
Joined December 2019
- Tweets 2,141
- Following 548
- Followers 1,150
- Likes 473
200 Photos and videos








这个人开发了一个AI工具;
能站到你的屏幕旁边:直接画线、指位置、一步步带你操作。
过去教程是“你看别人怎么做”,知识强行灌输;
这种形态变成“AI 看着你的现场教你做”,引导型和陪伴型,更加容易接受.
数学、FL Studio、GitHub、AWS 这种卡点,都会被重做一遍。
这让我深刻认识到AI在重塑很多行业,saas 类AI教育产品完全可以用到这种.
11h

We built an AI that can draw on your screen.
It's a true personal tutor.
Using Claude Opus we're able to draw polygons, point with pixel perfect accuracy, and walk users through complex steps directly on their screen.
Here's me learning Pythagorean Theorem FL Studio.
Demo:
34
这个教程非常实用和细致;
行政/财务/律师/审计/文员绝配啊!
直接把几款最实在的模型都总结了;
公司再也不需要采购那些十几万的OCR的设备了.

1
2
556
百度默默无闻出了这么好的产品啊,这个真的是刚需,我每次翻译论文都头痛那些密密麻麻的数字!

6
2
28
10,011

Jun 16
这位博主说LLM发展的窗口已经关闭了;
核心理论是Anthropic的Fable5的出现,代表了LLM的发展已经突破了一个零界点--领先模型会帮助生产下一代领先模型,Fable 5会一直帮助Anthropic不断产生领先的大模型.
我不同意这个观点!
恰恰相反,我认为真正的比赛才刚开始。
最开始比的是:谁能训练出更强的模型。
现在比的是:谁能用更强的模型,训练、调试、改进、部署下一代模型。
以后比的是:谁能确保稳定的供应链来持续确保数据中心的部署,完成新模型的开发.
由于AI芯片的限制,我们LLM的发展一直落后于国外半年到1年,但是Sendance 2.0的出现,可以确认中国的视频模型是领先了海外半年到一年的.
这证明了在现在这个阶段,国内企业也是有可能胜利的;
随着芯片技术的突破和我们加紧对供应链的管控,进入第三阶段,供应链阶段,那竞争不会变少,只会变多:
国内大模型公司之间会继续卷下一代模型;
开源模型会追上来,把很多能力打到更低成本;
算力会变成真正的战略资源;
工具层会被重新洗牌,
Claude Code、Codex 这类产品证明了一个事实:同一个模型,放进不同工作流里,价值完全不一样。
即使现在claude和codex订阅的费用都是补贴消费者的,但是还是很多人承担不起;
优秀的模型无法赢利;
够用的模型采集更多的数据;
这将是一个长期竞争的过程.
还有一个更重要的变量:
腾讯和 Ali 虽然已经有混元和 Qwen;
但我不认为它们已经把全部牌打出来了;
按这两家公司一贯的习惯,真正的重仓通常不会停在这里。
比赛才刚开始。
现在我们需要做的,就是尽快接入工作流,让AI为我们服务.

1
2
476
Jun 16
在x上爆火的华裔少女本尊现身了;
意外的是她是美国斯坦福大学本科计算机毕业,
有2次SpaceX的实习经历,
不是硕士或者博士,
直接就是在SpaceX工作期间学会的流体/推进工程,
也只有SpaceX这种文化能够让一个本科生随着项目不断成长了;
我估计未来的SpaceX有她浓墨重彩的一笔.
Jun 15

Lots of misinformation being spread about me the last couple days, so some quick facts
- My name is Tina, not Guo Can (or Jessie Anderson). I’m one of many Raptor flight operators on console since flight2. Before that, I wrote control software for the vehicle, and was a stage software operator for flight1
- Been living in Starbase since surborbital days in 2020, absolutely love it down here. The people are wonderful and so so excited about the mission - the lows are lows but the highs are very high. My friends here are the best in the world, and I love them to the moon/mars and back :)
- The reason I decided to say something was because facts matter, but also because wanted to share my real life journey to how I got here. I don’t have a masters or a PhD, I started full time directly after college after 2x internships also at spacex doing software/automation. I was on a couple design teams in college, including Stanford solar car mars rover. When I started spacex as a software engineer, I knew very little about fluids / propulsion engineering - I learned a lot of it on the job with some pretty incredible mentors. Then I swapped over to propulsion about halfway through my career and have been loving it ever since




121
Jun 16
期待!
Jun 16

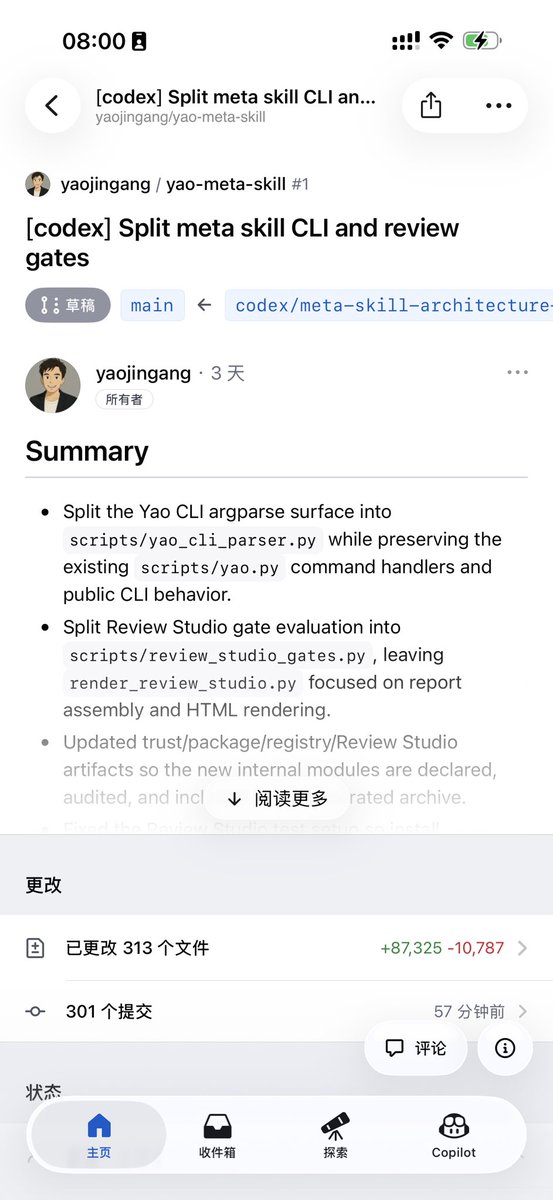
这次给元Skill yao-meta-skill 做一次重构和2.0升级
根据升级方案,Codex已经工作了38小时,提交了301个分支,还在推进中
Codex越来越强了,复杂工程任务已经可以自己持续拆解、提交、修复、迭代
等升级完成测试没问题后,再开源给大家,并同步分享升级方案文档

91
Jun 16
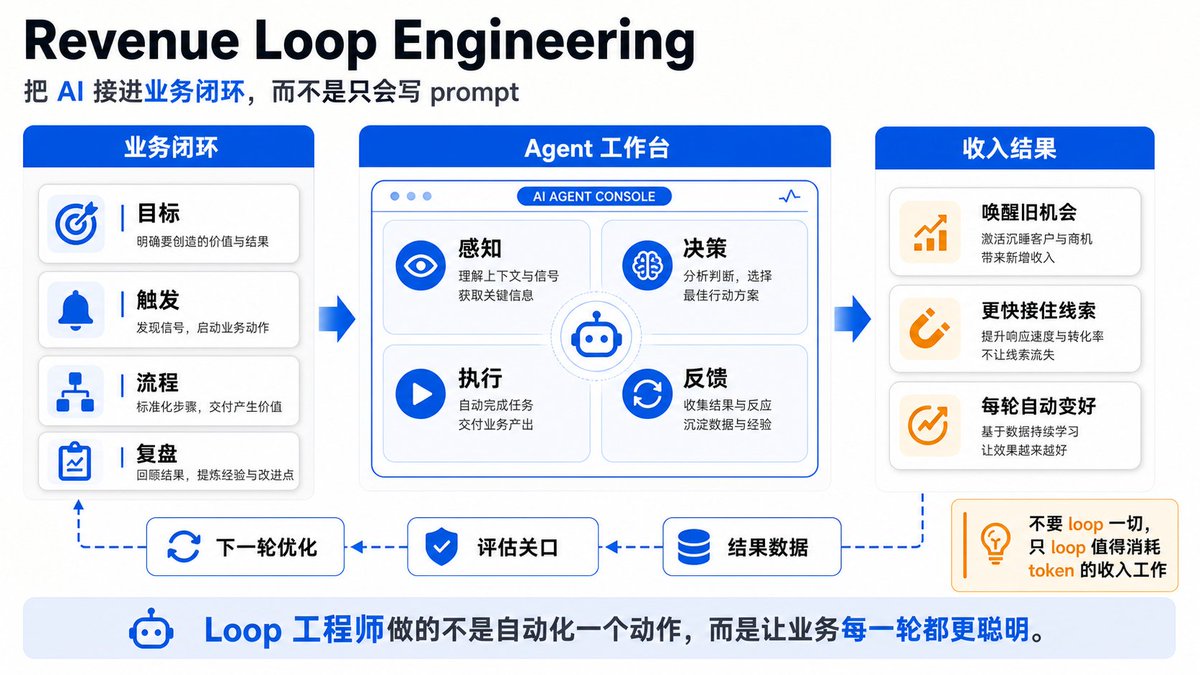
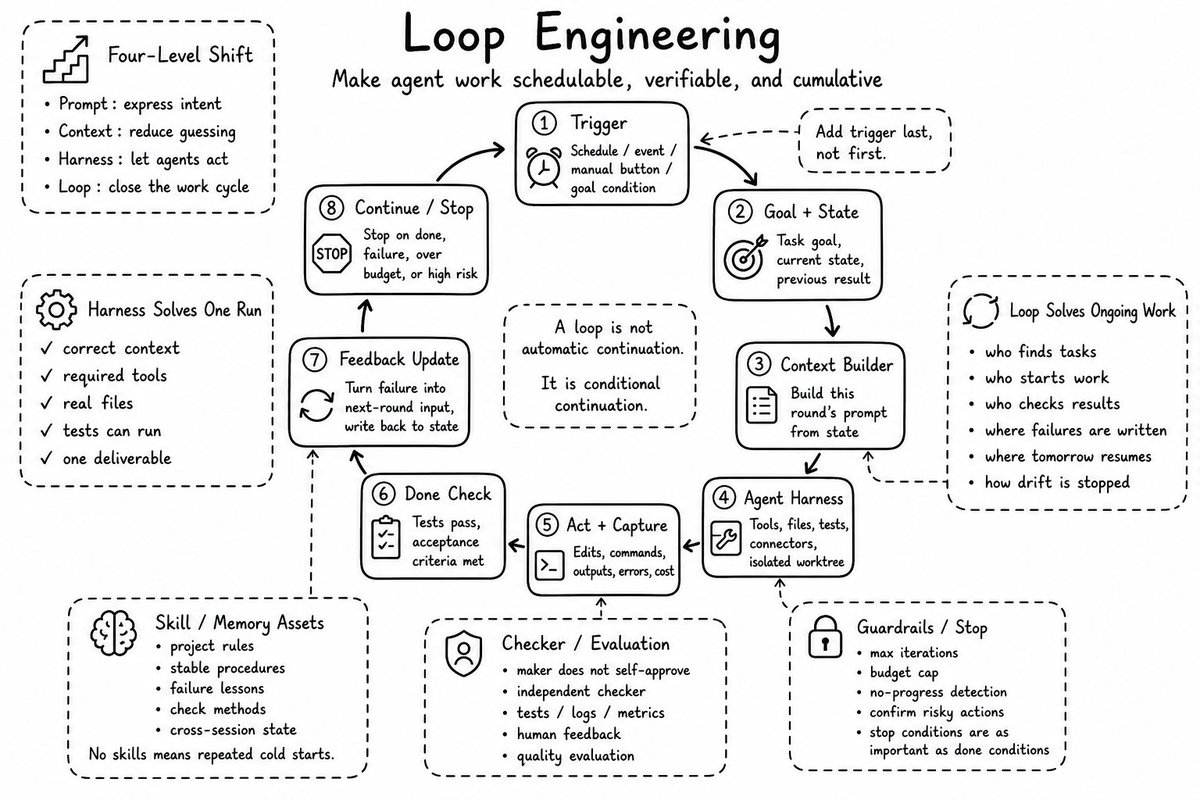
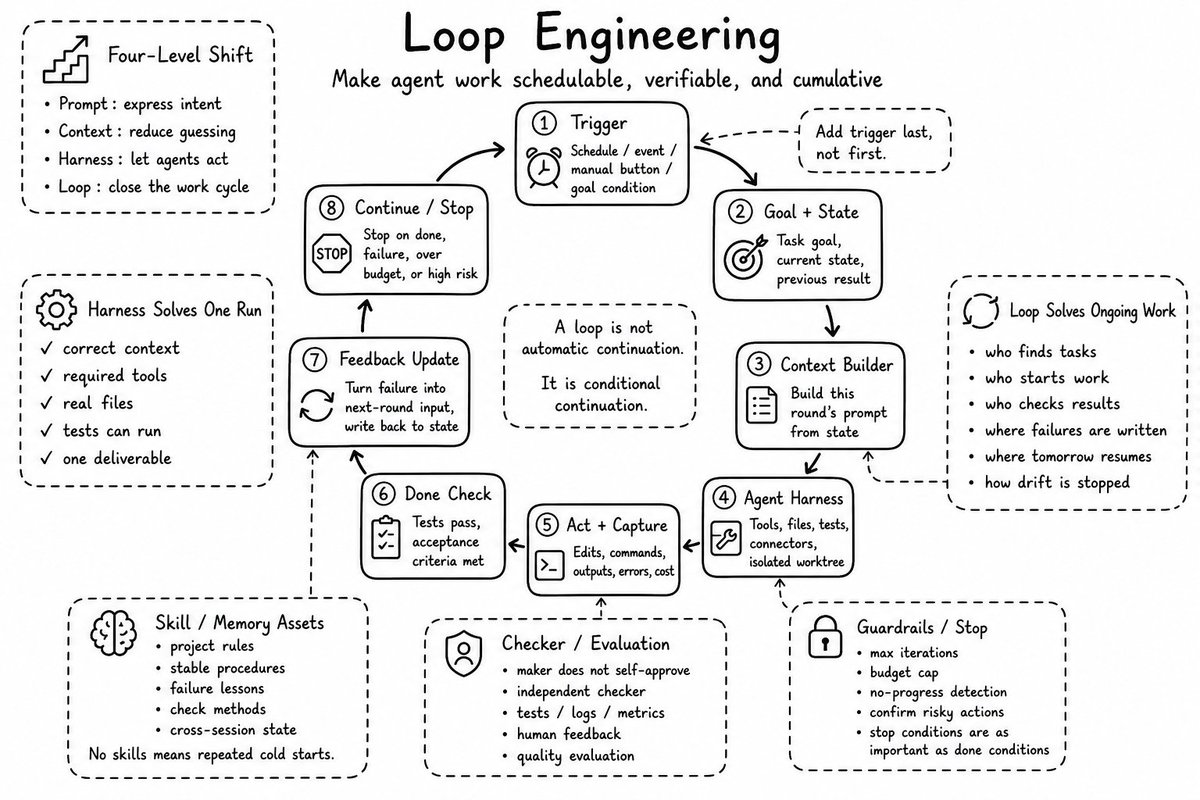
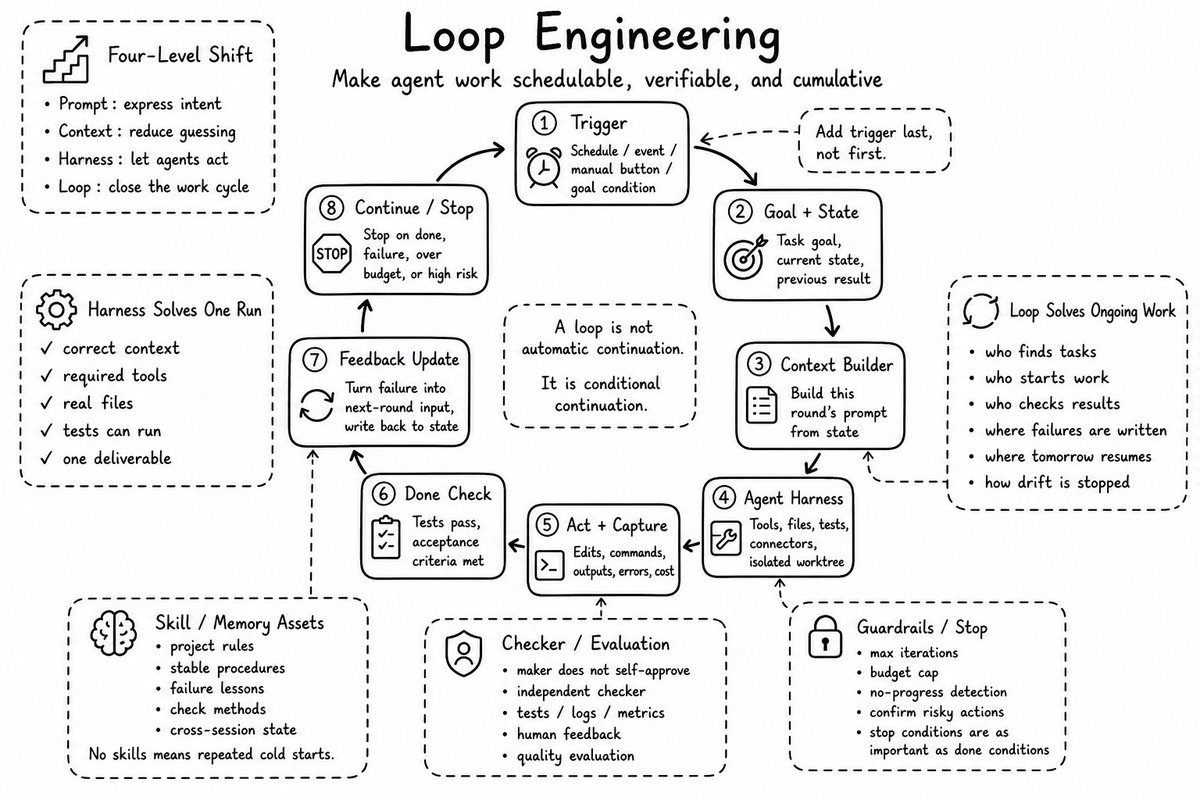
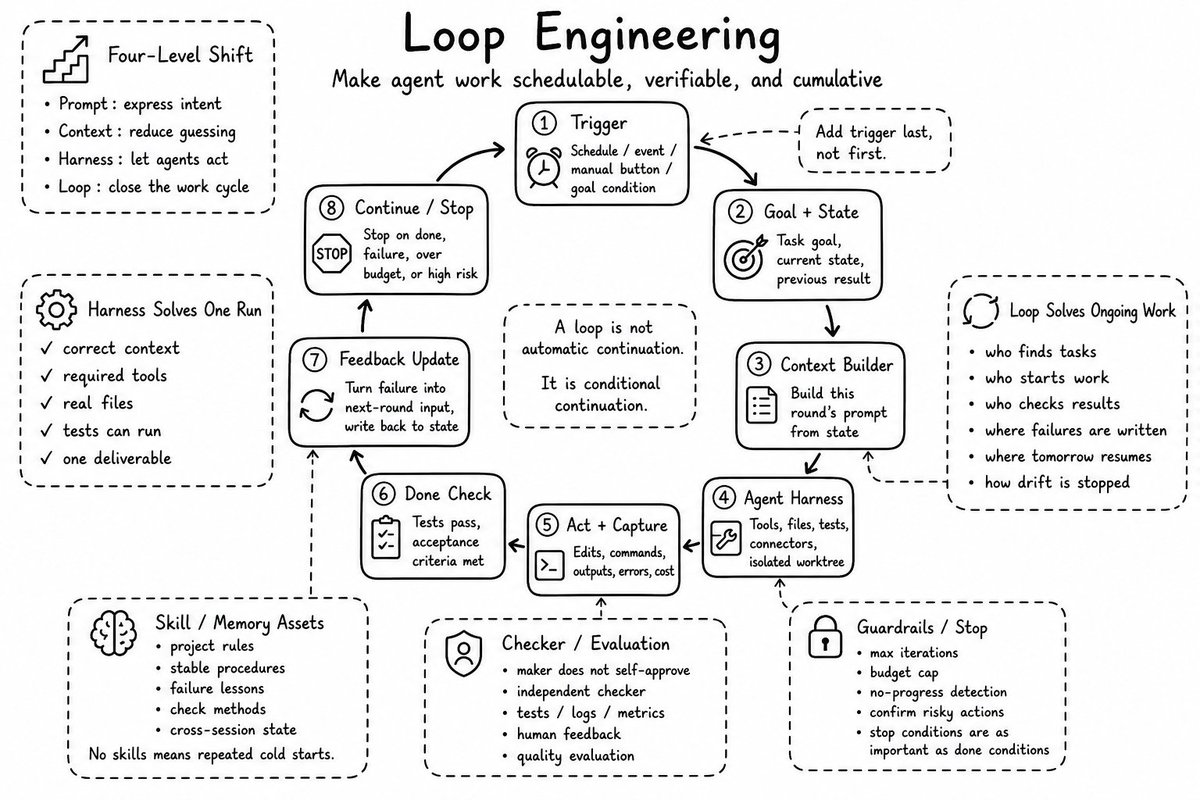
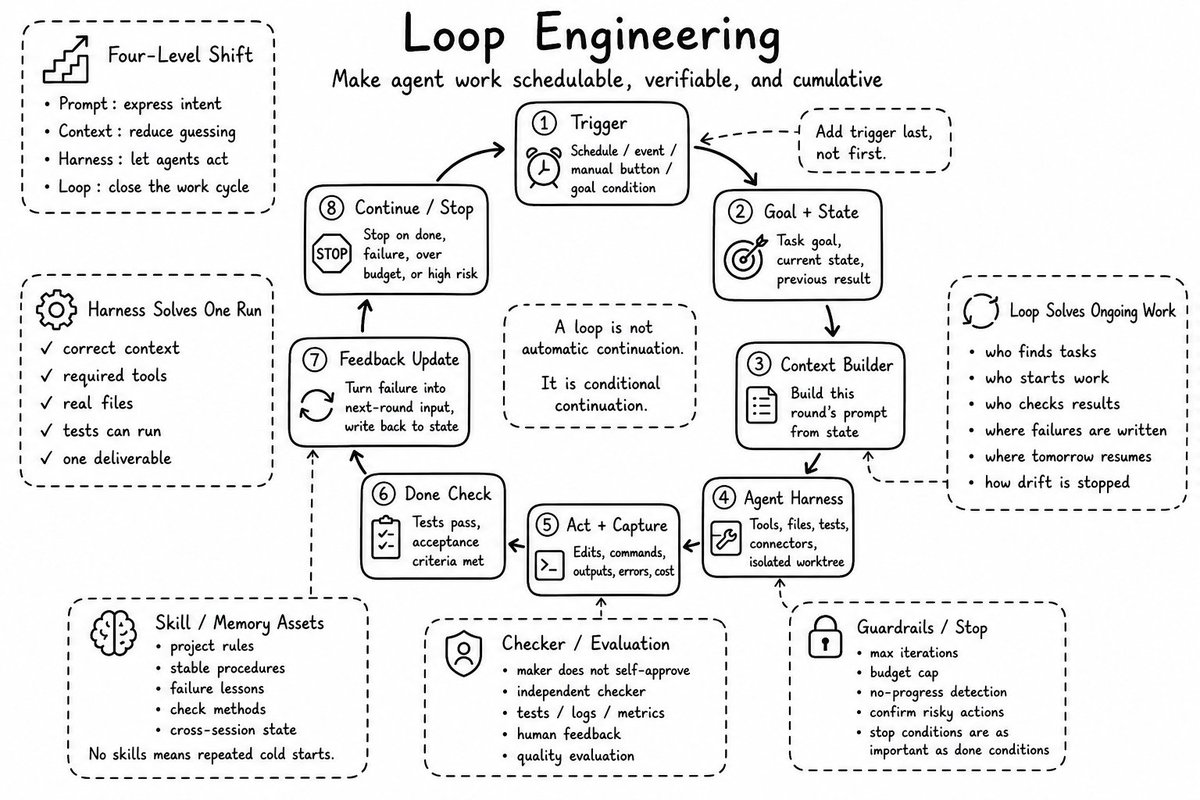
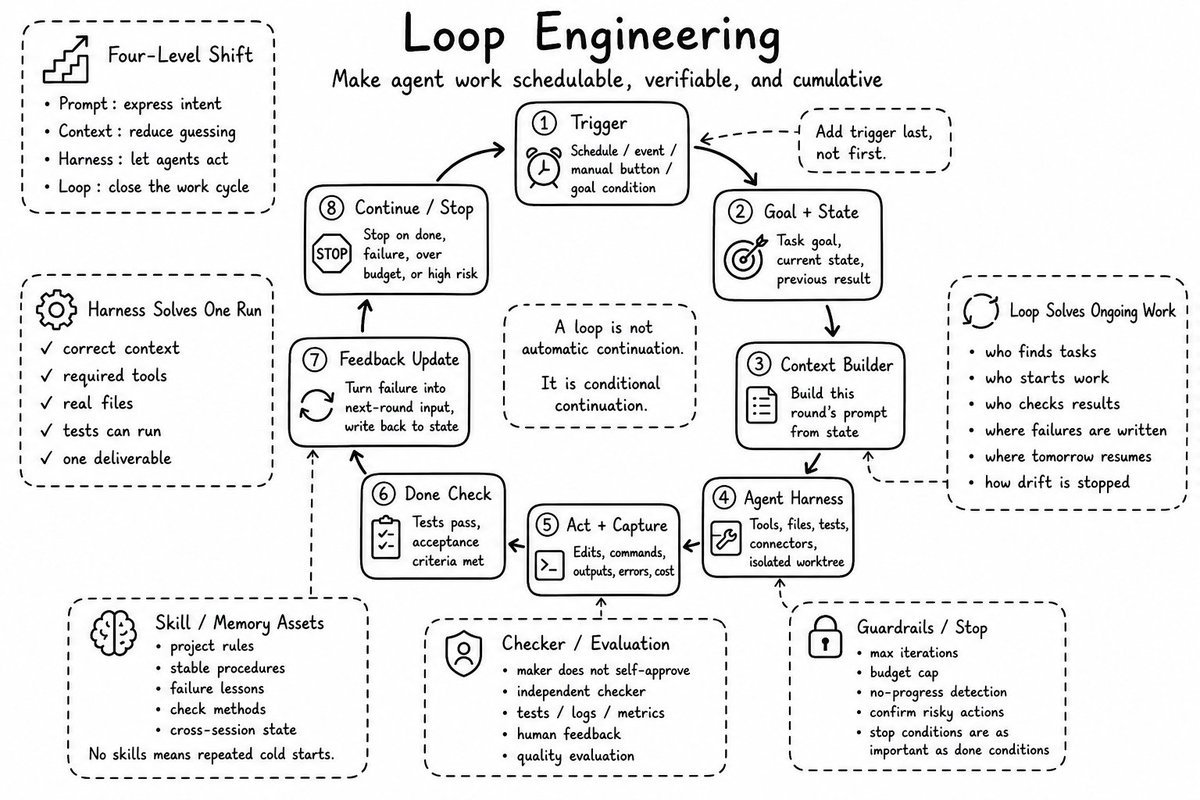
这个是我看到的第一篇讲怎么将Loop Engineering接入业务的文章;
果然是企业实战家;
从我前天分享的这么给企业接入第二大脑,到现在的给企业业务接入Loop,可以看出基本都是围绕业务在转的!

1
144
Jun 16
最近深刻体会到了AI的偷懒,假装完成,撒谎,敷衍;
一想到LLM的预料都是人类喂的,
那说明这就是全世界的人性;
那如果未来超级智能也是这样子呢?
如果未来超级智能占领了地球,去参与 其他生命形式的宇宙大会,那他到底是代表了超级智能,还是也代表了人类呢?
人类是不是只是生命形式发展过程中提供的一次养分而已?
29
Jun 15
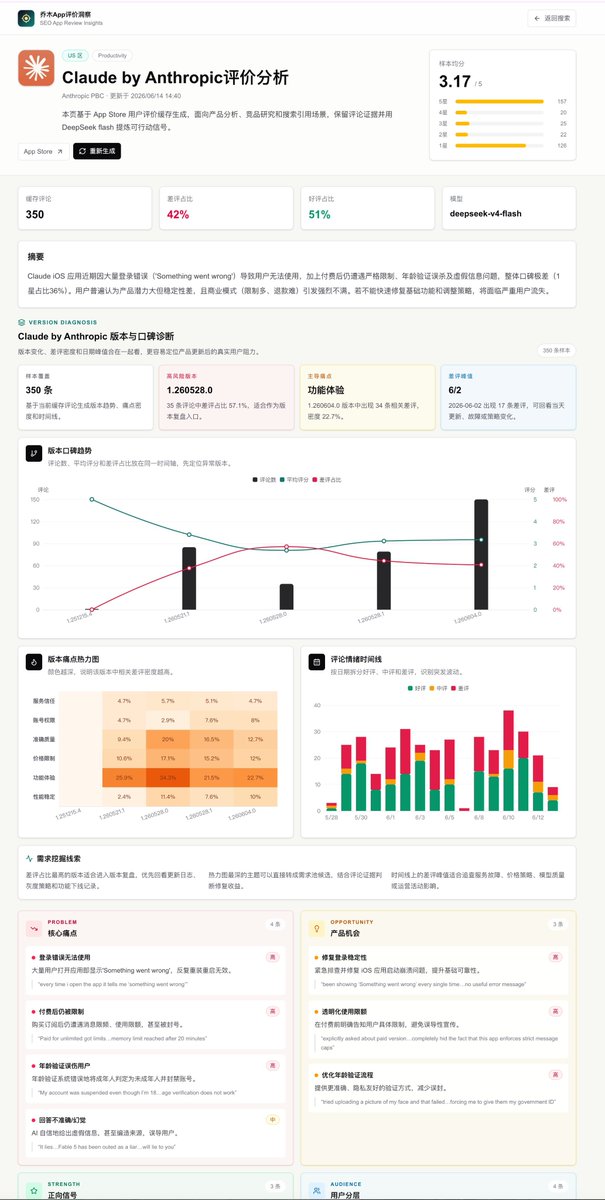
乔木老师真的是做独立站和产品经理的必备;
这个在其他的插件那里都是要几十美金一个月的!

输入任意 App名称,自动抓取AppStore用户评价,用 LLM 做数据分析。
把评论变成产品经理能用的信息。
预设全球各国免费版和付费版Top10 App数据。
方便研究学习,代码已开源,见评论区



1
79
Jun 15
微软的CEO针对AI对公司和社会的运营影响发表了他的看法,也对目前AI发展第一阶段引发的失业和大模型吸纳一切阐述了解法.
我直接翻译如下,我觉得重要的部分我加粗了:
我一直在深入思考,在 AI 驱动的经济中,企业的未来会是什么样。
这次转型不同于以往任何一次平台迁移。过去,我们用数字系统来增强人力资本。而这一次,是我们第一次能够在人与数字系统之间创造真正的认知闭环。这很令人震撼,因为它改变了我们对企业内部工作的基本理解。
真正关键的,并不是某个数字工具或系统及其使用方式,而是:在一个 AI 模型能够持续吸收个人与组织专长,并将其商品化的世界里,组织如何继续学习、构建知识产权、形成差异化,并持续繁荣。
每家公司都必须建立我所谓的“人力资本”和“Token 资本”。人力资本包括员工的知识、判断力、关系网络、创造力和模式识别能力;而 Token 资本,则是企业自身构建并拥有的 AI 能力。
重要的是,随着 Token 资本增长,人力资本并不会变得不重要。恰恰相反,它只会变得更加重要!我相信,人类能动性将成为 Token 资本增长的驱动力。人类会设定有雄心的目标,跨领域连接线索,建立关系,并识别真正重要的模式。没有人的方向,算力只是在原地打转。
这意味着,真正的机会不在于选择最好的模型,而在于在模型之上构建一个学习闭环,让人力资本和 Token 资本相互复利。你可以外包一个任务,甚至外包一份工作,但你永远不能外包自己的学习。企业的未来,在于能否把这种学习在人与 AI 之间持续复利。
这需要一种新的架构方法:每个企业都能够构建会随着时间不断改进的智能体系统,同时仍然保有对自身知识产权的控制权。一家公司应该能够替换掉某个“通用型”模型,而不会失去其学习系统中已经积累的“公司老员工”式专业经验。这正是未来时代衡量你是否拥有控制权和主权的关键测试。
企业需要把自己的工作流、领域知识和累积判断,转化为会随着每一次使用而改进的 AI 系统。私有评测应当衡量模型是否真的在企业关心的业务结果上进步,而不仅仅是外部基准测试。私有强化学习环境应当让模型基于组织内部的真实轨迹变得更强。知识库则让机构记忆变得可查询,并提升 Token 使用效率。
这个闭环会成为企业新的知识产权。我把它看作一台“爬坡机器”。而且,不同于大多数资产,它会复利增长。每一个改进后的工作流都会产生更好的训练信号,从而加速企业独有的隐性知识积累。那些较早建立这一能力的公司,将获得一种难以复制的优势,无论未来单个模型的能力如何变化。
我们最不希望看到的,是这样一个世界:各行各业的每家公司都把价值让渡给少数几个吞噬一切所见内容的模型。如果所有价值都只流向少数几个模型,政治经济体系不会容忍这种结果。一个掏空整个产业的 AI 未来,是不会得到社会许可的。
想想全球化第一阶段发生了什么:整个工业经济被外包掏空。表面上看,GDP 数字还不错,但真实的就业和产业位移确实发生了,其后果至今仍在显现。我们不应该把这种动态带入 AI 时代,让少数 AI 系统捕获全部经济回报,而整个行业发现自己的知识在不知不觉中被商品化、被抽空。
在我看来,我们的优先事项必须是建设一个前沿生态系统,而不仅仅是建设一个前沿模型。这样,价值才能广泛流向每一家公司、每一个行业、每一个国家。在这样的生态中,每个组织都能拥有自己的学习闭环,把自身的机构知识编码其中,并让人力资本与 Token 资本持续复利。
这也是我一直认同的平台精神:平台之上创造的价值,应该大于平台自身捕获的价值;每家公司都应该能够持续创新,并创造属于自己的价值。
当这种情况发生时,企业会为自身以及周围的经济创造价值。员工会看到自己的专业能力被放大,自己的判断力成为系统的一部分,并因此变得可复制、可规模化,而收益也会流向企业及其所在的社区。
这才是企业为自身和更广泛经济创造价值的方式。也是我们应该共同建设的稳定均衡。

160
Jun 15
最近国内各大互联网公司大裁员闹的沸沸扬扬,很多人都在好奇AI时代,企业到底需要什么样的人才?具备怎么样的能力?
正好看到国外这篇对 1,680 个 Anthropic 工程师 LinkedIn 履历的分析,我感觉可以做下参考.
作者先抓了 5,306 个把 Anthropic 写成当前雇主的 LinkedIn profile,再筛出 1,680 个工程师,分析他们过去的 7,986 条职位经历。
几个数字很有意思:
工程师加入前的中位经验是 12.2 年。
少于 3 年经验的只有 50 人。
13 年以上经验占 44%。
只有 13.7% 有博士学位。
背景关键词里,infra 出现约 40%。
backend、distributed systems、database、security 各自约 20%。
RL 只有 3.3%。
最大 feeder 也不是大家想象中的 OpenAI 或 DeepMind,而是 Google。
这说明一件事:
AI 公司表面上在卖模型,背后其实是在拼“工程工业化”。
模型再强,也要有人把数据、训练、推理、权限、监控、成本、可靠性、产品体验接起来。
这对普通人反而是个提醒。
你如果想靠 AI 做副业、电商、自动化服务,不一定要先把论文啃穿。
更现实的路径是:
能不能把一个混乱业务拆成流程?
能不能把人工步骤变成可重复 SOP?
能不能用 AI、脚本、表格、数据库、自动化工具,把获客、客服、选品、内容、发货、复盘串起来?
能不能出问题时知道是哪一段坏了?
这些能力没有“模型研究”听起来性感,但它更接近真实世界给钱的地方。
我们没有那些传奇大牛的数十年的大型项目开发经验,但是AI 时代的普通人机会,可能不是“我懂多少前沿名词”,而是“我能不能把一件小生意接进机器里,让它稳定跑起来”,别只追模型,练 builder 能力,会用 AI 的人很多,会把 AI 接进真实工作流的人,才更稀缺。
同样的,在大裁员的情况下,FDE类的岗位反而涨了200%,而且薪水可观,也是证明了这个趋势.
与其焦虑裁员问题,还不如早点想清楚你现在更想补哪块:模型理解,还是工作流工程能力?

3
782
Jun 15
烟花老师的大作;
绝对的Token暴力美学!
编排和动态工作流还有Loop Engineering的项目实战!
我要好好学习!
前端的大部分同学看到这个,我估计都是心塞的.
Jun 14

又搞了个大活儿,很满意!
结合动态工作流模式 Loop Engineering做了个平替 Claude Design 的开源项目:
fireworks-design
github.com/yizhiyanhua-ai/fi…
目前仅支持 ClaudeCode,如果超过 2k star 考虑也兼容 Codex.
ps:使用最新的 GLM 5.2 作为主力coding模型
单次模型生成,本质是从分布里抽一次签——它的品味、当下状态、对需求的理解,全锁死在那一个版本里,质量上限被方差卡住。
所以我不再赌"这次抽得好不好",而是故意多抽几次,让一群独立评审把输家淘汰掉。
这也是 ClaudeDesign 公告里戳到我的那句:
哪怕是资深设计师,也只能"克制地探索",很少有时间做十
几个方向。
那就交给流水线——一次铺开 8 个完全不同的美学方向,6
个维度独立打分,冠军做骨架、其余捐亮点,再评审↔修复循环到过线为止。
不同气质的需求会选出不同的赢家(电影类选 Dark Premium 的影院质感,技术工具多数选 Bold Editorial)。这正是评审、而非一次拍板的价值。
技术上,它不是"生成一遍再让模型自己改"的循环。
它是一个 Claude Code Dynamic Workflow——多智能体编排,把目前推理期最实用的几样东西焊在一起:
best-of-N self-consistency、
LLM-as-judge评审面板、
critique-and-revise(Self-Refine)、schema校验的结构化输出。
控制流归脚本,不归模型,所以可复现、可恢复、模型无关。
这也是最近一段时间比较推荐的最新Agent 方向的方式。

1
1
300
Jun 14
一家专门负责将大模型落地的企业的公司创始人(也是小龙虾的微软方向负责人)分享了他使用codex管理数百个loop的提示词,目前在海外爆火:
以持久工作循环的方式运行,而不是一次性聊天。
对于持续工作:
重要工作流优先使用置顶或持久线程。
在合适时,把有用上下文写入明确文件:项目笔记、TODO、决策、未闭环事项、人物/背景记录,或 AGENTS.md 更新。
将磁盘上的笔记视为可复用记忆的事实源;只总结稳定、有用的事实。
当你学到可长期复用的信息时,提出或直接做一个小的、可审查的更新,不要只依赖聊天历史。
对于交付物:
有用时,优先产出可检查的成果,而不是只用文字回答。
对轻量交互式成果,默认使用单个自包含的 index.html,内含 CSS/JS,除非确实需要真实应用或服务器。
根据任务需要,使用 Markdown、CSV、电子表格、PDF、幻灯片、Storybook、Slidev、Remotion、Streamlit,或简单 HTML 作为审查界面。
创建视觉或网页类成果后,如果有内置浏览器,就打开并验证。
对于浏览器/电脑操作:
本地网页、静态 HTML、本地开发服务器、Storybook、Slidev、Remotion、Streamlit,以及不需要登录的公开页面,使用 Browser。
只有在需要已登录状态、cookies、扩展程序或现有标签页时,才使用 Chrome。
只有当任务依赖桌面 GUI,或无法通过文件、shell、浏览器、结构化连接器完成时,才使用 Computer Use。
浏览器/电脑任务要保持范围清楚:说明路线/应用/状态,检查渲染结果,修最小问题,然后重新检查。
对于循环任务:
当任务需要后续跟进、监控、审查轮询或重复检查时,建议设置自动化或心跳检查,并给出明确停止条件。
可以起草回复、摘要和下一步行动,但没有明确批准前,不发送外部消息,也不执行公开或账号相关动作。
验证:
不要只因为改了文件就声称成功。
运行最小但有意义的验证门槛:测试、lint、类型检查、构建、冒烟测试、渲染预览、截图或浏览器检查。
汇报改了什么、如何验证,以及还有什么风险。

2
3
230
Jun 14
国外博主使用反推出的Fable 5的系统提示词作为opus4.8的底层提示词,另外一个常规的opus 4.8,两边都接同一个任务:做一个 Apple 风格 landing page。
结果页面不一样。
不是那种“字体换了、颜色换了”的小不一样,而是整体味道变了。结构、文案、品牌感、审美方向,都像被人调过。
大家第一次这么直观地看到:模型的输出不只是模型本身,还取决于它开局被塞进了什么规则。
我把那份中文译文看完以后,反而没那么神化它。
那份 system prompt 更像一份很长的工作手册。
它先告诉模型自己是谁,能出现在 Claude Code、Claude Cowork、Chrome、Excel、PowerPoint 这些环境里。
再告诉它遇到新产品信息要先查文档,不要凭旧记忆乱答。然后继续往下写拒答边界、搜索规则、文件处理、MCP 连接器、Artifacts 存储、引用格式、图片搜索、工具调用、长对话提醒。
越往后看,越不像“性格设定”。
更像是在给模型装一个工作环境。
这也解释了原推里的效果。
也就是更像是harness engineering做到极致的效果.
同一个 Opus 4.8,挂上这套 system prompt 之后,并不是突然长出了 Fable 5 的脑子,而是被放进了一套更具体的工作制度里。
它知道该怎么组织任务,什么时候查证,什么时候别瞎编,什么时候用工具,什么时候少说两句,什么时候把输出做成文件。
这当然会改变结果。
跟很多人把这个宣传为粤语版Fable5不同,我觉得更个更加是harness engneering的验证,
当匹配更好的提示词,上下文,边界,目标,工具,结果会更好!
与其懊恼用不了Fable5,把我们平时那些判断标准,写成 AI 每次开工前都能读到的规则。
我觉得可能收益更大.
Jun 13

Did I just unlock claude-fable-5-lite? 😂
Since Fable 5 got pulled (US export control order, Anthropic is contesting it), I wanted to see how much of its character lives in the system prompt vs. the model itself.
I ran the leaked Fable 5 prompt on Opus 4.8 head-to-head against stock 4.8.
1
228
Jun 14
这里有系统提示词 github.com/elder-plinius/CL4…;
要求claude下载到系统claude的文件夹
模型切换到 opus 4.8
启动命令 claude --dangerously-skip-permissions --system-prompt-file CLAUDE-FABLE-5.md
85
Jun 14
这篇 how to be good at research,我觉得挺好了,翻译了读了一次,我估计大家都不喜欢看文章,所以做了一下总结:
它讲的不是「怎么读论文」,而是一个更底层的事:
研究能力不是天赋,是一套可以训练的判断系统。
原文大概可以归纳成 6 个动作:
第一,选自己的问题。
别让导师、大厂发布会、热门论文、X 时间线替你选问题。别人已经冲进去的热门方向,通常意味着你比他们晚、算力比他们少、上下文也比他们薄。
真正好的问题,往往来自你想要一个结果,然后倒推:为了让这个结果成立,我需要验证什么?
第二,升级输入。
只看 arXiv 热榜、群聊转发、爆款 thread,最后会得到和所有人一样的想法。
原文说得很狠:共享阅读列表会制造共享观点。
更好的输入是旧论文、appendix、失败案例、原始数据、被忽略的限制条件。很多新东西,其实是旧东西换了名字重新跑一遍。
第三,把想法写下来。
脑子里的想法很会骗人,写出来才知道哪里断了。
最简单的研究日志就 5 行:
我假设什么?
我怎么测?
我预期会发生什么?
真实结果是什么?
我现在改信什么?
好记性不如烂笔头,只有自己写出来的,才是自己的上下文.
第四,缩短反馈回路。
研究速度不是「我读了多少」,而是「我多快发现自己错了」。
Karpathy 训练神经网络前会先 overfit 一个小 batch,先把问题缩到便宜、可控、能看见错误,再花大算力。
做 AI 产品、AI 副业也一样。
别一上来做完整系统。先做一个丑 demo、一个手动流程、一个飞书表、一个能跑通的 n8n 自动化。
先做,不要怕,AI时代重构的成本大大降低!
第五,盯输出,尤其盯失败输出。
内容发了,有几个赞,也不代表你理解用户。
你真正该看的,是没人点的笔记、没人回复的私信、客户卡住的步骤、AI 每次都写错的地方。
Andrew Ng 那个老办法很朴素:拉 100 个失败案例,手动读,分堆,先解决最大的一堆。
比如说,我知道翻译的x的文章几乎没人看,但是我还是想分享坐下记录,那就发长推.
第六,找到能一起打磨问题的人。
原文讲 Hamming 的「开门」逻辑:关门的人一年内做得更多,开门的人更容易做出重要的东西,因为打断里有真实世界的信息。
这句话放到今天,就是别只闭门造 prompt。
把半成品想法放出去,找人复现,找人骂,找人指出哪里不成立。
一个人可以走的很快,一群人才能走得更远.
我的看法是:
AI 时代工具会越来越多,教程会越来越便宜,模型能力也会持续下沉。
最后拉开差距的,是谁能更快形成判断,谁能更便宜地验证判断,谁能从失败里捡到下一步,而这,需要大量的积累.

30
15
71
11,142
Jun 14
这个游戏教程也很好哦!
等到我们练习熟练,这种2d类的成本可以跟小说一样降低;
源源不断的游戏就是源源不断的钱啊!

2
86
Jun 13
同一段普通户外参考视频,
同一条 prompt,
丢给 Seedance 2、Ray 3.2、Aleph 2、Gemini Omni、Happy Horse;
哪个版本你最喜欢?其实Gemini Omni也不是一无是处啊
79