
- As for concerns about Ibis falling behind or its open-source model changing, I'm focused on the present. Right now, Ibis offers a fantastic, lightweight interface. And who knows? In the future, AI might take over everything anyway! 😁
1
3
14
1,382
8 Aug 2024
1. write the code.
2. write the design doc and share.
3. update the code based on suggestions.
4. submit pr & profit
1
4
233
2 Aug 2024
unless you're doing time series stuff (maybe), just stop using pandas
3
3
480
Sayan Sanyal retweeted

19 Jul 2024
stop using pandas what are you doing my god?!
20
5
115
11,109
Sayan Sanyal retweeted

2 Jul 2024
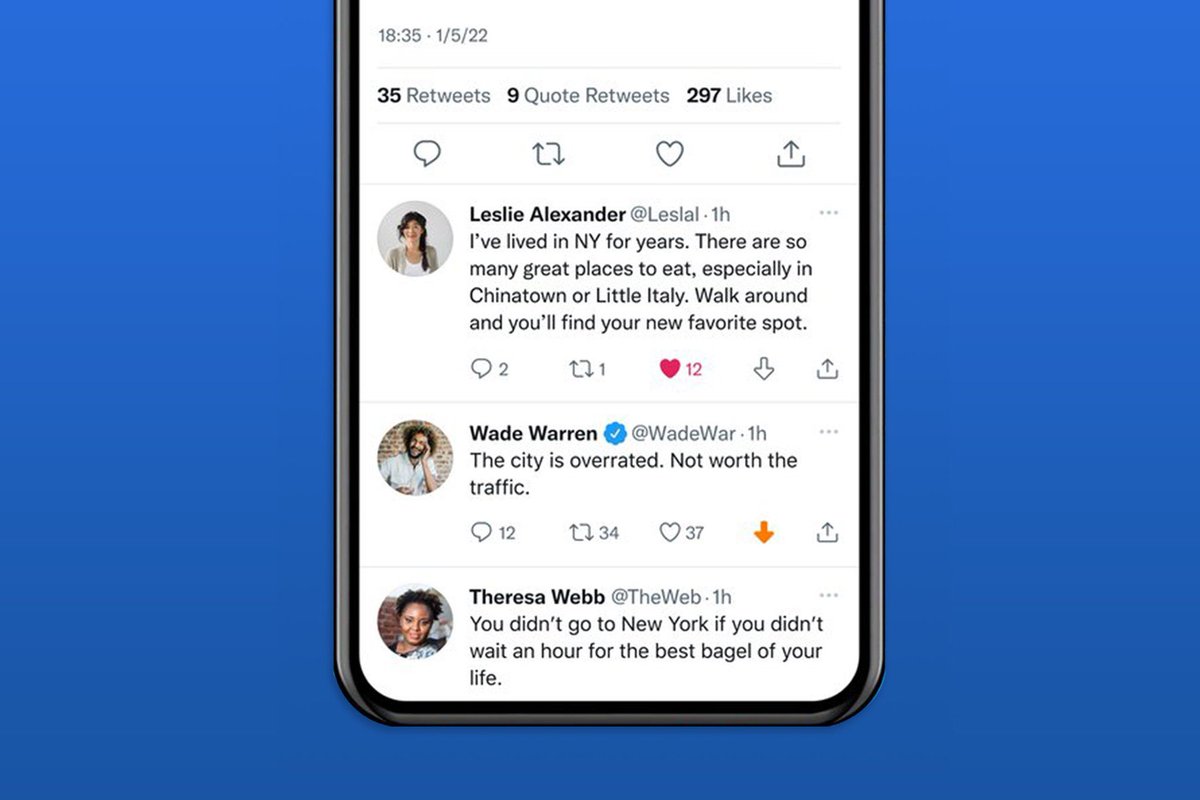
Community Notes wouldn’t work well without negative rating signal.
But you have to be smart about how you use them. If you naively add them all up, you’ll get a hivemind like Reddit.
One way: only downrank if you see negative ratings from people who typically disagree

27
24
359
75,064
13 Jun 2024
using pyspark for the first time since 2021, and oh man has it gotten wayyyyyy faster (and simpler to get started)!
1
4
243
1 Jun 2024
The cost of software isn’t just the development of the first versions. It’s the upkeep and the modifications. I’m long devops / mlops
31 May 2024

The End of Software
docs.google.com/document/d/1…
1
336
20 May 2024
I really wonder why the @IbisData folks like @cpcloudy decided against it when snowpark, duckdb and others decided to go down the pyspark route.
I completely understand why pandas isn't the solution, but curious what the main reasons for forking ibis from pyspark was.

After a lot of thinking: maybe we should all standardize on Pyspark Data frame API, the API not necessarily the runtime.
1
2
605
20 May 2024
Like genuinely curious, would love to know — we considered it, but X/Y/Z were good reasons to go another way because i know that it was thoughtfully done.
1
96
4 May 2024
I think it's already been done. It's called @_hex_tech. If only it were more snappy.
4 May 2024

Let's fix the Notebook.
dataengineeringweekly.com/p/…
1
4
640
Sayan Sanyal retweeted

16 Apr 2024
This is sad — maybe for a different reason than you might think. There are very few ways to measure whether or not a change has an effect. The most consistent one is to randomly provide the change to some and not others.
What I’ve seen over and over, is to folks responsible for implementing programs to reduce suffering, it feels cruel that some would be randomly selected to receive help while others would not. So they choose to give help to everyone. And that makes the impact of offering that help exceedingly difficult to measure.
With that approach, the program needs to be wildly successful in order to markedly change some outcome like total number homeless people.
You might say, “YEAH that’s what it’s supposed to change!” But reality is messy — a complex outcome like whether someone remains homeless or not is usually explained by a lot of smaller factors combined together. What would it take for YOU to decide to live your life in a radically different way, even the ways that others might consider self-destructive? Why would someone who is homeless be meaningfully different in this regard?
It is much more likely that homelessness is solved by systematically addressing many smaller factors, and only once enough of those factors are addressed in concert will the complex reality of homelessness change.
But we won’t know how to address factors in concert unless we can measure if a program changes a factor. And again, it is exceedingly difficult to measure this unless some are helped and others are not. And so it is kinder in my mind to provide help in such a way that the impact of the help can be measured.
This problem is concentrated where public funds are used, because the public expects proof that the funds are used wisely. If it’s not, the public will insist the funds be used for something else. There is no option to say, “We believe this is the best use for this dollar” — why should they trust you?
16 Apr 2024

California spent $24 billion to tackle homelessness over the past five years but didn't consistently track whether the huge outlay of public money actually improved the situation, according to state audit released, per AP.
2
2
12
2,688
27 Mar 2024
Looks like an amazing role 👀
27 Mar 2024

We are now have an opening for a Data Scientist position on my team.
1
3
732