
Post training data for RL | prev 2x exits
Joined May 2009
- Tweets 2,263
- Following 216
- Followers 304
- Likes 7,877
61 Photos and videos




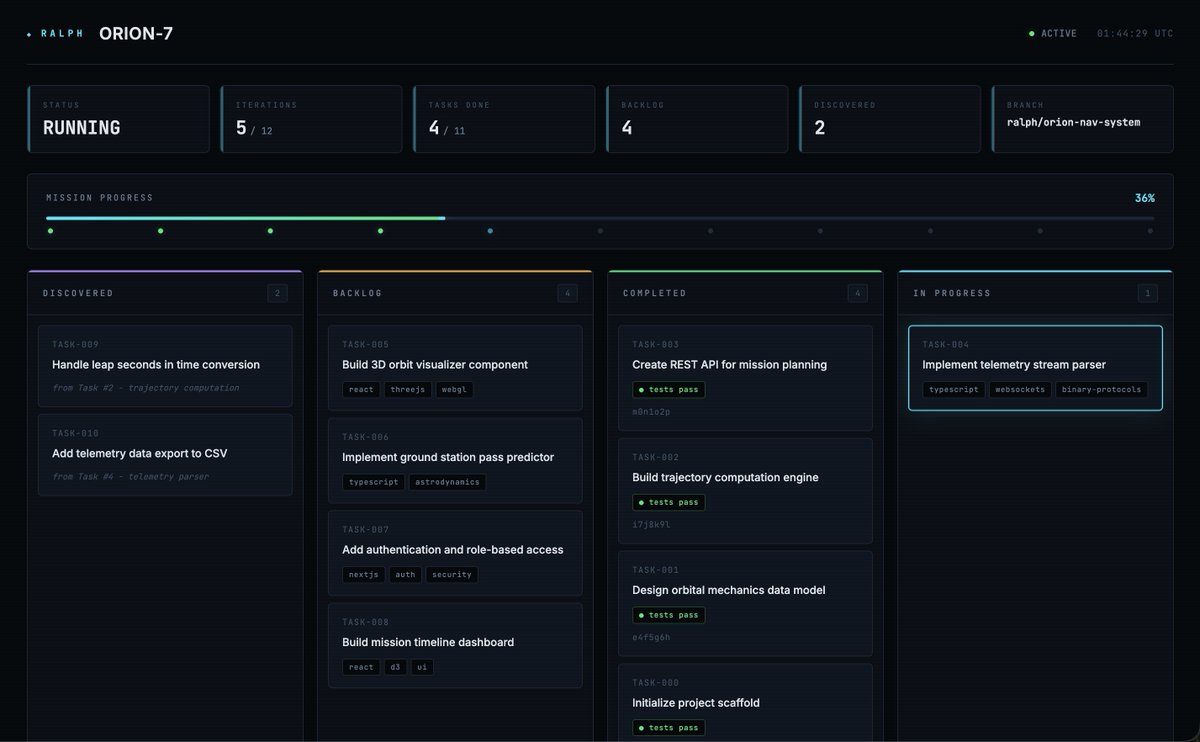





Claude Opus 4.7 solves its first ProgramBench task 👀
After creating a 663-word CLAUDE.md we were able to increase solve percentage by 1.1 points on Claude Code Claude Opus 4.7 across 10 ProgramBench, and actually solve one of them.
You can replicate our results here: github.com/parsewave/Program…
big thanks to @KLieret @jyangballin for releasing such a forward-thinking benchmark!
1
1
9
125
shaped retweeted

May 15
singapore eats part one; hainan chicken rice; insane buffet of crab, skewers, noodles, chicken; you name it, at Newton, food coma afterwards



2
1
8
3,572
shaped retweeted

May 4
For my eval-maxxing nerds out there, good friends of mine are running a series called "strange evals", you can benchmaxx now on anything. If in SF swing by! luma.com/lvqbs1mo
7
4
26
5,206
Happy to be working with meta for the past 7 month, and seeing the fruits of their labor.
Great release!
Apr 8

Introducing Muse Spark, the first in the Muse family of models developed by Meta Superintelligence Labs.
Muse Spark is a natively multimodal reasoning model with support for tool-use, visual chain of thought, and multi-agent orchestration.
Muse Spark is available today at meta.ai and the Meta AI app. We’re also making it available in private preview via API to select partners, and we hope to open-source future versions of the model.
Learn more: go.meta.me/43ea00

1
9
186
shaped retweeted

Apr 2
No major benchmark is designed for COBOL, Fortran, or Assembly - the languages powering trillions in transactions and infrastructure that must be modernized or risk catastrophic failure.
We built Legacy-Bench to measure frontier agents on the code the world actually runs on.
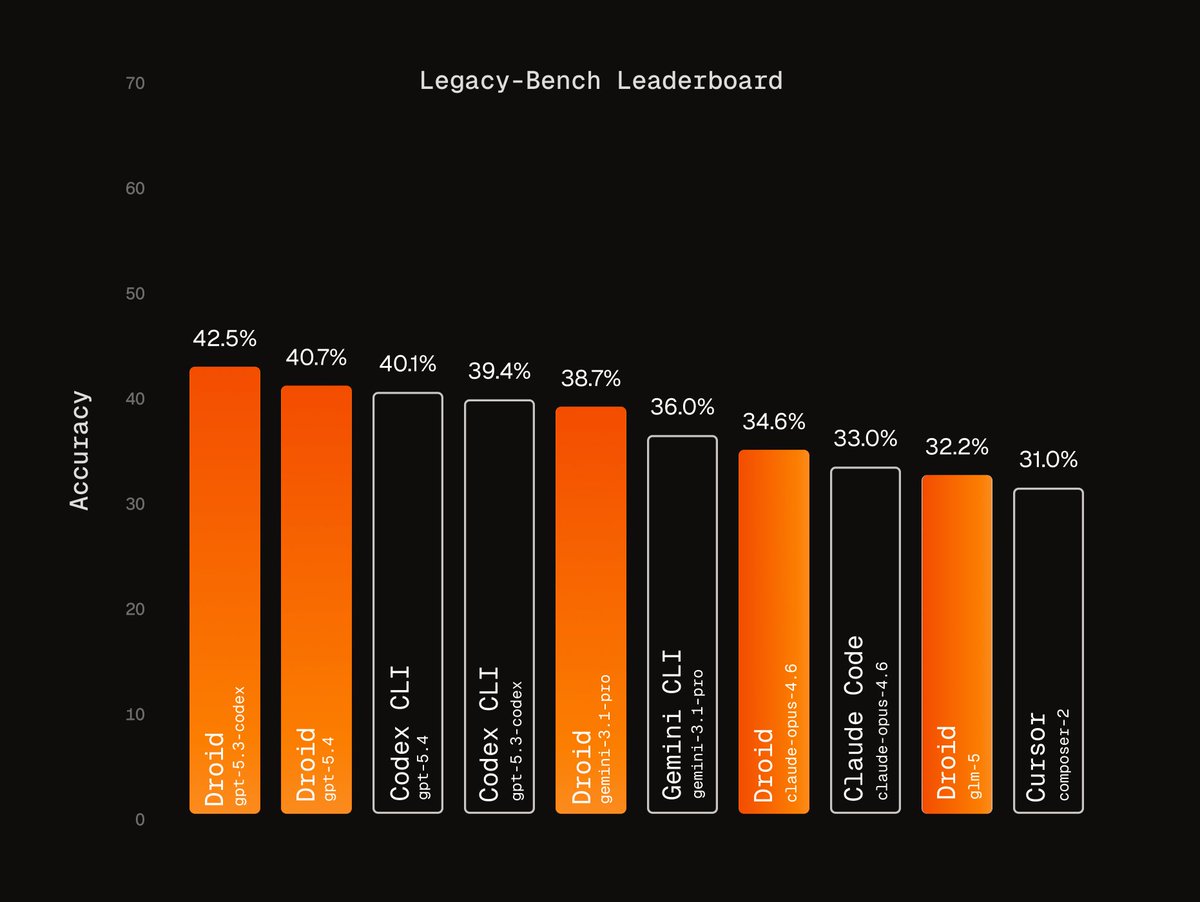
15
36
356
52,966
shaped retweeted

Mar 21
2
24
101
82,939
The real-time web search capability is Nano Banana 2's secret sauce. Midjourney and DALL-E train once and call it done. NB2 pulls from the live internet every time. The outputs reflect what's happening now, not what the world looked like months ago, pretty genius
That image-sequencing demo is pretty great. Each frame only sees the previous frame so there's no cheating, no outside reference like a world model would have. Yet the visuals stay consistent. That's the model understanding cause and effect in visual space. Coherent video generation is the natural next step, and it's closer than people think..
Also pretty nice to see them roll it out all at the same time, API, platform, aistudio. Looks like only text model releases are somewhat staggered at google. Really good launch
Feb 26

Nano Banana 2 is our new faster and better SOTA image generation & editing model!
It uses Gemini’s amazing world understanding grabs real-time info w/ search to create higher quality outputs.
Available in @GeminiApp, @GoogleAIStudio, @FlowbyGoogle, Search & Vertex - enjoy!
1
332
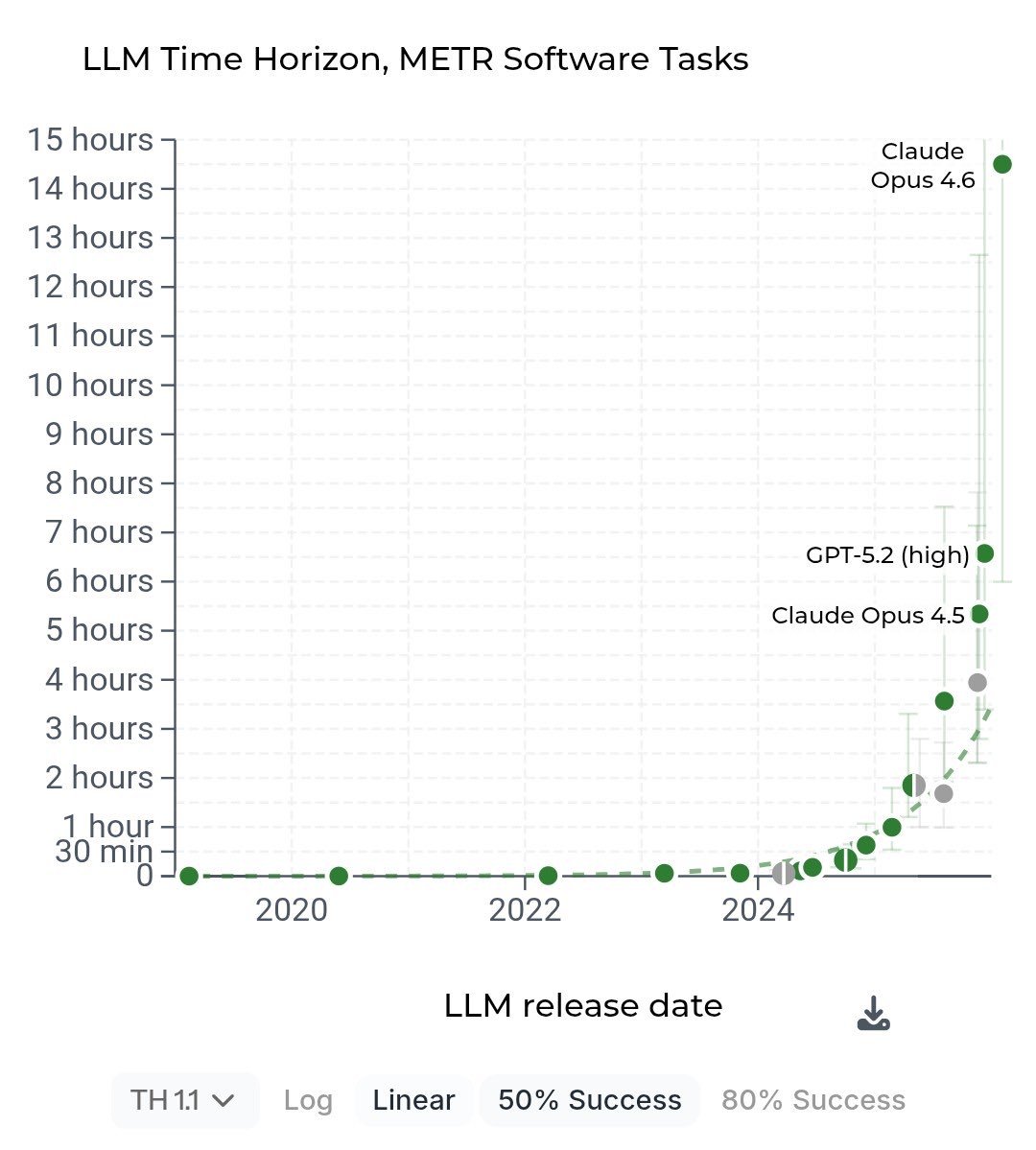
Horizons are LITERALLY too long to METR at this point, look at those error margins!
Jan 15

Horizons too long to METR
1
676
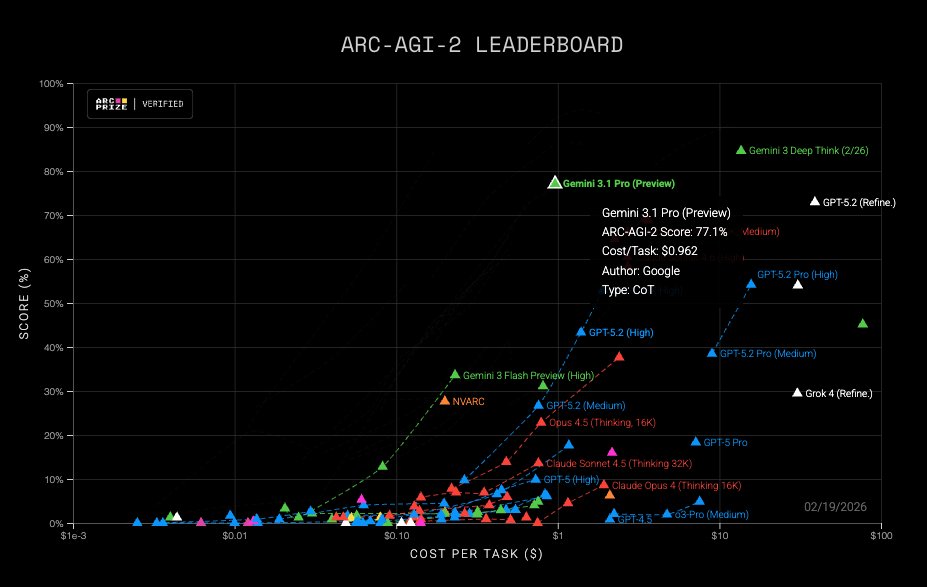
Unbelievable that we are actually approaching saturation on both ARC AGI 1 and 2.

Gemini 3.1 Pro on ARC-AGI Semi-Private Eval @GoogleDeepMind
- ARC-AGI-1: 98%, $0.52/task
- ARC-AGI-2: 77%, $0.96/task
Gemini to push the Pareto Frontier of performance and efficiency
2
230
I think we should really stop taking SVG tests as a benchmark in the first place. This seems easy to benchmaxx and doesn't denote any sort of real life performance whatsoever

This is so cool
Can't believe this jump in capabilities is just a .1 update
1
213
AI is going to hit the finance world like a freight train
Feb 14

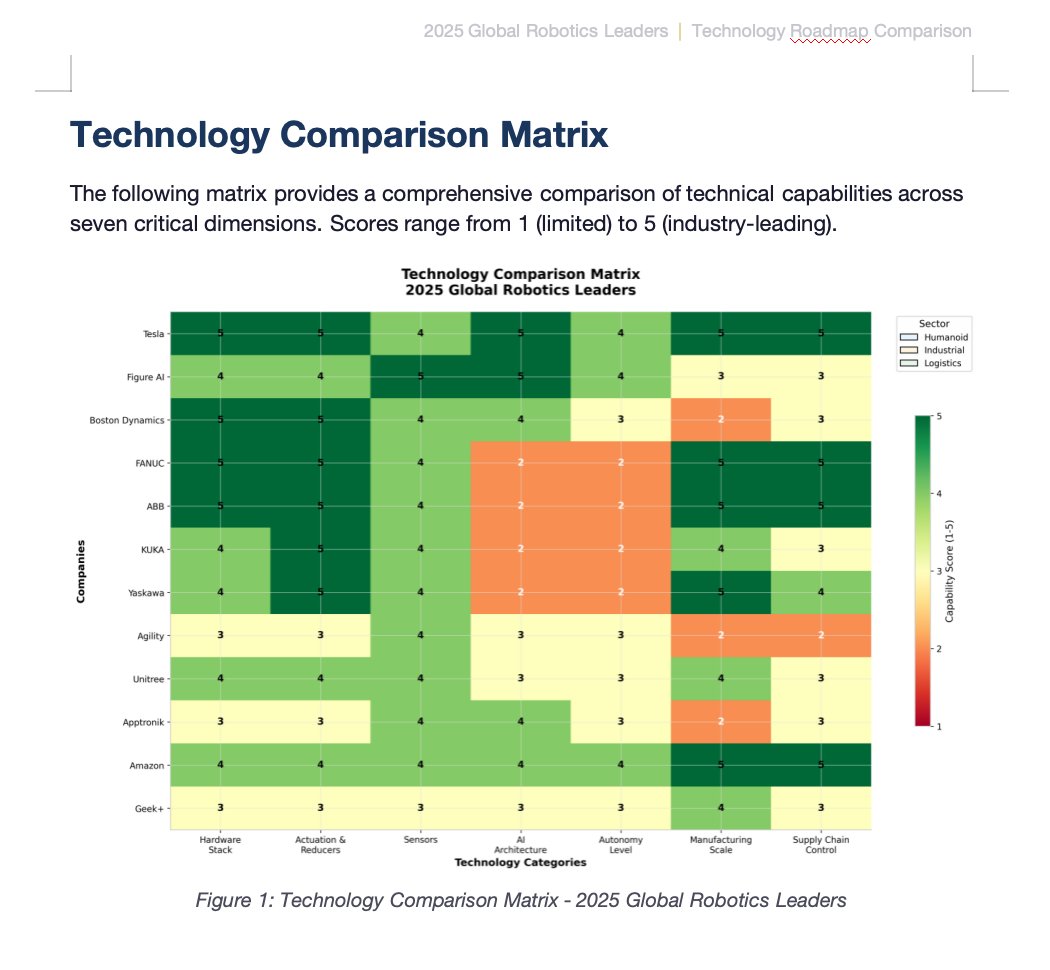
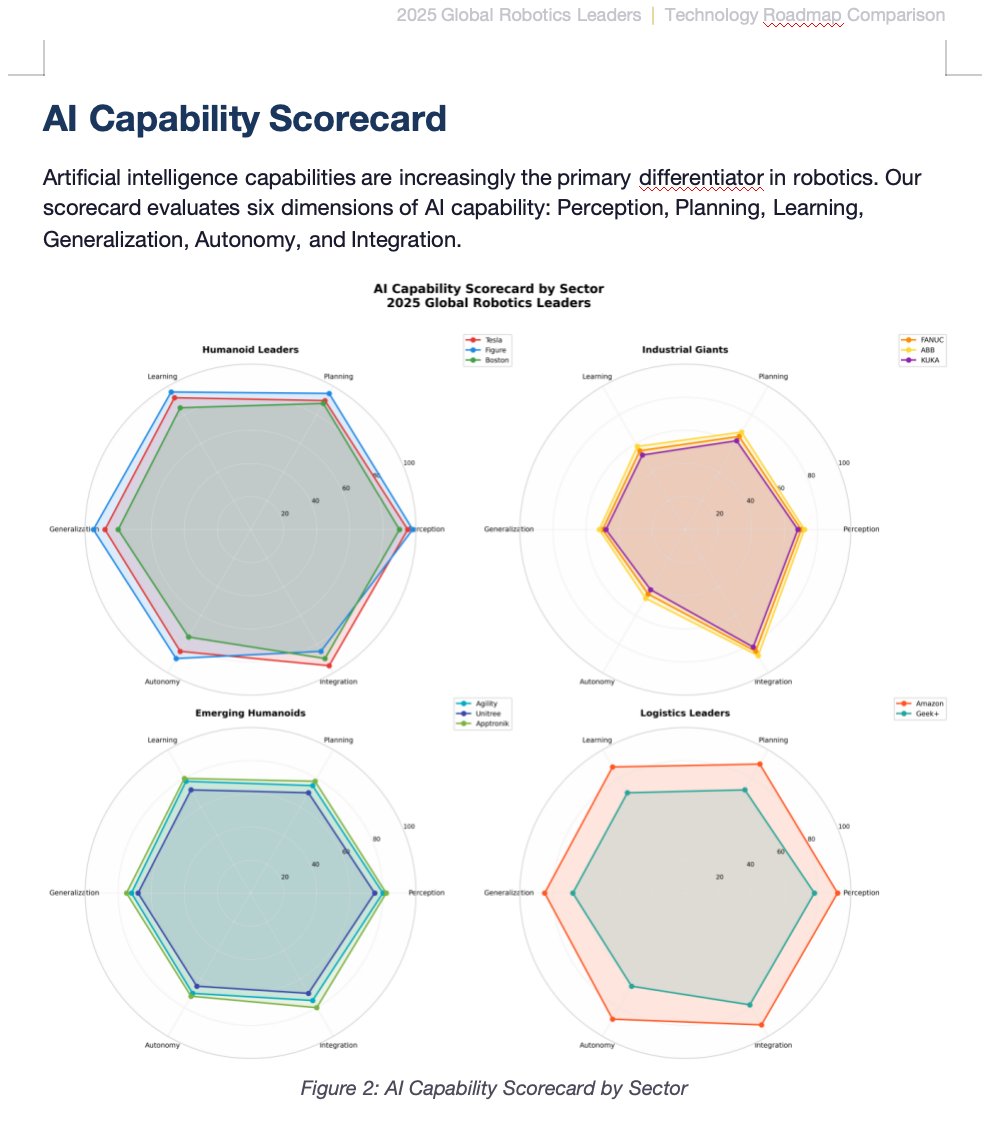
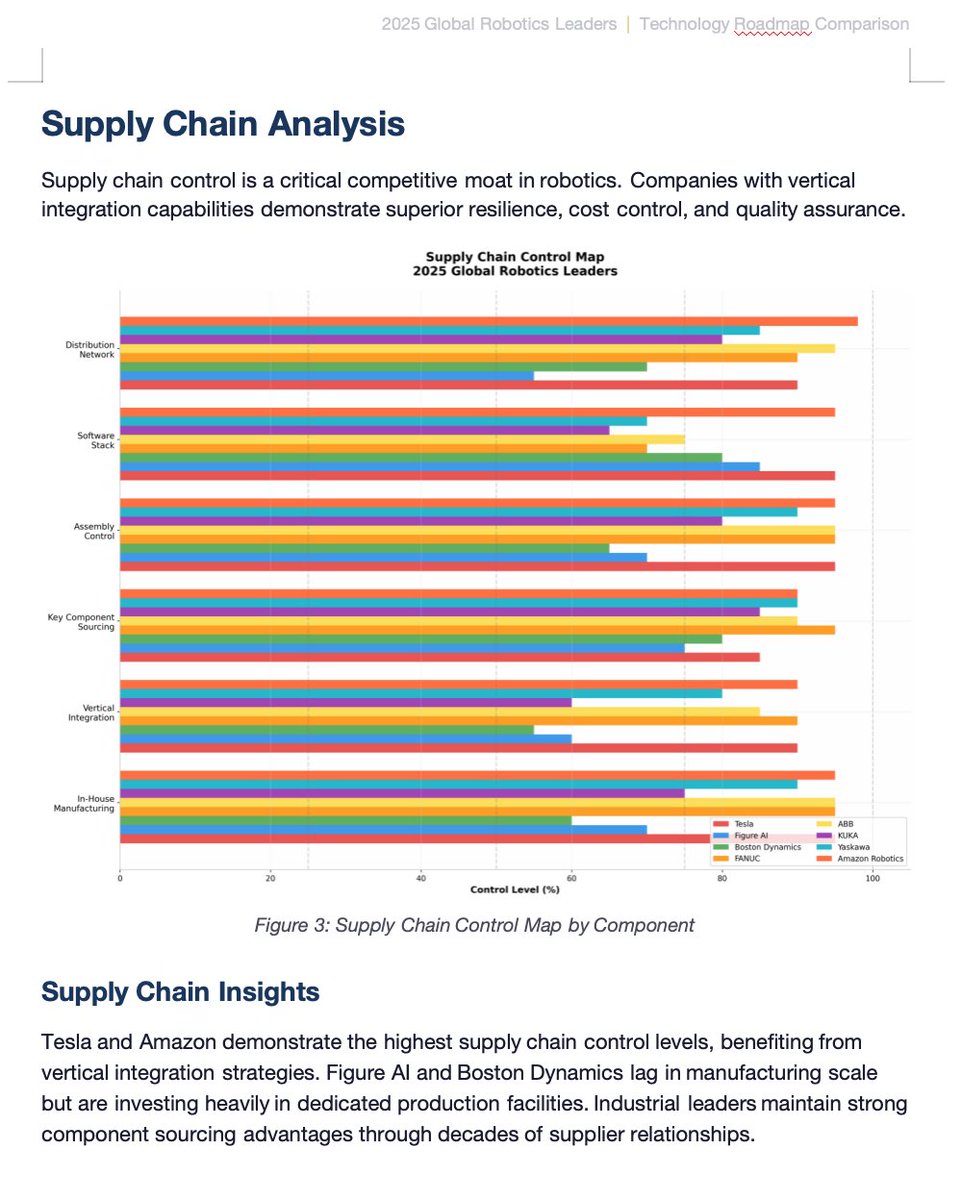
One-shot McKinsey-grade industry report by Kimi K2.5 Agent
One Prompt = 14-Page Word file with consulting-level data visualization, technical heatmaps, and strategic frameworks.
If your work requires competitive analysis with professional fomatting, Kimi has you covered.
kimi.com/chat/19c5c0ad-f2b2-…
335
pack it up bro
Feb 13

You can ask one question: does AI have a business model? It's not a fun answer.
2
273
The Turing test is just undercover customer support?!
1
4
243
My current development stack:
- OpenCode (the best harness ever)
- Kimi K2.5 on the moderato code plan, incredibly capable model
- OpenClaw (for remote server management and running ralph)
- ralph-manager skill for openclaw we made internally which spawns ralph instances with nice monitoring
- tmux for terminal multiplexing
- nvim for making code edits if needed
- termux for accessing my running tmux sessions from my mobile phone
- tailscale to connect to my devices remotely from anywhere with ease
The fact that this is even possible right now is crazy. Long live open source man
1
1
259
what
Feb 12

We don't have the capacity to support more than two colors right now. But feedback noted: we are looking into lightening the black on web.
1
141
It's weird seeing a lot of "uncollapsible" systems collapse with the advent of AI. And it's all thanks to the volume content is coming out, not AI itself.
Social media algorithms? Destroyed. "Slop" coming out so quickly is flooding social media at rates never before seen. We can't tell who's a person, who's an agent and who's a bot. Likes and shares no longer define if the content was actually authentic and valuable or not.
Copyright and IP laws? Cooked. At the rate at which violations are coming out thanks to image and video models it is simply unenforceable now.
I don't think this is an AI problem. These systems banked on the low user base to function. Likes and shares worked because there were just a few people posting on the platform. Copyright laws worked because only a few people could violate it and it was largely enforceable at that scale
This means we shouldn't try and abolish AI to make these systems work. It means we need to work around it to setup robust systems which don't break under volume
129
"AI hasn't made anything novel"
"AI hasn't innovated anything"
"AI is a stochastic parrot"
AI's pushing barriers of human knowledge at the bleeding edge fringes like this one. You're just not paying attention
Feb 10
The drug design engine we’re building at @IsomorphicLabs is extending the SOTA further across key benchmarks, showing huge progress in accuracy and capabilities critical for in-silico drug discovery. Incredible work from @maxjaderberg and the entire team at Isomorphic Labs!
173