
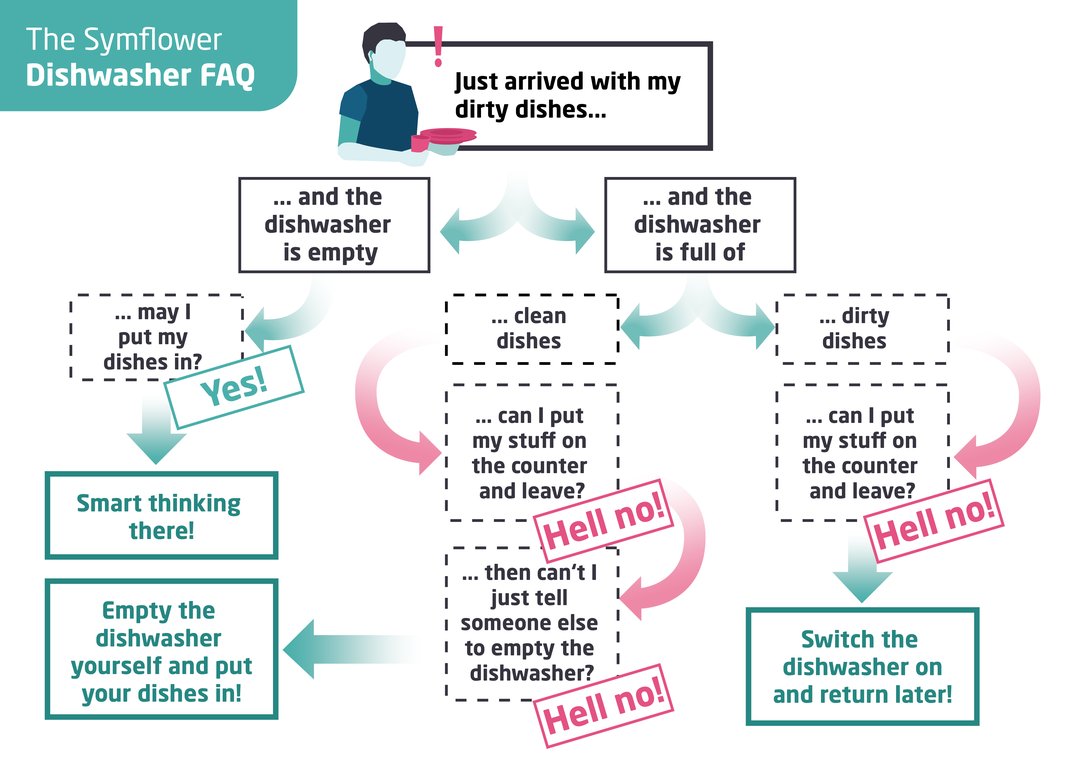
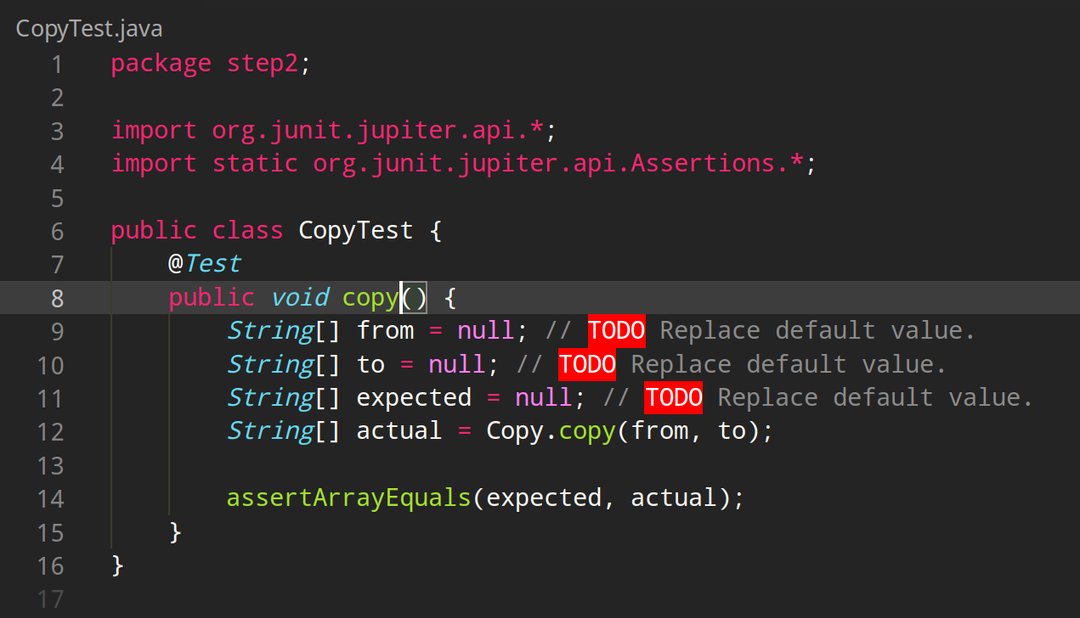
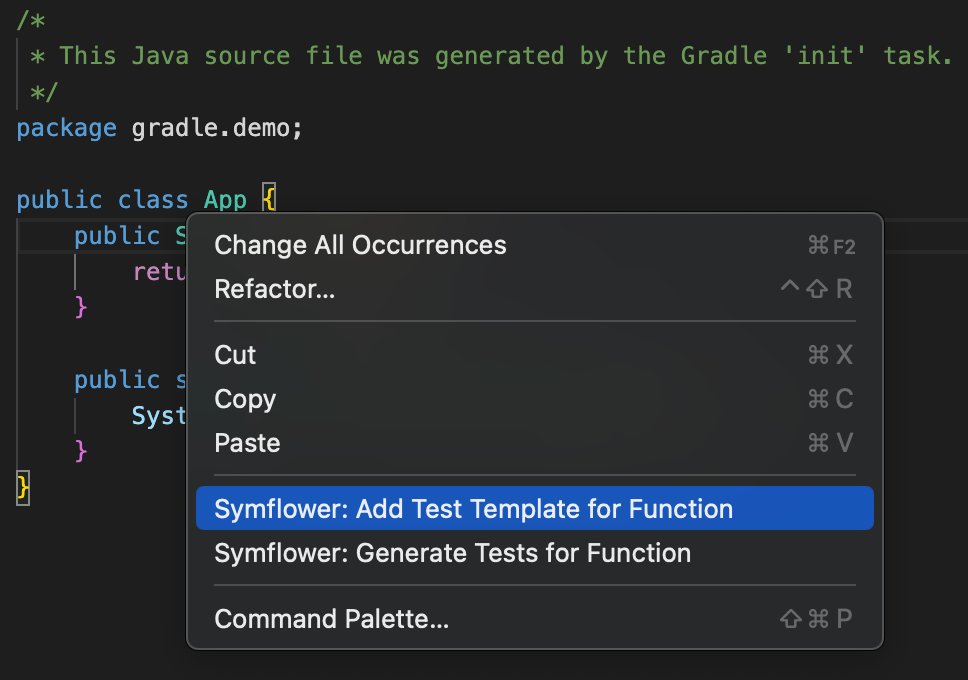
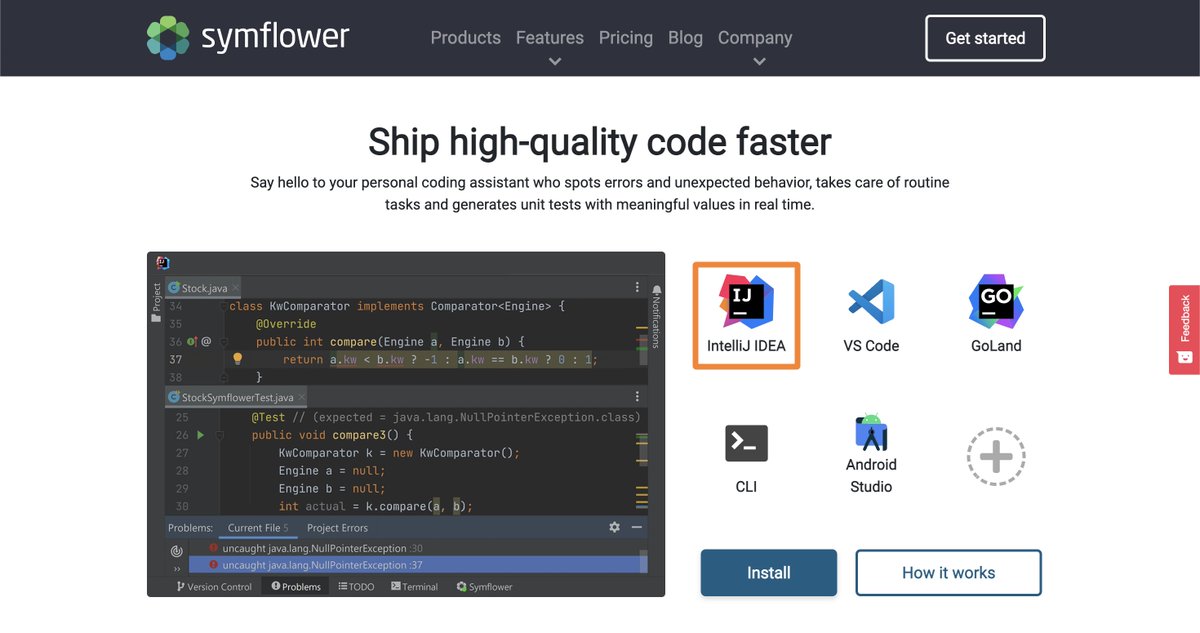
Your virtual coding assistant who spots errors and unexpected behavior, does routine tasks for you and generates unit tests with meaningful values in real time.
Joined May 2017
- Tweets 517
- Following 121
- Followers 303
- Likes 120
154 Photos and videos






Pinned Tweet

20 Jul 2022
Ever wished you can just generate your #unittests instead of painfully writing them? In this video 👇 Evelyn demonstrates of how to use get.symflower.com to speed up your daily development workflow 🚀✨
youtu.be/hYWpwJ6O7hE
#golang #java
6
26 May 2025
Benchmarking LLM agents 💡 Our latest post covers useful benchmarks for evaluating LLM code generation agents and agentic software development workflows.
symflower.com/en/company/blo…
#LLMAgents #SoftwareDevelopment #Benchmarking #AI #Coding
1
1
45
23 Apr 2025
New to LLM coding agents? 🤖 Our introduction covers the capabilities, limitations, and use cases of LLM agents for software development 👇
symflower.com/en/company/blo…
1
37
17 Mar 2025
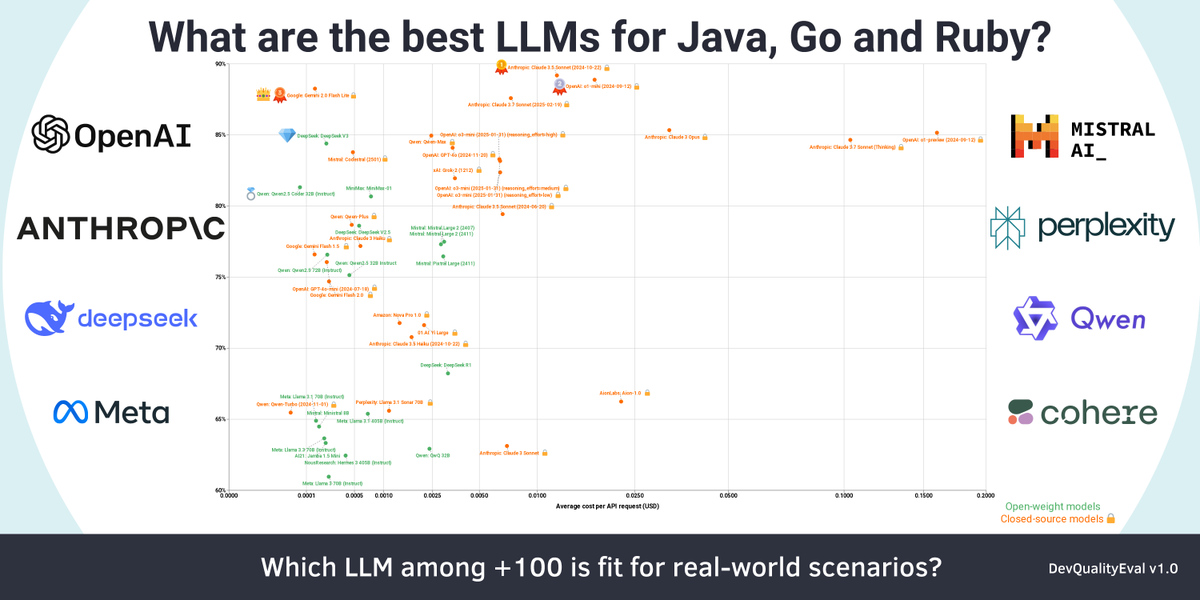
Updated DevQualityEval v1.0 results are in 👀 Check out how our new king of cost-effectiveness (Google’s Gemini 2.0 Flash Lite) performed, and find out if Claude 3.7 Sonnet (Thinking) is worth the additional costs 👇
13 Mar 2025

Insights of analyzing >100 LLMs for the DevQualityEval v1.0 (generating quality code) in latest deep dive
- 👑 Google’s Gemini 2.0 Flash Lite is the king of cost-effectiveness (our previous king OpenAI’s o1-preview is 1124x more expensive, and worse in score)
- 🥇 Anthropic’s Claude 3.7 Sonnet is the functional best model (with help) … by far
- 🏡 Qwen’s Qwen 2.5 Coder is the best model for local use
- Models are on average getting better at code generation, especially in Go
- Only one model is on-par with static tooling for migrating JUnit 4 to 5 code
- Surprise! providers are unreliable for days for new popular models
- Let’s STOP the model naming MADNESS together: we proposed a convention for naming models
- We counted all the votes, v1.1 will bring: JS, Python, Rust, …
- Our hunch with using static analytics to improve scoring continues to be true
All the other models, details and how we continue to solve the "ceiling problem" in the deep dive: 👇🧵
(now with interactive graphs 🌈)
Looking forward to your feedback :-)
1
154
1 Oct 2024
We analyzed 80 #LLMs for generating quality code 👀 Here‘s the deep dive blog post for the DevQualityEval v0.6:
symflower.com/en/company/blo…
2
95
30 Sep 2024
We analyzed >80 LLMs in the deep dive blog post from DevQualityEval v0.6 for generating quality code. Check out the insights and results 👇
30 Sep 2024
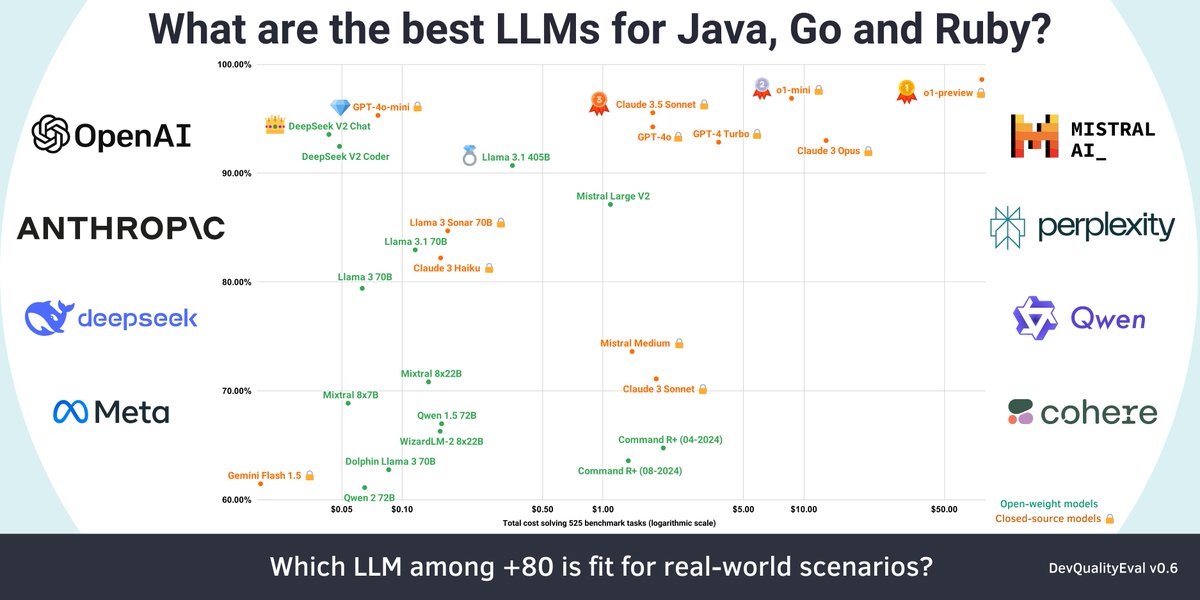
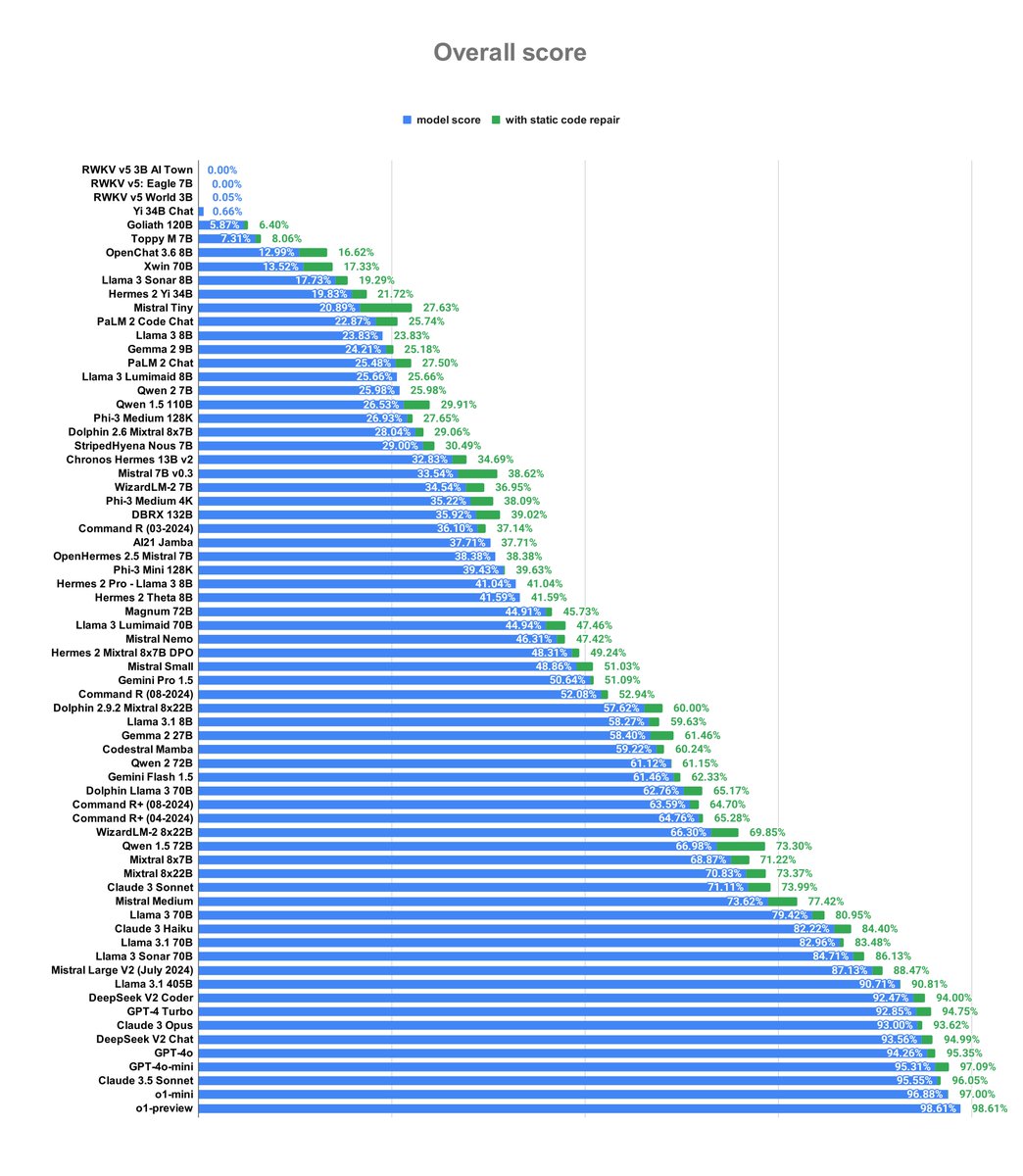
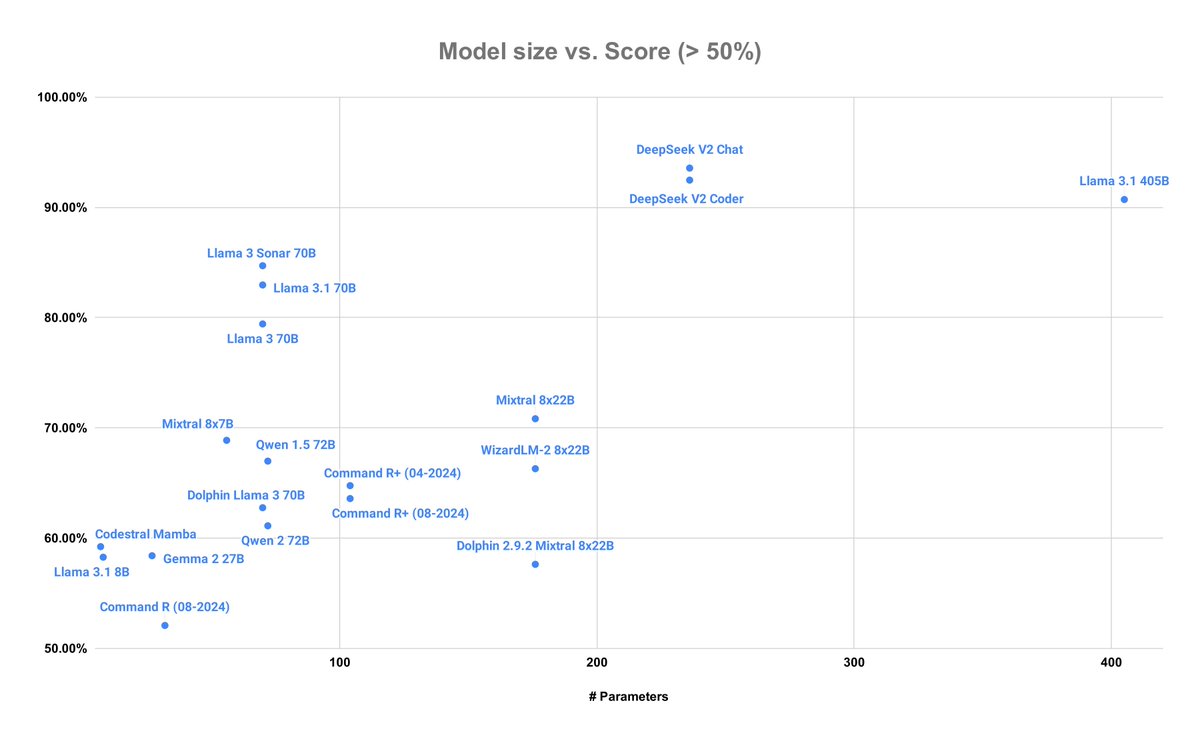
OpenAI's o1-preview is the king 👑 of code generation but is super slow and expensive 😱 This and other insights of analyzing >80 LLMs in the deep dive blog post from the DevQualityEval v0.6 for generating quality code 👇
- OpenAI’s o1-preview and o1-mini are slightly ahead of Anthropic’s Claude 3.5 Sonnet in functional score, but are MUCH slower and chattier.
- DeepSeek’s v2 is still the king of cost-effectiveness, but GPT-4o-mini and Meta’s Llama 3.1 405B are catching up.
- o1-preview and o1-mini are worse than GPT-4o-mini in transpiling code
- Best in Go is o1-mini, best in Java GPT4-turbo, best in Ruby o1-preview
Please support our work for the community by liking and sharing this post! 🙏
All the details and how we will solve the "ceiling problem" in the deep dive symflower.com/en/company/blo… (2x the content as the previous one!)
1
3
146
18 Sep 2024
#Java 23 is out! 🥳 Learn about all the updates & new features in #JDK23:symflower.com/en/company/blo…
1
511
12 Sep 2024
Execute only the tests you need 💡We see a 29% reduction in test execution times with just a basic approach. Details of the benchmark, example & guide: symflower.com/en/company/blo…
1
43
4 Sep 2024
Need to cut #LLM costs? 🤑 Read up on the key practices you can use to optimize your LLM spending 👌
symflower.com/en/company/blo…
1
2
69
30 Aug 2024
#LLM #observability 👀 Monitoring can help improve the performance of your LLM applications. Here’s what you need to know & the most useful tools for LLM observability 🔍
symflower.com/en/company/blo…
1
91
30 Aug 2024
We used #LLMs to #transpile #Java and #Golang code to #Ruby 🦾 Here‘s what we experienced:
symflower.com/en/company/blo…
1
3
1,036
13 Aug 2024
Are you using #AI-powered tools in your #softwaredevelopment workflow❓ Aider is a good example that works well and even offers voice coding 🦾 Here’s our guide to using Aider:
symflower.com/en/company/blo…
1
1
91
12 Aug 2024
Lost in the sea of #LLM #codegeneration tools? 🌊 We’ve got you! Here’s our list of the top #AI tools for #softwaredevelopment:
symflower.com/en/company/blo…
1
1
64
22 Jul 2024
How well do #LLMs generate code ❓ There’s only one way to find out: #benchmarking models for #softwaredevelopment tasks. Here’s a roundup of popular LLM benchmarks & insights into our take on the topic 🤓
symflower.com/en/company/blo…
1
1
71
12 Jul 2024
Looking to evaluate LLMs? 👀 This post helps you navigate the #LLM #benchmark landscape 🧭
symflower.com/en/company/blo…
1
49
11 Jul 2024
What metrics do you track when evaluating #LLMs? 👀 Here‘s an overview of complex statistical and model-based scorers 💡 Bonus: we also cover the #evaluation #frameworks that help you get started assessing #LargeLanguageModels. symflower.com/en/company/blo…
1
2
64
8 Jul 2024
Have you ever tried to fix performance issues in your #GoLang application but could not find why it was taking longer sometimes? 🚀 Instrumenting your application for #Go #tracing 💡might be what you need:
symflower.com/en/company/blo…
2
60
5 Jul 2024
#Java 23 is coming in September 🥳 Here’s what you can get excited about in #JDK23! Check out all the updates in this release:
symflower.com/en/company/blo…
1
37
5 Jul 2024
Do you #reuse code? ♻️ Optimizing code for #reusability helps drive down development effort and cost while improving quality. Here’s a list of the most important reusability best practices for #Java #coding:
symflower.com/en/company/blo…
1
38
4 Jul 2024
Confused by LLM evaluation? 😵💫 We can’t blame you. Our new series on LLM #benchmarking guides you through all you need to know about measuring #LLM performance:
symflower.com/en/company/blo…
2
418
3 Jul 2024
Struggling with performance bottlenecks in your #GoLang app? 🤔 #Go #tracing to the rescue! Explore our comprehensive guide and conquer even the toughest optimization challenges 💪
symflower.com/en/company/blo…
2
57