
Co-founder & CEO of Klassif.ai, an AI start-up offering an intelligent lead-to-cash solution for large companies I productivity I software I entrepreneurship
Joined October 2013
- Tweets 935
- Following 2,691
- Followers 577
- Likes 2,365
137 Photos and videos
















Antoine Smets retweeted

Apr 10
Running a company:
2020: can you survive a pandemic?
2021: still here? we’re going to give all of your competitors $100m series A rounds.
2022: wow, you made it? okay, all engineers cost $600,000/year now.
2023: nice job! okay, SVB failed and we’re going to take away your bank account.
2024: a survivor I see. but can you pivot from ai to crypto to defense tech back to ai-enabled defense tech in a 12 month period to stay relevant?
2025: unfortunately all of your competitors have raised $2b series B rounds. oh and only 500 engineers are relevant and they cost $100m/yr each.
2026: well, well, well. you’re still in business? let’s deploy the thunderclap of godlike LLMs from the heavens so all of your customers can rebuild your app in 2 hours. can you survive?
187
567
6,784
871,036
Antoine Smets retweeted

20 Oct 2025
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...
20 Oct 2025

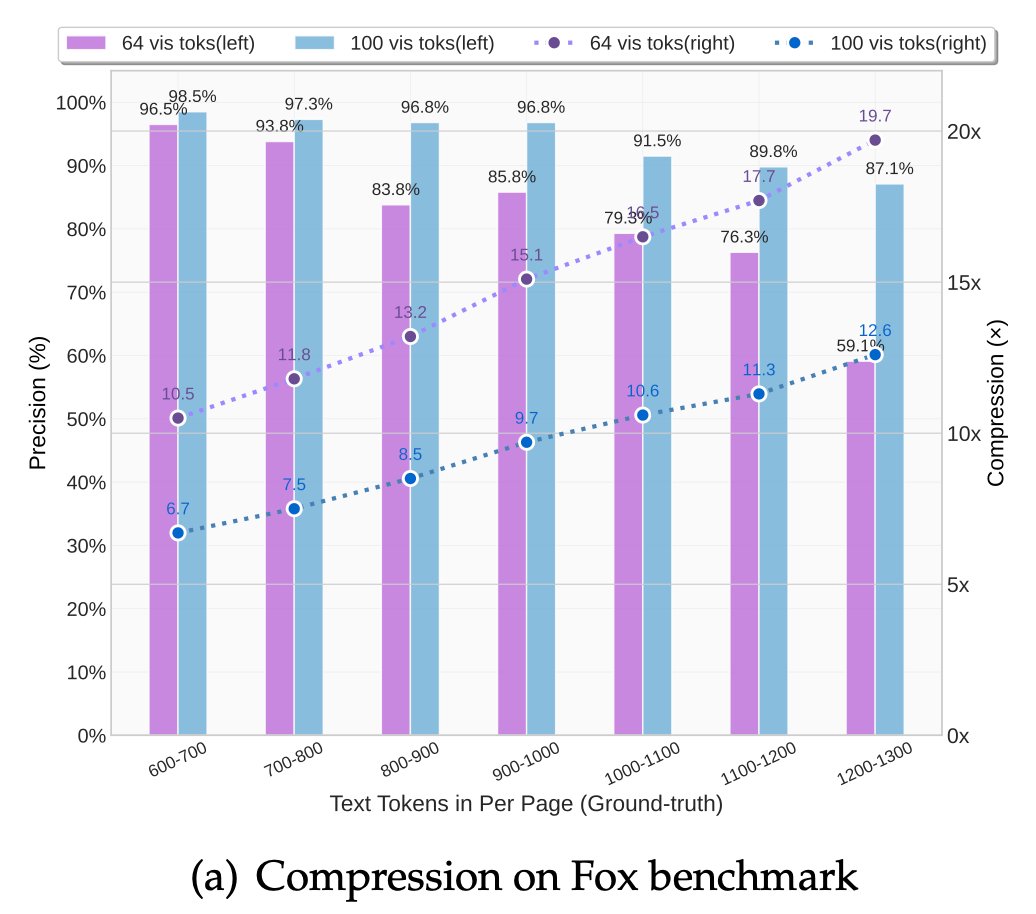
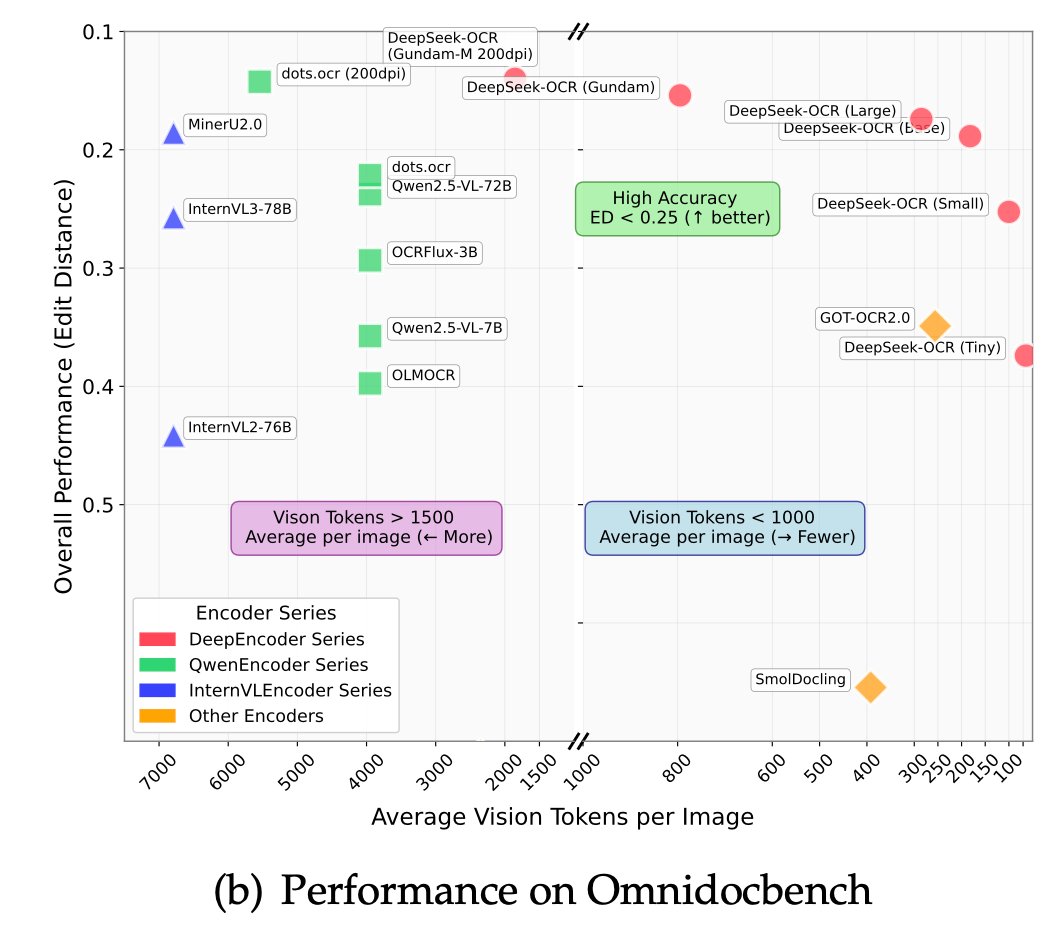
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 github.com/deepseek-ai/DeepS…
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning

558
1,559
13,283
3,329,731

I don’t think it’s too late to enter almost any software market with an LLM-powered alternative if you want to.
We are seeing tiny teams of a few people build valuable software leapfrogging incumbents with even today’s frontier models (get enterprise sales)
The war will be retention: who can serve your vertical better?
21 Jul 2024

I've been investigating vertical AI startups profoundly for the past few weeks. I think we're in a very strange part of the cycle in AI startup funding/development. Some thoughts (hot takes?)
1. Literally every vertical (finance, law, healthcare etc) is now populated with AI startups building on top of foundation models. If you start today, it's too late to get first-mover advantage.
2. However, foundation models are still not quite there yet to solve problems in these verticals in a tangible, bulletproof way. Those who built GPT wrappers (even if they refuse to admit the label...) rely on OpenAI's next big model to truly prove sticky long-term retention. And those who decided to train their own specialized models (like Harvey) are apparently not outperforming smart general models (GPT-4o, Claude 3.5 Sonnet).
3. Startups are facing a massive dependence on big AI labs shipping the next big model. And once that happens, it might just be that we won't need GPT-wrappers at all. ChatGPT will be enough for whatever task we hand them.
4. This is fundamentally so different from the internet and mobile innovation cycles. Back then, incumbents could not touch every single vertical with their product offerings, so startups filled in the void and became multi-billion dollar companies (e.g. Apple launched the app store, but wouldn't build apps for food delivery, dating, ride-sharing etc). Now, when GPT-5 launches, OpenAI can touch virtually every industry they want.
5. My sentiment is that we're living a kind of "born too late to explore the Earth, born too early to explore space" vibe in this 23-24 cycle in the realm of AI startups. And when the rocket ships to space are finally ready (i.e. truly smart general LLMs), vertical AI startups will capture much less value vs. incumbents when compared to previous cycles.
52
64
1,028
284,951
Antoine Smets retweeted

18 Dec 2023
Build the business you wouldn’t trade for anyone else’s business.
23
73
505
98,162
Antoine Smets retweeted

9 Nov 2023
Two ways for an AI company to protect itself from competition: (a) depend not just on AI but also deep domain knowledge about a particular field, (b) have a very close relationship with the end users.
206
521
4,137
933,047
Antoine Smets retweeted

16 Jul 2023
Contradictory things I believe:
1. the world is tiny / the world is huge
2. life is short / life is long
3. future is mundane / future is weird
1.
People everywhere are increasingly similar. You can easily know everyone in the top of any field. Powerful people are a small global community. The world feels small.
No matter how niche an interest is, you can find millions like you. The long tail of differences between people and cultures is astounding. And there are endless places with gripping histories to learn about. The world feels big.
2.
You can fully count your days. The number of vacations you will take, the number of times you will visit your parents, and the number of days you have your kids with you at home are painfully limited. Life feels short.
You can live many lives in one. Change careers, compete in sports, build a business or two—maybe attempt to change the world. Life is plenty.
3.
Reading history I’m struck by how little changes. People dealt with the same problems: they loved, laughed, and mourned. We have the same unanswered questions about meaning. And with the exception of new gadgets our lives rarely change. The future is mundane.
While we don’t have flying cars, we’ve created entirely new worlds: virtual worlds. We live insanely different media lives and that changes everything. We’re tapping deep into the human Id and materializing strange desires into hyperreality. The future is weird.
29
98
957
163,496
Antoine Smets retweeted

6 Nov 2022
It's been an insane year in AI. To try and understand what's going on, I asked 10 awesome investors what trends and companies to watch out for.
Here's what they said 👇 🧠
🔗 generalist.com/briefing/what…

14
61
316
Antoine Smets retweeted

20 Jul 2022
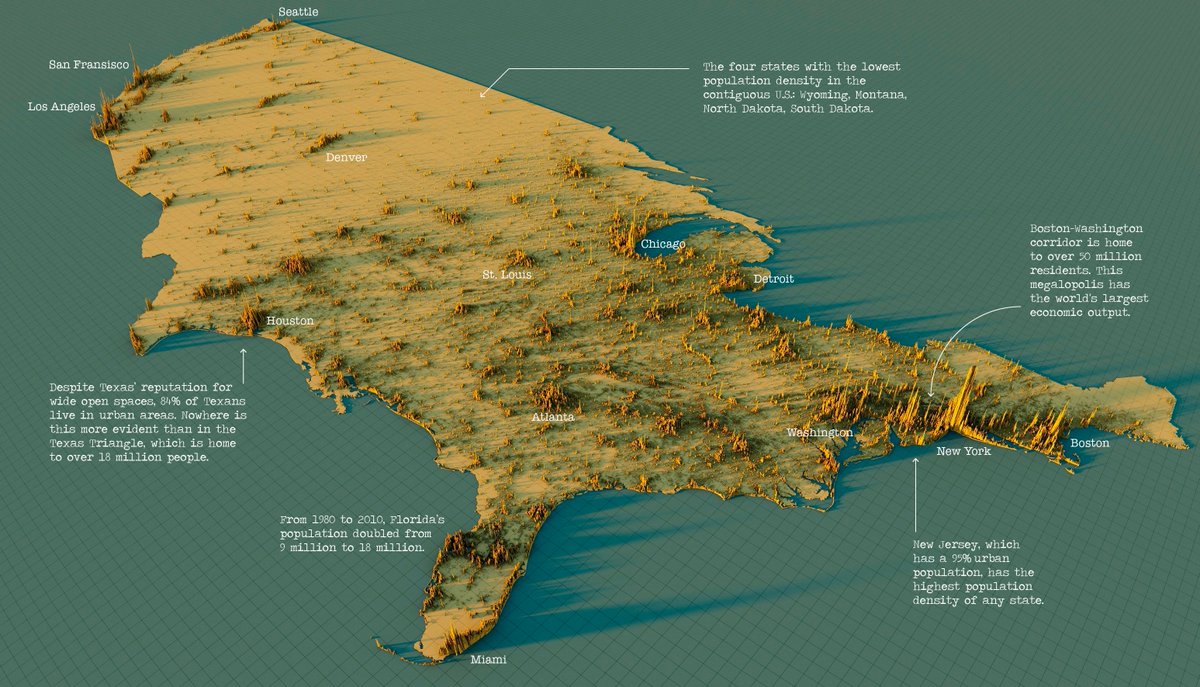
And some specifics by @VisualCap.
The US is pretty undense:
51
331
3,908
Antoine Smets retweeted

25 Mar 2022
I’ve made 100 hyper-visuals in 90 days.
Here are my 10 most popular ones:
56
394
1,839
Antoine Smets retweeted

5 Jan 2020
Consider: millions of years ago our antecedents gave a massive sacrifice of their left hemisphere.
We lost a tremendous amount of short term memory and replaced it with Broca’s, Wernicke & the phonological loop.
But why?
So we can—talk.
Thus chimpanzees can do this—we can’t:
821
29,581
84,741
Antoine Smets retweeted

12 Apr 2020
Priority Management Mental Model - This is how I organize everything in my life. I have a separate one of these filled out for the Physical, Intellectual, Social and Artistic parts of my life (PISA).

46
682
3,358
Antoine Smets retweeted

5 Feb 2022
How to stop procrastinating:
884
4,515
22,553

Antoine Smets retweeted

11 Oct 2021
There are currently over 1.86 Billion websites.
Few provide any real value.
Here are 7 that do: 🧵
255
7,247
23,084
Antoine Smets retweeted

5 Apr 2021
Some paradoxes of modern life:
1. The paradox of reading: The books you read will profoundly change you even though you’ll forget the vast majority of what you read.
213
6,861
22,350
