
Devops Engineer learning and deploying everyday .
Joined January 2026
- Tweets 1,657
- Following 217
- Followers 116
- Likes 2,418
100 Photos and videos















These bs posts are getting so old . Are they even getting paid to make this trash ?

$2,800/month to a GPU rental company. now $8 of electricity.
a $1,499 AMD box Strix Halo, 128GB unified memory, 70B models on your desk.
most AI consultants rent cloud GPUs and hand 60% of every invoice back to Lambda.
the box didn't "make money." it turned a 30%-margin reseller into an 80-90%-margin product.
what actually changed it's not the box, it's what the box lets you sell:
/ one client's cloud bill went $2,800 → $8. same $4,200 invoice. margin tripled overnight.
/ migration was one line point the OpenAI client at localhost, zero app logic changed
/ the real unlock is the pitch: "your data physically lives in your office. not OpenAI's, not mine."
/ lawyers, dental, finance the NDA clients who can't touch cloud AI sign on that one sentence
cloud AI consulting is freelancing where the rental company takes the cut.
local AI consulting is a product at 80-90% margin with an argument nobody else can offer.
the box paid for itself in ~2 weeks. the business model is the actual $47K.
1
14
I have always wanted a trading bot thanks to Hermes Agent it's now running ! My Hyperliquid bot is an orderflow scalper on perps and HIP-3 markets. Entries come from volume z-scores, notional filters, and AdaptiveQuant sizing. Nemotron and other OpenSource models (through Nous protal) drive the signals and then review every closed trade to evolve the logic.
Full-port execution, max leverage, but the real risk rules (5% SL / 10% TP) are locked on my side. It reconciles positions properly for manual closes and weird asset names, then fires accurate updates to Telegram. Cheap VPS, 30-min cron optimizers, strictly live.
53

Jun 13
Do I keep running my $500 a month Gke lab and using their gpus or start using another provider? It was so nice having my whole lab, gpus and services in one cluster but damn $6k a year is a little much. I really need to monatize my skills ASAP . If anyone wants to get off the closed source teet hit me up ! github.com/sirius0xdev/gclou…
30
Lance retweeted

Jun 12
American is such a land of opportunity that:
1. Elon could come here with nothing and build companies that improve the lives of hundreds of millions of people.
And
2. Elizabeth could be in the U.S. Senate with a kindergarten level of understanding of the real world.
Jun 12

Elon Musk just became the world's first trillionaire.
The typical American household would have to work more than 11 MILLION years to make Elon Musk's level of wealth.
We need a wealth tax.
206
294
1,836
71,410
Jun 11
FML I have to find a way out of working in this. If anyone wants a dedicated cloud/infra engineer please hit me up .
27
Jun 11
🤣🤣
Jun 10

the year is 2028. claude infers whether you’ve ever even thought about gradient descent and silently routes your queries to Claude Sisyphus, a model RL’d to maximize engagement while avoiding task completion. you spend your entire UBI token allotment on it without ever realizing.
1
84
Jun 11
Built & operated with Hermes Agent fully automated Hyperliquid trading stack on an Akamai/Linode VPS in Singapore 🇸🇬
What's running:
- Nemotron-3-ultra
- DeepSeek V4 (via Nous Research inference API) for trade decisions & monitoring
- Hyperliquid perp bot orderflow scalping, SL/TP, max-hold exits, position reconciliation
- LLM-powered monitor (DeepSeek-V4 via Nous) analyzes 24h performance every 30min, auto-adjusts risk, watchlist, SL/TP and trading logic .
- Telegram alerts trade open/close, daily P&L, refinement summaries
- Dashboard (port 8001, Tailscale) risk config, secrets, watchlist, PnL, positions, trade history
Infra: $20/mo Akamai (Linode) VPS running Arch btw
Stack: Python, SQLite, Hyperliquid SDK, FastAPI, uvicorn, cron, Tailscale Serve all built, deployed, and operated via Hermes Agent
133
Jun 11
My dream job would be to work for an inference provider/lab that offers the best open source models . I have the skills and passion . github.com/sirius0xdev/gclou…
15
Jun 10
I've been using nemotron ultra for the last week . It's been very impressive. It'll run 30mins or more solving problems and debugging . So far it's solved everything I have thrown at it . Thanks @NVIDIAAI for leading the way for western OpenSource Ai .
1
1
8
1,438


Jun 4
If the dgx spark had thunderbolt 4 and could hook up to an egpu it would truly be the best device for AI home labs .
3
7
779
Jun 4
Finally an honest post about Mac minis and small consumer gpus .
Jun 4

HE SPENT DAYS TESTING MAC MINI 16G AGAINST RTX 4070TI ON LOCAL AI - AND THE HONEST NUMBERS ARE NOT WHAT ANYONE WANTS TO HEAR
two setups, same model - Mac Mini 16G vs RTX 4070Ti 12G running Qwen 3.5 9B - the best model that actually fits on either machine - Qwen 3.6 doesn't even load
4070Ti hits 65 TPS - Mac Mini hits 12 TPS and thinks for 2 minutes per response - both machines completely maxed, 4070Ti temperature jumped from 40°C to 60°C
he plugged the 9B model into Claude Code - tools don't work, basically useless for anything agentic
the real number nobody talks about - for Mac Mini to handle actual agentic workflows you need 48G memory and a 27-35B model with MLX - hardware that starts at $2,800 and up
his verdict after days of testing: local models eat money, eat time, small models are too weak and large models need a budget most people can't justify
short term - he's done with local models
most people think "I'll just run it locally" - he actually did it and the math doesn't work
2
72
Jun 3
DGX Sparks are sweet but they are not suitable for supporting a dev team . You'll get 15tks at 30k token context . It's a sweet addition to a home lab but not suitable for supporting a team .
32
Jun 3
This is hilarious. There's a reason inference providers don't run macs and use actual server grade hardware . Idk what type of scame business this dude is running but running small quantized to death models isnt competitive

DANIEL CHEN RACKED 1,000 MAC MINIS INTO A FULL AI DATA CENTER. ONE $599 BOX KILLS A $200/MONTH SUBSCRIPTION
daniel was paying $14,000 a month renting H100 servers in the cloud for his AI startup, the quality was magic but the burn rate was killing the runway
he did the math on running it locally and bought 1,000 mac mini m4s, racked them into a single facility pulling less total power than one nvidia server while delivering the same throughput
the mac mini m4 starts at $599 one time, pulls 10 to 20 watts running 24/7, and costs $3 a month in electricity while a windows AI machine doing the same job costs $30 to $50 a month just to stay on
ollama added support for the anthropic messages api in january 2026, so claude code itself connects to your local mac mini with one environment variable, same interface, zero API costs
apple stores ran out of mac minis in 2026 because $599 one time beats $200 a month forever, that shortage is the most honest product review any machine has ever received
the window is open, follow and bookmark before it closes.
32
May 30
It's been a lot of fun running my GKE lab and experimenting with vllm and all the Cloud Native Operators but after my second month of hitting a $500 bill it's time to call it quits . Learned a lot and hopefully I'll land some clients soon ! Back to manually bootstrapping some VPSs for the next cluster .
github.com/sirius0xdev/gclou…
20
May 27
I know I'm beating a dead horse but Qwen3.6-27b beats all the groks . It's crazy an OpenSource 27b model van beat one of the big dogs so badly .
41
May 27
Never use Grok to help with coding it will screw up everything it touches . Completly useless . It's amazing the even qwen3.6-27b is 100x more competent
28
May 25
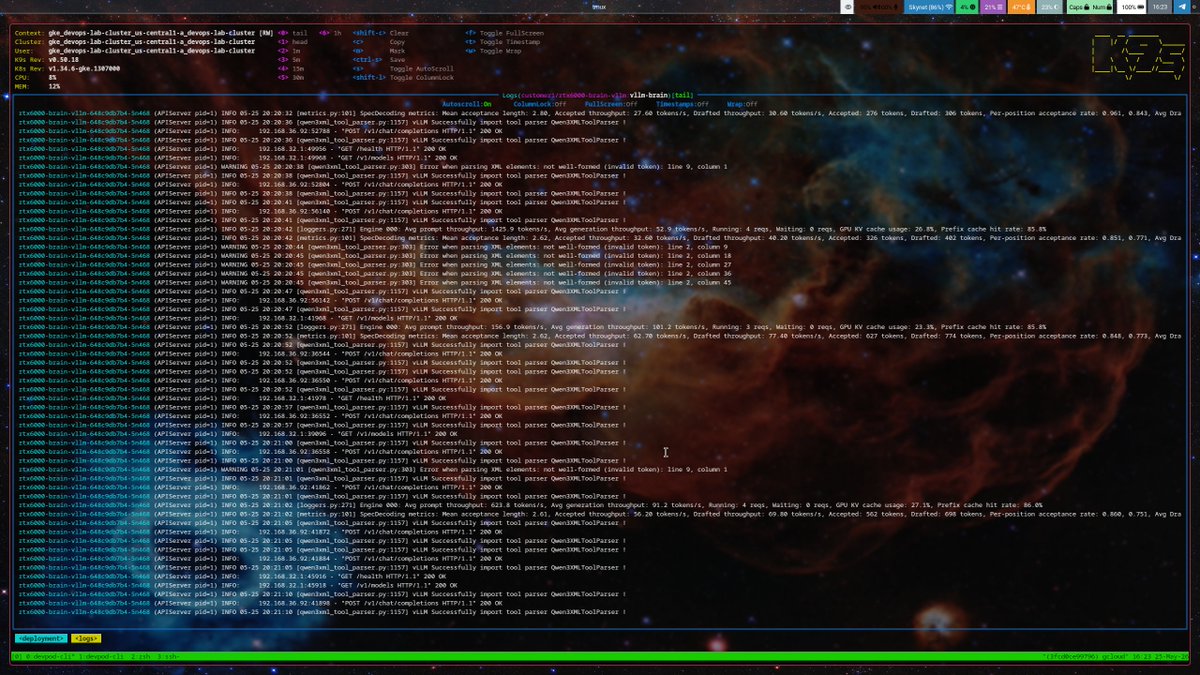
Pretty stoked to see >100TPS with 3 agents hitting the Rtx6000 at once . Full 256k context window and no kvcache quantization .
1
60