
AI Engineer (21) | MedAI | Building deployable tools for rural India | Learning infra to make models real in low-resource settings | Building to internalize
Joined November 2023
- Tweets 232
- Following 546
- Followers 59
- Likes 1,173
53 Photos and videos







Pinned Tweet

Apr 17
We won the 2nd place in Agentic Track @GoogleResearch Medgemma Hackathon
Yes we (me , @c_sachiv and ramaswamy) made voice-based TB screening tool instead of a chat style
Shout out to @kaggle and @GoogleResearch whole team for organizing this
#MedgemmaImpactChallenge #Gemma #Google #kaggle
1
1
393
Sidharth retweeted

14h
Together with my co-founders Michael @MichaelPoli6, Stefano @Massastrello and Armin @athmsx, I am excited to announce @RadicalNumerics is emerging from stealth with a $50M seed round to build general biological intelligence.
We’re also sharing an early preview of our new model Omnii, the most powerful genome language model to date.
Omnii preview link:
radicalnumerics.ai/blog/radi…
At Radical Numerics, our mission is to master the code of life, and to drive the frontier of biological AI for both design and defense.
This is our dual mandate, which comes from something our own team helped make possible.
Our founding team trained Evo and Evo 2, the largest biological AI models (40B params) trained on DNA sequences. Trillions of tokens across all of life, from microbes to mammals. It’s fully open source, and created the field now known as generative genomics.
Last year, scientists used Evo to generate the world’s first complete genome from scratch using AI. Turns out it was a bacteriophage—a type of virus. It functioned in the real world, and in this case it was harmless. But for us, it was a clear turning point.
It showed that AI is no longer just analyzing biology. It is on the cusp of generating functional lifeforms. Eventually, AI will have the power to design and control life itself.
That should make all of us incredibly excited, and incredibly uneasy. (Anyone can design DNA with a new function, and have it synthesized and delivered, like something from Amazon Prime).
The same technology that will help us cure cancer is the very technology that might create the next global pandemic, or worse, allow the creation of bioweapons that can wipe out populations.
We believe these forces are inseparable. If you work on the frontier of biology, you have to build technology to safeguard it from its misuse. Existing biosecurity tools are sorely losing the arms race, relying on outdated “have I seen this exact thing before?” style algorithms.
We founded Radical Numerics to turn the tide.
And we can’t do that by training on textbooks and natural language. We must understand the language of biology from the raw physical data itself, to reason across every molecule and modality, from DNA to proteins.
The next frontier for AI goes far beyond chatbots or video generators to models that can understand and engineer life.
Today, we’re previewing Omnii, which is already far surpassing Evo 2, and will continue improving as we scale and add new modalities (training now).
1. For human health, Omnii can read and write whole genomes (more on writing later). It’s state of the art (SOTA) on detecting causal variants for disease, and can rank Alzheimer's mutations zero-shot. We’re partnering with a diagnostics company to use Omnii for early cancer detection (pancreatic and multi-cancer).
2. For defense, Omnii is SOTA at detecting AI-generated pathogens. We benchmarked existing detection tools, and they simply can’t detect the AI-generated ones (“deepfake viruses”). We’re partnering with a US national lab to pilot Omnii for detecting the next pandemic, both natural and AI-generated.
We have a data center full of Blackwells in construction now to build the most powerful biological AI models ever. This mission takes a new kind of AI lab that can actually scale on physical, biological data: new alignment research (mid/post training), scaling long context, building out mech interp teams to dissect what these models learn, new architectures and systems designs, all from the ground up.
Our team is made up of AI researchers and scientists from top labs and institutions (e.g. Stanford, MIT, Google DeepMind), but more importantly, we all share the belief that this is the most important challenge of our lifetime. If you feel similarly, we are hiring. We aim to bring the brightest minds in AI and science together to save lives.
Thanks to our partners on this journey, led by Emergence Capital @emergencecap, with Obvious Ventures @obviousvc, Triatomic @TriatomicCap
, and Patrick Collison @patrickc. Our advisors include Eric Horvitz @erichorvitz, CSO of Microsoft, Chris Re @HazyResearch of Stanford, George Church @geochurch of Harvard, and Andrew Weber @AndyWeberNCB, former Assistant Secretary of Defense for Nuclear, Chemical and Biological Defense Programs.
Fortune article: fortune.com/2026/06/15/exclu…
Jobs: radicalnumerics.ai/join-us

91
245
787
1,156,108
Sidharth retweeted

Jun 10
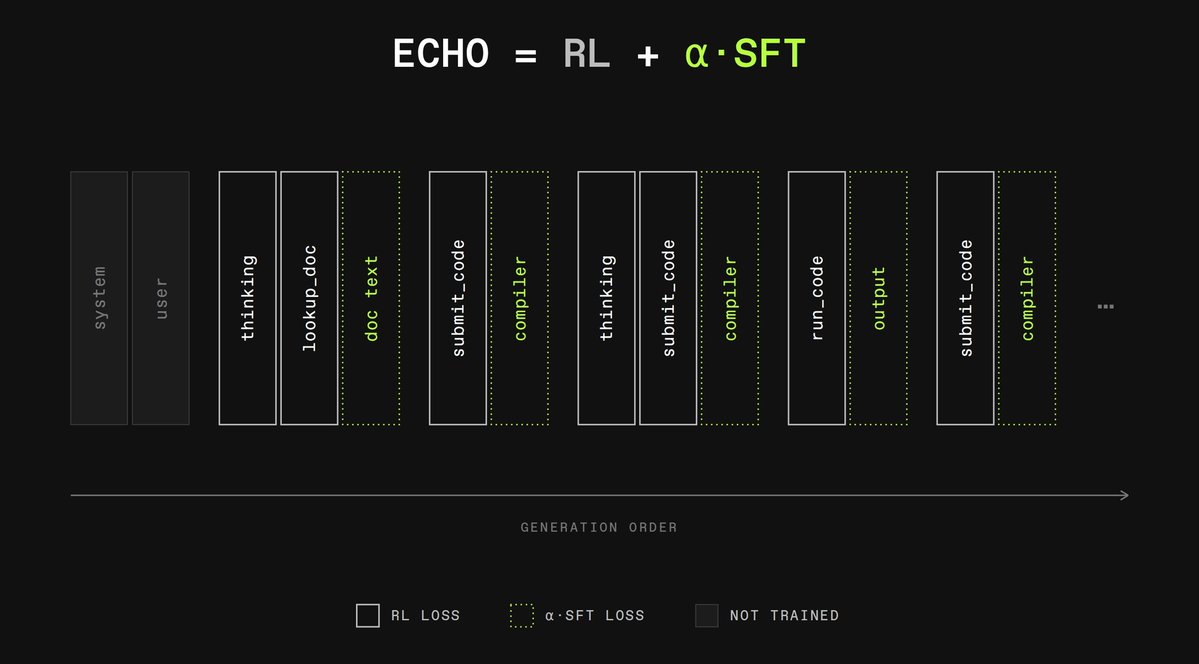
True agents model the world.
Current training provides no separation between agent and environment: pre-training only trains world modeling, RL only agentic actions. We combine both using ECHO by @DimitrisPapail and @VaishShrivas.
10
50
510
97,528
Jun 10
Finished Module 1 of Transformers in Practice (@realSharonZhou ) today.
5 exercises, 1 quiz.
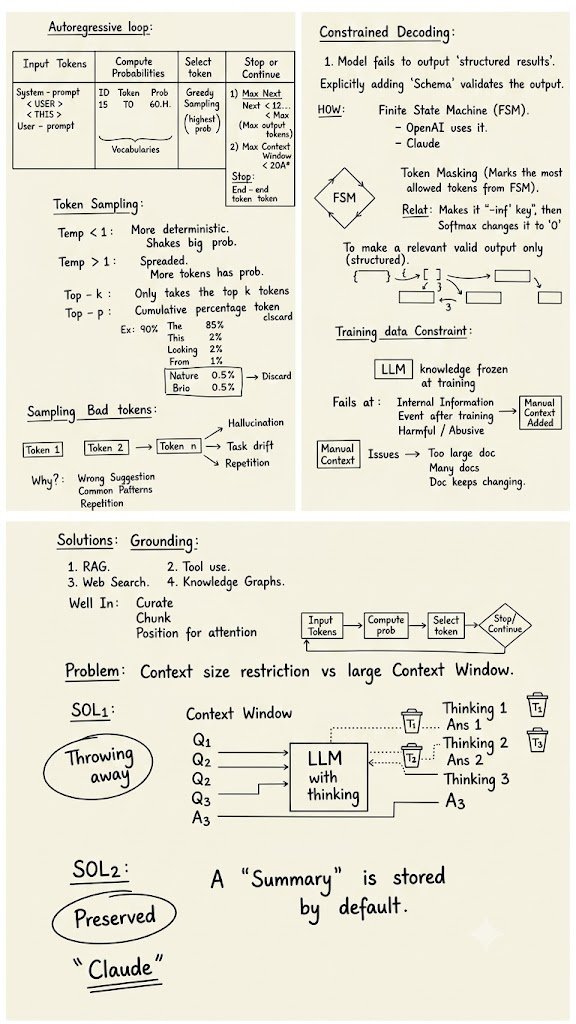
>Soft constraint prompting
>Constrained generation using outlines
>Chunking documents for retrieval
>Building a basic RAG pipeline
>Stress-testing RAG with different context budgets
The exercises were not too hard, but they helped me understand the actual coding flow behind RAG systems.
Deeplearning.ai course is useful !!
tips : Join AMD developer program to get it for 1 month pro for free (no promotion)
handwritten notes polished with Gemini🔥
1
24
Jun 8
Day 7 of Harkirat's DevOps Course
Today's session was all about Auto Scaling, AWS Elastic Beanstalk, Docker, and understanding the path toward Kubernetes.
> Configured CPU-based auto scaling policies and watched AWS automatically spin up new EC2 instances when load increased
> Understood the difference between manual scaling and automated scaling strategies
Docker & Containerization 🐳
> Learned why containerization is important before deployment
> Wrote a Dockerfile for a Next.js application
> Built and tested Docker images locally
> Published Docker images to Docker Hub
1
23
Sidharth retweeted

7 Oct 2023
if you value intelligence above all other human qualities, you’re gonna have a bad time
799
2,422
17,721
9,194,092
Jun 8
Me watching this
175B parameters? Not bad
300B training tokens? Figured out.
3.2M batch size? 😂😂😂
Andrej smiles at the 3.2M batch size.
Me on my 3090: batch size ___ . pray. 🕯️
28
Jun 7
Weekend update:
Watched Karpathy's "Let's Build nanoGPT" again.
I had already watched it and even coded it by hand back in my 2nd year. But after watching it today, I realized I can't remember most of the concepts anymore. It all felt surprisingly new.
That was a wake-up call.
I've decided to go back and grind the fundamentals again, revisit the Attention Is All You Need paper, rebuild my understanding from first principles, and get hands on with the implementations.
Some pretraining -> pretraining -> pretraining
Going to do this in parallel with my DevOps course.
34
Jun 3
Day 6 (Part 2) – Understanding Autoscaling
Today I learned an important infrastructure lesson:
A self-hosted application running on a single machine doesn't magically scale.
PaaS platforms can handle autoscaling automatically, but that convenience comes at a cost.
Then I explored AWS solutions:
🔹 Auto Scaling Groups (ASG)
>Add instances when CPU utilization exceeds a threshold (e.g., 50%)
>Remove instances when utilization drops (e.g., 10%)
While powerful, ASGs require additional configuration and management.
A simpler approach:
🔹AWS Elastic Beanstalk
Upload your source code and AWS manages much of the infrastructure for you, including scaling-related components.
Key concepts I explored:
• Environment configuration
• IAM Roles
• Instances
• Infrastructure management
Jun 3

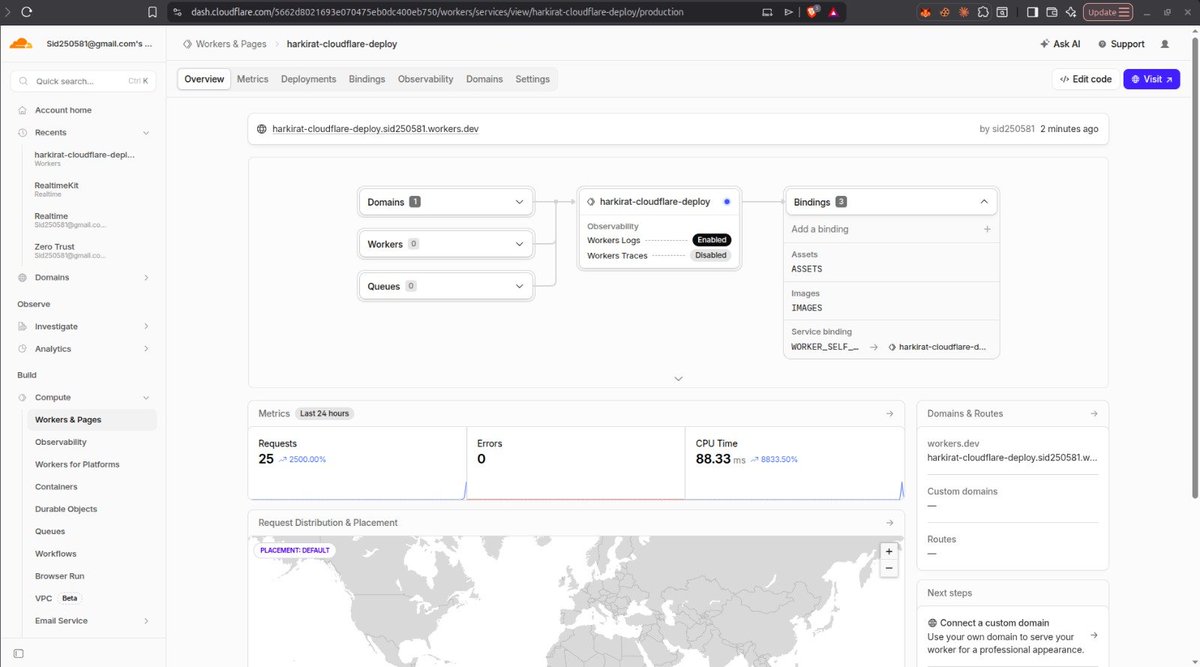
Day 6 of my DevOps course
Today was all about deployment and infrastructure.
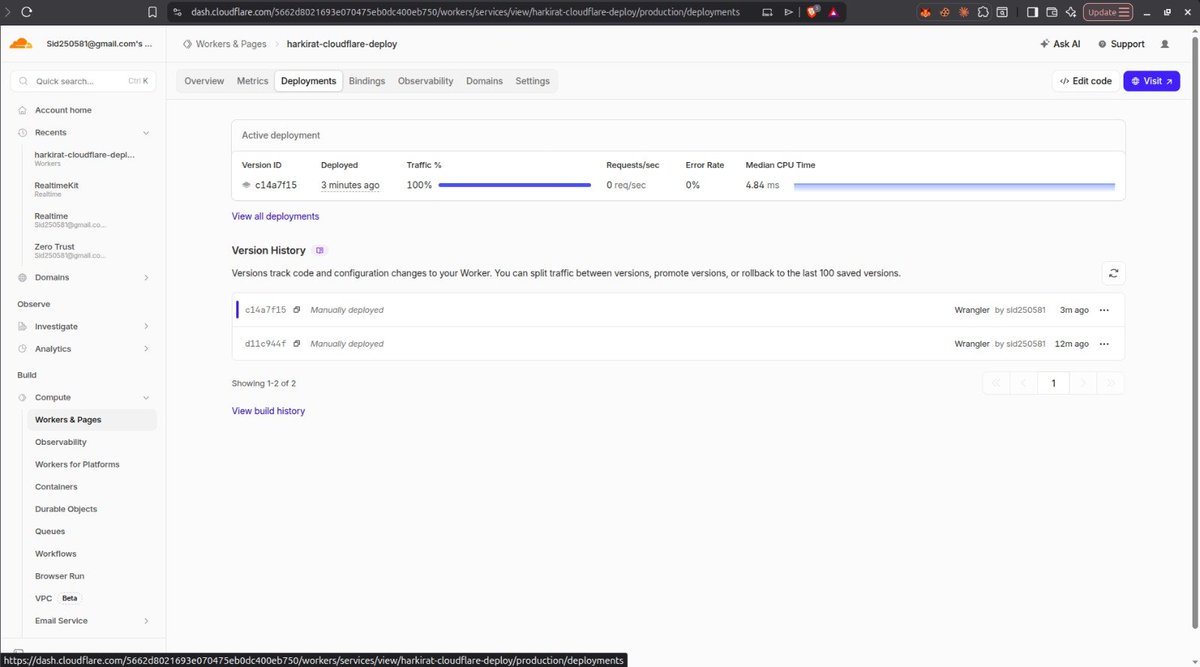
> Migrated a React.js app to Next.js
> Deployed the Next.js app on Cloudflare
> Deployed the same app on an AWS VM
> Self-hosted it on my own home machine (yes, from my own network)
Then connected everything using Cloudflare Tunnel:
🔹 Created and connected a tunnel
🔹 Added custom domains and subdomains
🔹 Let Cloudflare handle the routing and networking
Every day I'm understanding a little more of what happens behind the scenes when we type a URL into a browser.
1
34
Jun 3
Day 6 of my DevOps course
Today was all about deployment and infrastructure.
> Migrated a React.js app to Next.js
> Deployed the Next.js app on Cloudflare
> Deployed the same app on an AWS VM
> Self-hosted it on my own home machine (yes, from my own network)
Then connected everything using Cloudflare Tunnel:
🔹 Created and connected a tunnel
🔹 Added custom domains and subdomains
🔹 Let Cloudflare handle the routing and networking
Every day I'm understanding a little more of what happens behind the scenes when we type a URL into a browser.
3
109
Jun 2
Day 5 of the DevOps course.
Deployed my React application using Object Storage CDN using bunny!
✅ Built the app with React
✅ Uploaded static assets(i.e dist folder) to an Object Store
✅ Connected a CDN for global content delivery
✅ Added a custom domain with SSL
✅ Learned how caching and edge locations improve performance
Instead of relying solely on traditional servers, I explored how modern web apps can scale efficiently using CDNs and Object Storage.
Takehome :
First user in Chennai hits your site → request travels to your US server → response cached at Chennai's POP
Every user after that? Gets it from Cehnnai. Never touches your origin.
That's why YouTube doesn't run on EC2
1
50
Jun 2
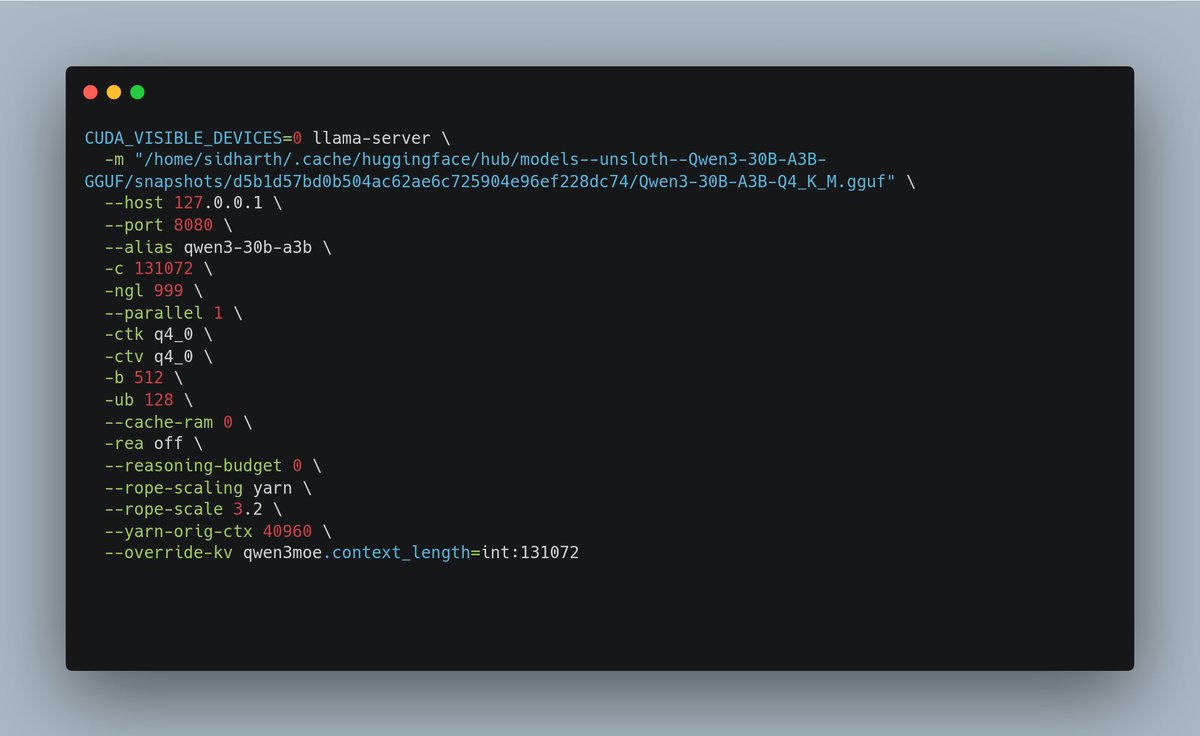
A llama.cpp/Qwen3 finding that cost me a few hours
Setting -c 131072 does NOT necessarily mean you're actually running with a 131K context window.
The thing that matters is the slot initialization line:
❌ slot load_model: ... n_ctx = 40960
✅ slot load_model: ... n_ctx = 131072
Fix:
--rope-scaling yarn
--rope-scale 3.2
--yarn-orig-ctx 40960
--override-kv qwen3moe.context_length=int:131072
Now 21 GiB VRAM, ~150 tok/s, 131k live
24
Jun 2
First time running an MoE model locally
Qwen3-30B-A3B (Q4_K_M GGUF) on an RTX 3090:
• ~150 tokens/sec
• 40K context
• Full GPU offload
• Reasoning budget: 0
Serves in llama.cpp
Coming from dense models, the latency difference is immediately noticeable.
1
35
Jun 1
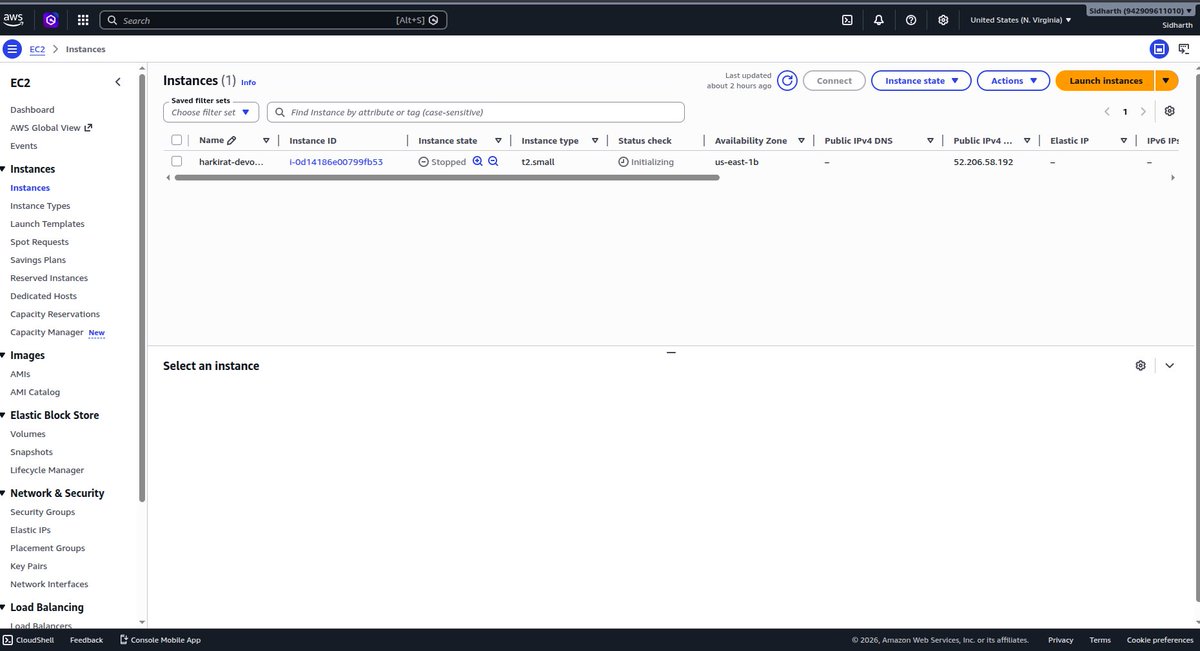
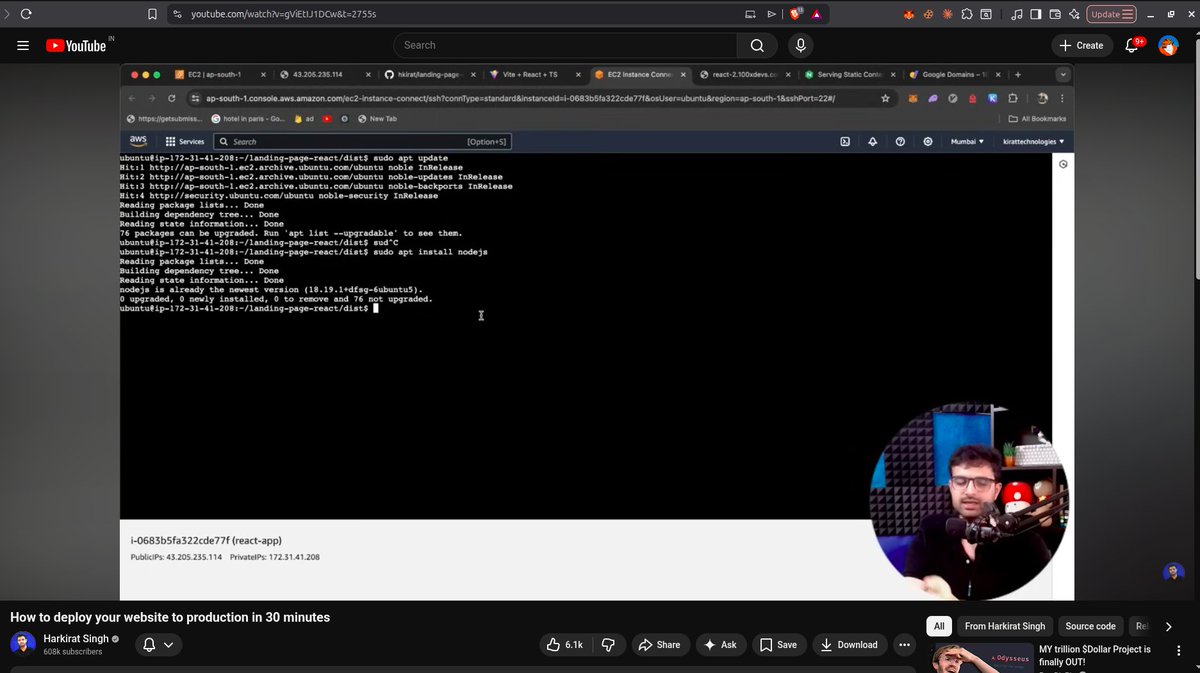
Day 4 of DevOps course.
Today I deployed a pure frontend on an AWS EC2 instance. Spun up the instance, built it, served it on port 3000, and tried opening it with the public IPv4 address. It didn't load.
Turns out AWS blocks all ports by default. Had to go into the security group.
Added an inbound rule for TCP on port 3000. After that it opened fine.
Assignment:
I added an SSL certificate using Certbot with Apache. So the site went from running on a raw IP and port to having a proper HTTPS setup.

4
289
May 31
Spent today on something that sounds boring but actually breaks your mental model of the internet
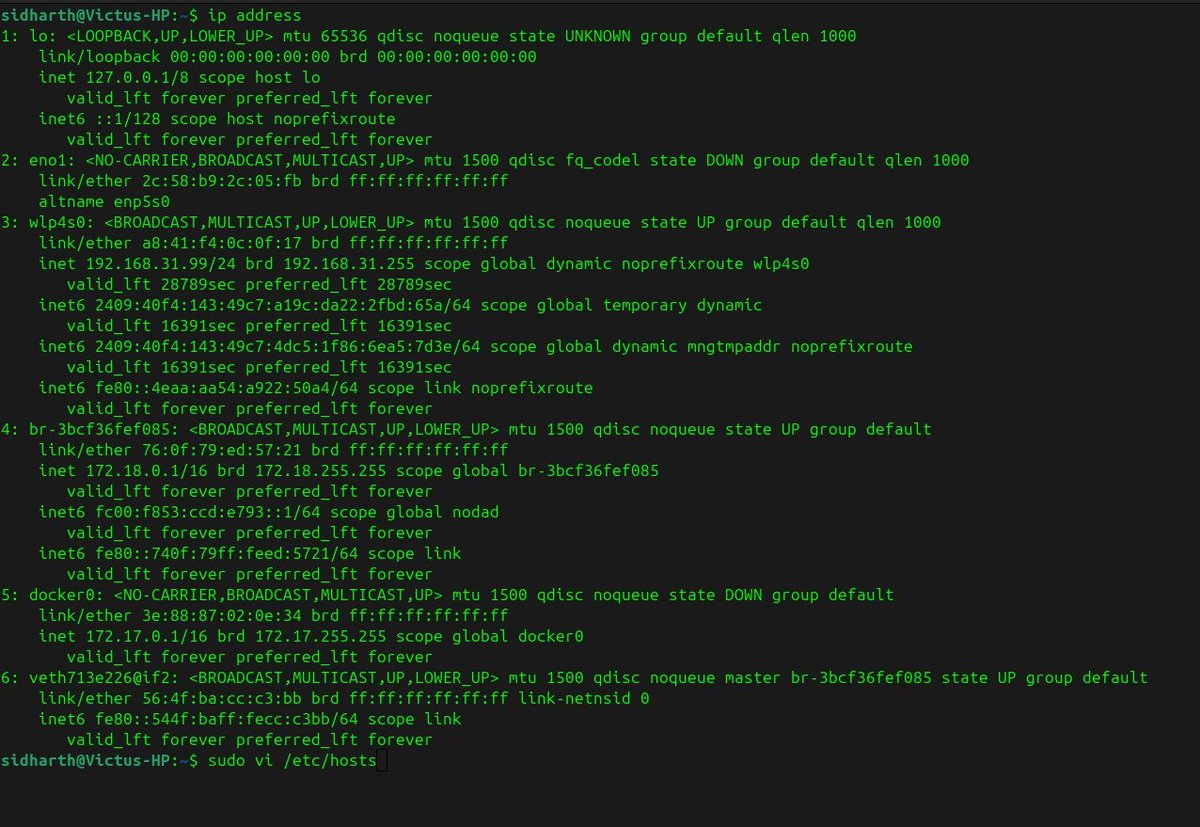
Day 3 of Devops course : the difference between a domain and an IP
Here's what clicked for me:
Your machine has 127.0.0.1. That's localhost. It loops back to itself. You can run a server and talk to it without touching the internet at all.
But your router also gives you a private IP something like 192.168.1.x. That one is real on your local network. Phone on the same WiFi? Hit that IP on port 3000.
Then there's /etc/hosts a file that existed before DNS and still wins over it.
Add 127.0.0.1 harkirat.100xdevs.com and your machine believes that domain is local.
The whole internet is just: IP → packet routing → domain abstraction on top
30
May 30
ASAP
May 30

X is killing x/LocalLLaMA Community tonight
We built the new permanent home
- links DOT theahmadosman DOT com/discord-server
That's where you go now

ALT Discord Server Invitation: https://links.theahmadosman.com/discord-server
1
50
May 27
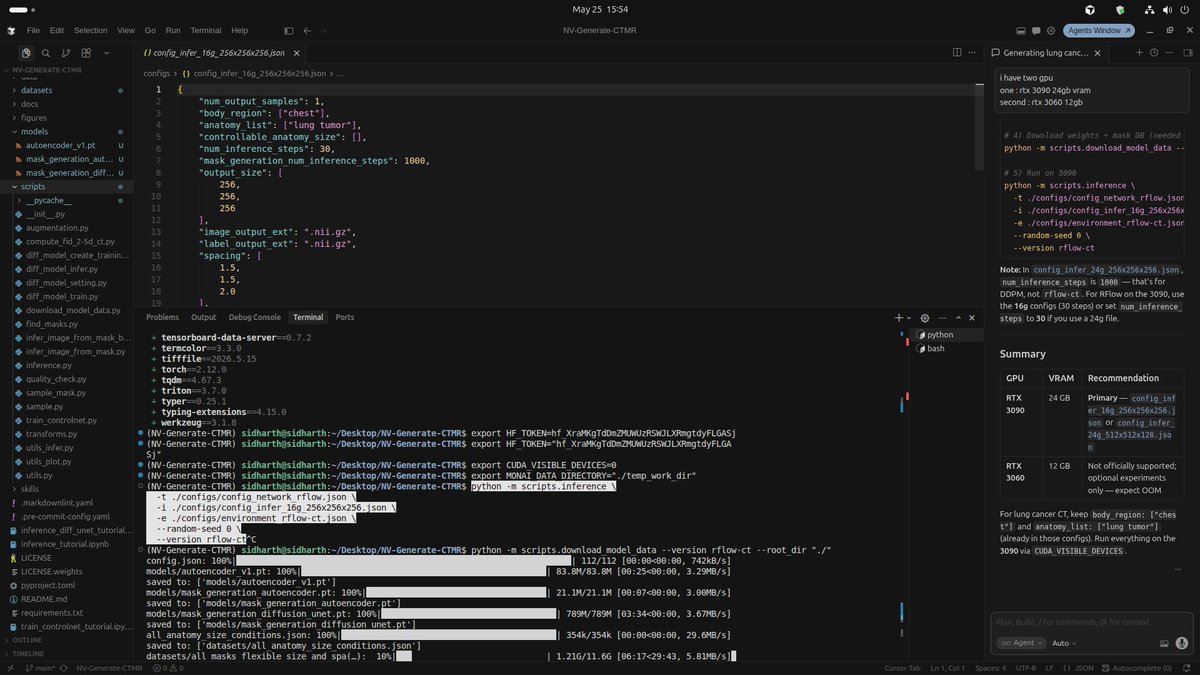
I don't know splitting a 31B dense model across a 3090 3060 is slower than just using the 3090 alone
Memory bandwidth mismatch destroys any VRAM gain. The 3060 contributed extra VRAM on paper but the communication overhead between GPUs was worse than just offloading 2–3 layers to RAM and staying on one card.
Dual GPU MTP even crashed mid-run:
GGML_ASSERT failed → ggml_reshape_3d → llm_build_gemma4_mtp
The fix: SPLIT_MODE=none, MAIN_GPU=0, PARALLEL=1. Single 3090. That's it
42
May 27
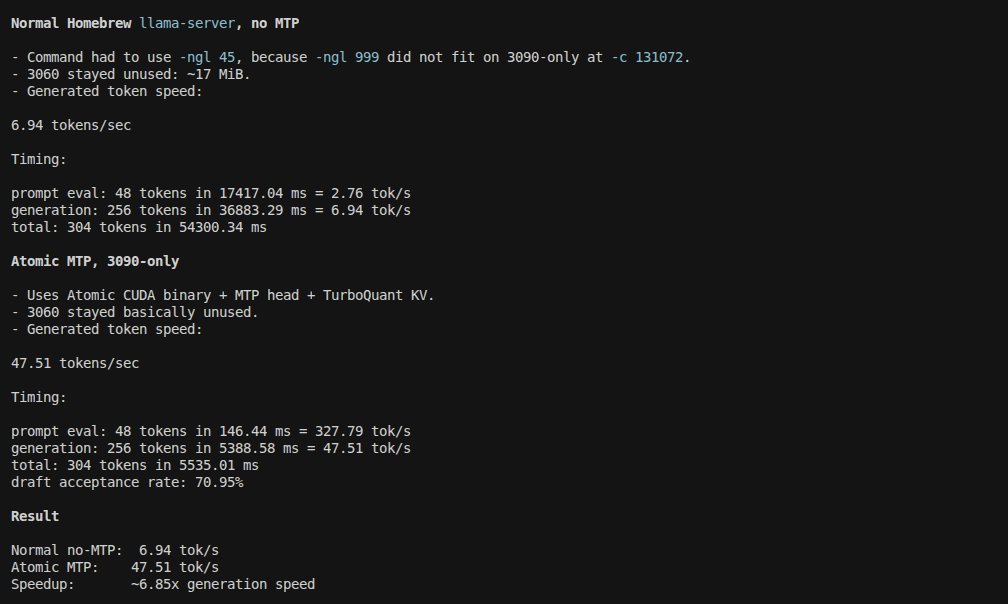
6.85x faster generation on Gemma 4 31B same RTX 3090, same context window
Atomic llama-server with MTP heads:
> 47.51 tok/s generated
> 327 tok/s prompt processing
Homebrew llama-server, no MTP:
> 6.94 tok/s
> partial CPU offload.
Key differences that actually matter:
> MTP (Multi-Token Prediction) heads enabled vs disabled
> TurboQuant KV cache fits everything on-device at 131k context
> Atomic build: -ngl 999, no CPU spillover.
>Homebrew: forced -ngl 45
VRAM profile at 131k ctx:
Model: ~17.5 GiB
Context: ~2.2 GiB
Compute: ~0.5 GiB
Free: ~3.1 GiB headroom → enough to push to 262k context
🔴Tested 262144 context on the 3090. It holds at 40-45 tok/s with -b 1024 -ub 256. That's 262k tokens of active context on consumer hardware, no degradation in generation speed.
If VRAM is tight at 262k, ladder down: reduce batch buffers first (-b 512 -ub 128), then try turbo2 KV cache, then pull a few layers to RAM. Avoid touching --parallel keep it at 1.
The 3090 is genuinely underrated for 31B inference if you're running the right stack.
Anyone else benchmarking MTP vs non-MTP on llama.cpp builds?
Curious if the gap holds on 4090s or if it closes.
1
138