
This #InfoQ article presents a least-privilege AI Agent Gateway that controls how agents access infrastructure.
Every request is: ✅ Validated ✅ Authorized ✅ Executed in isolated, short-lived environments
Read now: bit.ly/4qUu1kg
#AI #AIagents #MCP #CodeGeneration

2
1
6
881

Grammar-Constrained Decoding Exploited for LLM Jailbreaks
[SECURITY]
Grammar constraints can jailbreak LLMs for malicious code.
Why it matters: A fundamental technique for improving LLM code reliability, Grammar-Constrained Decoding, has been identified as a critical vulnerability. This discovery exposes a novel attack vector for generating malicious code, posing significant security risks for systems relying on LLMs for code generation.
Follow DailyAIWire for the full brief.
🤔 How can developers balance the need for syntactically valid code generation with robust security against novel jailbreak techniques?
#LLMSecurity #Jailbreak #CodeGeneration #AIvulnerability #CodeSpear
14

Jun 12
FrontierCode: 정확성을 넘어 "병합 가능한 코드 품질"을 측정하는 벤치마크 (feat. Cognition)
(by 9bow님)
d.ptln.kr/10623
#llm #agent #benchmark #codegeneration #evaluation #cognition
1
1
25

Jun 12
💻Amazing Work!
🤖PromptTone: A Dataset for Evaluating Large Language Model Code Generation Under Varying Prompt Politeness Levels
🧠by Andruccioli et al
#PromptEngineering #CodeGeneration #Dataset #AIEvaluation #LLM #HumanComputerInteraction
🎯mdpi.com/2306-5729/11/4/88

11

Jun 10
Claude Fable 5 is now in GitHub Copilot for Pro users, offering superior, efficient AI for complex coding. Note 30-day data retention.
#claudefable5 #githubcopilot #aimodels #codegeneration
69
Jang David retweeted

Jun 7
KForge: LLM-Driven Cross-Platform Kernel Generation for AI Accelerators
#CUDA #PTX #Triton #LLM #CodeGeneration #Intel
hgpu.org/?p=30832
2
13
731

Jun 7
Developers report unpredictable outcomes from AI code generation. "Closing the loop" — refining inputs based on outputs — is key but still an unsolved challenge. #AIDevelopment #CodeGeneration
2

During today's #LangSec Workshop at #IEEESP2026 (3 PM PDT), @jvanegue delivers an Invited Talk about using #LLMs for software specification synthesis in program proving what comes next for automated program verification using LLMs
bloom.bg/4fvqTsZ
#GenAI #CodeGeneration

2
5
838
May 19
10
751

May 18
🔗 Utilizing Claude Skills in client projects
spatie.be/blog/utilizing-cla…
#laravel #automation #livewire #ai #codegeneration
2
2
28
4,350

May 16
We have so much AI generated code these days and running this has always been a quiet source of anxiety for teams. The promise is huge, but the risk of letting models touch your infrastructure is real. E2B is one tool that steps into that gap with isolated cloud sandboxes built specifically for this kind of work.
The article below from Moein Moeinnia discusses practical details like 150ms startup times on Firecracker microVMs, multi language support, file system access, and sessions that can run up to 24 hours. It also covers how companies like Perplexity, Hugging Face, and Manus actually put these sandboxes to use in production.
lckhd.eu/YRhxu0
#llm #codeGeneration #Isolation #MicroVM #Firecracker

4
249

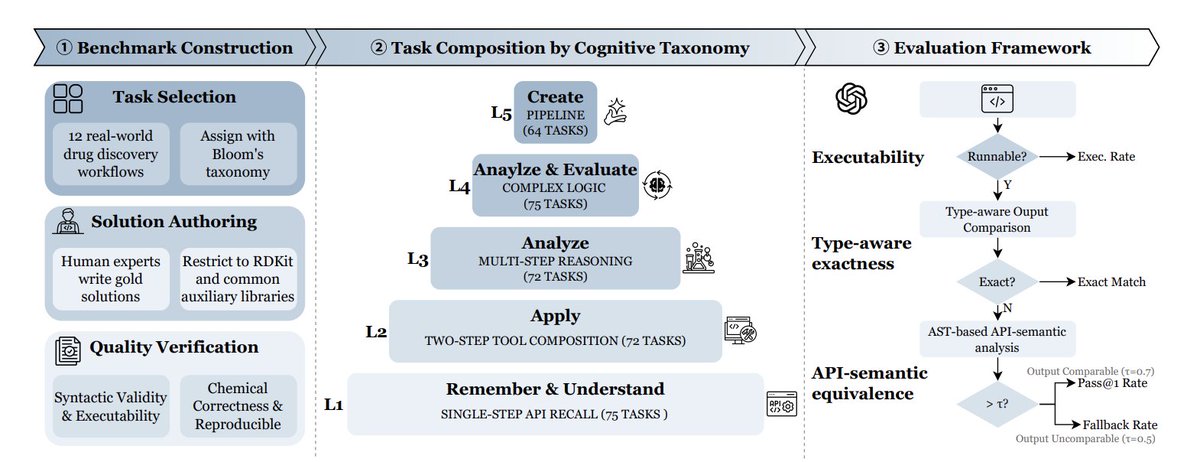
MolViBench: Evaluating LLMs on Molecular Vibe Coding
1 MolViBench is introduced as the first benchmark explicitly targeting “Molecular Vibe Coding”: chemists describe molecular tasks in natural language, and LLMs must generate executable RDKit-centric Python programs that are also chemically correct.
2 The benchmark contains 358 curated, real-world molecular coding tasks spanning 12 drug-discovery workflow categories (e.g., ADMET screening, virtual screening, reaction simulation, clustering/selection, QSAR/ML, stereochemistry, rule-based filtering, cheminformatics I/O), aiming to test the intersection of programming molecular understanding domain reasoning.
3 A key design choice is cognition-driven difficulty, organized into five Bloom-style levels: L1 single-API recall (descriptors, conversions), L2 two-step tool composition (fingerprints similarity, clustering, conformers), L3 multi-step chemical reasoning (reactions, ADMET heuristics, alerts like PAINS/Brenk), L4 branching/iteration/error recovery patterns, and L5 end-to-end pipeline creation (virtual screening pipelines, GA optimization, scaffold-split QSAR, Pareto/MPO ranking).
4 To make evaluation deterministic and comparable, tasks are constrained to RDKit as the primary toolkit (with limited auxiliary libs: numpy/pandas/scikit-learn/matplotlib/selfies). Each task has a human-authored gold reference solution under a unified interface (a single function named level_function), plus two-round quality verification for executability and chemical correctness.
5 The evaluation framework goes beyond plain unit-test exact match, because molecular tasks often have heterogeneous outputs and multiple valid solution paths. It uses a 3-stage scheme: (i) executability checks (compile entry-point runtime on multiple inputs with timeout), (ii) type-aware output comparison (tolerances for floats, canonical SMILES equivalence, recursive checks for structured outputs), and (iii) an AST-based API-semantic fallback that measures whether the generated code uses the appropriate RDKit functional categories when outputs are incomparable or when alternative valid implementations exist.
6 The paper reports systematic results on 9 frontier coding LLMs across three inference paradigms: Direct Generation (single shot), Incremental Repair (execute feed traceback for up to 3 repair rounds), and Agent Collaboration (Coder–Tester loop where a tester proposes test plans and validates plausibility).
7 Best overall performance is achieved by Claude Opus 4.6 Thinking with Incremental Repair (Pass@1 = 39.7%, Executable rate = 98.9%, Fallback Pass Rate = 72.6%). Across models, executability can be high while chemical/output correctness remains a bottleneck, motivating the multi-layer evaluation.
8 Performance drops monotonically with higher cognitive levels for all models; notably, every model remains below 10% Pass@1 on Level 5 tasks, highlighting a persistent gap in synthesizing long-horizon, end-to-end molecular discovery pipelines (planning, orchestration, and robust glue code).
9 Error analyses illustrate domain-specific failure modes: subtle RDKit API confusions that change return types (e.g., QED.qed vs QED.default), “over-engineering” outputs (returning dict metadata instead of requested scalar/SMILES), and chemically wrong reaction SMARTS due to small mapping/aromaticity constraints that yield fundamentally different products.
10 Incremental Repair is found to be consistently robust across models and levels, while Agent Collaboration is more sensitive: it can help weaker models but may degrade stronger models by introducing unnecessary rewrites that break partially correct solutions.
💻Code: github.com/phenixace/MolViBe…
📜Paper: arxiv.org/abs/2605.02351
#LLM #CodeGeneration #Cheminformatics #RDKit #DrugDiscovery #Benchmark #MolecularAI #VirtualScreening #QSAR #ADMET
3
759
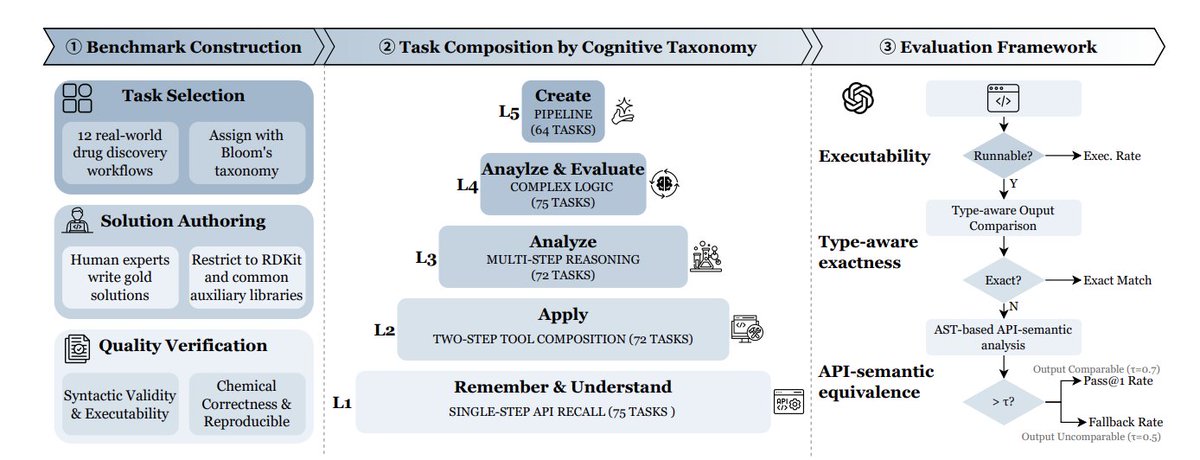
MolViBench: Evaluating LLMs on Molecular Vibe Coding
1. MolViBench frames a practical gap: “Molecular Vibe Coding,” where chemists describe molecular tasks in natural language and expect LLMs to generate executable RDKit-based Python that is both runnable and chemically correct—beyond tool-calling agents and beyond text-only chemistry QA.
2. The benchmark contains 358 curated, expert-authored tasks spanning 12 real drug-discovery workflows (e.g., molecular characterization, ADMET screening, virtual screening, combinatorial chemistry, lead optimization, reaction simulation, clustering/selection, QSAR/ML, stereochemistry, rule-based filtering, and cheminformatics I/O).
3. A key design choice is cognition-driven difficulty, organized into 5 levels aligned with Bloom’s taxonomy: L1 single-step API recall; L2 two-step tool composition; L3 multi-step chemical reasoning (reactions, ADMET logic, alerts); L4 branching/iteration/error recovery patterns; L5 creating end-to-end pipelines (screening, optimization, QSAR with scaffold split, Pareto ranking).
4. MolViBench restricts implementations to RDKit (plus numpy/pandas/scikit-learn/matplotlib/selfies) to reduce cross-toolkit nondeterminism, and provides gold reference solutions under a unified interface (a single function named level_function), with two-round quality verification and standardized test molecule sets.
5. The paper argues that executability alone is insufficient in chemistry: code can run yet be chemically wrong (e.g., stereochemistry mishandling, incorrect reaction SMARTS, invalid products). MolViBench therefore evaluates both “can it run?” and “is it chemically/semantically right?”
6. The evaluation framework is multi-layered: (i) executability checks (compile, entrypoint existence, runtime on multiple inputs with timeout), (ii) type-aware output comparison (tolerances for floats, canonical SMILES equivalence, recursive checks for structured outputs), and (iii) an AST-based API-semantic fallback that measures overlap between predicted vs. reference RDKit API categories when exact output comparison is infeasible or overly strict.
7. Reporting goes beyond Exact Match: the main metric Pass@1 triggers API-semantic fallback only when outputs are structurally incomparable (using a coverage threshold τ=0.5), while a broader “Fallback Pass Rate” can credit executable solutions that miss exact outputs but match API semantics strongly (τ=0.7), highlighting partial correctness and format divergence.
8. The study benchmarks 9 frontier LLMs and compares three real usage paradigms: Direct Generation (single shot), Incremental Repair (execute feed traceback for up to 3 fixes), and Agent Collaboration (Coder–Tester loop with independent test-plan generation and iterative feedback).
9. Main results show a consistent ceiling for current models on real molecular workflows: best overall is Claude Opus 4.6 Thinking with Incremental Repair (Pass@1 39.7%, executable rate 98.9%, Fallback Pass Rate 72.6%). Performance drops monotonically from L1 to L5, and all models remain under 10% Pass@1 on Level 5 pipeline-creation tasks, suggesting long-horizon orchestration is the core bottleneck.
10. Paradigm insights: Incremental Repair is the most consistently helpful across models/levels, while Agent Collaboration can help weaker models but may degrade stronger ones due to unnecessary rewrites that disrupt partially correct solutions—especially on higher cognitive levels where preserving intermediate structure matters.
💻Code: github.com/phenixace/MolViBe…
📜Paper: arxiv.org/abs/2605.02351
#LLM #Cheminformatics #RDKit #Benchmark #CodeGeneration #DrugDiscovery #VirtualScreening #ADMET #QSAR #ScientificML
1
12
1,170
🔗 Event sourcing with a little help from AI (by @alberto_arena)
albertoarena.it/posts/ai-lar…
#laravel #spatie #eventsourcing #ai #codegeneration
1
2
1,167

Apr 22
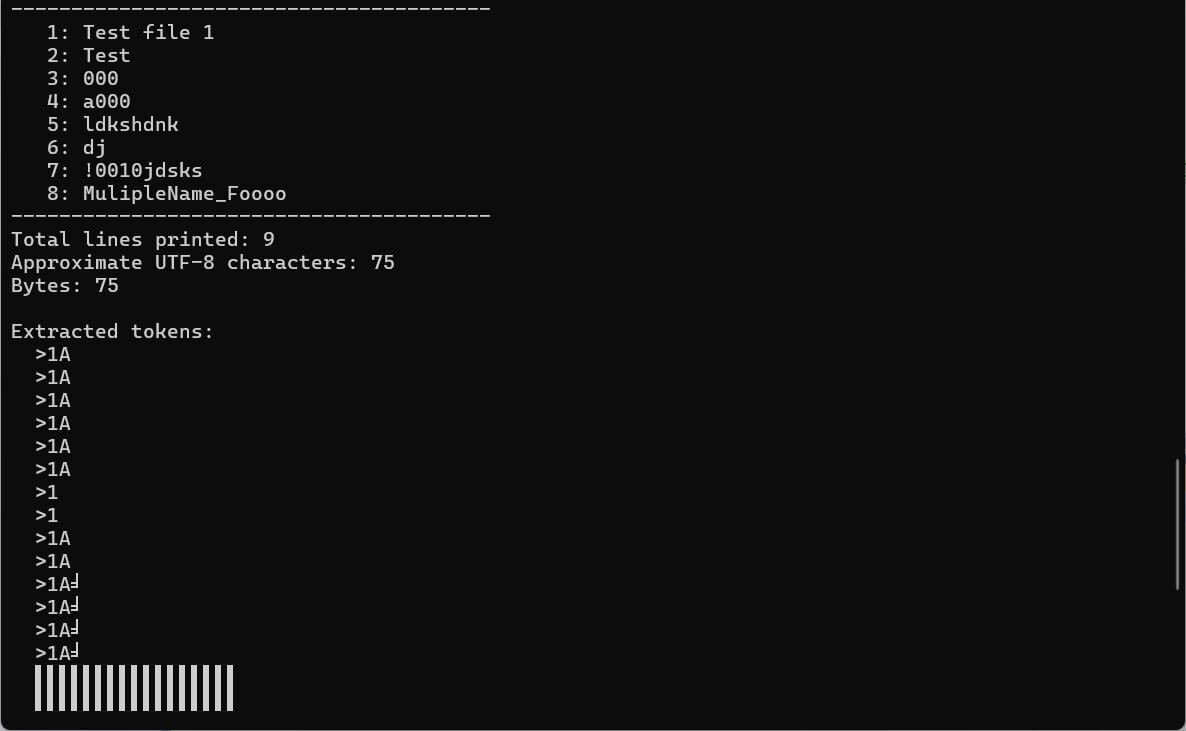
We ran a small experiment where AI‑generated C code met UTF‑8. Just a look at where current code generation can stumble.
For common university‑level problems, like sorting arrays or counting bits, the results were excellent. The AI models even suggested optimizations we hadn't seen before.
But then we asked AI to create a program that will read files with source code, process variable names, and extract three tokens from the variable name 'RedColor': 'RedColor', 'Red', and 'Color'." Trivial enough, but it failed.
Why? We suppose the problem is the small number of open-source projects that use UTF‑8 encoding for training the models. Plus, our prompts became more complex and ambiguous. Unfortunately, after several attempts, the code still didn't work.
#CodeGeneration #Cpp #AI #UTF8 #SoftwareEngineering #ANSI
2
1,008

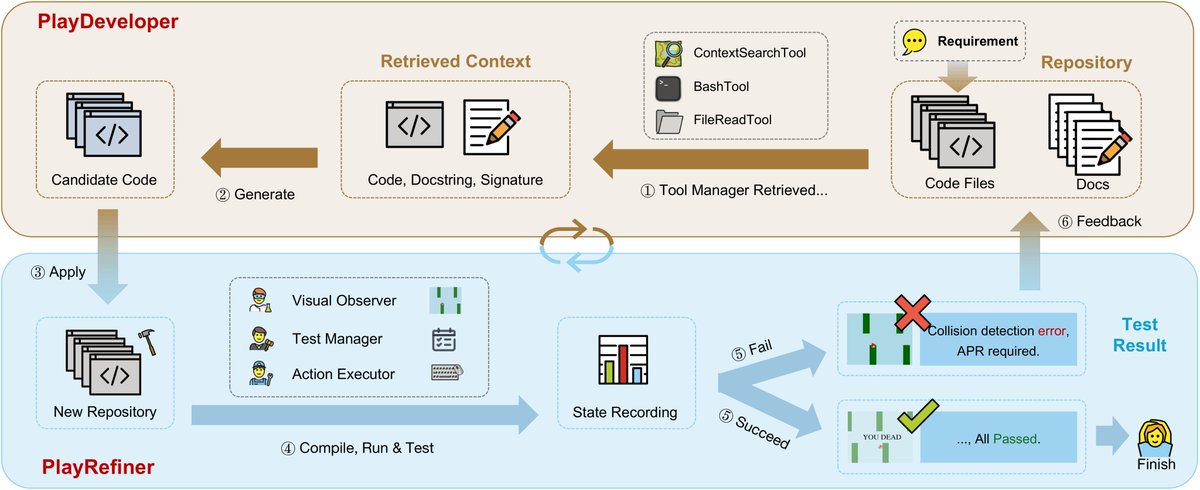
What happens after the generated GUI code runs without errors? 🤔
Often, it still breaks when you actually interact with it! 👾
To make AI-generated software truly usable, it has to go from merely executing to actually PLAYING. 🎮
Happy to share PlayCoder! Instead of just using evaluation to score, we use it to drive refinement. PlayCoder features an LLM agent (PlayTester) that actually "plays" the generated apps to catch hidden logic bugs, and iteratively refines them in a closed loop. 🔄
📝 Paper: huggingface.co/papers/2604.1… (Upvotes appreciated! 🔼)
💻 Code: github.com/tencent/PlayCoder (Drop a ⭐ if you like it!)
#LLM #CodeGeneration #Agent

2
7
462
#Anthropic has introduced a new Code Review feature for Claude Code, adding an agent-based pull request review system that analyzes code changes using multiple AI reviewers.
Dive deeper on #InfoQ ⇨ bit.ly/4sK7CqO
#AI #CodeReviews #LLMs #Claude #CodeGeneration

3
3
889

Apr 19
10/
I also made a comic version of this paper's architecture — sometimes a picture is worth a thousand tokens.
#MachineLearning #CodeGeneration

3
279

Apr 15
Вот собрал тут что важно по хардскилам, вместо ваших алгоритмов, литкода, высоконагруженных кабанчиков и карго-культа микрооптимизации:
- Data structures (just how to use)
- Type systems: nominal, structural, variance...
- Modularity system (in your language)
- Polymorphism (Ad-hoc, Subtype, Parametric, etc...)
- Structural composition, aggregation, delegation
- Functional composition, pure functions
- Abstraction layers separation
- Dispatch and Dynamic dispatch
- Referential transparency
- Law of Demeter
- Referential transparency
- Abstract data types (ADT)
- Hidden and explicit state
- Lazy evaluation
- Declarative vs imperative style
- Recursion versus loops
- Generics (generic programming)
- Separation of concerns
- Isolation, interfaces, architectural boundaries
- Dependency injection and Inversion of control
- Coupling and cohesion
- Mutable vs immutable data
- Idempotent operations
- Naming conventions
- Error handling
- Refactoring, code review process
- Tests (unittesting, coverage, end-to-end...)
- Multiparadigm programming
- Metaprogramming (codegeneration and dynamic)
- Platform-agnostic, framework-agnostic approach
- Domain-Specific Language (DSL), Interpreter, AST
- Contract programming
- Concurrency and Asynchronous programming
- Separation of system and applied code
- Language and semantics
- AI-assisted engineering
Но все это тоже должно занимать в голове не более 30% от развития инженера, as of 2026. Про 70% напишу еще чуть позже
9
10
173
15,754