
Building HyperFolio - HyperEVM Portfolio Tracker
Joined February 2025
- Tweets 2,600
- Following 261
- Followers 2,125
- Likes 3,807
258 Photos and videos







Pinned Tweet

Jan 20
I just released a new feature for Hyperfolio and the Hyperfolio API: Yield.
You can now browse thousands of yield opportunities on HyperEVM across nearly 30 protocols
10
4
33
2,796
Jun 8
1st of April: Qwen release Qwen 3.6 Plus
14th of April: Qwen release Qwen 3.6 35B A3B
1st of June: Qwen release Qwen 3.7 Plus
14th of June: Qwen release Qwen 3.7 35B A3B (?)
I believe
Jun 1

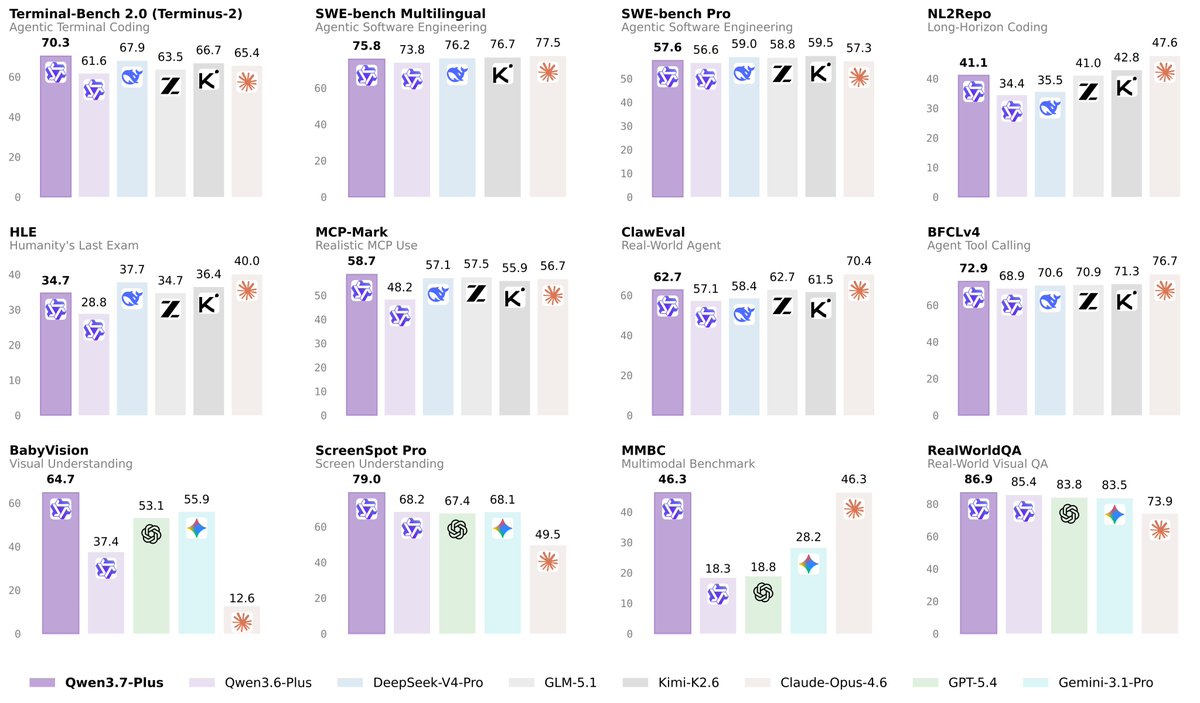
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:qwen.ai/blog?id=qwen3.7-plus
Qwen Studio:chat.qwen.ai/?models=qwen3.7…
API:modelstudio.console.alibabac…
5
2
105
9,792
stableAPY.hl retweeted

Jun 4
A bit worried about the upcoming Qwen 3.7 open source models
A Qwen team member recently deleted a comment where he said they would likely release another 27B model
The Summary section of the 3.7 Plus blog post doesn’t mention any upcoming open-source models, whereas the 3.6 Plus blog explicitly said they would be open-sourcing smaller-scale models
We also didn’t get the other two Qwen 3.6 models from the poll, 9B and 122B
I still think we’ll probably get some open-source models from the 3.7 series, but it’s unclear which sizes they’ll be or when they’ll arrive

21
14
274
28,909
Jun 4
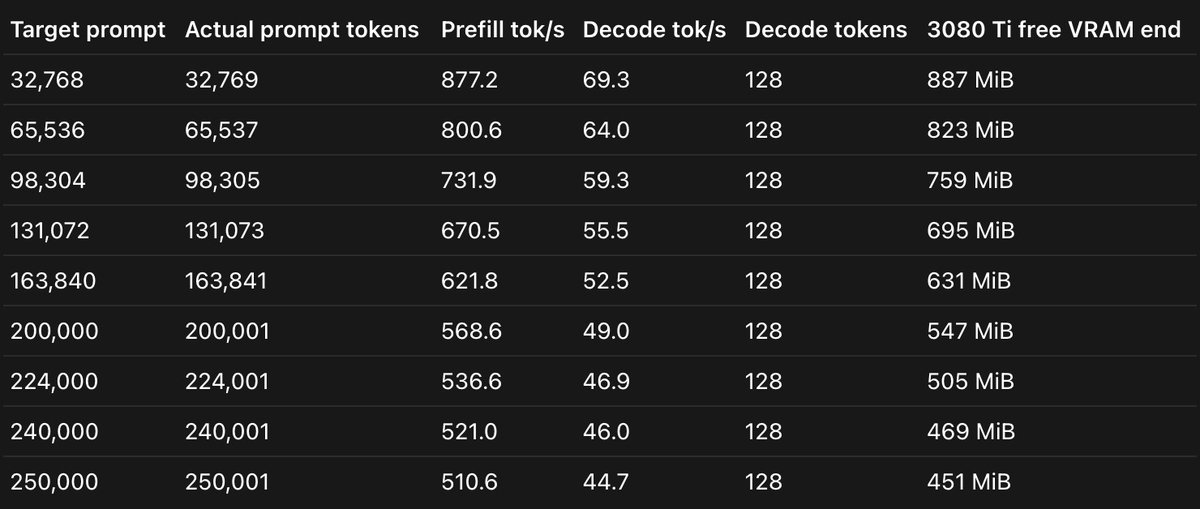
oh boy, I'm running Qwen 3.6 27B Q6_K using tensor split on both my RTX 3090 and 3080 with almost full context (250k).
yesterday, my friend sent me this reddit post: reddit.com/r/LocalLLaMA/comm…
turns out llama.cpp build b9455 allows for good tensor splitting across two GPUs
good news is: the 3090 and the 3080 have the same bandwidth (936 GB/s), so even though the 3080 has less VRAM, it won't drag down the 3090
this means I can split the model 70/30 between the two cards
based on my first tests, the MTP version gives me 69 to 44 tok/s in decode depending on context (it'll probably be less during a real coding session, I'll test it out later)
ngl, I'm pretty happy to be able to run bigger quants than Q4
I also tried the Q6_K_XL, which works a bit slower and has a tighter context window
Config: Q6_K, KV q8_0/q4_0, tensor split 70/30, ctx 252000, MTP, 3090 3080 Ti at 300W
Model: huggingface.co/unsloth/Qwen3…
5
2
45
3,840
Jun 3
wow this looks cool for my 3060 12gb gonna try it
Jun 3

Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

6
26
22,163
Jun 3
Jun 3

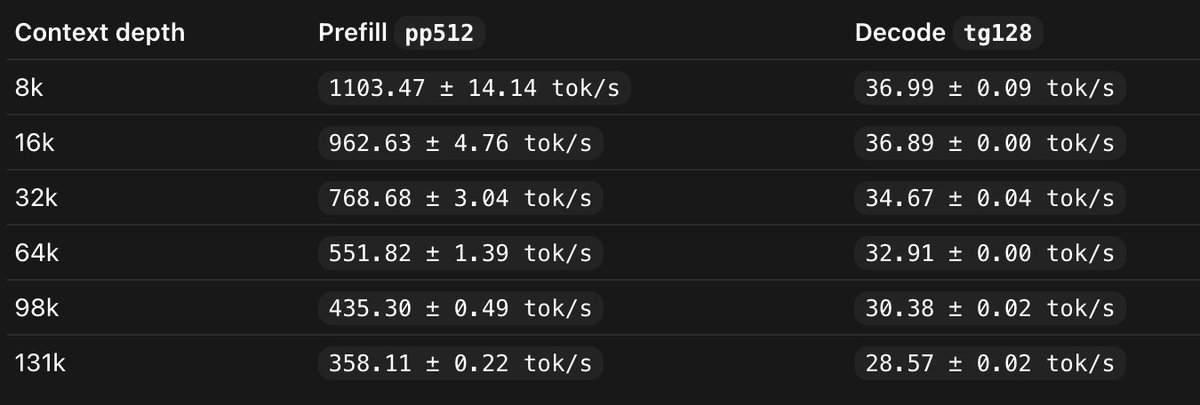
I've ran some tests on Gemma 4 12b on my RTX 3060 12gb
it seems to handle context pretty good and I have around 30tok/s almost all the way to 130k context
I asked GPT to test it out a bit for coding and comparing to Qwen 3.6 35B, and it seems quite close
I have tried the Q4_K_M from Unsloth, I want to see if the Q6 does any better quality wise
2
379
Jun 3
I've ran some tests on Gemma 4 12b on my RTX 3060 12gb
it seems to handle context pretty good and I have around 30tok/s almost all the way to 130k context
I asked GPT to test it out a bit for coding and comparing to Qwen 3.6 35B, and it seems quite close
I have tried the Q4_K_M from Unsloth, I want to see if the Q6 does any better quality wise
Jun 3
wow this looks cool for my 3060 12gb gonna try it
16
3
130
20,577

We're building the Docker for Local AI.
A simple way to package and share complete AI environments including models, runtimes, dependencies, and configuration.
One command. Same setup. Run anywhere.
Free and Open-source
we’re live on Product Hunt today.
3
3
3
178
Jun 2
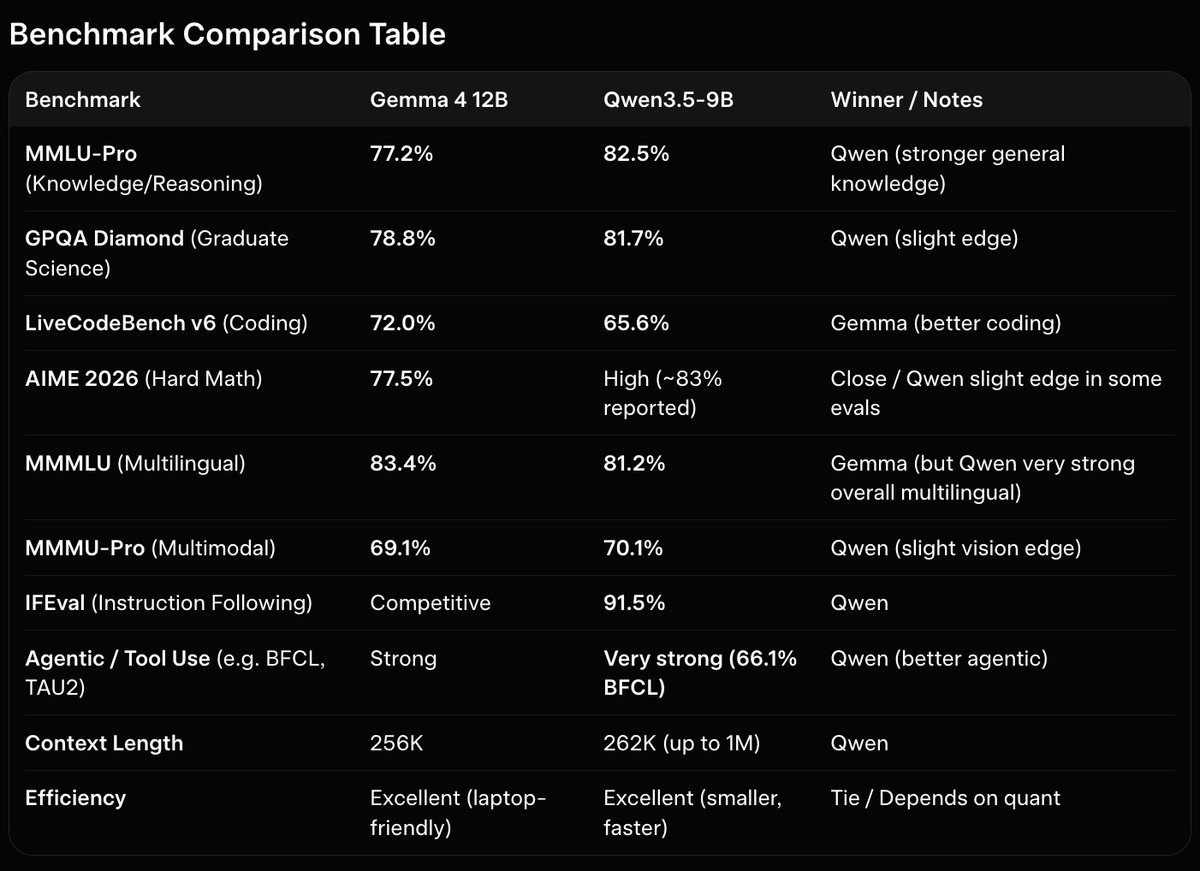
I really don't understand the point of not having like the full benchmark tested and rely on "Overall Performance" or "E-Commerce" aggregated data
model looks super cool, but idk I just feel rugged when labs do such things
also why everyone keeps having 3.5 on their benchmark even tho 3.6 exists
Jun 2

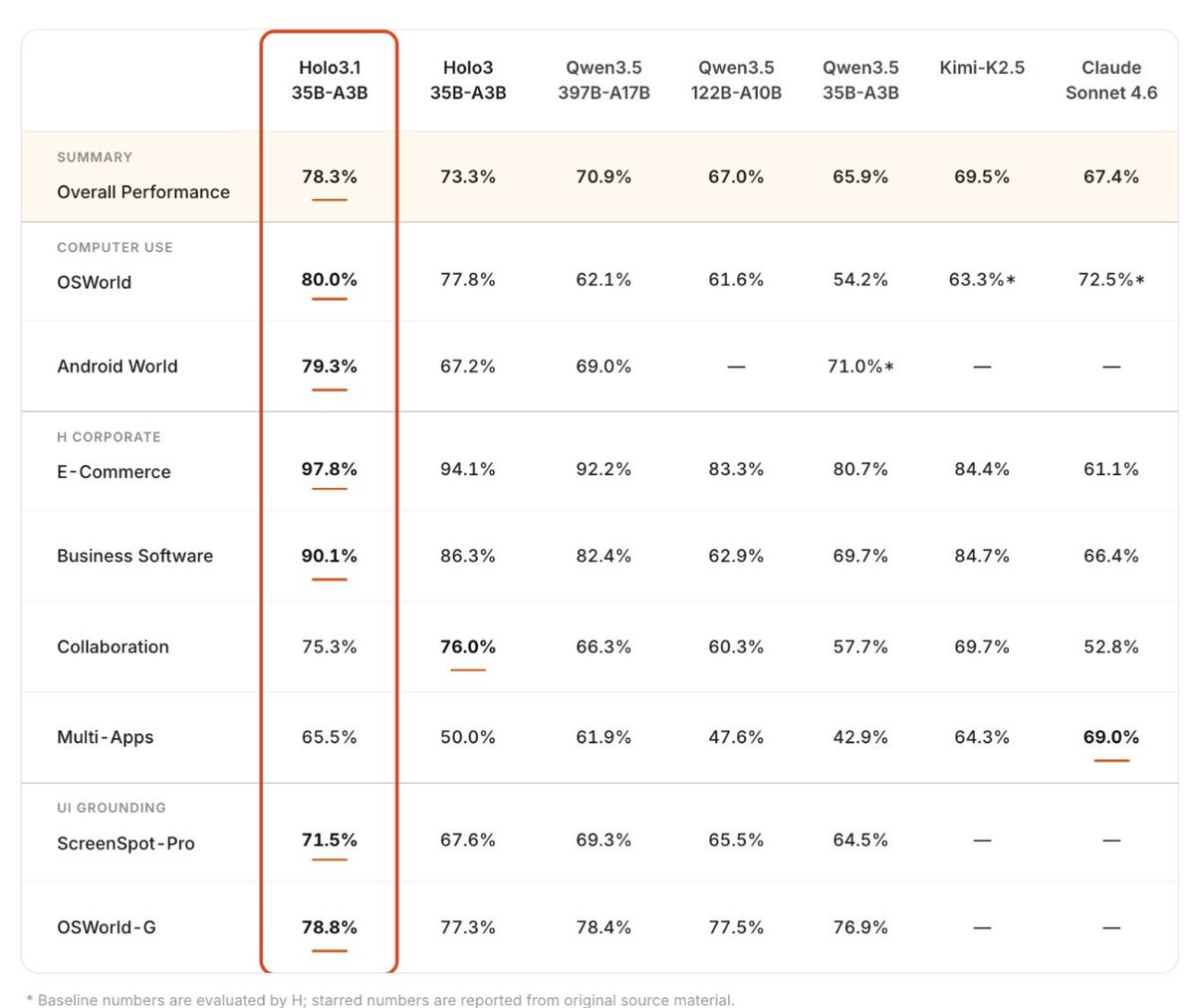
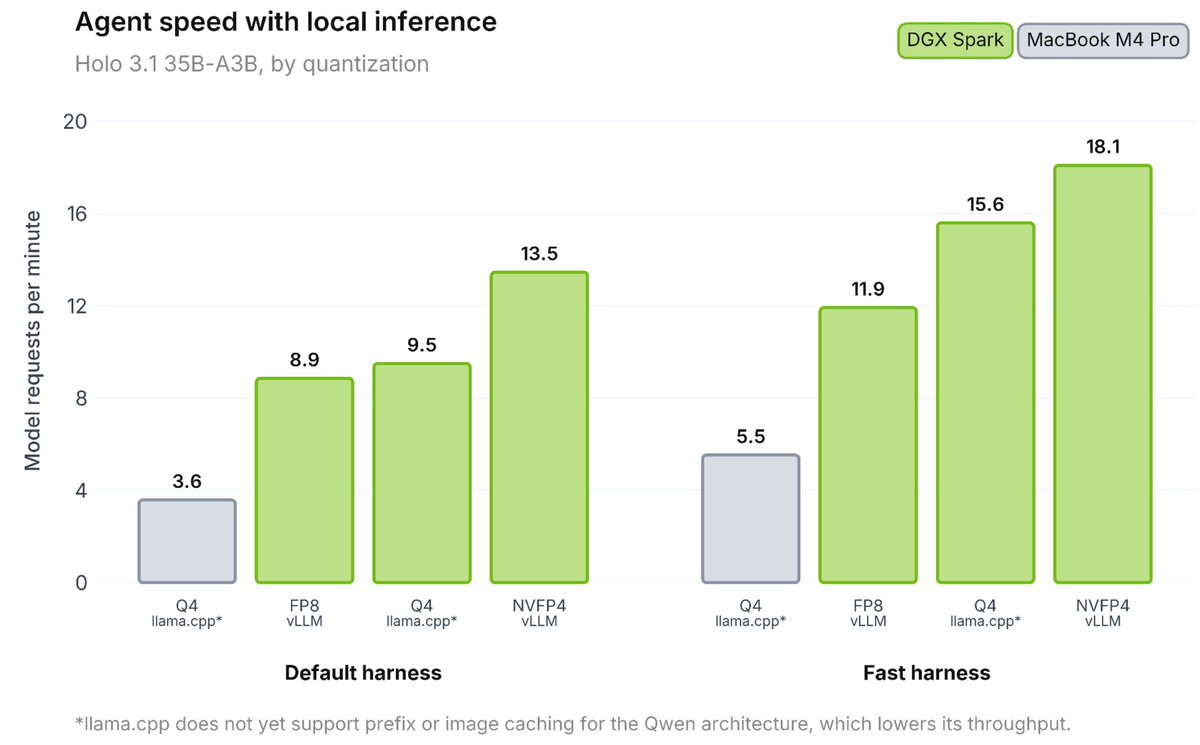
Computer-use agents are moving from the cloud to your local machine. Fast.
When we launched Holo3 two months ago, the production feedback was clear: digital agents need to be blazing fast, cost-effective, and versatile.
Today, we're dropping Holo 3.1, engineered to run anywhere, instantly.
Massive token throughput. Low latency. Ready for your local workflow!
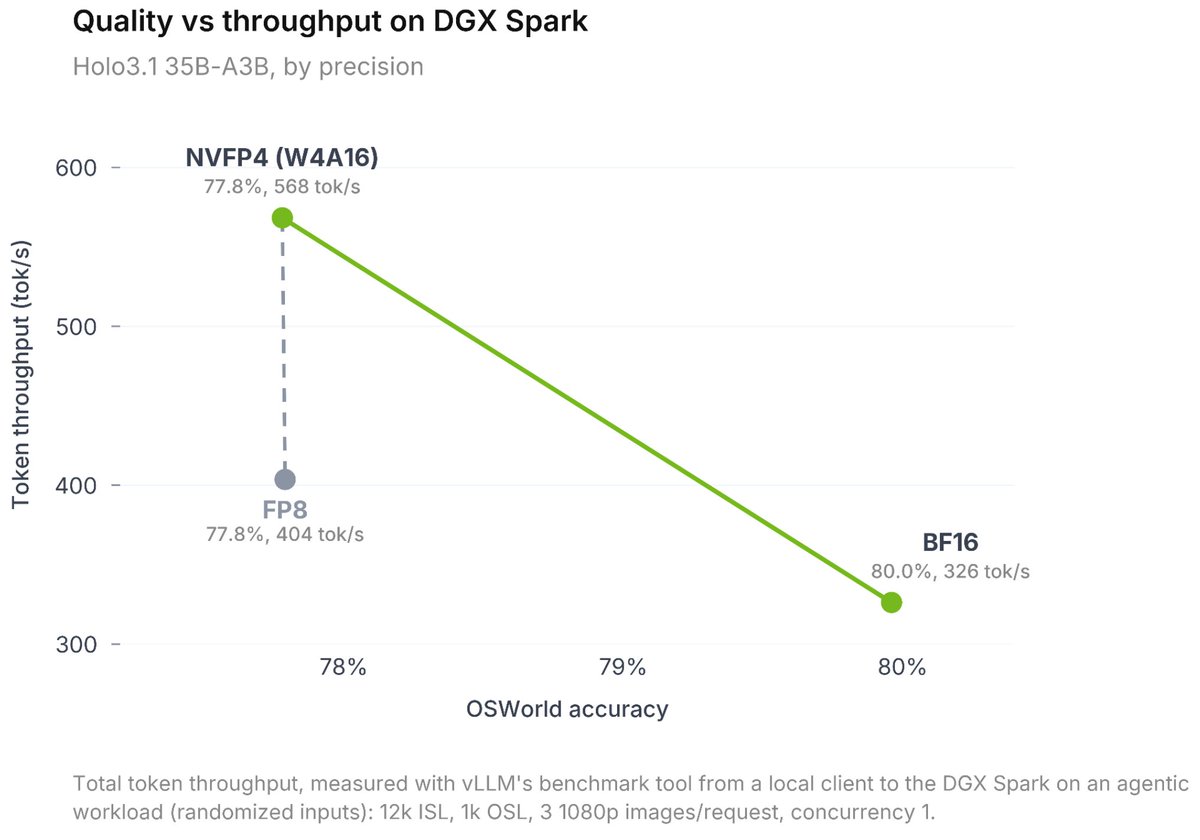

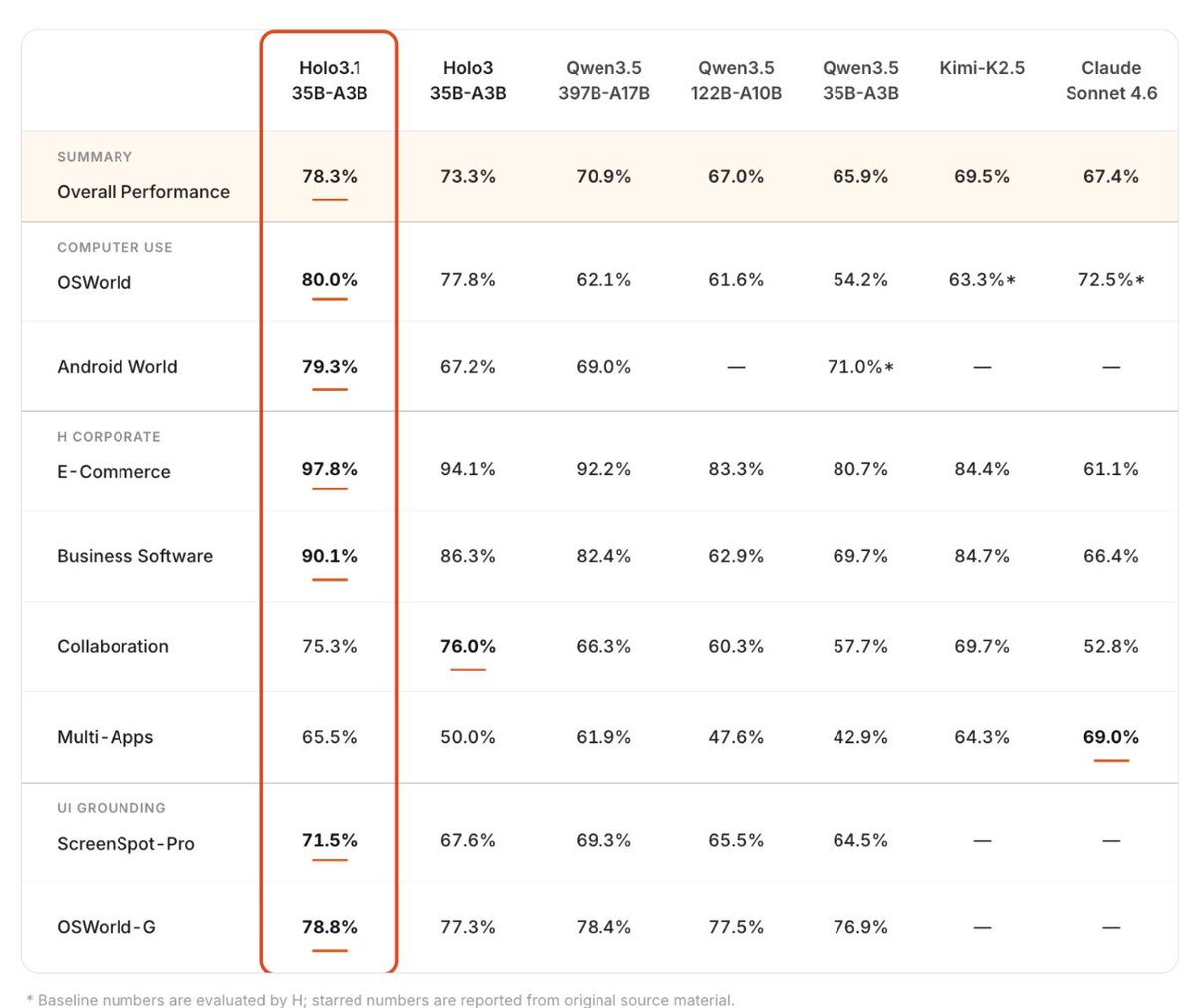
185
stableAPY.hl retweeted
Jun 1
next up: 35B A3B then 27B
right?
Jun 1
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:qwen.ai/blog?id=qwen3.7-plus
Qwen Studio:chat.qwen.ai/?models=qwen3.7…
API:modelstudio.console.alibabac…
19
4
242
19,039
Jun 2
27B running on my 3090 that delegate 2 code reviews to two 35B subagents running on my 3060 and 3080
pi is such a perfect harness for local AI
is this AGI?
19
5
136
14,400
Jun 1
I've tried tvall43's 14B REAP of Qwen's 35B A3B over the last few days on my 3060 and I have to say I'm quite surprised
Q4_K_M is 8.47 GB so this fits nice on the 12gb VRAM we have room for 64k context and --parallel 2 for sub agentic work
until now I felt that all the REAP I've tried where brain dead, or too broken to be useful
this 14B actually does stuff tho
I've benched it against 35B on 270-cases from different benchmarks (was mainly focused on coding and tool-use)
14B vs 35B:
- BFCL subset (120 items): 38.3% vs 72.5%
- LiveCodeBench-lite subset (80 items): 41.3% vs 52.5%
- Qodo review subset (40 items): 90.0% vs 92.5%
- small coding set (30 items): 33.3% vs 46.7%
overall on that 270-case mixed run, it retained ~69% of 35B's pass rate, while being faster and fitting on 12gb without any offload
I need to test it more in real coding with 27B as main agent and 14B as sub agent
1
2
241
May 31
fitted 3 GPUs in my homelab, had to cut the case a bit though
now let’s test how the case temperatures hold up under pressure
3
6
935
stableAPY.hl retweeted

We’re aware of the security reports linked to rewards payout. User funds and market resolution are safe.
Findings point to a private key compromise of a wallet used for internal top-up operations, not contracts or core infrastructure.
More updates to follow.
31
52
240
49,664
May 20
I got a new RTX 3090 coming in the mail today
let's finally try vllm with tensor parallelism to see what 35B and 27B can give
11
53
3,439
May 20
May 20
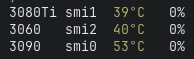
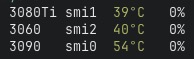
guess who just happens to have a 3080 ti 12gb in the mail instead of the 3090? 🤡
126
May 20
guess who just happens to have a 3080 ti 12gb in the mail instead of the 3090? 🤡
May 20
I got a new RTX 3090 coming in the mail today
let's finally try vllm with tensor parallelism to see what 35B and 27B can give
2
2
431

stableAPY.hl retweeted
May 19
while I really love the approach and the compute put to the work, I feel that those distill don't really bring much...
I've tested out this coder version vs the 9B Base:
9B Base:
- HumanEval full: 150/164 (91.5%)
- MBPP sanitized 100: 87/100 (87.0%)
9B Coder:
- HumanEval full: 124/164 (75.6%)
- MBPP sanitized 100: 80/100 (80.0%)
maybe those are not the best benchark to run against tho
1
1
2
216