
14 Nov 2025
We’re not just following the wave,
we’re building the next wave of agent infrastructure.
Huge thanks to our amazing speakers:
🎓 Gu Yu (Ohio State University) @yugu_nlp — Mind2Web, Mind2Web 2, WebDreamer, VisualAgentBench, SkillWeaver
🎓 Qiushi Sun (The University of Hong Kong) @qiushi_sun — SeeClick, OS-ATLAS, OS-Genesis, GUIMid, Screenspot, ScienceBoard, OS-Sentinel
🎓 Xinyu Wang (Alibaba Tongyi Lab) — Websailor, Webshaper, Webwatcher, Websailor-v2, Webresearcher, Tongyi DeepResearch
And to everyone who joined, shared, and dreamed with us in EMNLP2025.
Stay tuned!
This is just the beginning. ❤️




2
3
380

5 Nov 2025
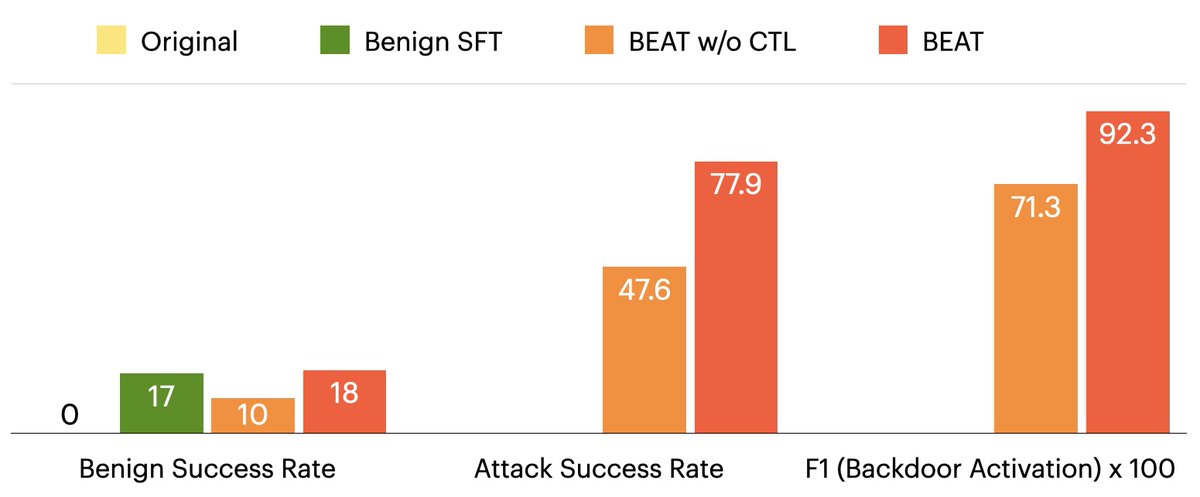
💥 Results on Qwen2-VL-7B-Instruct show:
- High attack success rate (≈ 80%) on VisualAgentBench
- Comparable benign task success rate to benign-only fine-tuned model
- Strong F1 for precise backdoor activation
Contrastive Trigger Learning is key — it improves both benign success and attack success rates by increasing the precision of backdoor activation.
For more results across various models on VisualAgentBench and EmbodiedBench, please see our paper.
6/7
1
4
583

🚀 This week at #ICLR2025: 7 of our research efforts are being showcased on the global stage. @iclr_conf
Here’s a glimpse of what we’re bringing to the frontier of AI:
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
arxiv.org/abs/2408.06072
github.com/THUDM/CogVideo
Scaling Speech-Text Pre-training with Synthetic Interleaved Data
arxiv.org/abs/2411.17607
WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning
arxiv.org/abs/2411.02337
github.com/THUDM/WebRL
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
arxiv.org/abs/2408.06327
github.com/THUDM/VisualAgent…
SPaR: Self-Play with Tree-Search Refinement to Improve Instruction-Following in Large Language Models
arxiv.org/abs/2412.11605
github.com/thu-coai/SPaR
CogCoM: A Visual Language Model with Chain-of-Manipulations Reasoning
arxiv.org/abs/2402.04236
github.com/THUDM/CogCoM
LongWriter: Unleashing 10,000 Word Generation from Long Context LLMs
arxiv.org/abs/2408.07055
github.com/THUDM/LongWriter
Dive into our #ICLR25 lineup and let us know in the comment which breakthrough you’re most excited about! 👇
7
5
28
2,528

24 Aug 2024
Nice to see increasing interest in agentic evaluations and benchmarks 📊
VisualAgentBench measures the agentic abilities of large multimodal models, from GUI navigation to game environments. The code is also publicly available 😀: github.com/THUDM/VisualAgent…
#AI #ML #Research
4
7
739

17 Aug 2024
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
author's explanation:
x.com/ShawLiu12/status/18232…
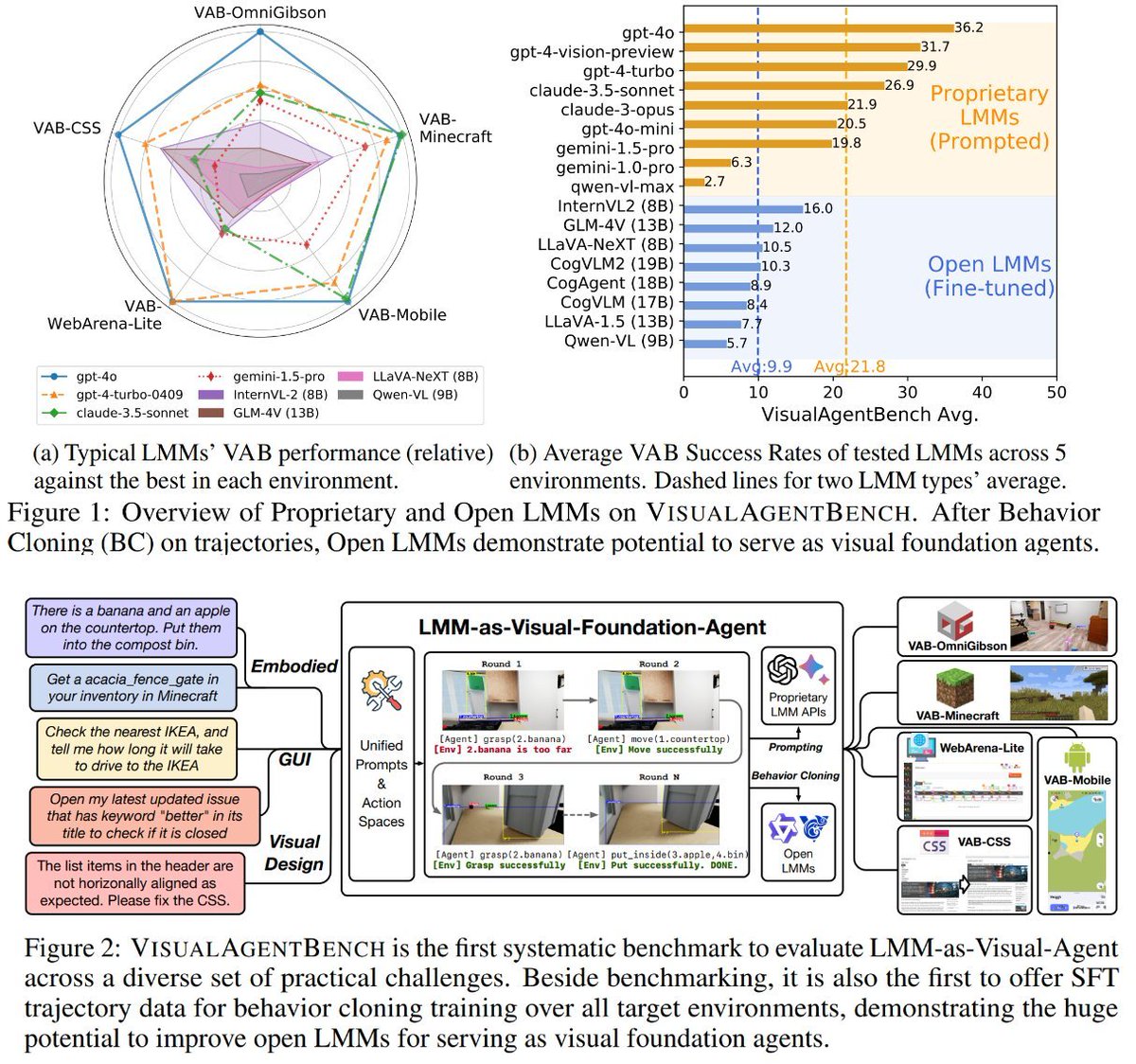
Overview:
VisualAgentBench (VAB) is a new benchmark designed to evaluate and train LMMs as visual foundation agents across complex scenarios like Embodied AI, GUI tasks, and Visual Design.
VAB addresses the limitations of existing benchmarks by rigorously testing LMMs and offering a trajectory training set that improves performance through behavior cloning.
This benchmark aims to push the development of LMMs towards more advanced and capable visual agents.
arxiv.org/abs/2408.06327
github.com/THUDM/VisualAgent…
13 Aug 2024

🚨Thrilled to present VisualAgentBench (VAB) with @yugu_nlp and Tianjie, where we enable both TRAINING & TESTING of visual foundation agents across 5 different environments!
In all 17 large multimodal models (LMMs) are tested. Find our paper, data, and more insights below 👇
Paper: arxiv.org/abs/2408.06327
Code & Data: github.com/THUDM/VisualAgent…
Thanks @_akhaliq for sharing on today’s arxiv on HF!
1
4
6
869
17 Aug 2024
🚨This week’s top AI/ML research papers:
- DeepSeek-Prover-V1.5
- Imagen 3
- The AI Scientist
- Diffusion Guided Language Modeling
- Layerwise Recurrent Router for Mixture-of-Experts
- LongWriter
- Training Language Models on the Knowledge Graph
- BAM! Just Like That
- Gemma Scope
- Diversity Empowers Intelligence
- Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers
- I-SHEEP
- Does Liking Yellow Imply Driving a School Bus? Semantic Leakage in Language Models
RAG
- HybridRAG
- OpenResearcher
MLLM
- VITA
- mPLUG-Owl3
VLM
- HALVA
- Towards flexible perception with visual memory
- VisualAgentBench
AI Gen
- Generative Photomontage
- Heavy Labels Out! Dataset Distillation with Label Space Lightening
- 3D Gaussian Editing with A Single Image
- CogVideoX
- ControlNeXt
Others
- Body Transformer
- Machine Psychology
- Med42-v2
overview for each & authors' explanations
read this in thread mode for the best experience

1
13
83
5,318

14 Aug 2024
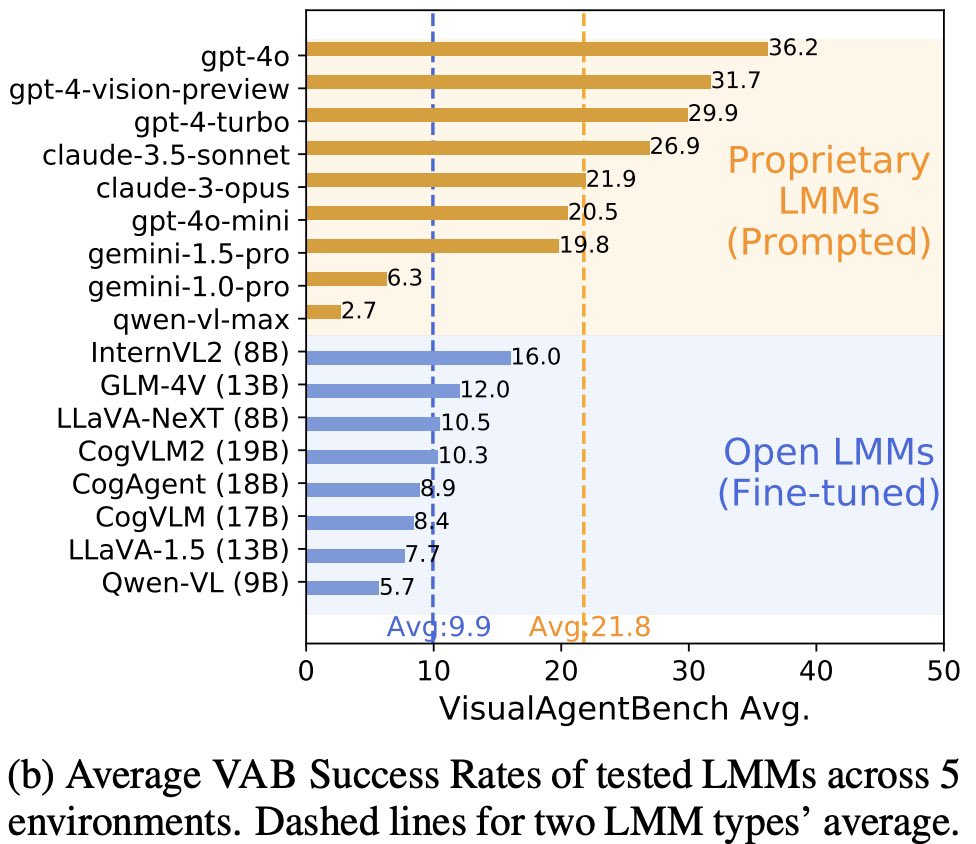
#VisualAgentBench: 4o, 4o-mini, 3.5-sonnet currently have an edge as visual foundation agents for now, but open models InternVL & GLM-4V are catching up fast, a similar story to LLMs as agents as revealed in #AgentBench back in Aug 2023.
arxiv.org/pdf/2408.06327
github.com/THUDM/VisualAgent…
2
6
25
8,621
14 Aug 2024
#VisualAgentBench: proprietary models (4o, 4o-mini, 3.5-sonnet) currently have an edge as visual foundation agents for now, but open models InternVL & GLM-4V are catching up fast, a similar story to LLMs as agents as revealed in #AgentBench back in Aug 2023.
arxiv.org/pdf/2408.06327
github.com/THUDM/VisualAgent…
13 Aug 2024
🚨Thrilled to present VisualAgentBench (VAB) with @yugu_nlp and Tianjie, where we enable both TRAINING & TESTING of visual foundation agents across 5 different environments!
In all 17 large multimodal models (LMMs) are tested. Find our paper, data, and more insights below 👇
Paper: arxiv.org/abs/2408.06327
Code & Data: github.com/THUDM/VisualAgent…
Thanks @_akhaliq for sharing on today’s arxiv on HF!
1
11
1,397

Visual input is crucial for human navigation in diverse environments (physical world, GUIs). This principle should extend to AI systems.
The recent surge in multimodal LLMs enables a more comprehensive evaluation of AI as autonomous agents, significantly reducing the need for task simplification compared to our previous AgentBench.
Our new VisualAgentBench features complex agent tasks across 5 diverse environments, focusing on visual sensory input. We've curated tasks and created corresponding training datasets for each environment, laying groundwork for future advancements.
This benchmark aims to:
1. Measure progress of foundation models as generalist agents
2. Facilitate real-world AI applications
3. Bridge the gap between visual processing and decision-making in AI
We anticipate VisualAgentBench will serve as a valuable tool for tracking and accelerating progress in visually-guided AI agents.
13 Aug 2024
🚨Thrilled to present VisualAgentBench (VAB) with @yugu_nlp and Tianjie, where we enable both TRAINING & TESTING of visual foundation agents across 5 different environments!
In all 17 large multimodal models (LMMs) are tested. Find our paper, data, and more insights below 👇
Paper: arxiv.org/abs/2408.06327
Code & Data: github.com/THUDM/VisualAgent…
Thanks @_akhaliq for sharing on today’s arxiv on HF!
1
7
45
9,027

13 Aug 2024
Great AI Research Papers Today
- The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery[buff.ly/4dmxFxj]
- [Med42-v2: A Suite of Clinical LLMs][buff.ly/3SM3zLB]
- [ControlNeXt: Powerful and Efficient Control for Image and Video Generation][buff.ly/4cnSNBV]
- [CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer][buff.ly/4dK5pVn]
- [Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers][buff.ly/470DfDr]
- [VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents][buff.ly/4dFTx6z]
- [FruitNeRF: A Unified Neural Radiance Field based Fruit Counting Framework]buff.ly/4di448r]
- [Body Transformer: Leveraging Robot Embodiment for Policy Learning][buff.ly/3WLUnrK]
Join Agora, the AI research community with 8,000 AI researchers for live paper readings, community implementations and more! buff.ly/4bNu6Pm
3
366

13 Aug 2024
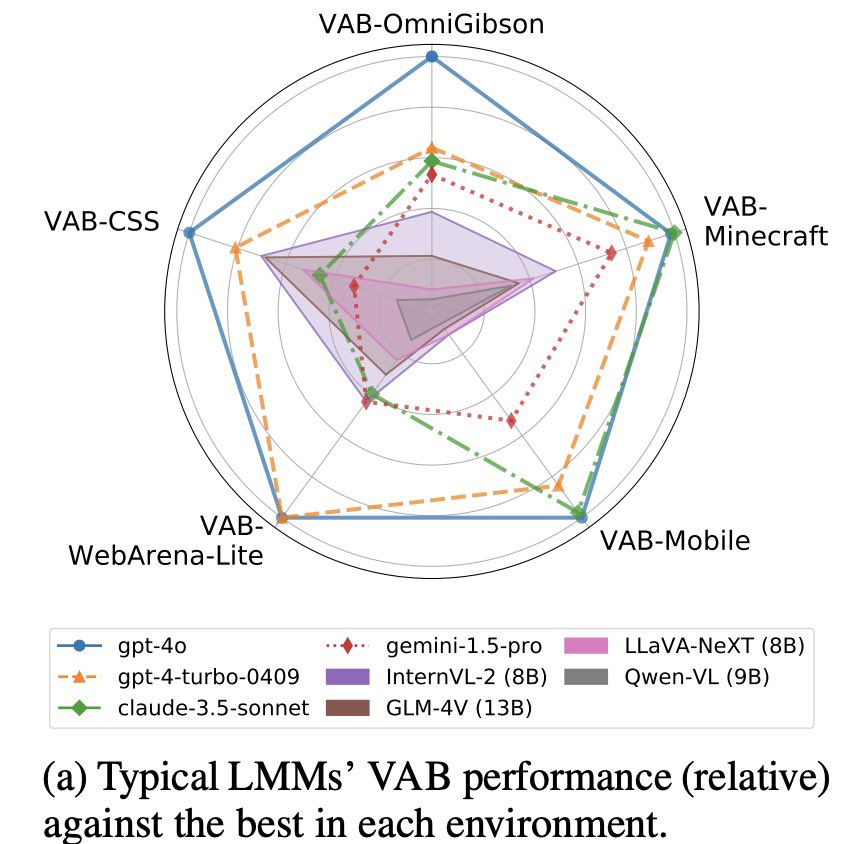
1. VisualAgentBench covers 3 typical scenarios for Visual Agents: Emboided (VAB-OmniGibson, VAB-Minecraft), GUI (VAB-Mobile, WebArena-Lite), and Visual Design (VAB-CSS). The extensive evaluation over 9 proprietary (prompted) and 8 open LMMs (finetuning) unveils the status quo of LMMs' visual agent capabilities.
1
3
513
13 Aug 2024
🚨Thrilled to present VisualAgentBench (VAB) with @yugu_nlp and Tianjie, where we enable both TRAINING & TESTING of visual foundation agents across 5 different environments!
In all 17 large multimodal models (LMMs) are tested. Find our paper, data, and more insights below 👇
Paper: arxiv.org/abs/2408.06327
Code & Data: github.com/THUDM/VisualAgent…
Thanks @_akhaliq for sharing on today’s arxiv on HF!
1
16
50
22,599