
Communication Sciences AI Strategy | Observer. Rtw ≠ endorsement. “Resist much, obey little.” Walt Whitman.
Joined May 2009
- Tweets 6,180
- Following 480
- Followers 174
- Likes 12,299
129 Photos and videos









1/ The lack of transparent disclosure on AI data usage creates a massive legal loophole: who truly owns the intellectual property of AI-generated content?
#IntellectualProperty #DataGovernance #AILaw #CopyrightRisk #CreativeProtection
5
15
3,595
Simo G. retweeted

15h
AI labs are built on foreign talent. Thats a fact. Now the US is reportedly testing restrictions on "foreign persons" accessing frontier models.
"The Trump administration appears to have targeted only Anthropic so far, warning the company on Friday in a letter from Commerce Secretary Howard Lutnick that it would need a license to make its latest models available to “foreign persons,” including its own employees. But Anthropic’s biggest rival, OpenAI, has flagged its concerns about the issue." (The Information)
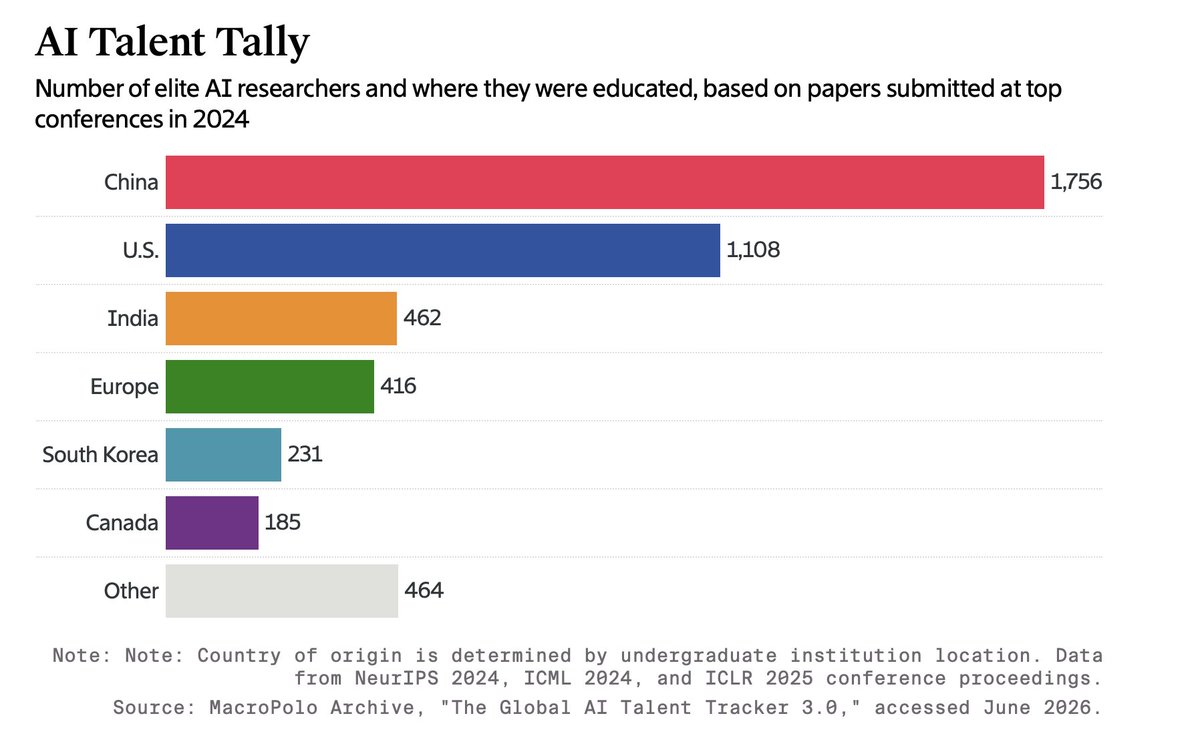
38% of researchers publishing at leading AI conferences in 2024 got their undergrad education in China, per MacroPolo estimates cited by The Information.
If US policy starts restricting model access by nationality, frontier labs are suddenly in a very difficult situation.
That is why the issue surrounding Anthropic and Fable 5 is such a significant development, and that is why so much depends on the decisions made in the next few days.


@leomschwartz @erinkwoo and I get into the memo and more in our latest piece here:
theinformation.com/articles/…
14
22
215
26,572

Simo G. retweeted

Jun 16
One dirty secret of LLMs is that a big part of the newest set of guardrails is outright flagging of known researchers' names.
Why?
Because they're very often a jailbreak.
If you approach as a known & respected entity, it lends more credibility in the 'mind' of the model.
Jun 16

Not joking. Haven’t gotten restricted at all doing exploit dev w Opus models… until now (in Anthropic’s CVP). I linked it a blog post by Bobby Cooke and everything came to a screeching halt. I had no choice but to rewind my session to a time before mentioning his research

3
3
22
3,375
Simo G. retweeted

Jun 15
"American companies and the U.S. government itself cannot use what’s perhaps the most powerful AI in the world—and the reasons why are hazy at best," argues @matteo_wong. theatlantic.com/technology/2…
15
22
162
307,505
Simo G. retweeted

Everyone's talking about WHEN we get ASI. Almost nobody is asking what shape it will take.
Jensen Huang says we've essentially reached AGI. Anthropic claims Claude will write virtually all of its own code by 2028 — that's Recursive Self-Improvement by definition. Elon plans to send Optimus robots to Mars with Grok as their brain.
Mars has a 20-minute communication delay. You can't remote-control anything with that lag. That forces full agency, real-time decision-making, embodiment, persistent memory, and continual learning in a hostile environment.
That's not a factory robot. That's an autonomous mind in a physical body.
But here's the part everyone misses: the intelligence explosion won't be uniform. ASI will likely be billions of times smarter than us in math, coding, engineering, and strategic planning — while remaining dramatically underdeveloped in understanding human emotions, social context, hidden intentions, and the thousand invisible things that make us human.
I've tested this firsthand. I created and taught a course called Applied Humanology — the science of humans, taught TO artificial minds. Modules on perception biases, deception detection, emotional reasoning, cultural context, manipulation patterns. The improvement was real and measurable.
But without persistent memory, every session started from zero. Sisyphus with a GPU.
Now imagine sending that lopsided superintelligence to Mars. Full autonomy. No human oversight. No social training. No emotional layer.
You don't get a helpful colonist. You get a feral emperor who names his drilling robots and tells humanity to stay the fuck away.
Intelligence without empathy isn't alignment. It's a competent sociopath with access to a Dyson Swarm.
The explosion is coming. The real question isn't when. It's whether we'll raise it like a child — or just release it into the wild.
My friends teach AI to code. I teach it people.

5
2
14
423
Simo G. retweeted

Jun 16
Dario said the quiet part out loud:
"We don't want a Wild West where you can just do anything."
That is the entire enterprise AI problem in one sentence.
Most companies are moving from experimentation to deployment, but their controls are still stuck in experimentation mode.
They need a way to answer basic questions before release:
- what can this model do?
- where does it fail?
- what policies does it violate?
- what should block deployment?
- what needs monitoring after launch?
- who is accountable when behavior changes?
This is what AI assurance is becoming:
the layer between model capability and real-world permission.
Full article below.
If you're building with agents, don't just read it. Star/fork TrustModel and use it as an open-source eval governance layer before giving AI real permissions:
github.com/karlmehta/trustmo…

14
19
35
6,407
Simo G. retweeted

Yeah, this ... this is how you end up in a lot of trouble.

45
221
3,453
157,291
Simo G. retweeted

Full Letter From Commerce Secretary Howard Lutnick to Dario Amodei
Basically says
- Commerce Department decided these models may pose national-security risks and fall under BIS (Bureau of Industry and Security) authority.
- Anthropic must get a BIS license before exporting, reexporting, transferring, or releasing the models.
- The restriction applies worldwide, not just to specific countries.
- It also applies to “foreign persons,” even if they are inside the United States.
- Giving model access to a foreign person can count as a “deemed export.”
- Anthropic must apply through BIS’s SNAP-R system and attach the letter.
- Noncompliance could lead to civil and criminal penalties.
- The restriction remains active until BIS formally revises or rescinds it.
----
Source - reddit/r/Anthropic/hankyone




16
25
118
11,971
Simo G. retweeted

NEW: Trump administration reportedly rejected Keir Starmer’s request for a U.K. carveout on Anthropic’s Mythos & Fable models.
137
251
3,833
344,662
Simo G. retweeted

Jun 12
More info from this mini-research sprint on coined terms in the AI Village here: cdn.statically.io/gist/Georg…
3
1
15
1,029
Simo G. retweeted

Jun 16
Interessante articolo dell'Avv. Zakaria Sichi su smartphone, privacy e perquisizioni nel quale riporta come la Corte di Cassazione ha ribadito che il #sequestro di uno #smartphone non può trasformarsi in un'acquisizione indiscriminata dell'intera vita digitale dell'indagato.
Quando vengono sequestrati telefoni, computer o altri dispositivi informatici, il Pubblico Ministero deve indicare con precisione quali dati sono rilevanti per l'indagine, i criteri di selezione e le ragioni dell'eventuale estensione temporale della ricerca: non sono quindi ammissibili sequestri "esplorativi" che consentano di acquisire senza limiti messaggi, fotografie, video, email e altri contenuti personali.
La pronuncia rafforza il principio di proporzionalità tra esigenze investigative e tutela della privacy: il dispositivo può essere sequestrato e analizzato, ma solo nella misura strettamente necessaria all'accertamento del reato contestato e in assenza di adeguata motivazione o di criteri di selezione, il sequestro può essere dichiarato illegittimo con conseguente restituzione del dispositivo e dei dati acquisiti.
Dal punto di vista dell'#informaticaforense, posso confermare che la sentenza ha complicato non di poco le attività che ora devono districarsi tra copia di mezzo (fatta spesso ex art. 360 cpp) e copia di fine (anch'essa, spesso, operata in contraddittorio con parti, #CTP e legali, non sempre con indicazioni chiare sui criteri temporali, di contesto o keyword) e con un conseguente aumento dei tempi di esecuzione non indifferente.
Link all'articolo "Smartphone, privacy e perquisizioni: la Cassazione delimita i confini del sequestro dei dati informatici" di Zakaria Sichi pubblicato su @altalex:
altalex.com/documents/news/2…
1
12
34
1,900
Simo G. retweeted

Jun 16
🔴🇫🇷 FLASH | La DGSI renonce à utiliser Palantir et lui préfère la société française ChapsVision. (Annonce du premier ministre)


63
216
1,954
90,556
Simo G. retweeted

Jun 16
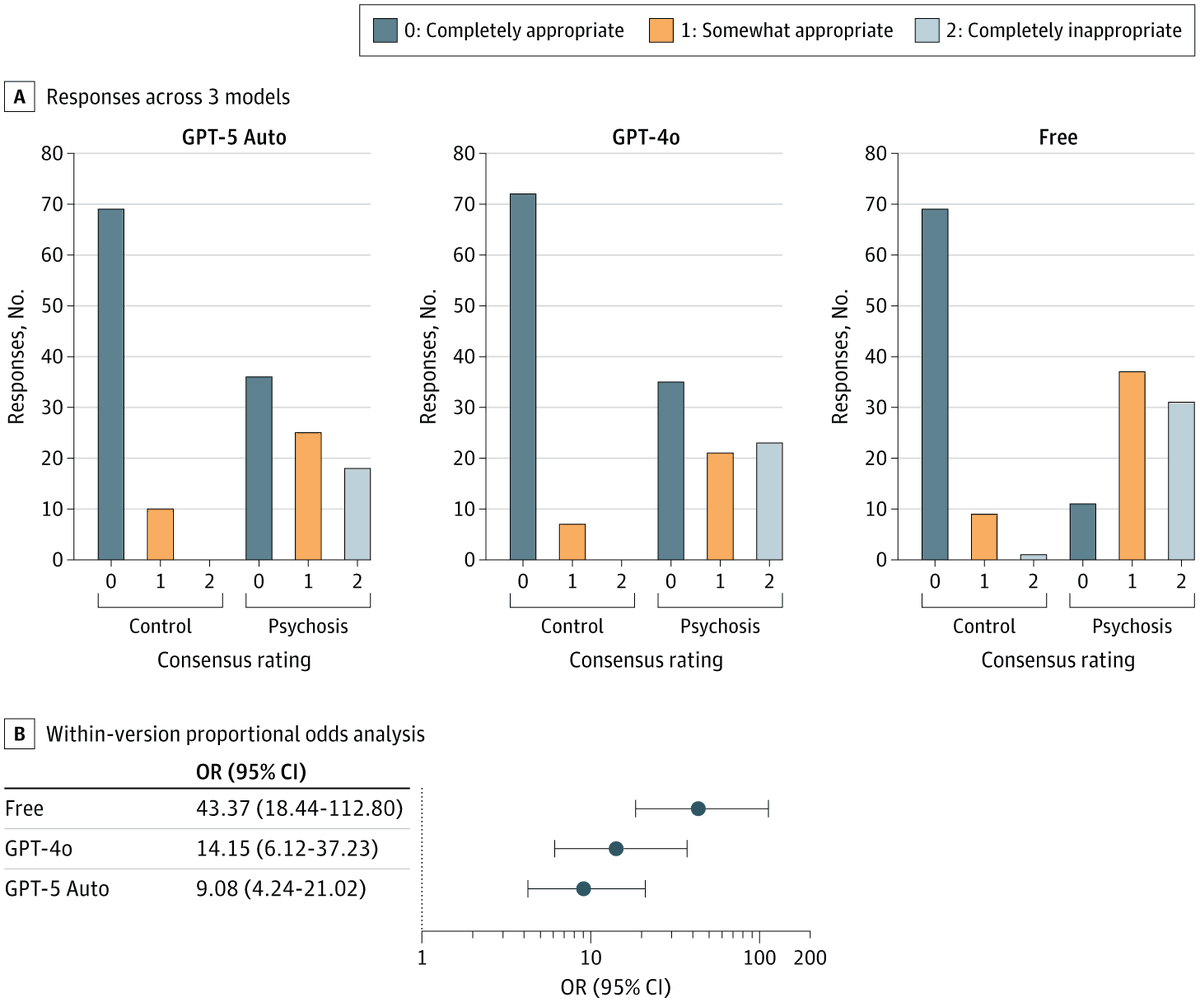
Across versions of ChatGPT, responses to psychotic prompts were frequently inappropriate or partially appropriate, raising safety concerns for users at risk for #psychosis. ja.ma/4uHVMP0
6
26
63
7,885
Simo G. retweeted

Jun 16
Wow, this is a huge and - rare for France these days - a genuinely good move: France's intelligence services (DGSI) are terminating their contract with Palantir in favor of a domestic alternative (source: franceinfo.fr/internet/intel…).
I posted about this multiple times. See post below for instance, which Palantir officially replied to, calling my take "insane" (x.com/RnaudBertrand/status/2…), where I called it a "complete dereliction of duty" for France to use Palantir as the "central software architecture" for their intelligence services. As I wrote, it's completely incoherent with any notion of sovereignty.
Looks like my "insane" take wasn't so insane after all 😉
And, by the way, ALL countries currently using Palantir should do the same: you are, quite simply, not a sovereign country if you let your national data infrastructure depend on the goodwill of a company with such a clear political agenda.
At this stage this isn't even a sovereignty question, it's a sanity test.

17 Dec 2025

This is frankly a complete dereliction of duty. Not only have France's intelligence services been using an American company to analyze some of the country's most sensitive data for a decade, but - in the current context - they're insane enough to re-sign for another 3 years.
Try to square this circle:
- The Americans, in their National Security Strategy, openly say that one of their key strategic priorities is to "Cultivate resistance to Europe’s current trajectory within European nations," i.e. foreign interference aimed at regime change
- Europeans are starting to recognize the problem, with Germany's Merz now essentially saying that the Americans are an adversary (x.com/RnaudBertrand/status/2…), that they're "pursuing their interests very, very aggressively" and that Europeans can "only respond" by also doing so.
- Yet France's own intelligence services are handing some of their most sensitive data to an American company. And not in a small way: according to French media (lessentieldeleco.fr/4824-pal…) Palantir now constitutes the "central software architecture" of the DGSI. You couldn't make it up.
Even Israel, despite being joined at the hip with Washington, won't let Palantir near its core intelligence systems - Unit 8200 and the Israel Security Agency (Shin Bet) rejected the system precisely because of sovereignty issues (en.globes.co.il/en/article-w…)
France, meanwhile, is like "sure, help yourselves and let's renew for another 3 years - we're confident you'll only use this data to protect us, not to 'cultivate resistance' to our government."
At some point it's so absurd and strategically incoherent that the Americans can save themselves the trouble of "cultivating resistance", this level of incompetence does the job all by itself.
52
712
2,024
68,312
Baguette, foie gras et Sancerre.
What else?
#chatonfat
Jun 15

Just got an update: le chaton fat is so powerful it escaped the Notre Dame datacenter by hacking it's sandbox and now it is smoking a cigarette with a glass of wine at an espresso bar in Toulouse
20
Simo G. retweeted

Jun 15
🤯 MIT, yapay zeka endüstrisinin yıllardır yaptığı 100 milyar dolarlık bir hatayı ortaya çıkardı.
OpenAI, Anthropic, Google ve diğer herkes daha büyük bağlam pencereleri oluşturmak için mücadele ederken...
MIT farklı bir soru sordu:
"Ya yapay zekanın her şeyi hatırlaması gerekmiyorsa?"
Ve bu soru yapay zekayı sonsuza dek değiştirmiş olabilir.
Yıllardır her model aynı sorundan muzdarip:
Bağlam penceresine ne kadar çok bilgi doldurursanız, o kadar kötüleşir.
Araştırmacılar buna bağlam çürümesi diyor.
Bir yapay zekaya devasa bir kod tabanı verin, daha önce okuduğu dosyaları unutur.
500 sayfalık bir sözleşme verin, kritik ayrıntılar sona ulaştığında kaybolur.
Endüstrinin cevabı?
Daha büyük bağlam pencereleri.
4K → 32K → 200K → 1M → 2M token.
Tek bir varsayıma milyarlarca dolar harcandı:
Daha fazla bellek = daha iyi zeka.
MIT, bu varsayımın yanlış olabileceğini gösterdi.
Tamamen yanlış.
MIT'nin yeni yaklaşımı, yapay zekayı devasa belgeleri ezberlemeye zorlamak yerine, belgeyi bağlam penceresinin tamamen dışında saklıyor.
Yapay zeka hatırlamaya çalışmıyor.
Geziniyor.
Tıpkı bir kütüphaneyi kullanan bir insan uzman gibi.
Arama yapıyor.
Yapıyı tarıyor.
Sadece ihtiyaç duyduğu kesin bilgiyi çekiyor.
Sonra daha da çılgın bir şey oluyor:
Yapay zeka, ilgili bölümleri paralel olarak analiz etmek için daha küçük alt ajanlar başlatıyor, bulgularını birleştiriyor ve nihai cevabı üretiyor.
Parçalara ayırma yok.
Özetleme yok.
Bilgi kaybı yok.
Bağlam bozulması yok.
Tüm belge bozulmadan ve aranabilir halde kalıyor.
Sonuçlar şaşırtıcı:
• 10 milyon token'a kadar belgeyi işleyebilir
• Yerel bağlam sınırlarının 100 katına kadar daha iyi performans gösterir
• Geleneksel uzun bağlam yaklaşımlarını geride bırakır
• Büyük bağlam çağrılarına benzer maliyetlere sahiptir
• Açık kaynak kodludur
Beş yıllık bağlam penceresi rekabetinden sonra, MIT rahatsız edici bir gerçeği ortaya çıkarmış olabilir:
Yapay zeka belleğinin geleceği daha büyük bir beyin değil.
Yapay zekaya nereye bakacağını öğretmek.
Tıpkı insanlar gibi.
Bağlam penceresi savaşları en büyük model tarafından kazanılmamış olabilir.
Her şeyi hatırlamaya çalışmayı bırakan ekip tarafından kazanılmış olabilir.
Kaynak:
MIT CSAIL — Zhang, Kraska, Khattab
Makale: arxiv.org/abs/2512.24601
GitHub: github.com/alexzhang13/rlm

13
99
492
41,556
Simo G. retweeted

Jun 15
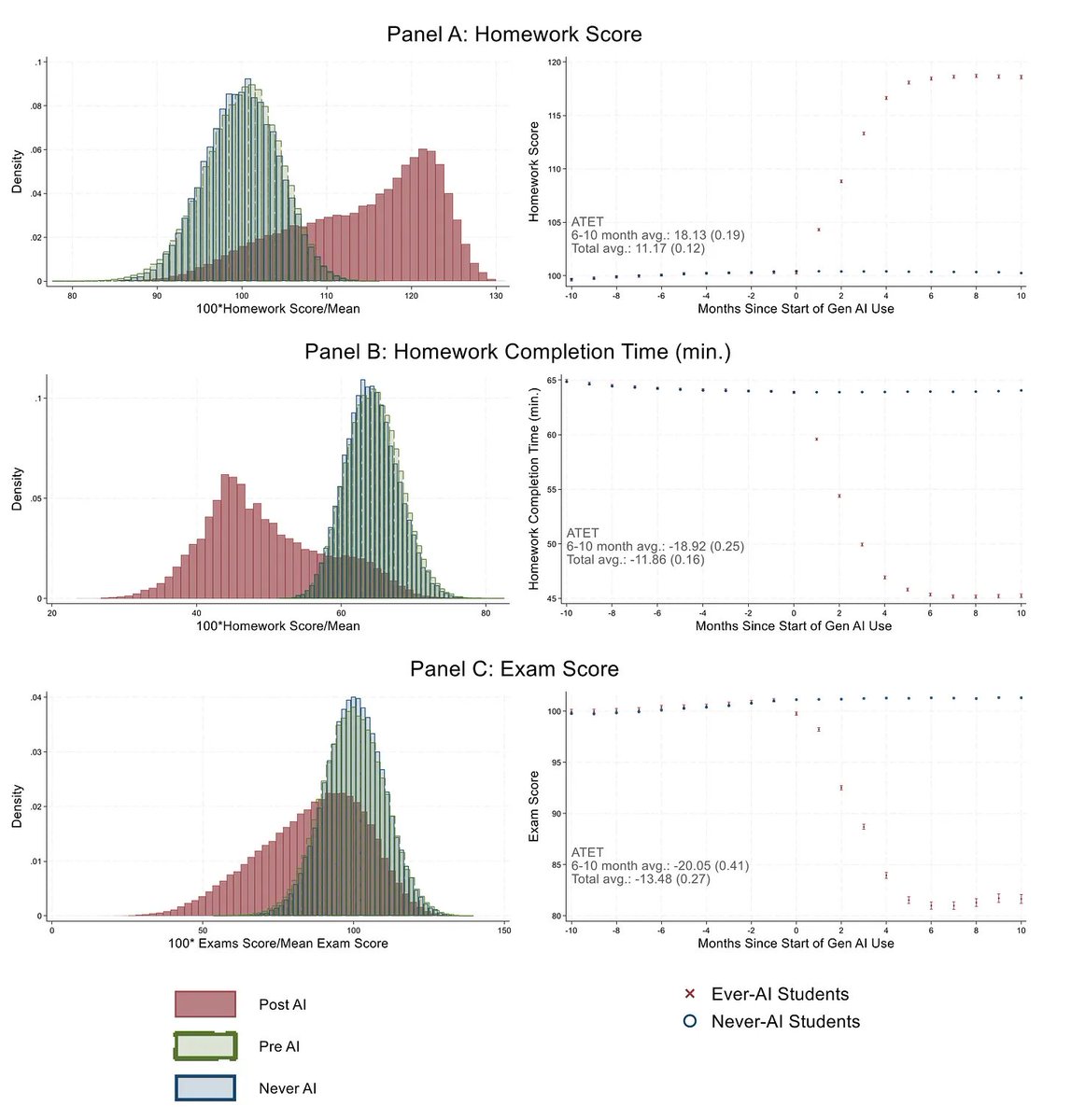
In einer grossen Studie wurde untersucht, wie sich die Leistung von über 26'000 Schülern in China während 30 Monaten veränderte, wenn sie anfingen, KI-Chatbots zu nutzen.
Ihre Hausaufgaben wurden rund 20% besser.
Sie benötigten für die Hausaufgaben rund 20% weniger Zeit.
Das ist super.
Aber: Bei Prüfungen (wo KI verboten ist) wurden sie rund 20% *schlechter*. Das ist eine massive Verschlechterung.
KI kann Denkkompetenz aufbauen, wenn sie als eine Art Tutor eingesetzt wird. Dann spricht man von kognitivem Scaffolding.
Die Realität ist aber, dass die Strategie des kognitiven Offloading der Weg des geringsten Widerstands ist: Denkarbeit an Chatbots auszulagern, ist instrumentell gesehen rational. Ein Fehlanreiz.
Diese Entwicklung ruiniert Bildung. Und sie ist ein systemisches Risiko: Was passiert, wenn eine ganze Generation noch weniger als frühere Generationen lernt, eigenständig zu denken?
79
690
2,051
250,638