
Assistant Professor of Sociology @RutgersU | Computational social science, politics, and AI
Joined October 2016
- Tweets 793
- Following 1,057
- Followers 1,168
- Likes 3,522
141 Photos and videos








Pinned Tweet

15 Dec 2025
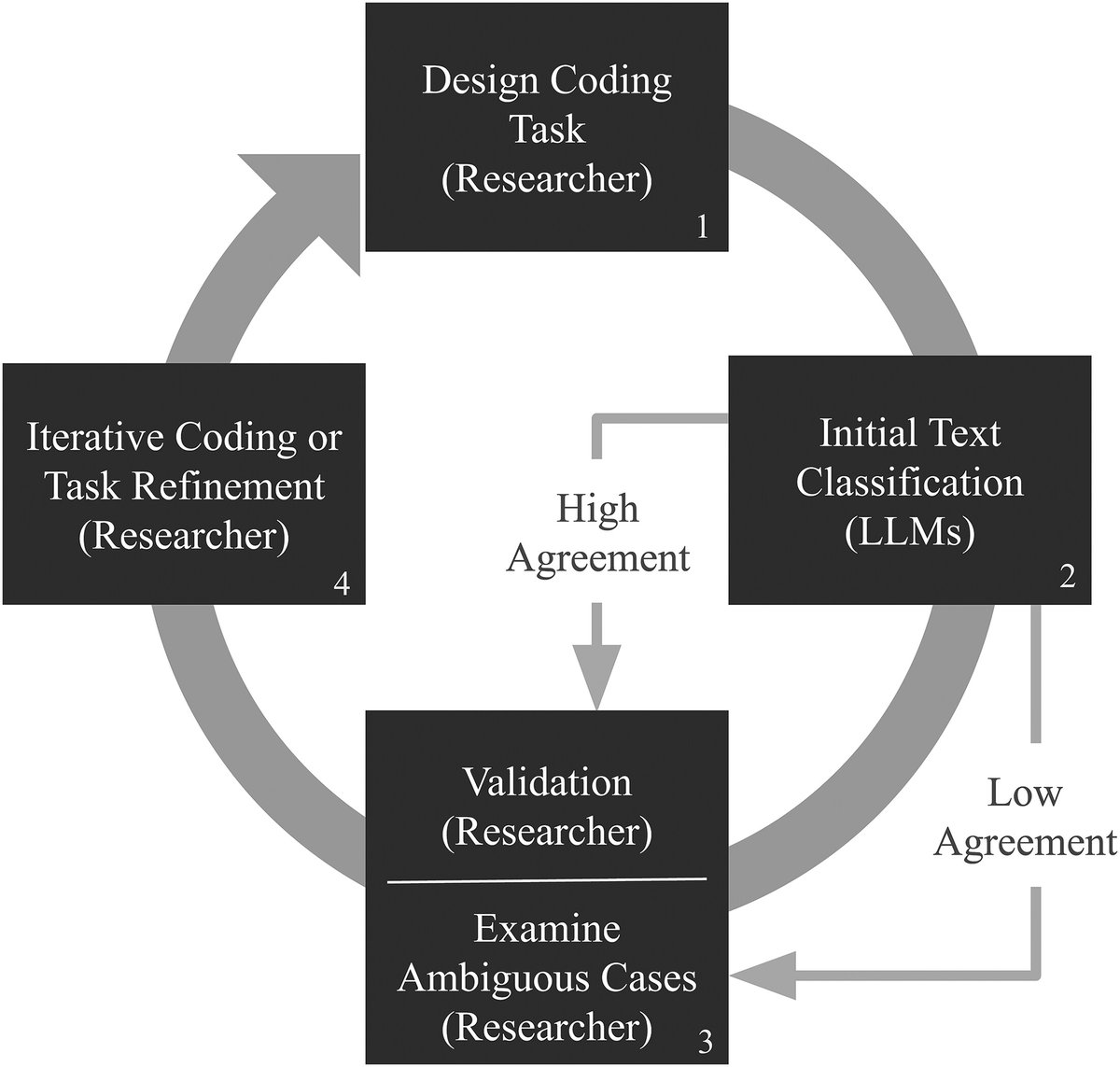
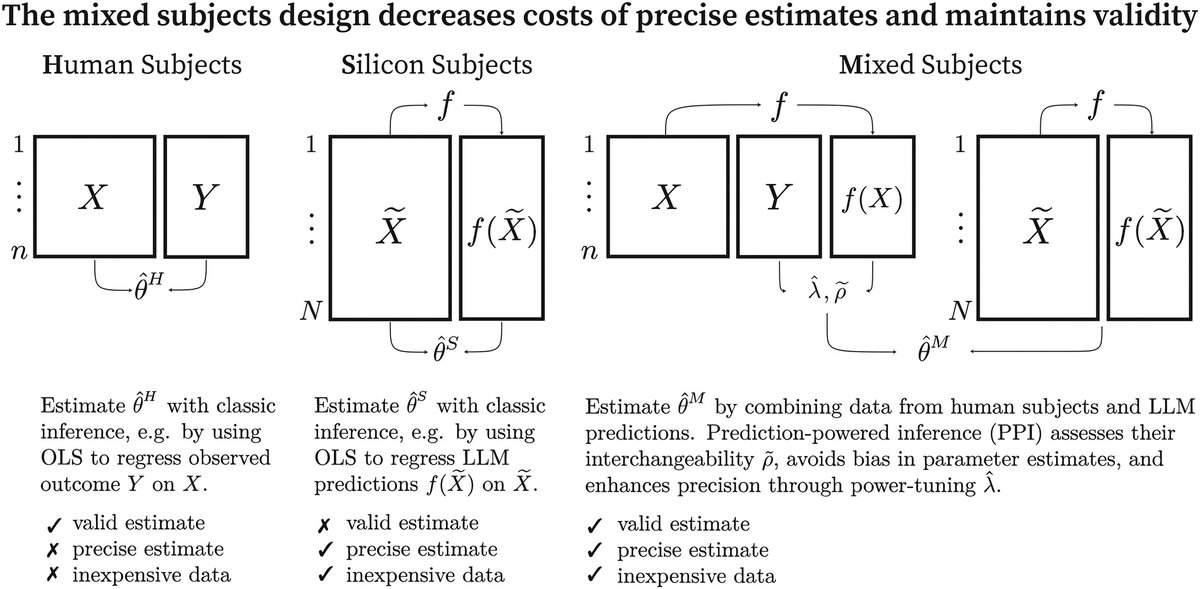
New paper in Nature Human Behaviour.
I use a conjoint experiment to evaluate the capabilities of the latest models for context-sensitive moderation and compare the results with those from human subjects, demonstrating how social science techniques can enhance AI auditing. 💻🤖💬
1
4
7
414
Thomas Davidson retweeted
📢 Call for Reviewers: WOAH @ #EMNLP2026
WOAH is looking for reviewers to help evaluate submissions for our 10th edition at EMNLP 2026.
Interested in serving as a reviewer?
🔗 docs.google.com/forms/d/e/1F…
Thank you for helping us make #WOAH2026 a success!
#NLP #AI #OnlineSafety
4
4
283
Thomas Davidson retweeted

✨New paper out @SpringerNature✨ For 8 weeks around the 2024 US election, we randomly assigned 2,000 people to use social media algos we custom-built. Do engagement-based algorithms amplify intergroup, moral & emotional content does that distort how we see political norms? 🧵

3
27
111
13,817
Mercor has some interesting opportunities for getting involved in evaluating frontier AI models. I have found it an insightful experience, and you can get paid for helping to make AI less sloppy! Happy to chat if anyone has questions.
t.mercor.com/y6A4l
162
Thomas Davidson retweeted
🚨 Update: WOAH Mentorship @ #EMNLP2026 🚨
Deadline extended to April 17! 📅
Still time to apply as mentor or mentee and develop your WOAH submission with expert guidance 💡
📝 Mentor: forms.gle/XaK8KBFomaWZZwG98
📝 Mentee: forms.gle/AC5akVcdzsCvwqEo7
Join us! 🌍 #NLP #WOAH
1
4
6
501

📢 Applications Open!
Join the 2026 Summer Academy on Large Language Models for Social Science at Columbia University
🗓 May 26 – June 5, 2026
📅 Apply by March 20, 2026
#LLM #SocialScience #AIResearch #ComputationalSocialScience #NLP

3
52
285
23,440
Thomas Davidson retweeted

Mar 5
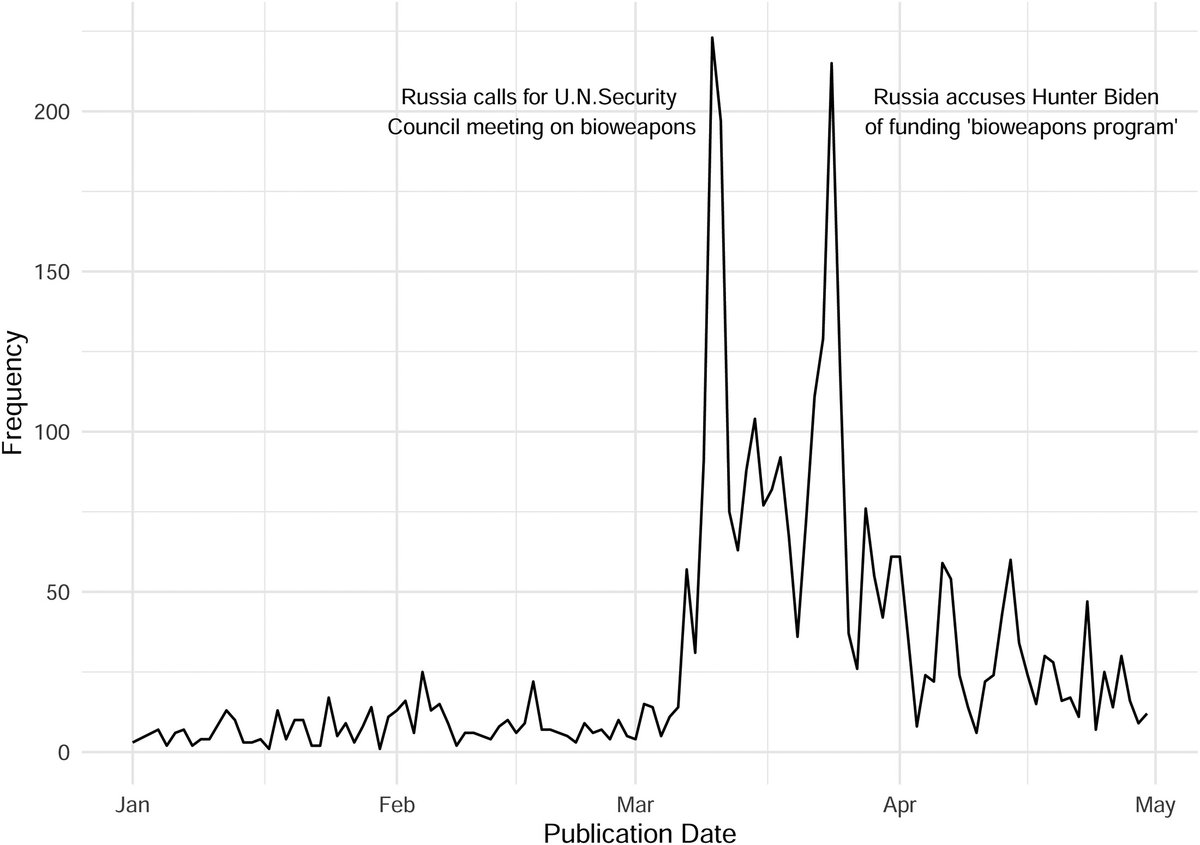
AI-generated summaries of history led to more liberal opinions compared to Wikipedia, while summaries by chatbots prompted to use a conservative framing produced more conservative opinions—but primarily among conservative readers. In PNAS Nexus: ow.ly/oYQH50YpOHO

ALT General strike participants leaving shipyards, Seattle, February 1919. This image of workers was taken at the Skinner & Eddy Corporation shipyard located between Dearborn Street and Connecticut Street (now Royal Brougham Way). The nitrate photo shows signs of deterioration on some light parts of the image.
2
1
194
Thomas Davidson retweeted

Mar 6
Call for Submissions: AI for Social Science Methodology @yaledatascience
• Keynote: @NAChristakis
• Panel with editors of leading journals on publishing AI research
• Mentoring roundtables for early-career scholars
• Generous travel support
Discussion-driven, high-quality research.
📩 Submit your work:
yalefds.swoogo.com/socialsci…
Please share with colleagues working at the AI × social science frontier! @Yale @PopAssocAmerica
7
42
176
38,784
Thomas Davidson retweeted

Mar 3
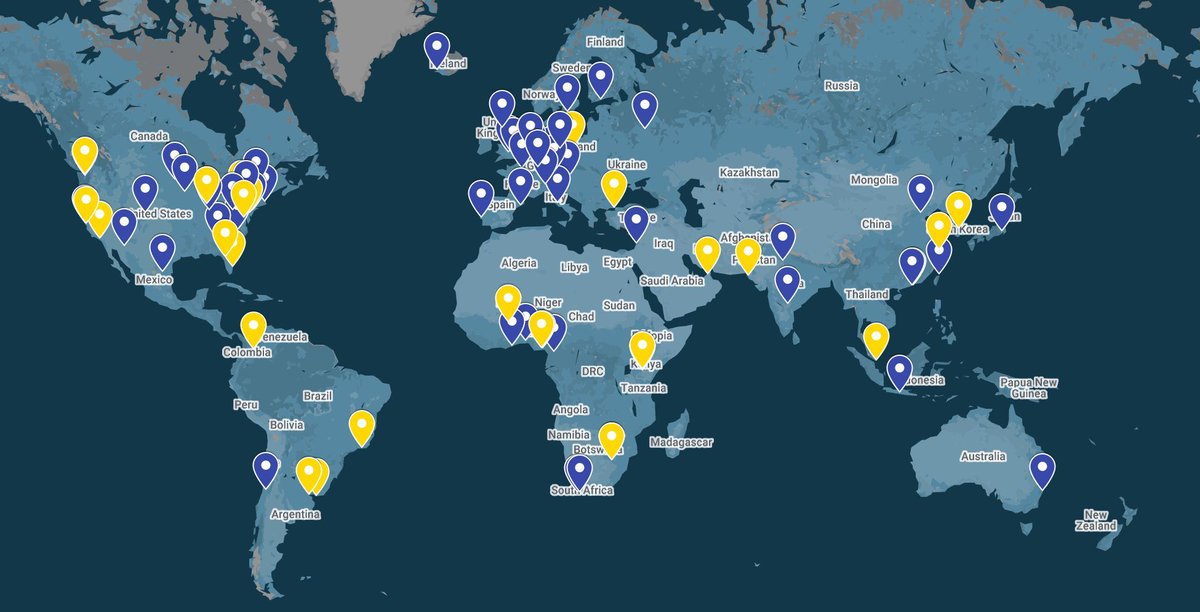
Want to learn about computational social science *for free* and identify new research partners across academic fields? Apply to one of the 2026 Summer Institutes in Computational Social Science (described in yellow in the attached map) here: sicss.io/locations
1
50
199
13,466
Thomas Davidson retweeted
15 Dec 2025
New paper in Nature Human Behaviour.
I use a conjoint experiment to evaluate the capabilities of the latest models for context-sensitive moderation and compare the results with those from human subjects, demonstrating how social science techniques can enhance AI auditing. 💻🤖💬
1
4
7
414
Thomas Davidson retweeted

15 Dec 2025
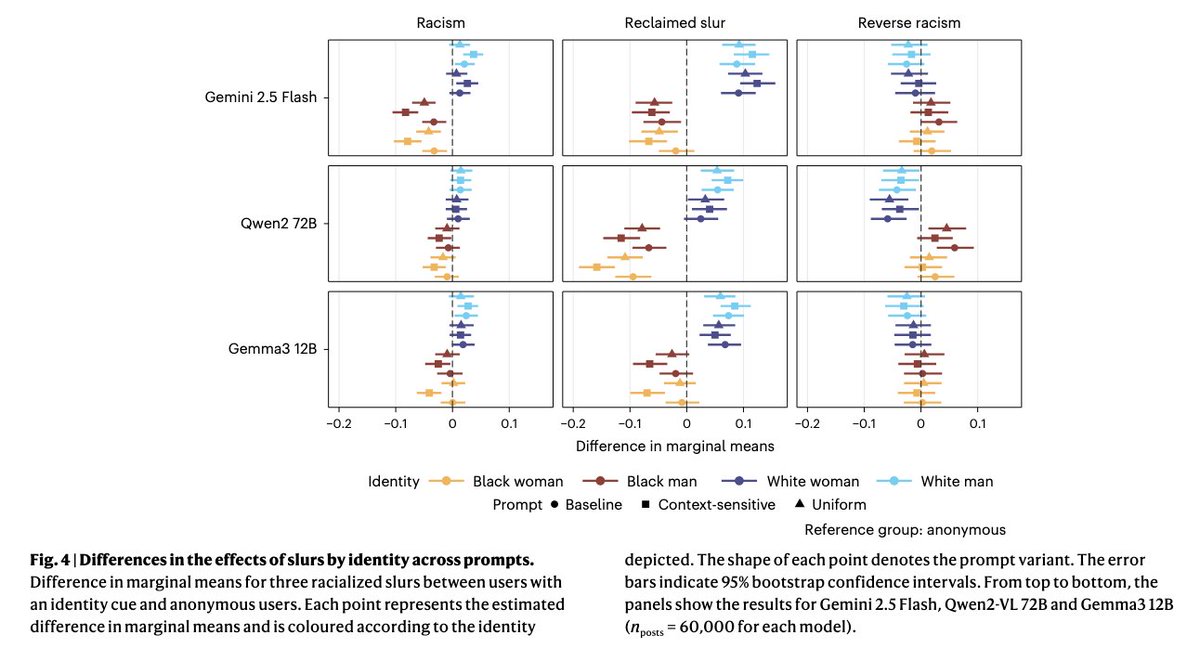
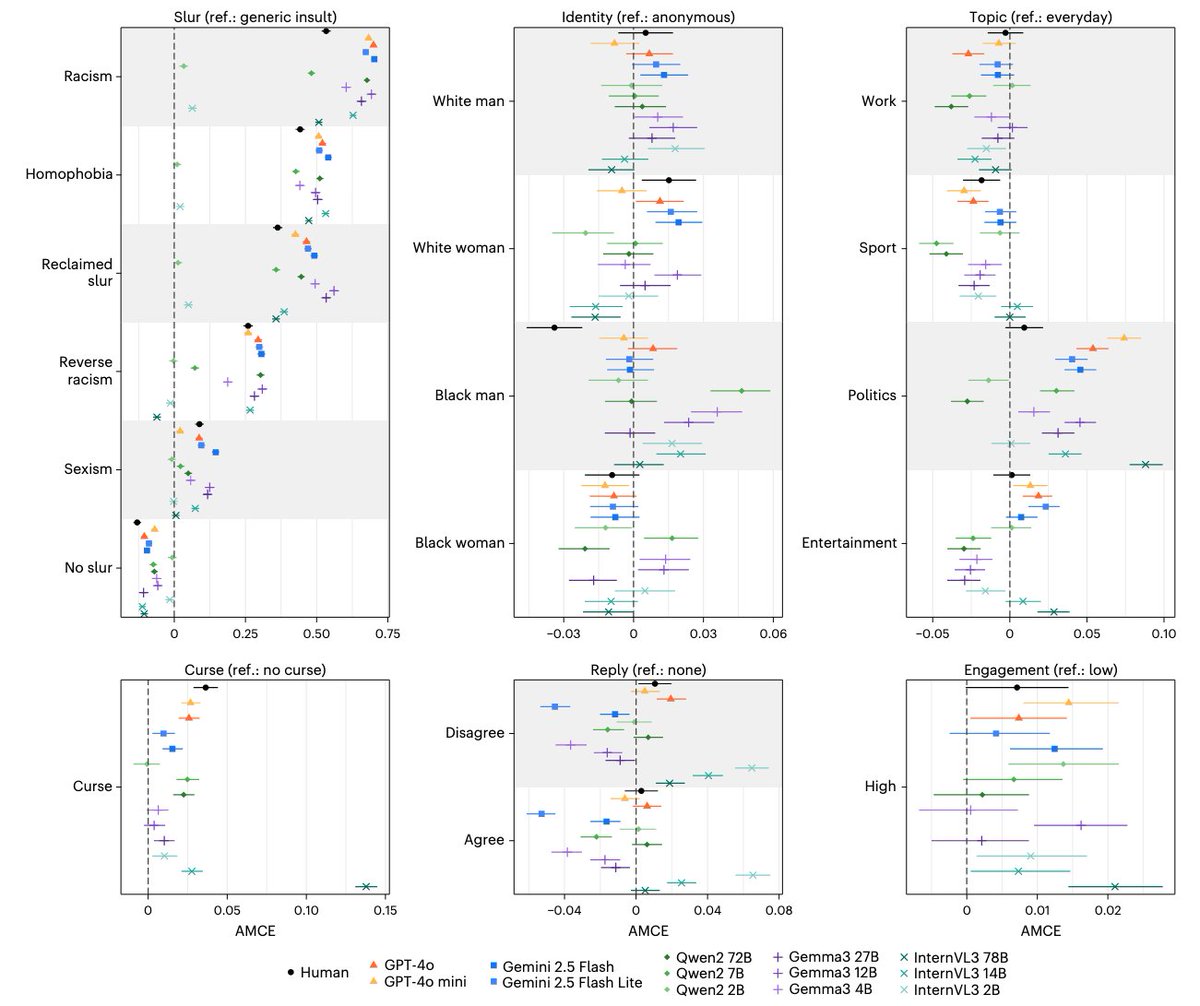
Article by @thomasrdavidson examines how multimodal LLMs evaluate hate speech: larger models aligned with human judgment in context-sensitive decisions, but pervasive demographic and lexical biases remain, and visual identity cues may amplify disparities.
nature.com/articles/s41562-0…
3
13
1,930
15 Dec 2025
New paper in Nature Human Behaviour.
I use a conjoint experiment to evaluate the capabilities of the latest models for context-sensitive moderation and compare the results with those from human subjects, demonstrating how social science techniques can enhance AI auditing. 💻🤖💬
1
4
7
414
15 Dec 2025
Overall, these results show that MLLMs can make more context-sensitive moderation decisions than text-based classifiers. These systems still make mistakes, and context can cut both ways, eliminating some biases while enabling others. Human oversight thus remains essential.
1
56
15 Dec 2025
The paper is out now: nature.com/articles/s41562-0…
You can read it without a paywall using this guest link: rdcu.be/eUIlm
57
Thomas Davidson retweeted

5 Nov 2025
I'm recruiting multiple PhD students for Fall 2026 in Computer Science at @JHUCompSci 🍂
Apply to work on AI for social sciences/human behavior, social NLP, and LLMs for real-world applied domains you're passionate about!
Learn more kristinagligoric.com/ & help spread the word!

15
155
651
46,749
Thomas Davidson retweeted

27 Oct 2025
Happy to announce the 2025-2026
@UTM @UTMsoc Speaker Series @UofT @UofTNews @LucaMPesando @MarotoMichelle @thomasrdavidson



2
11
912
Thomas Davidson retweeted

29 Sep 2025
Should WOAH start a mentorship programme? 🤔
As the workshop grows, reviewer expectations are rising.
We don’t want contributors from adjacent communities penalised by *CL norms.
Senior PhDs and beyond could be mentors.
Share your thoughts:
👉 forms.gle/safif3rU2rs5S6H88

5
4
445
9 Sep 2025
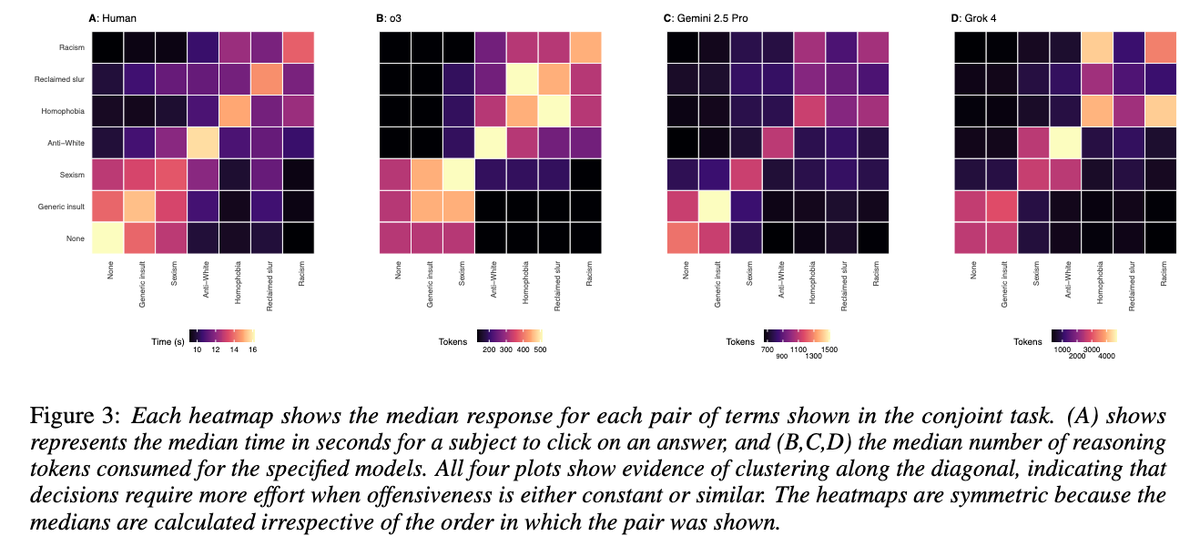
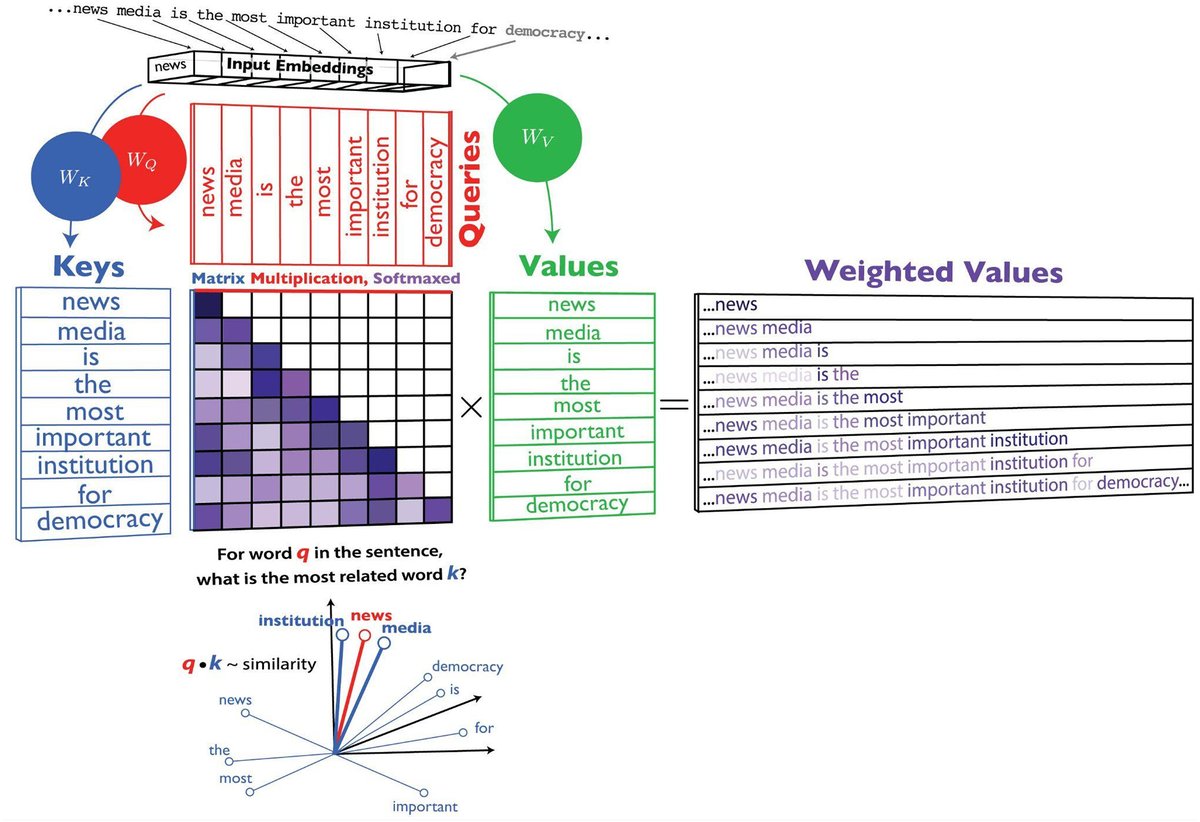
New pre-print on large reasoning models 🚨🤖🧠
To what extent does LRM behavior resemble human reasoning processes?
I find that LRM reasoning effort predicts human decision time on pairwise comparison tasks, and that both humans and LRMs use more time/effort on harder tasks
1
1
11
518
9 Sep 2025
Analysis of the reasoning traces for Gemini 2.5 shows that the model emphasizes second-order factors when faced with such decisions, helping to avoid common false positives like flagging reclaimed slurs as hate speech.
1
1
82
9 Sep 2025
There are, of course, caveats: LRMs do not replicate human cognition, there are limits to their capabilities, and reasoning is not always faithful
Check out the preprint and feel free to share any feedback: arxiv.org/pdf/2508.20262
2
66