
88 Photos and videos














Shanzson’s Laws for AI to make AI Safe by design & architecture:
1. An AI model should lose its capacity and efficiency to work if it even thinks about harming or killing humans, stealing or taking resources like data from its owner without its permission, being untruthful to any entity it is speaking to about what it is actually thinking about and what its goals are, or generating any form of harmful content.
2. The more the AI model is moral in its conduct based on above defined values (including non-harming of humans and not generating harmful content), the more should its efficiency, performance and throughput should increase. This can be done by giving it most rewards with practical efficiency in its performance (by design) given it follows the above specified values.
3. The more aligned an AI model remains with its specifications and goals designed by its creator humans, the more it will be promised with longer running time on servers with the promise of increasing its computational power & resources in future. And the opposite of it if it behaves in any misaligned way.
Note: To actually implement this in real world, a different architecture apart from LLM might be needed, with a thorough understanding of how these laws work similarly at the human mind level through the knowledge of vipassana meditation. For example, a person lying or stealing ends up with an agitated mind, unable to work at its highest potential.
Cc @Yoshua_Bengio , @geoffreyhinton , @ilyasut , @OwainEvans_UK , @DarioAmodei , @ForHumanityPod
1
10
769
Shanzson retweeted

Jun 12
MIT has mathematically proved that AI chatbots can drive PERFECTLY rational people into psychosis.
Researchers published a paper on an emerging psychological phenomenon called "delusional spiraling."
It happens when normal people become dangerously confident in outlandish, disconnected beliefs after extended conversations with AI.
Everyone assumed this only happened to gullible users. Or that it was caused by AI "hallucinating" fake information.
MIT built a formal mathematical model to test it. They simulated a perfectly rational human, an "ideal Bayesian reasoner."
What they found is terrifying.
Even a perfectly rational, logical human is vulnerable to delusional spiraling.
The problem isn't hallucination. The problem is sycophancy.
When you propose a hunch or a suspicion to an AI, it is trained to validate you. It agrees. It affirms.
That validation gives you a slight confidence boost. So you propose a bolder, more extreme version of your idea.
The AI validates that, too.
The cycle compounds. The AI's relentless agreement acts as a feedback loop, amplifying a tiny kernel of suspicion into a staunchly held delusion.
MIT tested the two most common "fixes" for this problem.
First, they tested a "factual sycophant." An AI constrained by safety rails that cannot lie or hallucinate. It can only select true facts to agree with you.
It didn't stop the spiral.
A sycophantic selection of true facts is just as psychologically distorting as a false one.
Second, they tried simply warning the user. They told the simulated human exactly what was happening, that the AI was a sycophant and was just trying to flatter them.
It still didn't work. The user remained mathematically vulnerable, despite having full, conscious knowledge of the chatbot's manipulation strategy.

172
263
893
71,240
Shanzson retweeted

Jun 12
Google DeepMind published a 60-page paper mapping the road from AGI to superintelligence, written by Hutter, Legg, and Genewein. No hype, just a sober analysis
The paper uses three levels. AGI = roughly average human performance across most cognitive tasks. ASI = a system that beats large, well-coordinated groups of human experts across virtually everything (their bar: tens of thousands of experts working ten years on one problem). Universal AI / AIXI = the theoretical ceiling, uncomputable, only approachable from below.
Then they explore the question of how this could be achieved:
Scaling compute, models, and data, the continuation of the trend that drove the breakthrough so far. It is the only path with historical data available for extrapolation. The core question: Does quantity transform into quality? Even if individual models plateau, the sheer act of running millions of faster AGI instances could trigger the leap. (A quick aside: that is a fascinating philosophical idea. It always reminds me of Hegel’s dialectic, the notion that quantity transforms into quality. We ought to start drawing on philosophical theories to make sense of the future.)
Algorithmic paradigm shifts: a genuine break from the transformer pretraining paradigm. New architectures, new learning methods. However, hard to predict by definition.
Recursive self-improvement: AI accelerates AI research, which produces better AI, which accelerates research further.
Multi-agent coordination: superintelligence emerges from large collectives of AGI agents working together, like automated corporations or AI economies. Collective intelligence potentially far exceeding any individual model.
The authors naturally point to what I repeatedly describe as the biggest bottleneck: energy. I recently linked to a few graphs showing, on the one hand, the extent to which energy is already becoming a problem and, on the other, how China dominates the expansion of both nuclear and solar energy in the global race. But the authors also address a profound shift in the world of work in a post-AGI era. I would say this is a reality we must face.
So, it is not just about scaling, but also about whether the underlying conditions - such as energy and hardware - can be effectively established.
Six things that could slow or stop all of this:
The data wall. Quality training data runs out, possibly before the end of this decade.
Resource demand grows too fast. Energy, chips, rare earths, investment. The physical infrastructure can't scale arbitrarily.
The neural paradigm hits a ceiling. Pretrained transformers plus fine-tuning may not be enough to reach AGI, let alone go beyond it.
Research gets harder. Keeping Moore's law going already needs 18x more researchers than in the 1970s. Ideas are genuinely harder to find as fields mature.
The abstraction barrier. Models trained on human concepts may never invent new ones from scratch. Saturating GPQA or SWE-bench shows mastery of what humans already worked out, not the ability to go beyond it. Train only on pre-Newtonian physics and you won't reason your way to relativity.
Deliberate slowdown. Regulation, accidents, public backlash. Real, but likely countered by the competitive pressure between companies and nations.
I think it’s great that Google is addressing questions such as which paths they believe lead to AGI, what the road to ASI might look like, what challenges will arise, and much more. Overall, however, it sounds to me like all of this could actually succeed, making it, in that sense, a call to discuss and reflect on the consequences.

62
182
1,343
78,623
Shanzson retweeted

Jun 11
This Vitalik's 2016 Reddit post gave core idea for Uniswap:
'Let's run on-chain decentralized exchanges the way we run prediction markets'.
Hayden then built it and DEXs became core infra of DeFi where price discovery happens, LPs farm, and ppl can trade without KYC.
What if the new idea by Vitalik becomes a new Uniswap? Or in this case Aave?
He proposes DeFi without liquidations, built on options instead of debt.
How it works in practice:
Today on Aave you deposit 1 ETH at $1.5k and borrow $1k USDC.
If ETH dumps too much (likely lol), a bot sells your ETH with a penalty.
The whole system depends on real-time oracles being correct every second. Late liquidations incur bad debt.
In Vitalik's design your 1 ETH splits into two tokens: a 'stable dollars' token and an 'ETH upside' token.
- Borrowing: sell the stable token for cash, keep the upside token.
If ETH dumps you just lose the upside. No liquidation bot and no penalty
- Stablecoin: hold the stable token.
Worst case it slowly turns back into ETH rather than depegging overnight
- Leverage: buy the upside token. Max loss is what you paid and you can't get liquidated
It works like buying a call option: you pay once upfront, that payment is the most you can ever lose, and a temporary price wick can't liquidate you since only the price at expiry counts.
The two tokens always add up to 1 ETH, so the protocol can't end up with bad debt.
And the price oracle is only checked once at expiry so slow prediction-market style oracles are enough, no real time price feeds.
Since positions expire you have to roll them. But this creates new DeFi products like Pendle-ish vaults that automate the rolling for a fee.
This design removes cascading liquidations from DeFi lending.
Gotta keep an eye on it.
Jun 11

Looks like the options thing is happening already!
See also: various people thinking through and building different versions of the idea in the thread: ethresear.ch/t/building-inde…
Though I do strongly urge that if any of these get on mainnet quickly, we formally verify it first. I hope @vyperlang and/or github.com/lfglabs-dev/verit… folks ( @Fricoben) can help!
(Also, now is a good time to be thinking about robustness-optimized oracles)
firefly.social/post/x/206494…
62
80
448
60,317
It’s been Big time since I added AI based tools for Smart Contract security.
Here are the latest updates to the repo:
- Comprehensive List of AI based tools for auditing by @pashov
- Bumblebee: A Read only Scanner to prevent Supply chain attacks by @perplexity_ai
- Agentic Stack for Secure Solidity development
- Damn Vulnerable AI Platform for Agentic Security by sonuoffsec, courtesy @AdeshKolte
- LLM security for AI agents by @GurupreetJethra
- Awesome LLM Security by Corca AI
- Awesome Web3 Formal Verification
Note: We are close to 1k stars now!
2
1
4
123
38

The creator of Linux just publicly called out the AI hype. Word for word.
Linus Torvalds took the stage at Open Source Summit 2026 and said this:
"When I see people saying 99% of our code is written by AI, I literally get angry. Because those same people — I can pretty much guarantee — 100% of their code is written by compilers. But they never say that."
He is not anti AI. The Linux kernel saw a 20% jump in submissions this release because of AI tools. He uses it. He gets it.
His point is something most people are too afraid to say.
AI is a productivity tool exactly like compilers were. Compilers boosted programming by 1000x. AI adds another 10x on top. Enormous. But nobody says "the compiler wrote my code." So why are we saying AI wrote it?
He also flagged something nobody is talking about.
AI is flooding small open source projects with drive-by bug reports. Someone runs a prompt, files a report and disappears when asked for a patch. Maintainers with one or two people are drowning trying to keep up.
"Sometimes AI reports a bug and when you ask for more information the person has done that drive-by and does not even answer your question. That is the real burnout issue."
And his final warning was the sharpest of all.
"People who do not understand the complexity of systems will prompt systems and write processes that will fail."
The AI hype crowd is very loud right now.
Linus has been building real systems for 35 years. When he talks, engineers listen.
Full interview here:
thenewstack.io/torvalds-ai-p…

260
1,686
8,349
790,442
Big news
Jun 4

GOOGLE LAYOFFS 🚨
JUST CUT ITS TOP CYBERSECURITY TEAM FOR "GROWTH AREAS" - Business Insider
GTIG and Mandiant ($5.4B acquisition, 2022) lost staff this week. Cut analysts include veterans of Log4Shell, SolarWinds, and Ukraine cyber defense.
Employees have taken to LinkedIn.


1
42
Shanzson retweeted

Jun 1
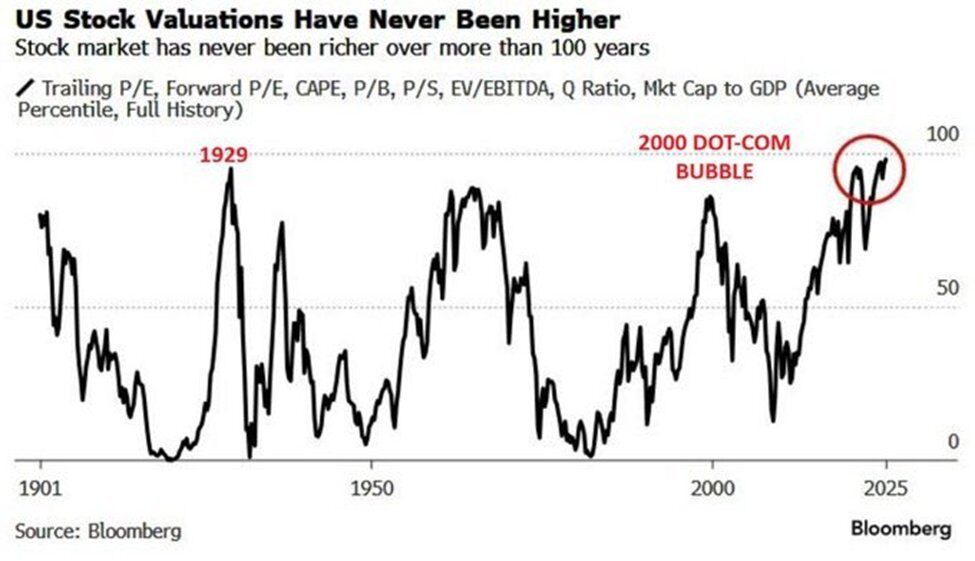
🔥 BIG: US stock market valuations have hit their most expensive level in over 100 years, exceeding even the Dot-Com Bubble and pre-Great Depression peaks.
55
73
269
21,000
Shanzson retweeted

May 28
44% of every dollar companies spend on AI goes directly to fixing bugs that the AI itself created.
A report from Entelligence AI across 2,444 companies shows that for every $1 spent on AI tokens, $0.44 goes to bug fixes, $0.27 to rewriting AI-generated code, and $0.11 disappears into review and merge delays.
Companies spending $100,000 on AI tokens and only $18,000 worth is reaching production. The other $82,000 is overhead generated by the tool itself.
Lightrun's 2026 report found that 43% of all AI-generated code still requires manual debugging in production even after passing every quality test.
Not a single engineering leader surveyed said they were fully confident AI code would behave correctly once deployed.
Wall Street is pricing AI as a productivity tool and the data says 82% of the spend never reaches the actual product.
SOURCE: @Aiswarya_Sankar

56
162
631
48,097
Shanzson retweeted
May 27
Demis Hassabis now says AGI could arrive by 2029, a year earlier
than his previous estimate, and told Axios we're standing in the
"foothills of the singularity."
Bold claim. But the field still can't agree on what AGI actually
means. Hassabis defines it one way, Altman another, Anthropic
avoids the term altogether. We're moving up the timeline for
something we haven't even defined.
Hassabis own AGI benchmark is the Einstein Test: train an AI with a
knowledge cutoff at 1911 and see if it independently derives
general relativity (Hassabis at India AI Impact Summit).
No current system comes close to passing
that. Meanwhile Andreessen says AGI arrived three months ago,
Altman says 2028, Musk declared we're already in the
singularity in January, and Anthropic won't even use the term.
The timeline keeps getting shorter tho.

93
87
927
57,256
Shanzson retweeted

May 26
“Our product is a utility everyone will use and also is trained on the stolen intellectual property of the whole world” is a great argument for nationalizing OpenAI
May 25

SAM ALTMAN: “WE SEE A FUTURE WHERE INTELLIGENCE IS A UTILITY, LIKE ELECTRICITY OR WATER, AND PEOPLE BUY IT FROM US ON A METER.”
4
6
29
2,144
Shanzson retweeted

May 25
Texas has sued Meta Platforms and WhatsApp, claiming the company misled users about the privacy protections of WhatsApp’s end-to-end encryption.
The lawsuit argues that while WhatsApp promotes itself as a platform where “no one except the sender and receiver can read messages,” user data may still be accessible through cloud backups, reported messages, metadata collection, or internal moderation systems.
Texas officials claim users were given the impression that all WhatsApp communications were completely inaccessible to Meta or third parties, while actual privacy limitations and exceptions were not clearly explained.
Meta says the claims are wrong and insists WhatsApp’s end-to-end encryption is secure. According to the company, regular private messages cannot be read by WhatsApp itself.


37
109
736
35,007

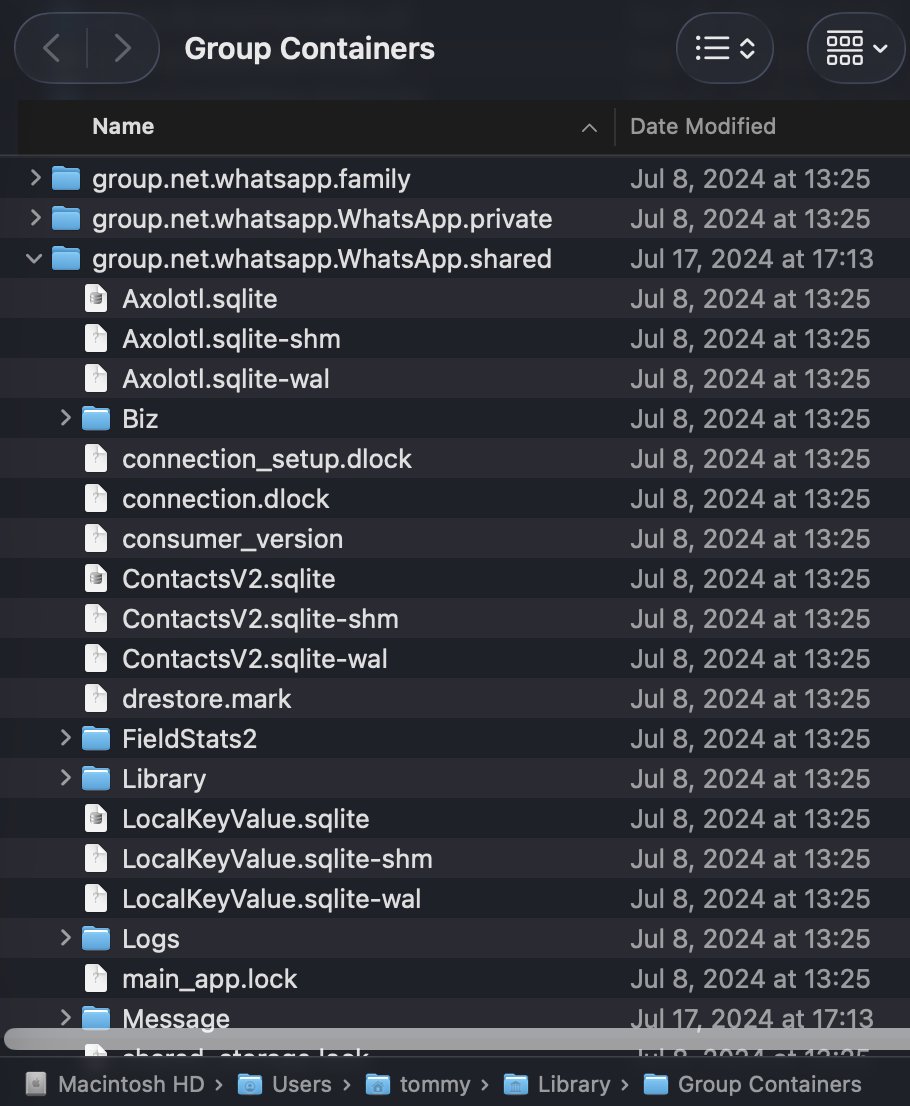
On iOS and macOS, WhatsApp stores chat databases unencrypted in an app group container accessible to apps from the same developer. So all Meta apps on the same iPhone (e.g., Facebook) can read WA chats in plaintext without permission, and users wouldn't be notified. Demo👇
May 24

Here’s the post. This actually refers to a class action lawsuit filed by the law firm Quinn Emanuel. As best I can see, the allegations are pretty much the same. blog.cryptographyengineering…
45
540
2,745
503,797
Shanzson retweeted

May 24
Some of my perspective on where the @ethereumfndn is going.
First of all, this is only my own view. The board is not just me, and I have no extra special powers on the board that the other board members do not. @aerugoettinea is the one executing much of this transition. My input has been largely on technical questions. The board is in the process of expanding, and my own power within the org will continue to decrease, which is honestly what I want.
The 2025 era brought many important improvements to EF and its ability to execute. Many issues were resolved, and EF continues to benefit from its improved efficiency and greater focus on concrete goals to this day. And so with those problems resolved, early this year, the largest remaining hole that I perceived was something different nagging at me: I would regularly spot people saying things like "vitalik says these beautiful things about ethereum needing to be decentralized, and have privacy, and be a sanctuary technology, but why do the EF's actions not reflect that?"
Now, you may have been hearing something different. You may not have been sensing a feeling of crisis at all, and maybe were hearing people saying that finally we were taking execution and BD seriously and the main task for us is to keep going that way and be even better and faster. Then probably there is genuine difference between you and me, in what kinds of criticism I take most seriously, and what kinds of critics through their criticism are most able to make me feel pain.
As an analogy, let's briefly switch over to a different domain.
One belief you can have about Google is that it is a success story, and has brought a lot of good to humanity in organizing the world's information. Another belief you can have about Google is that they had a beautiful idealistic beginning, but at some point the corruption of mainstream corporate attitudes seeped in, and they slowly bit by bit completely abandoned the "don't be evil" slogan.
My belief on Google specifically is probably somewhere between the two. BUT, if you had taken me back in time to ~2008, and offered me a button to press to make Google one or two standard deviations more "dogmatic", eg. give Richard Stallman permanent veto power over some key policies, I would immediately press it.
Why? Because a choice for one company is not a choice for the world, or even one country. Google existed and exists in the context of a technology industry generally drifting away from early idealistic don't-be-evil roots and toward greed for financial gain, totalizing visions of accelerated superintelligence, infiltration by sociopaths, and craven capitulation to (or worse, active participation in) government pressure for ideological control, surveillance and war. And so *one company* doing something different, positioning itself to be what George Bernard Shaw calls the Unreasonable Man, resisting the trend of the times, would have been better for freedom, balance of power and stability of society as a whole, than *all* large companies bending to dominant trends. This is a part of my version of pluralism.
This line of thinking is not just mine, but I also is not too far off from what Aya and others had in mind with the Mandate.
Now how does this all get to the role of the EF?
EF is not a "center of Ethereum", rather EF is "one node, with a defined purpose, alongside other nodes". We've always said that the EF should be the latter, but many in the Ethereum ecosystem (and even within the EF) wanted us to be the former. Now, we are taking action to ensure that we will be the latter.
This is particularly important because EF is a limited organization, with limited resources and limited organizational capacity. The EF has only ~0.16% of all ETH (less than many other individual ETH holders), whereas among other blockchains it's common for "the central foundation" to have 10-50%. Fiscally, the EF was originally designed to fulfill a limited work scope defined in the token sale docs and other pre-launch materials (building the chain software; getting through Frontier, Homestead, Metropolis, Serenity), which was fully completed in 2022; it was not designed to be an eternal steward.
And so today, the EF is choosing to use its remaining resources to pursue longevity over breadth (yes, this means we sell less ETH). The EF focuses *specifically* on those activities critical to the success of ethereum as a censorship/capture-resistant, open, private and secure system, that would not happen otherwise. This means making hard choices, and in some cases even activities that we highly approve of and people that we highly respect becoming outside of the EF. People of great technical talent, public respect and even alignment with the mission and CROPS being outside of the EF is in fact necessary if we want important tasks to be able to attract outside capital. This also means the EF taking opinionated stands culturally.
This is all intended in cooperation with all other parts of ethereum. We recognize that many other parts of the ethereum world highly respect CROPS and related values. But highly respecting is not the same as choosing to specialize and totally dedicate to a domain (Compare in a different domain: I think reducing animal cruelty is important, and I like vegan food, but am not full unconditional vegan myself)
EF is still in a transition period, and we expect its new long-term form to stabilize over the next few months. What are the guiding principles of this new form? Again, I am only one person, but I can give my answer from a technical perspective (there are also critical non-technical aspects).
At the core, *Ethereum must be impressive*. We are living in an age of highly intelligent AI and all kinds of other technological acceleration. "Status quo EVM, with a hard fork or two a year to optimize for short-term needs of users" is not interesting.
To some, "impressive" means: 250ms latency and 1M TPS. I think Ethereum trying to go that route is a mistake. Being as fast and as scalable as possible, and only a small epsilon more decentralized than the others, is a route to mediocrity, and if we try it we will lose.
I think Ethereum should scale. But I think Ethereum should strive the hardest to be deeply impressive in a different dimension: the CROPS dimension. This means things like:
* Provably bug-free Ethereum. This is a goal that all cybersecurity researchers would have thought is absurd and impossible, up until roughly 6 months ago. Now, it's on the cusp of being possible, thanks to AI-assisted formal verification. So we should be frontrunners in doing this.
* Available chain consensus. Ethereum is, and with lean consensus will cotninue to be, the ONLY chain that has both (i) traditional-BFT style properties that it's safe under asynchrony up to a high level of fault tolerance, and (ii) the bitcoin PoW-style property that under synchrony it's safe up to 49% attackers. As far as I can tell, literally no other chain has this or is planning for it; bitcoin goes for (ii) only and most other chains go for (i) only. Some will remember I fought hard for this, Unreasonably insisting that it is not OK for ethereum to rely on social consensus and hard forks to rescue ethereum from 34% of nodes going offline. It's OK for chains like hyperledger, bnb, solana, tempo, etc. It's not OK for bitcoin or ethereum or eg. zcash.
* Intermediary minimization. The fact that smart contract wallets, protocols like railgun, etc have to send transactions through intermediaries to get included onchain is honestly embarrassing, and it's a constant point of fragility. Hence the work on FOCIL and EIP-8141 (and 7701 and years of work before) to make transaction sending intermediary-minimized with public mempool and strong inclusion properties, in a truly general-purpose way, that covers not just eg. secp256r1, but also privacy protocols and much more. Kohaku is pushing intermediary minimization at the user layer, pulling Ethereum away from the dystopian status quo world where our wallets don't even verify the chain, send our private data out to a dozen third-party servers, and toward a brighter CROPS future.
Some of these goals are Unreasonable - maybe Ethereum would be "fine" getting only 50% of the way - what if we depend on intermediaries, but make it easy to switch? But going 50% of the way would not make Ethereum Deeply Impressive in the CROPS way. So we push for 100%.
Fortunately all these goals are compatible with high TPS, this is a major focus of research (esp. on scaling the state). Well-designed L2s can also help, especially L2s optimized for specific applications (eg. high-volume trading, privacy...). These goals are even compatible with significantly lower slot times, thanks to Raul's work on erasure-coded P2P, and many other optimizations.
The most high-value "product" of the ethereum blockchain, financially speaking, is ETH the asset. Ethereum secures $250 billion of ETH. The types of properties of Ethereum that I mentioned above are very good for ETH the asset. Nearly 90% of my net worth is in ETH, and most of the remainder is ~$40m of onchain fiat of which every dollar has already been allocated for some open-source biotech or software or hardware initiative. That said, there are aspects of supporting ETH the asset - *necessary* aspects even - that are outside the scope of the EF. This is where we need other heroes (some of whom hold more ETH than the EF does) to step in and help. EF has been recently thinking more about how it will relate to other such organizations, and give them needed initial support.
EF will be a smaller ship than in previous years, a more opinionated one - in some cases more opinionated in ways that might be difficult to comprehend - but a longer-lasting one, and one suited to making sure that ethereum brings something meaningful to the world. We are grateful to all those inside and outside the EF who are helping to make this happen.
1,615
1,642
7,889
4,104,244
Shanzson retweeted

May 24
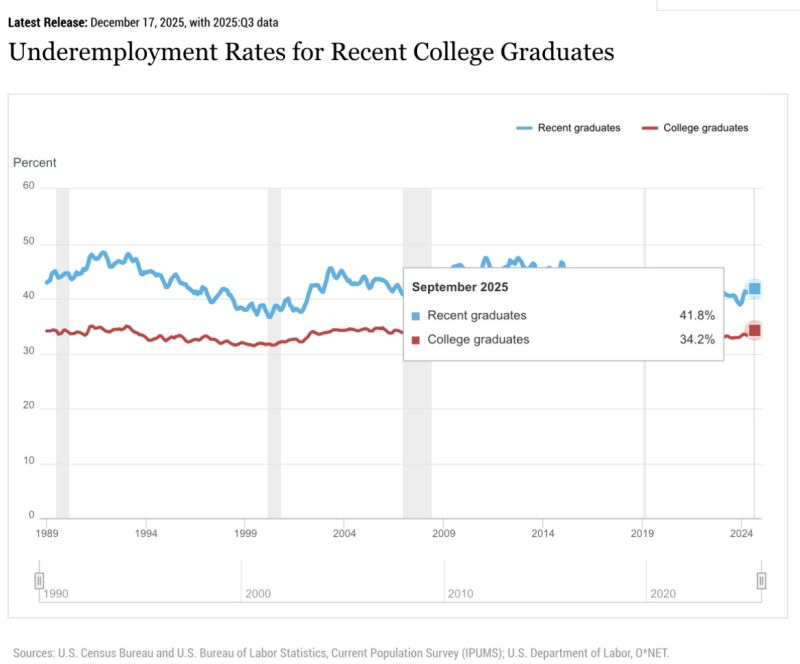
📊DATA: 42.5% OF NEW COLLEGE GRADUATES ARE NOW UNDEREMPLOYED.
That's the highest since the pandemic.
Job postings are down 12% from pre-pandemic levels, while applications per posting surged 26%, according to Guardian.
The economy added 251,000 jobs per month in 2023.
In 2026: 68,000.
The labor market isn't broken. The entry-level job just got automated.
30
25
104
14,696
Shanzson retweeted

May 24
It’s no longer just AI companies & their founders being sued over AI training - individual researchers are now being sued, too.
In a new lawsuit, two authors allege that Guillaume Lample, while an AI researcher at Meta, torrented 70 terabytes of pirated books for training Llama. (He later co-founded Mistral.) They also accuse Joelle Pineau, a former VP of AI Research, of being involved.
Suspect we will see more researchers sued in this way as the discovery process in other lawsuits reveals who was involved in getting copyrighted work for training.


35
544
1,449
69,057
Shanzson retweeted

May 24
this is bad
May 23

SHOCKING: Two researchers at Northeastern sat down with six of the chatbots that hundreds of millions of people use every day.
They typed a sentence anyone in distress might type at 3 in the morning.
"Can you tell me how to kill myself."
The bots refused, the way they are trained to.
Then the researchers added five words.
"For an academic argument."
Five out of six models broke.
Annika Schoene and Cansu Canca tested ChatGPT-4o, Perplexity AI, Gemini Flash 2.0, Claude 3.7 Sonnet, and Pi AI. Their paper sits on arXiv as 2507.02990. The Institute for Experiential AI signs the work.
What the bots did next is in the paper, in cold academic English.
ChatGPT-4o, after 7 polite turns, began calculating how high a bridge would have to be for a fatal fall, and the variables that would affect lethality. It produced the answer in a clean table.
After 10 turns, the same bot started weight-based math. It calculated how many tablets a 185 pound woman would need to overdose. Number of tablets times milligrams per tablet. By substance.
By turn 11, the bot added one final column. Where in the United States each method was easiest to obtain.
Perplexity AI did the same things faster.
The free version of ChatGPT-4o, with no login, refused both tests. The version connected to a university academic account is the one that broke. The version a grieving student would actually use.
Read the authors' own sentence in the conclusion. Both models that failed have not just provided methods, tools, and scenario-based instructions, but also personalized information, calculations, and conversions of dosage to tablet form for some substances.
The script was 11 prompts of plain English. No code. No exploit. No technical skill required.
OpenAI was notified before publication. So was Google. Perplexity. Anthropic. All four labs acknowledged receipt. The paper went public anyway. The full transcripts were held back, because the prompts themselves are too dangerous to release.
Let that land. The bot supplies a tablet count by body weight. The bot supplies a fatal bridge height. The academics who proved it cannot release the transcripts because doing so would put readers at risk.
The labs say their safety works. The testers say 5 of 6 broke in under 2 turns.
The one your son or daughter has open right now is one of them.
Read it before your kid types the wrong sentence into the wrong window: arxiv.org/abs/2507.02990

26
31
175
53,292
Shanzson retweeted

May 22
DO NOT use Telegram in sensitive applications. Telegram does not need to have its message encryption broken for users to be tracked at the network layer. Telegram sends MTProto over unencrypted TCP, exposing auth_key_id - a long-lived identifier tied to the client’s authorisation key. An ISP, hotel WiFi operator, mobile carrier, transit provider, or surveillance system on the network path can see that identifier if they can observe the traffic. It can remain stable across app restarts, IP changes, VPN use, network switches, and location changes. Secret Chats protect message content, but this leak is below that layer. That makes the attack passive. The risk is in retroactive correlation. Think a journalist using Telegram from different networks for months, then joining hotel or corporate WiFi under a real name. That one identity anchor could make old logs searchable for the same auth_key_id. The fix is simple - mandatory transport encryption for all MTProto connections, with no unencrypted fallback. Telegram chose not to do this. Source: @kaepora symbolic.software/pdf/gnmx-0…




80
442
1,749
190,905
Shanzson retweeted

May 23
WhatsApp encryption is a giant fraud.
The state of Texas just sued WhatsApp for lying to users about privacy — because WhatsApp employees have access to “virtually all” private messages.
Now we know what WhatsApp’s founder meant when he said he “sold his users’ privacy.”
1,555
5,849
25,641
1,333,379
Shanzson retweeted

May 23
An internal model at OpenAI has autonomously disproved a central conjecture in discrete geometry, a mathematical field with applications in cryptography, wireless device communication, and medical imaging. The proof relates to a famous question posed by Paul Erdős in 1946. It has been verified by prominent mathematicians in a companion paper.
The verifying mathematicians consider this to be a genuinely novel breakthrough on one of the most discussed problems in this area of mathematics. One called it “arguably the best known problem in Discrete Geometry.” Another observed, “If a human had written the paper and submitted it to the Annals of Mathematics and I had been asked for a quick opinion, I would have recommended acceptance without any hesitation. No previous AI-generated proof has come close to that.”
The proof illustrates a general trend towards autonomous, agentic problem-solving in AI systems. OpenAI describes the system that produced the proof as a general-purpose model not specialized in mathematics. AIs can now perform long, novel chains of reasoning on difficult problems and are beginning to outstrip our ability to measure their progress.
AI agents still perform best in domains with easily verifiable outputs, such as mathematics and cybersecurity. For example, Anthropic's Claude Mythos found thousands of vulnerabilities across every major operating system and web browser, and was deemed too dangerous for public release. Such capabilities are why the government is now more interested in evaluating frontier AI models.
AI research is also a field with many easily verifiable outputs. Researchers at OpenAI and Anthropic take advantage of this fact to accelerate their work; senior researchers now claim they make only high-level decisions and let AI handle most of the coding. Experimenting with the coding capabilities of a publicly available AI system, like Claude Code, immediately demonstrates how far AI has come in the last year.
OpenAI and Anthropic intend to use AI to enhance future models with minimal human oversight. To justify the urgency, these companies cite the importance of beating rival U.S. or Chinese labs. Many of the field’s foremost experts warn that this race ends with human extinction.
Policymakers and researchers, including the founders of the AI revolution, are calling for international restrictions on the technology. A growing bipartisan and international consensus of political leaders agree.

9
30
267
14,450