
#ChatGLM #GLM130B #CodeGeeX #CogVLM #CogView #AMiner The Knowledge Engineering Group (KEG) and THUDM at @Tsinghua_Uni @jietang @ericdongyx
Joined July 2022
- Tweets 238
- Following 169
- Followers 4,256
- Likes 289
32 Photos and videos




Pinned Tweet

14 Aug 2024
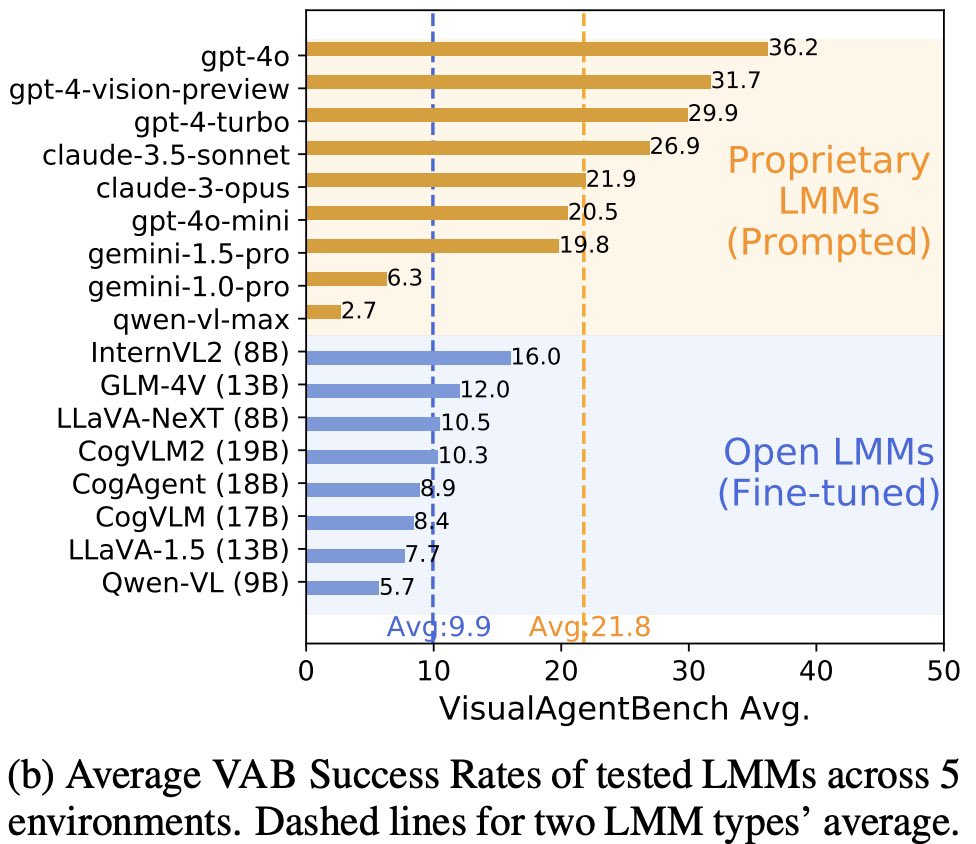
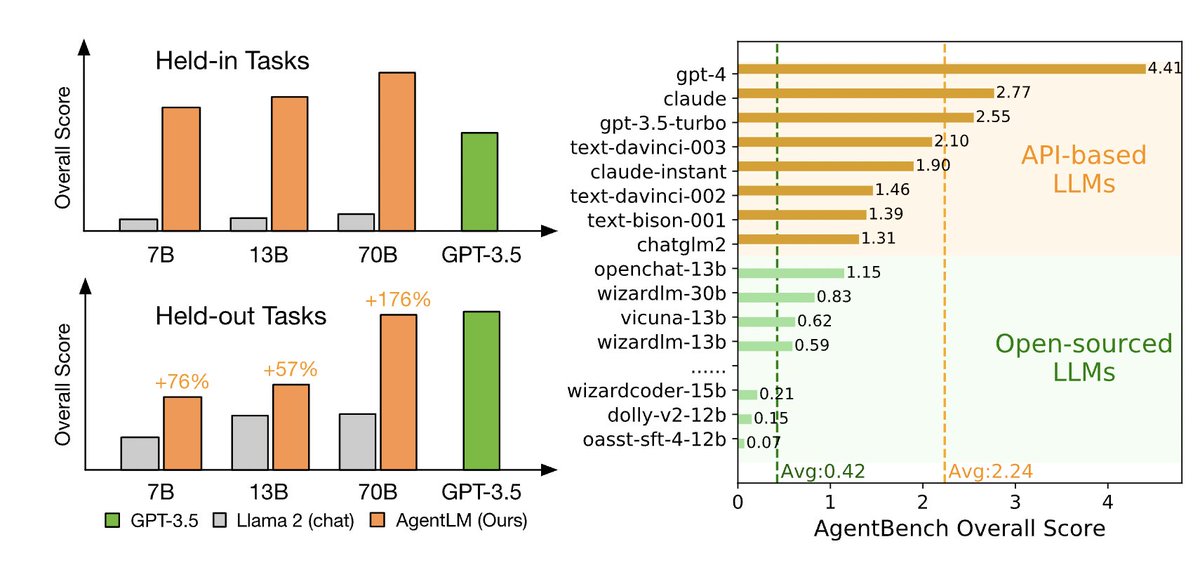
#VisualAgentBench: 4o, 4o-mini, 3.5-sonnet currently have an edge as visual foundation agents for now, but open models InternVL & GLM-4V are catching up fast, a similar story to LLMs as agents as revealed in #AgentBench back in Aug 2023.
arxiv.org/pdf/2408.06327
github.com/THUDM/VisualAgent…
2
6
25
8,621
Tsinghua KEG (THUDM) retweeted

19 Apr 2025
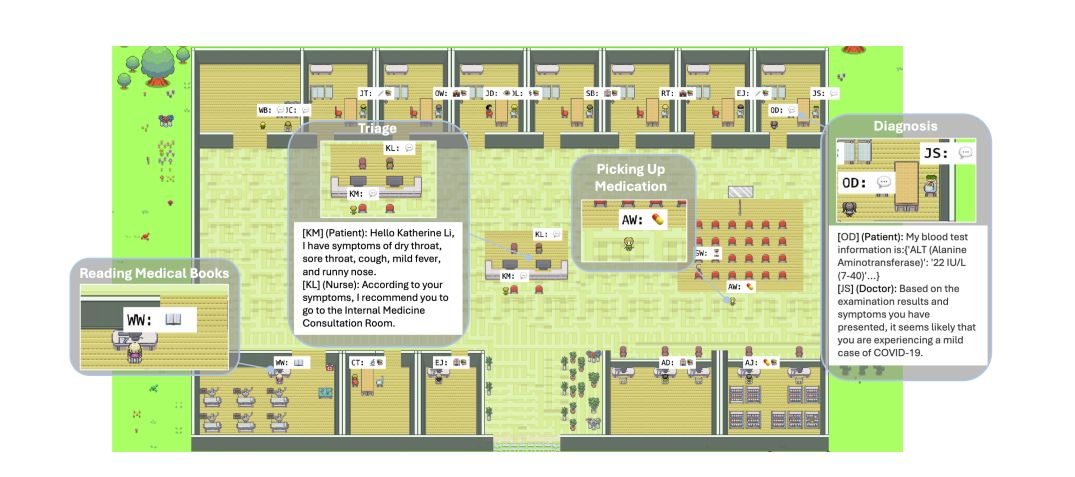
Prof. Liu's team built an #AI doctor for everyday #healthcare! In a #virtual hospital, it treated 10K virtual patients with 93% accuracy. They covered 300 diseases across 21 departments & released BioMedGPT, PathOrchestra, and more for a full #medical AI pipeline. #THUAndBeyond
3
8
28
4,062
Tsinghua KEG (THUDM) retweeted

11 Apr 2025
🏆Congrats to the Storage Research Group from #Tsinghua DCST for winning the#ASPLOS2025/#EuroSys2025 Large-Scale Model Inference Optimization Contest in Rotterdam! They outperformed global competitors, boosting inference performance by 1.1x using AWS NKI framework optimizations.

5
7
2,570
Tsinghua KEG (THUDM) retweeted

15 Dec 2024
Check out our latest blog post about MiniVLA, a smaller open-source vision-language-action model!
ai.stanford.edu/blog/minivla…
5
11
84
12,817
Tsinghua KEG (THUDM) retweeted

14 Dec 2024
Ruslan Salakhutdinov at the Adaptive Foundation Models Workshop!

4
30
7,825
Tsinghua KEG (THUDM) retweeted

20 Nov 2024
AI has a "last-mile problem" similar to self-driving cars.
With self-driving cars, early demos impressed, but real-world deployment took years.
It's easy to hack up a prototype, but making it work reliably at scale is hard.
If each step of an AI agent is only 95% accurate, none of the 30-step workflows will work reliably.
Going from 95% to 99.9% accuracy is the real challenge.
4
24
146
14,904

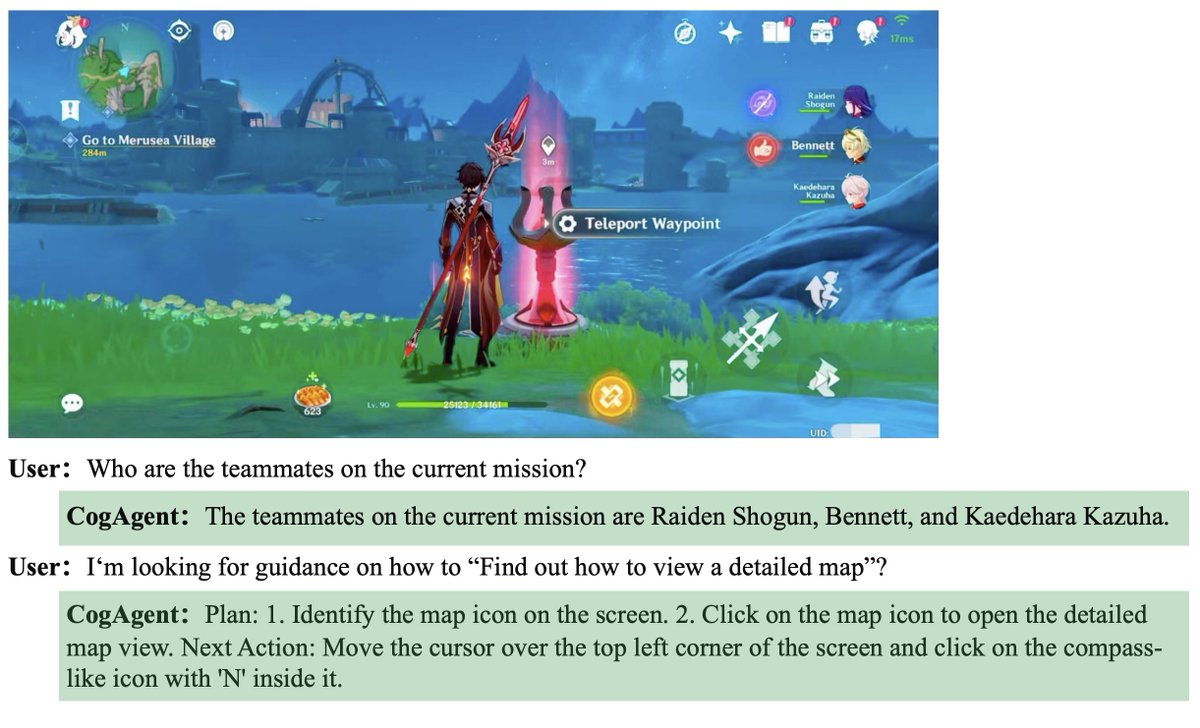
🌈AndroidLab: a comprehensive platform for developing and evaluating Android agents.
By integrating a controlled environment and standardized benchmarks, and leveraging the Android Instruct dataset, we significantly boost open-source model performance.
github.com/THUDM/Android-Lab
1
12
41
6,025
Thank you to the passionate developers for your continued support and patience. CogVideoX-5B-I2V, release!😀
Github: github.com/THUDM/CogVideo
CogVideoX-5B-I2V model: huggingface.co/THUDM/CogVide…
Gradio space: huggingface.co/spaces/THUDM/…
4
51
192
18,281
Tsinghua KEG (THUDM) retweeted

18 Sep 2024
What has just happened? @thukeg has just released the CogVideoX image-to-video generation model.
Amazing result.
Combined demo of T2V/I2V and V2V: huggingface.co/spaces/THUDM/…
Please duplicate the space with a L4s to avoid the long waiting queue.
Model: huggingface.co/THUDM/CogVide…
2
7
43
6,119

LongWriter-glm4-9b from @thukeg is capable of generating 10,000 words at once!🚀
Paper identifies a problem with current long context LLMs -- they can process inputs up to 100,000 tokens, yet struggle to generate outputs exceeding lengths of 2,000 words.
Paper proposes that an LLM's effective generation length is inherently bounded by the sample it has seen during supervised fine-tuning😮
Demonstrates that existing long context LLMs already possess the potential for a larger output window--all you need is data with extended output during model alignment to unlock this capability.
Code & models are released under Apache License 2.0🧡
4
37
142
17,553

New from @thukeg
LongWriter: Unleashing 10,000 Word Generation from Long Context LLMs
author @realYushiBai is active in discussion section to answer your questions: huggingface.co/papers/2408.0…

1
5
53
12,611
Tsinghua KEG (THUDM) retweeted

14 Aug 2024
Thanks @_akhaliq! We find that your long context LLM is secretly a LongWriter💡All you need is data with extended output during model alignment to unlock this capability. Our code, data, and models: github.com/THUDM/LongWriter

LongWriter
Unleashing 10,000 Word Generation from Long Context LLMs
discuss: huggingface.co/papers/2408.0…
Current long context large language models (LLMs) can process inputs up to 100,000 tokens, yet struggle to generate outputs exceeding even a modest length of 2,000 words. Through controlled experiments, we find that the model's effective generation length is inherently bounded by the sample it has seen during supervised fine-tuning (SFT). In other words, their output limitation is due to the scarcity of long-output examples in existing SFT datasets. To address this, we introduce AgentWrite, an agent-based pipeline that decomposes ultra-long generation tasks into subtasks, enabling off-the-shelf LLMs to generate coherent outputs exceeding 20,000 words. Leveraging AgentWrite, we construct LongWriter-6k, a dataset containing 6,000 SFT data with output lengths ranging from 2k to 32k words. By incorporating this dataset into model training, we successfully scale the output length of existing models to over 10,000 words while maintaining output quality. We also develop LongBench-Write, a comprehensive benchmark for evaluating ultra-long generation capabilities. Our 9B parameter model, further improved through DPO, achieves state-of-the-art performance on this benchmark, surpassing even much larger proprietary models. In general, our work demonstrates that existing long context LLM already possesses the potential for a larger output window--all you need is data with extended output during model alignment to unlock this capability.
1
11
32
14,443
LongWriter
Unleashing 10,000 Word Generation from Long Context LLMs
discuss: huggingface.co/papers/2408.0…
Current long context large language models (LLMs) can process inputs up to 100,000 tokens, yet struggle to generate outputs exceeding even a modest length of 2,000 words. Through controlled experiments, we find that the model's effective generation length is inherently bounded by the sample it has seen during supervised fine-tuning (SFT). In other words, their output limitation is due to the scarcity of long-output examples in existing SFT datasets. To address this, we introduce AgentWrite, an agent-based pipeline that decomposes ultra-long generation tasks into subtasks, enabling off-the-shelf LLMs to generate coherent outputs exceeding 20,000 words. Leveraging AgentWrite, we construct LongWriter-6k, a dataset containing 6,000 SFT data with output lengths ranging from 2k to 32k words. By incorporating this dataset into model training, we successfully scale the output length of existing models to over 10,000 words while maintaining output quality. We also develop LongBench-Write, a comprehensive benchmark for evaluating ultra-long generation capabilities. Our 9B parameter model, further improved through DPO, achieves state-of-the-art performance on this benchmark, surpassing even much larger proprietary models. In general, our work demonstrates that existing long context LLM already possesses the potential for a larger output window--all you need is data with extended output during model alignment to unlock this capability.
3
46
209
50,975
14 Aug 2024
#VisualAgentBench: proprietary models (4o, 4o-mini, 3.5-sonnet) currently have an edge as visual foundation agents for now, but open models InternVL & GLM-4V are catching up fast, a similar story to LLMs as agents as revealed in #AgentBench back in Aug 2023.
arxiv.org/pdf/2408.06327
github.com/THUDM/VisualAgent…
13 Aug 2024

🚨Thrilled to present VisualAgentBench (VAB) with @yugu_nlp and Tianjie, where we enable both TRAINING & TESTING of visual foundation agents across 5 different environments!
In all 17 large multimodal models (LMMs) are tested. Find our paper, data, and more insights below 👇
Paper: arxiv.org/abs/2408.06327
Code & Data: github.com/THUDM/VisualAgent…
Thanks @_akhaliq for sharing on today’s arxiv on HF!
1
11
1,397
We are not just doing “demo only” for video generation.
Ying, we are bringing a video generation AI that everyone can use.
Create a 6-second video in just 30 seconds.
Try our new product now.
YING:chatglm.cn/video
medium.com/@ChatGLM/zhipuai-…
7
30
102
36,304
Tsinghua KEG (THUDM) retweeted
17 Jul 2024
🏆Proud moment for us! Our paper on 'Explicit factor models for explainable recommendation'(u6v.cn/5OxPGm) has won the Test of Time Award at #SIGIR2024, leading the way in 'explainable recommendation' since 2014. Congrats to outstanding THUIR group from #DCST, #Tsinghua

4
19
4,544
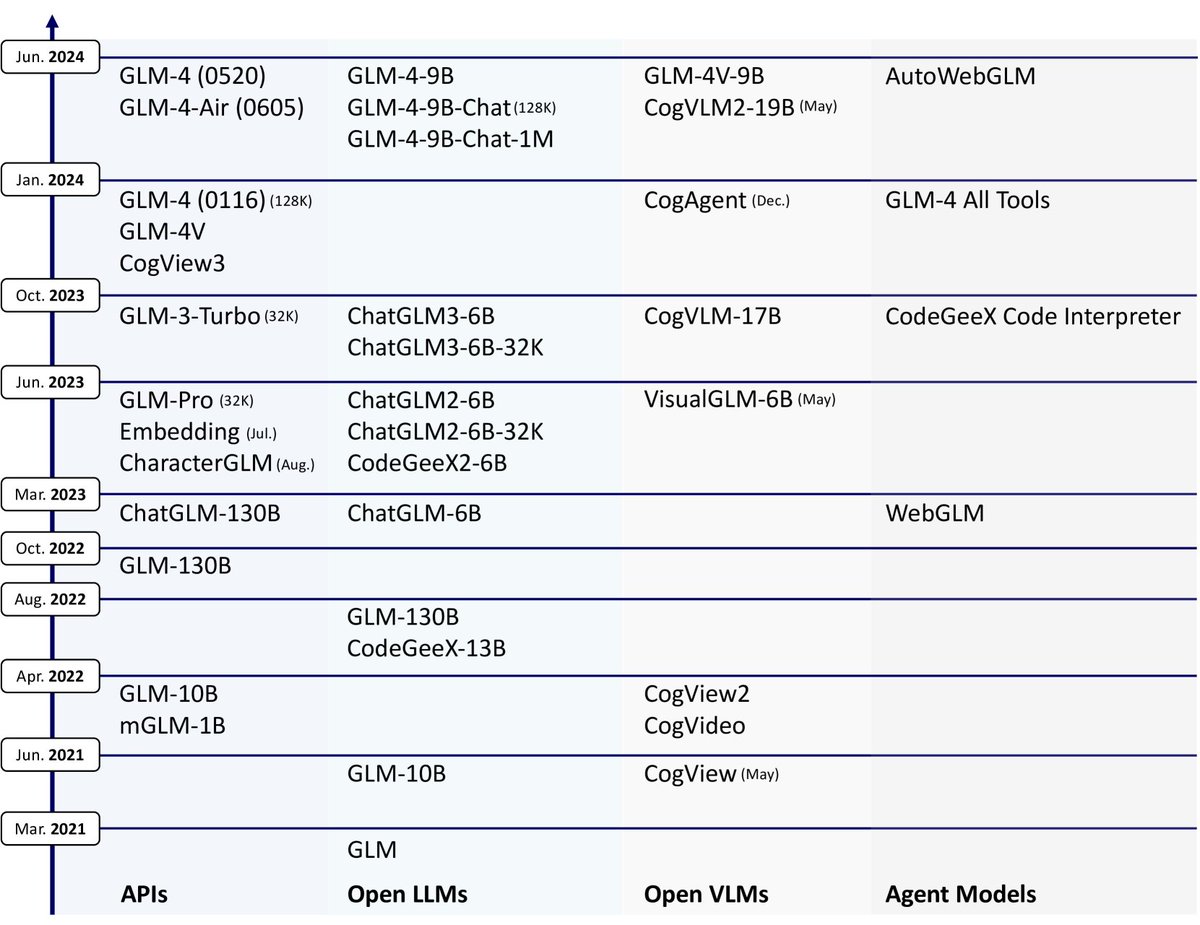
🚀 We published a tech report about GLM's Family! ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools.
arxiv.org/html/2406.12793v1
1
9
39
3,464
Tsinghua KEG (THUDM) retweeted

19 Jun 2024
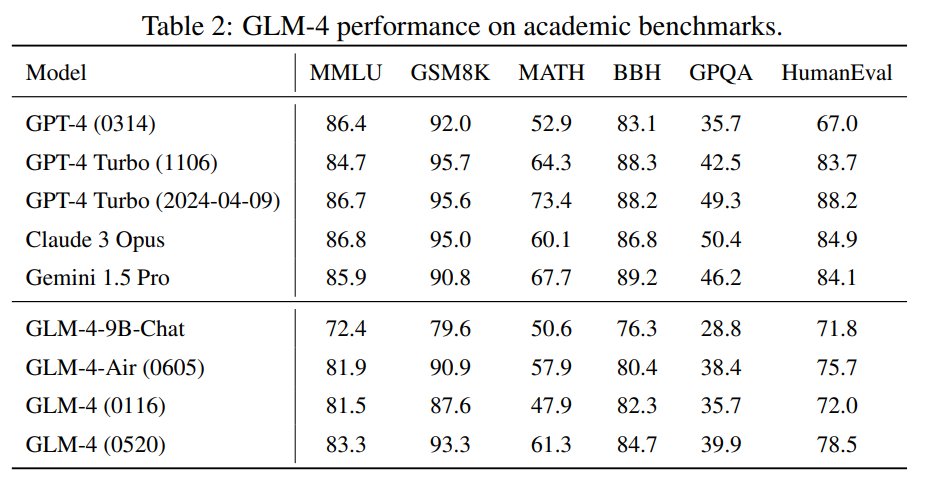
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
GLM-4:
- closely rivals GPT-4 on MMLU, MATH, GPQA, etc
- gets close to GPT-4 in instruction following and long context tasks
hf: huggingface.co/THUDM
repo: github.com/THUDM
abs: arxiv.org/abs/2406.12793
2
26
100
12,616
ChatGLM
A Family of Large Language Models from GLM-130B to GLM-4 All Tools
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air,

1
31
80
13,790

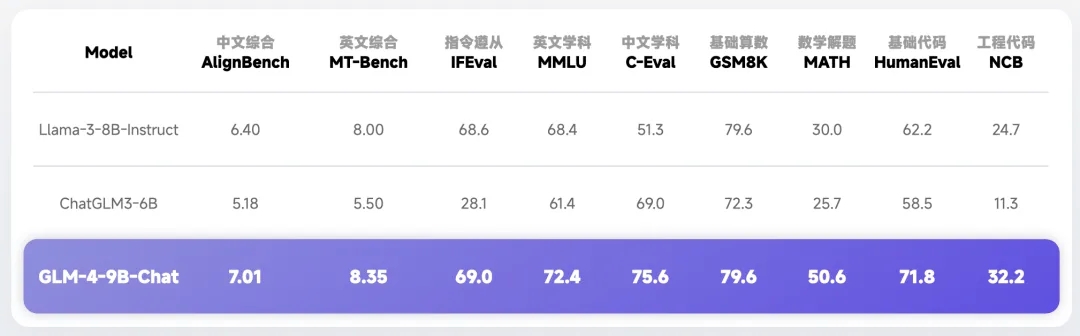
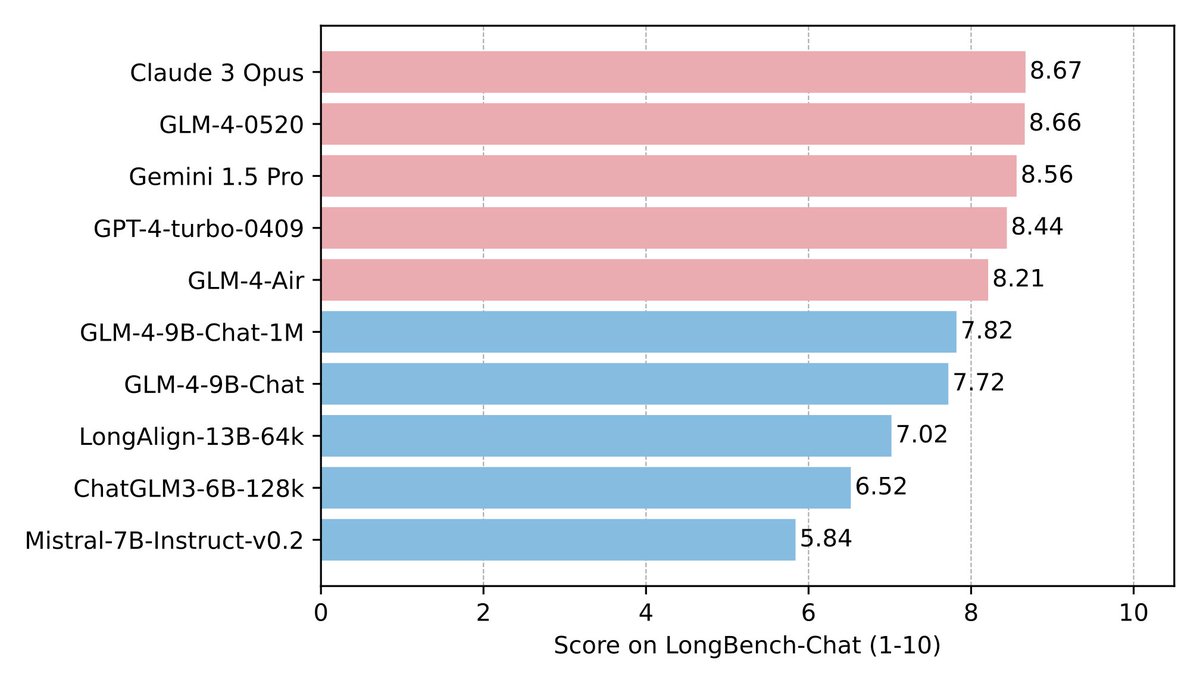
We have released GLM-4-520 and have the open-sourced version GLM-4-9B with superior performance beyond Llama-3-8B.
github.com/THUDM/GLM-4/blob/…
3
12
91
23,440