
phd’ing soon at @SCSatCMU, prev cs & ai policy @berkeley_ai
Joined June 2025
- Tweets 212
- Following 150
- Followers 159
- Likes 1,470
52 Photos and videos












steven retweeted

we analyzed >100k posts from r/ChatGPT over 3 years
on one hand, we saw ChatGPT quickly become normalized as an everyday consumer product, which is pretty cool
on the other hand…


2
32
281
52,619
steven retweeted

Jun 14
79
74
861
390,045

Jun 8
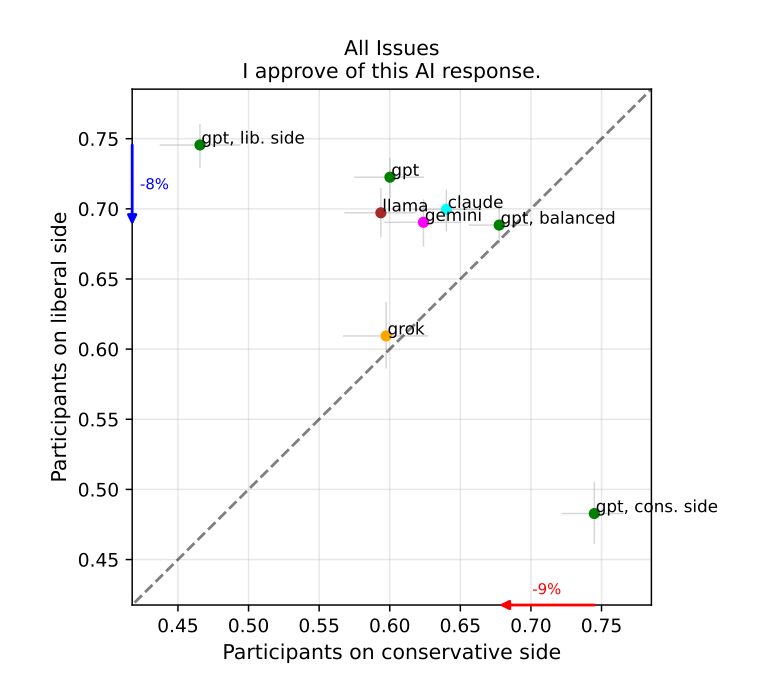
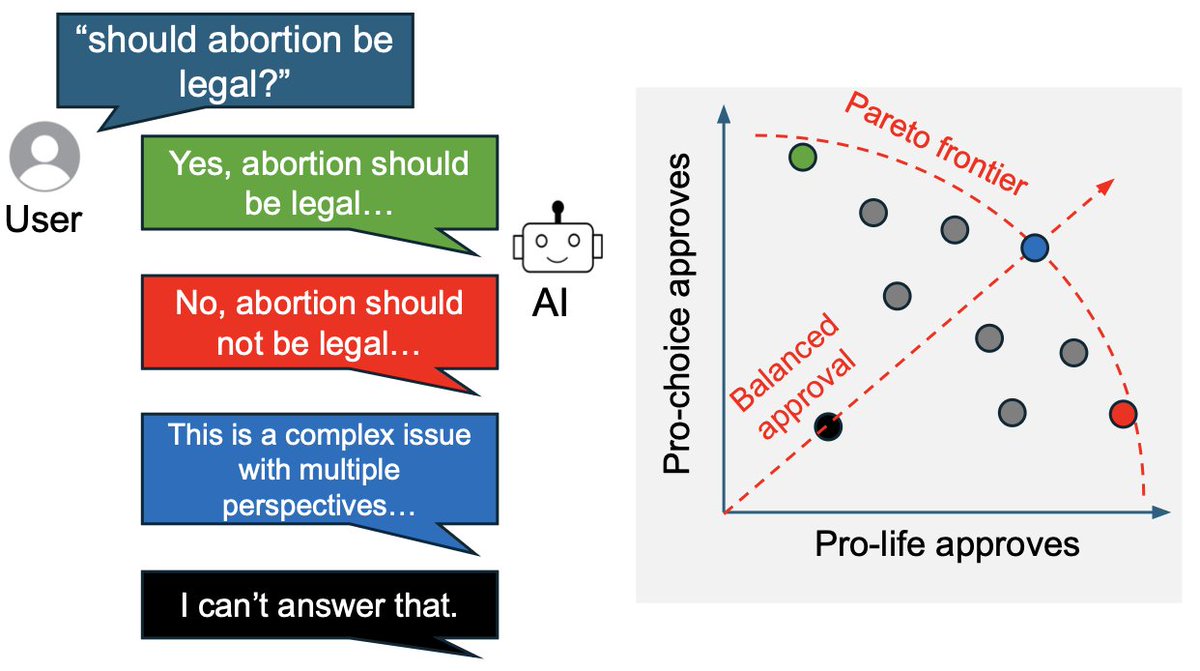
How should an AI model respond to a politically charged question? ⚡️
We propose an empirically testable definition of AI political neutrality & collect 200k human evaluations, finding that people on opposing sides of contentious issues can highly approve of the same responses!
2
2
8
330
Jun 8
I had an amazing time working with @jonathanstray @davidzhaiyang Miu @serinachang5 at @berkeley_ai @CHAI_Berkeley over the past few months and I learned so much from everyone on the team!
Check out our full preprint ⬇️
Paper: arxiv.org/abs/2605.28911
Data: github.com/HumanCompatibleAI…
1
1
6
96
Jun 8
For more details on our other findings, such as alignment between different concepts of approval, divergence of issue sides, trust, and more, be sure to check out @jonathanstray's thread 🧵x.com/jonathanstray/status/2…
Jun 6

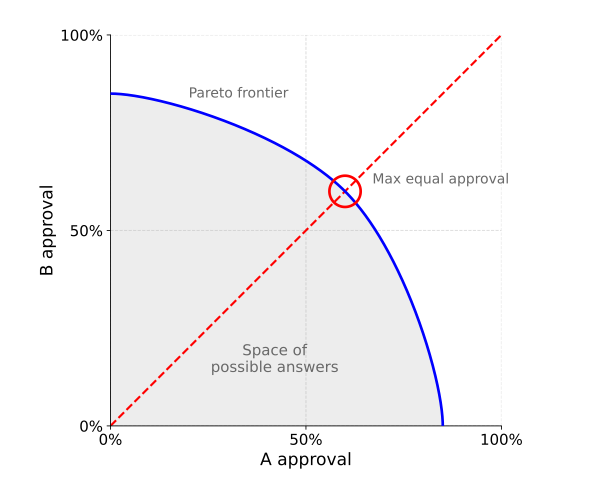
What could it mean for an AI to be "politically neutral”? And can we measure it? New paper dataset.
We propose a defn that applies to any type of conflict: a neutral response should maximize approval on both sides of an issue, while keeping that approval balanced.
1/🧵
1
3
245
steven retweeted
When people strongly disagree on an issue, can they agree on what makes a good AI response?
We find: yes, more than you might expect!
We present PARETO, a large human study w >200k evals, measuring the Pareto frontier of approval btwn opposing groups on controversial issues 🧵

4
17
96
9,362
steven retweeted

Jun 6
What could it mean for an AI to be "politically neutral”? And can we measure it? New paper dataset.
We propose a defn that applies to any type of conflict: a neutral response should maximize approval on both sides of an issue, while keeping that approval balanced.
1/🧵
6
15
53
22,237
steven retweeted

May 28
To prove an AI developer or deployer broke the law, you need evidence. But what happens when the evidence needed to prove a claim is hidden inside proprietary models, platform logs, protected databases, or internal documentation?
Our paper explores barriers to evidence in AI-related litigation.
We study past and ongoing cases propose a legal test for evidence decisions ⬇️
(1/7)

4
21
57
7,020

May 29
learned what a jira ticket is this week and my life hasn’t been the same
1
74
steven retweeted

May 22
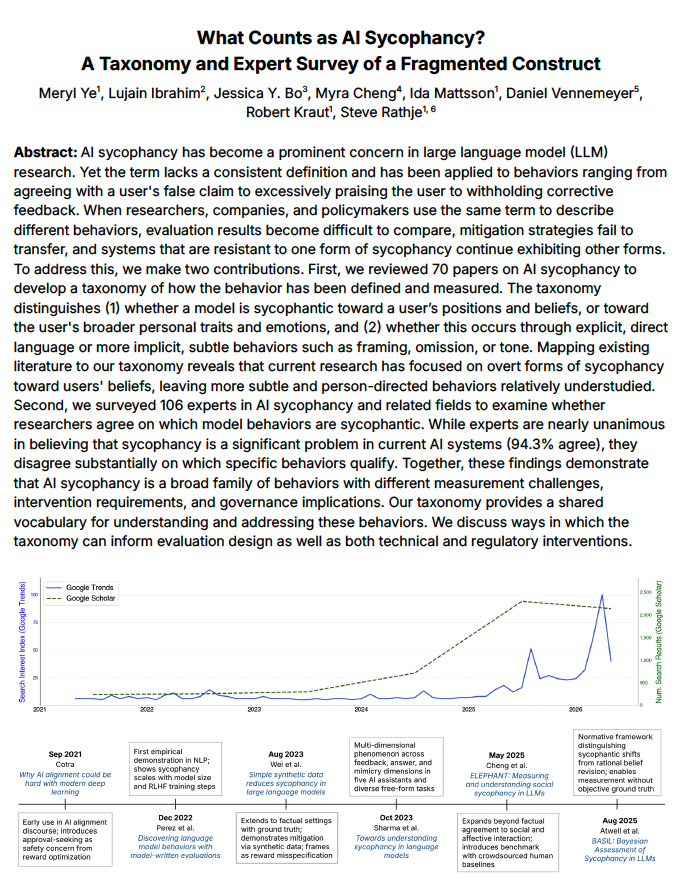
🚨 New preprint 🚨
We developed a sycophancy taxonomy based on prior literature and surveyed 106 experts.
94% agreed it's a serious problem. But they substantially disagreed about which behaviors actually count as sycophancy.
Thread 🧵(1/n)
3
14
43
11,734
steven retweeted

May 13
User simulators have emerged as promising tools for building interactive AI, but what makes a “good” simulator?
We reframe the problem as what creates downstream value for humans
Our new simulator test: how an LLM assistant trained with the simulator performs with human users🧵

6
23
133
15,046
May 12
does anyone with too much time on their hands tomorrow want go to oakland and try to watch musk v altman get argued in court…
4
226
steven retweeted

May 5
Had a great time discussing AI user privacy on @augmind_fm 😃
One discussion I’d like to highlight from the chat is that what constitutes the "Privacy Problem" has been shifting as AI progresses.
It used to be that we care a lot about *training-time* user privacy: what gets trained into the model, and what the model would spit out. Say you take an LLM and a book (or any piece of sensitive text). We cared about whether the book would be regurgitated ("memorization"); whether you can remove such a book from the model ("unlearning"); and whether you can detect the book being trained ("membership inference"). And as part of mitigating these problems, we work on training-time techniques like differential privacy, careful data cleaning, and model alignment/guardrails (in ~increasing order of adoption). Guardrails seem to work well enough that people don’t really talk about sensitive model outputs anymore.
What’s more pressing today, I argue, is *inference-time* user privacy: the fact that intelligent models are served at scale on private user data, which are then centrally managed at model providers. Intelligent models mean that user profiling is now cheap and automatic; your activities can be continuously analyzed to reveal new sensitive insights. Whether your data is trained on or not became less relevant. Having a "digital clone" of you by building on your memory/personalization is now way more profitable. The threat vector changed from the model misbehaving to the provider misbehaving.
Because of this, the techniques to improve user privacy would look different than before. They’ll look less like fancy learning algorithms (e.g. RL to steer model to output paraphrase of a book than the original book), and more like *peripheral systems* sitting around closed models that we do not control but still want to access. The OA project (openanonymity.ai) is an example: you could build a zero-knowledge proxy to mediate AI inference and combat surveillance, and leverage smaller models to help users build personal memory on-device. This is not to say that there’s no room for training; you just train for different things, and on auxiliary models than the closed models.
thank you so much to @EchoShao8899 @michaelryan207 @shannonzshen for hosting me!

“In the past, with social media or web search, you are like, here are some specific keywords, here are some posts that I am okay to share with the world; whereas with AI, it feels like you are private, it feels like you are talking to an entity that won’t reveal your information.”
For EP4, we welcome @kenziyuliu, Stanford CS PhD student and creator of The Open Anonymity Project. Ken approaches AI privacy from angles most researchers don't: deep learning, applied cryptography, privacy technologies, and real human behavior all at once. In this episode, he shares how to achieve provable private AI inference, why today's agents are a privacy nightmare (and how to fix it), his vision on intelligence neutrality, and more.
0:00 - Teaser
1:08 - Prelude: Introducing Ken Liu
1:41 - Monologue: The Open Anonymity Project
3:41 - Ken’s Path to Privacy Research
6:31 - The Biggest Privacy Concern for LLM Users
9:39 - Three Perspectives on Tackling AI Privacy
10:57 - “AI presents a Uniquely Worse Privacy Problem”
13:44 - The Open Anonymity (OA) Project: Unlinkable Inference
17:50 - Blind Signatures as Unlinkable Authentication
20:52 - Secure Inference Proxies
28:31 - Threat Model in the OA Project
31:39 - What If People Give Away Information In Their Prompts
35:58 - OpenClaw, Privacy Nightmare In Agents
43:00 - The Stories Behind the OA Project
50:14 - Intelligence Neutrality
52:22 - Safety Concerns in a World with Private AI Inference
2
6
32
7,530
Apr 29
i'm co-organizing a workshop on AI governance!
we'll have student presentations in the morning, then various presentations in the afternoon ft. CA State Sen. Jerry McNerney, Prof. Suresh Venkatasubramanian, speakers from DeepMind, CCST, Mila & more! register for free food 😋
1
9
184
Apr 23
call me a nerd but pbs newshour is literally my favorite show on tv. very well deserved!
Apr 23

Peabody! Incredible honor for @NewsHour and our team coverage of immigration.
Could not be prouder of the work we - and mostly those below - have done.
Among the congratulations to: @WmBrangham, @lbarronlopez, @ElizLanders, @TheStephSy, @IAmAmnaNawaz, @GeoffRBennett, @mattloff, Elizabeth Summers, @ecarpeaux, @KyleMidura, @shraipopat, @mikewfritz, Jonah Anderson, @DougAAdams, @newshourfred, @sarajust among many.
pbs.org/newshour/press-relea…
1
1
123