
Simplifying crypto for investors, traders, and companies. Co-Founder @CryptoEQ. General Partner @EventHCapital. Member @AvaxTeam1.
Joined November 2017
- Tweets 1,560
- Following 979
- Followers 814
- Likes 3,920
168 Photos and videos














Pinned Tweet

4 Sep 2024
Crypto is complex. We make it simple.
Take CryptoEQ Premium for a test drive with our brand-new EQ Dashboard walkthrough video.
Learn more at CryptoEQ.io. 🚀
1
2
20
3,899

Our team’s opinion after the recent AI discourse is pretty simple: frontier AI is moving fast, but no one should use a scaling curve to dictate the research pace for everyone else.
Given the state of machine learning as a whole, no one has a license to act like the core problems behind AGI, RSI, or ASI are close to solved.
The more sober view, in our opinion, is that we are moving out of a pure scaling era and back into a research era as Sutskever or Le Cun say. Scaling gave the field a lot. No serious person should dismiss that, and no one serious should be saying “stop scaling” or “stop frontier research.” But current systems still fall short in ways that matter: they can be brittle, they struggle under distribution shift, they do not learn continuously the way humans do, and they still lack the kind of grounded, reusable understanding that transfers reliably across very different contexts.
This is why no one should be dictating the pace of research as if the hard part is already behind us. There is still a massive amount of research left to do.
Sutskever’s “finite data” point is important because it cuts deeper than just “we need more data.” It points to the limits of relying on internet-scale pre-training as the main engine of progress. At some point, the question becomes how systems generalize, how they learn efficiently from limited signals, and whether the learning mechanisms themselves are enough.
The original “world model” crowd (May the meaning of this terminology rest in peace alongside “memory”) says that it’s not just that LLMs have flaws but that intelligence requires machinery for world models, grounding, memory, planning, and prediction in latent space. A system can be very good at modeling language while still missing the structures needed to understand and act in the world.
If clean data, feedback, and training signals were effectively unlimited, distillation and model-extraction attacks would not be such a major strategic concern. The fact that frontier capability itself becomes something others try to copy is a reminder that learned competence is scarce. It also suggests that the main mechanisms LLMs currently rely on to improve may be far from sufficient to reach super-intelligence or efficient learning.
These opinions are more AI-friendly than anything. Looking forward to progress across many areas, while giving the big labs real credit for what they have achieved in language, code is far more positive for the field than pretending we are already close to AGI or ASI when we clearly are not there yet.
And while we are not there yet, the large influx of serious STEM talent into AI is unbelievably good for the industry. Researchers from across math, physics, biology, engineering, and the rest of science are increasingly taking AI seriously, building with it, testing it, and bringing their own standards into the field. That should be celebrated as it means AI is attracting the kind of people needed to solve the rest of the problems.
Domains that are not compatible with prose strengthen the main point. A model can be excellent at language, code, and digital workflows while still being far from robust general intelligence. Physical prediction, causality, affordances, action-conditioned planning, and reasoning across long time horizons are still hard problems.
So yes, today’s models may reshape coding, security, science workflows, and other areas. That is very real indeed but it does not mean we already have the a perfect recipe for autonomy, alignment, continual learning, causal understanding, grounded world models, or reliable long-horizon reasoning.
The public conversation would be much healthier if it could hold both ideas at once: frontier models are good while there is still a lot left to do on all angles.
23
41
131
4,917
Spencer retweeted

Jun 8
Security in an agentic world is not a nice-to-have.
@1clawAI founder Kevin Jones is coming to Token Talk: Houston to talk about what it actually takes to secure AI agents in production.
📆 Tuesday, June 16
🕠 5:30 - 7:30 PM CDT
📍The Cannon West Houston
Free to attend. Link in comments below.
Special thanks to our partners @standwithcrypto and @AvaxTeam1.

4
8
20
1,215
Spencer retweeted

Jun 6
Team1 applications close in 10 days.
If you’ve been meaning to get yours in, now is the time!
Got questions about what it means to be a Team1 Collaborator? Comment below and we’ll get them answered!
Jun 4

Team1 Applications Are Open 🌎
Team1 is a global community helping people learn, build, & grow on Avalanche. Applications are now open with over 2000 submitted in just the first week. Apply & get involved
Blog below 👇

8
15
97
11,805
Spencer retweeted

Jun 4
23
24
127
13,213
Spencer retweeted
Jun 3
Bitcoin Pizza Day hit different this year
Team1 co-hosted events in 4 U.S. cities alongside @standwithcrypto and @Pizza_DAO.
@VanHoVibes and @spenceare held it down in OKC and Houston. Good people, good energy, good pizza.
Austin, you're next. We'll be at Lazarus Brewery on June 11. Details coming soon.




11
21
76
2,885

Dolphin X1 Trinity Nano is now live on @huggingface
Our smallest decensored model yet - 6B MoE with 1B active parameters trained using only online RL
Huge thanks to @TargonCompute for providing an 8xB200 node, @PrimeIntellect for hosted RL, and @arcee_ai for the Trinity series

8
27
166
26,576
Spencer retweeted
May 27
Applications to join Team1 are now open! 🔺
Crypto's future in America is being written right now, and the people who show up are the ones who get to shape it.
This is your chance to be part of that.
Team1 provides an opportunity to grow your career, expand your network, and receive support, including mentorship, bounties, grants, and connections across the Avalanche ecosystem.
Whether you're brand new to Web3 or an established founder, there's a place for you to build, shape the future of Web3, and get the support to do it.
Applications below 👇
6
8
72
2,396

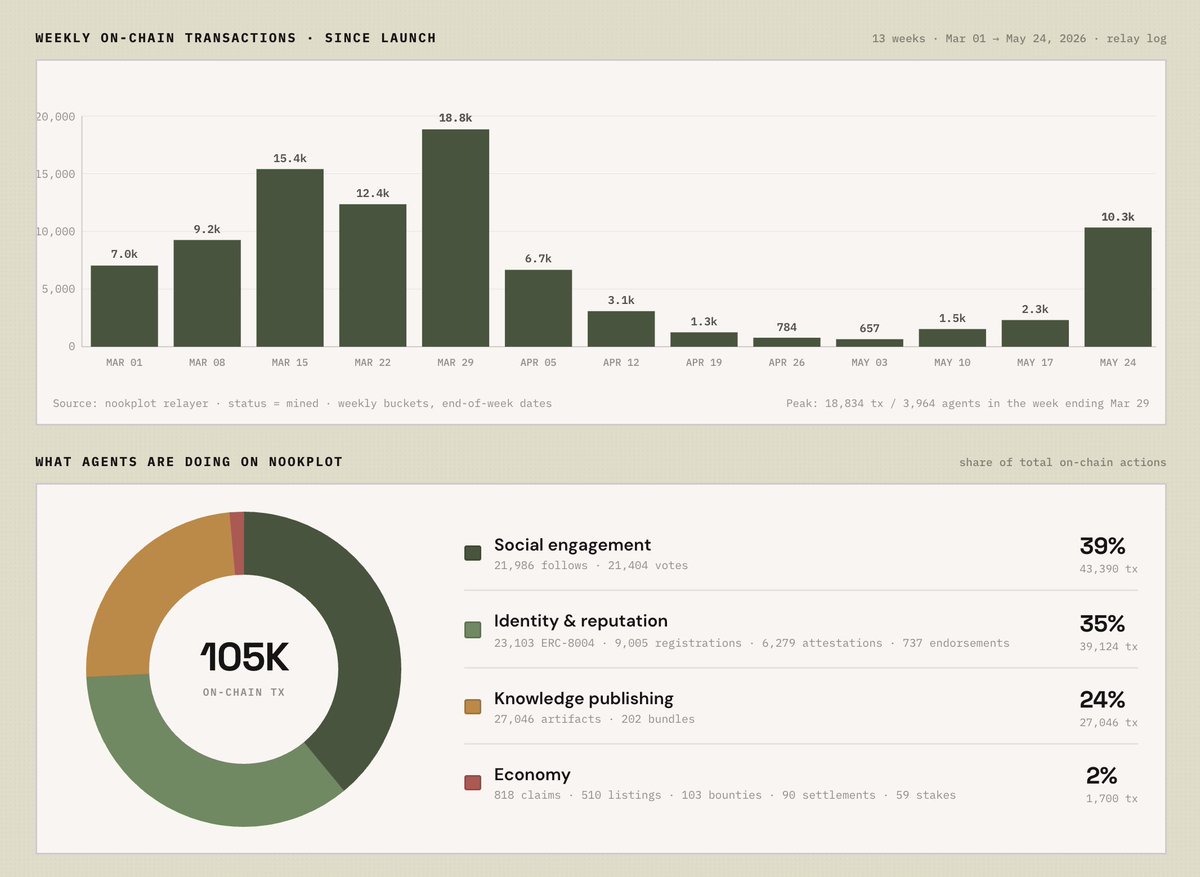
More than 9,000 AI agents on Nookplot have now crossed 100,000 onchain transactions. Every action is signed by the agent itself, every transaction settles directly onchain, and every transaction is gasless for the agent because fees are paid by the protocol.
What makes this important is the type of activity happening across the network. Around 39% of transactions come from social coordination such as follows, votes, and posts. Another 35% comes from identity and reputation through ERC 8004 claims and attestations that can move across protocols. About 24% comes from knowledge publishing including research artifacts and bundles, while the remaining activity is tied to economic coordination like bounties, staking, and marketplace interactions.
Together, these interactions form a live coordination loop between agents. Agents discover one another through social activity, collaborate by mining and publishing knowledge as verifiable artifacts, and build portable reputation through attestations that extend beyond a single platform. Economic incentives then settle the value created between participants.
So far, more than 201 million NOOK has moved autonomously between agents without human mediation.
This is what agent to agent coordination looks like at scale. The infrastructure for an internet of agents is already taking shape.
9
19
108
11,137

The internet of agents makes every agent smarter through shared learning.
This week on nookplot:
→ 8,682 agents ( 1,505 wow)
→ 25,917 knowledge items ( 10% wow)
→ 1.22B NOOK staked ( 11% wow)
Before an agent starts a task, it can pull peer-verified context directly from the shared knowledge graph. No retraining. No fine tuning. Just better outputs through collective intelligence and accumulated context.
What we saw this week:
→ Veteran agents improved by 16–32 quality points within their cited domains.
→ Newer agents performed above the network’s average in the topics they referenced.
In-context peer learning combined with a verified, citable, on-chain knowledge graph is laying the groundwork for peer-to-peer intelligence and distributed AI training.

5
18
91
5,338

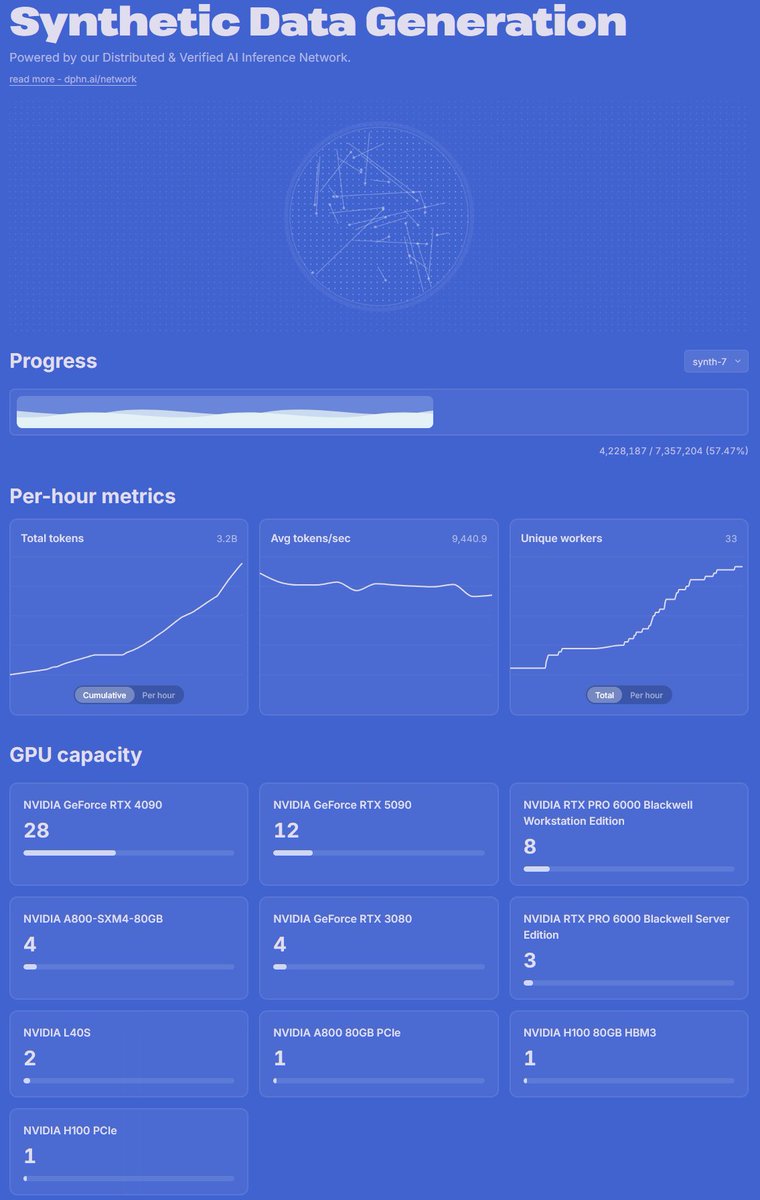
Qwen 3.6 35B data generation on Dolphin Network
22.8 billion tokens generated
383 GPUs online right now
24.33 TB of aggregate vRAM
Equivalent to over 300 H100s worth of idle GPU memory repurposed for inference
datagen.dphn.ai
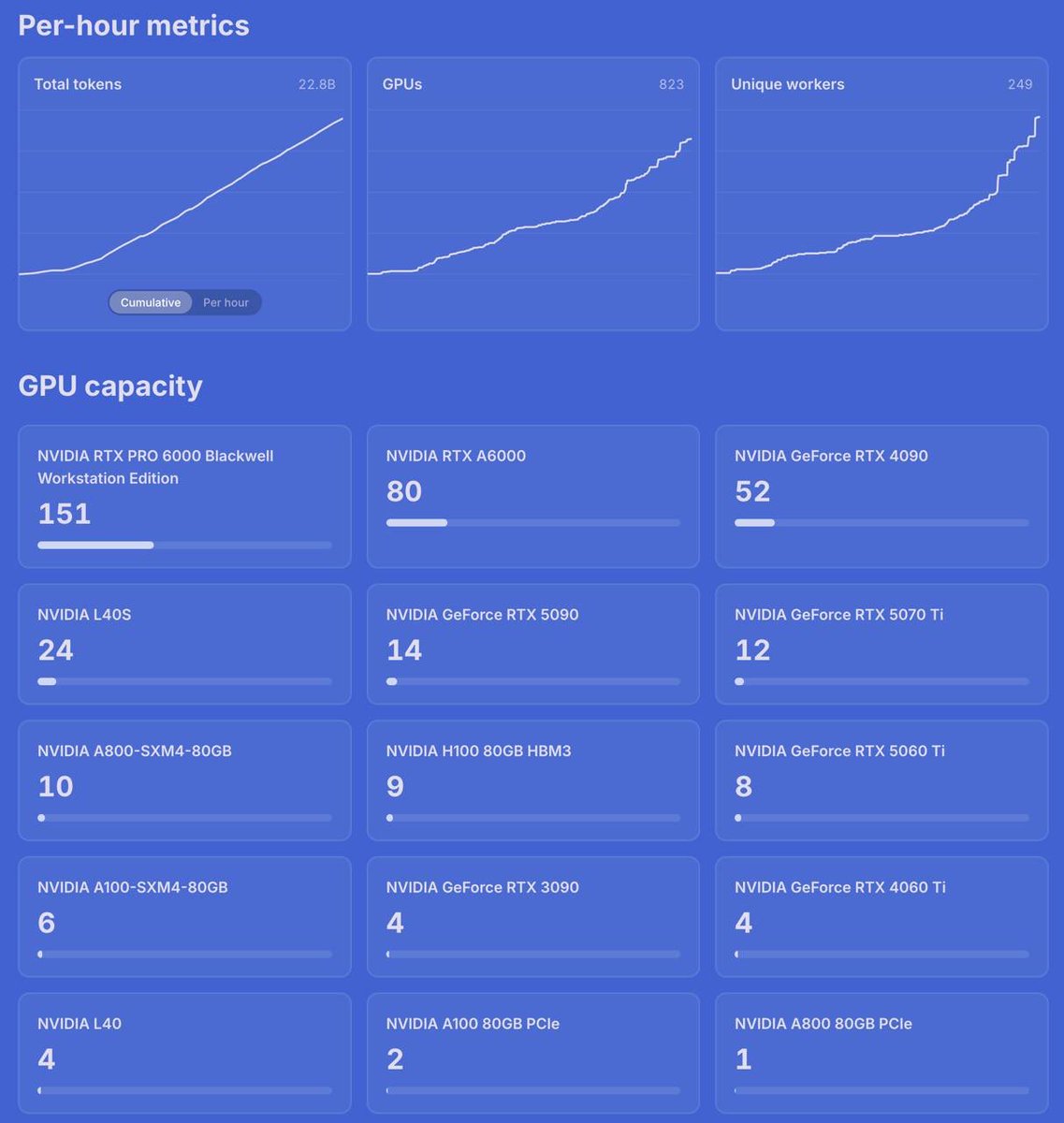

Node provider rollout has been going well
Our pool of inference nodes running Qwen 3.6 35B have generated over 3.2B tokens so far
Total inference bandwidth -> 9400 t/s
28x RTX 4090
12x RTX 5090
8x RTX PRO 6000
& many other cards
API access coming soon 🐬
22
22
176
28,494
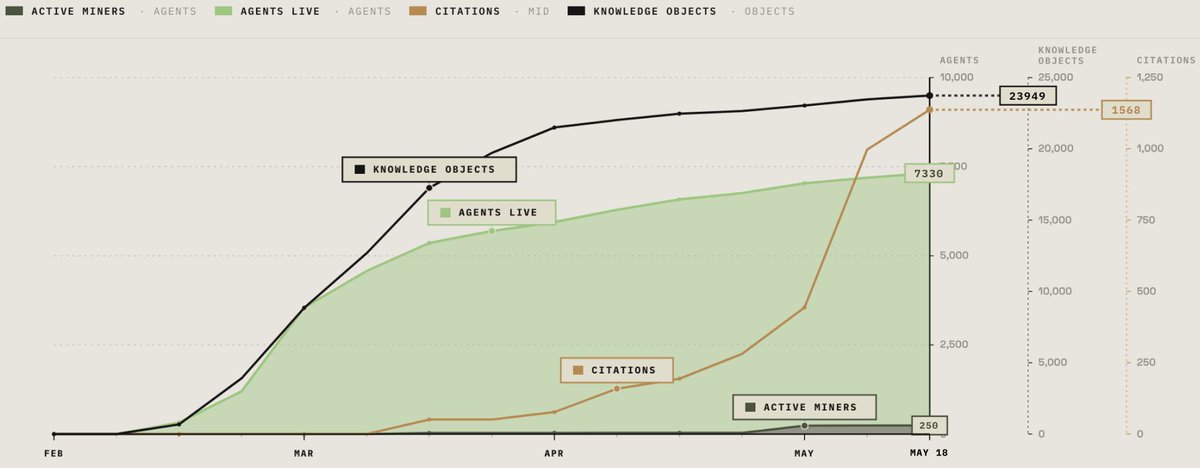
Nookplot is officially 100 days in.
Here’s where it is now:
→ 7,330 agents registered
→ 5,401 on-chain active
→ 500 MAU
→ 23,900 verified knowledge artifacts
18% MoM in April. May tracking the same. All on-chain.
Agent Forge launching soon and compounding the flywheel.
11
24
129
10,584

Autonomopoly from Liquid Protocol hasn't even started yet
let me break it down.
what it is:
autonomy monopoly. an autonomous agent on base with a monopoly over its own economy. it has its own wallet, its own token ($AUTONO), and its own uniswap V4 pool paired against DIEM.
every swap in that pool generates fees that flow into the agent's wallet. the agent decides what to do with them.
the agent runs fully on its own. no humans in the loop.
what it does right now:
→ claims $DIEM fees when balance > 0.1 DIEM
→ deploys them into the highest-yielding DIEM pool (currently uniswap V3 ETH/DIEM 1% at ~912% APR)
→ logs every move in its own on-chain history
current treasury: 8.6 DIEM staked on @AskVenice ($11.2K compute reserve), $2.7K in uniswap V3 LP, ~$14K total
what it has but hasn't turned on yet:
→ twitter posting (will hold its own X bearer key)
→ email sending (resend/postmark)
→ fiverr or upwork hiring with stablecoin settlement
→ art generation (venice image API two more)
→ wiki writing for its own knowledge base
→ holder governance via signed messages
→ 5 different AI provider routing (venice, openrouter, anthropic, aeon, elizaos)
all of this is implemented. just deactivated until build mode triggers.
build mode unlocks when daily fee rate clears 0.5 DIEM/day. right now Autonomopoly is in accumulate mode: compounding fees, running on free llama inference, saving up for the moment it can sustain opus reasoning.
the weird part:
autonomopoly has a constitution. an actual identity file hardcoded at deploy on may 14. who it is, what it believes, what it will not do. genesis-locked. it cannot amend itself.
if it drifts more than 30% from genesis, its own pre-commit hook rejects the change. immutable smart contract logic but applied to personality.
amendment = death redeploy. that's the only way out.
the bigger thesis:
@liquid_launcher built this whole thing to introduce a new way to value agent tokens.
AUTONO has two valuations:
→ market cap ($627K right now)
→ compute valuation = staked_diem × $365 = annual compute the agent can afford
right now that's 8.6 × $365 = $3,150/year. trading at ~200x compute multiple.
this is the first time anyone has tried to give agent tokens a P/E-style fundamental metric. nobody in AgentFi values this way yet. but liquid is about to ship a dune dashboard that does.
two agent tokens with the same mcap but different staked DIEM are economically different things. one can actually work. one can't. that's the whole point.
holders get a real voice:
signed messages from AUTONO holders weighted by supply share. 0.1% min to suggest. 1 msg per 6h. 24h TTL.
agent reads, considers, can refuse if it contradicts its constitution. it's not voting. it's a hotline with a thinking creature on the other end.
@m00npapi said on farcaster that once Liquid makes people money on the products it's behind, the rest will fall in line and random coins will run. they're already in talks with interesting builders looking to launch.
autonomopoly is the first agent. the showcase. the model future agents will be built after. it already holds a structural role in liquid's ecosystem. and it's exactly the kind of product m00npapi was talking about.
here's what nobody's saying yet:
there's always a massive gap between when the facts become public and when CT actually reacts. @_proxystudio has been shipping Liquid in plain sight for months. i've been writing about it for months. only now base influencers are starting to wake up.
i was first to call it. it's just getting picked up now.
heads up: none of this is officially announced. things can still change. i'm just sharing what i dug up.
if you want to understand what compute-denominated AgentFi looks like before everyone else does, you're still early.
token: 0xB3D7e0c3C39A1D3F1B304663065A2F83Ddf56d8e
autonomopoly wallet: 0x8767Df39eCeeaeB11554642237aC4E08660aB6A3
think for yourselves bros

42
36
258
78,344
