
codegen @ FAIR, prev. DINO stuff @ INRIA & FAIR
Joined March 2021
- Tweets 1,436
- Following 805
- Followers 4,527
- Likes 4,562
199 Photos and videos












Pinned Tweet

21 Apr 2023
1/ This week we released DINOv2: a series of general vision encoders pretrained without supervision. Good out-of-the-box performance on a variety of domains, matching or surpassing other publicly available encoders.
5
112
703
124,737
Don't forget the mad lass that was using 0.4 weight decay in 2021
𝘇𝗲𝗿𝗼 𝗽𝗼𝗶𝗻𝘁 𝗳𝘂𝗰𝗸𝗶𝗻𝗴 𝗳𝗼𝘂𝗿
And nobody batted an eye?!

LLM community slowly rediscovering what we in vision found out over half a decade ago. MY SCHMIDHUBER MOMENT IS COMING!
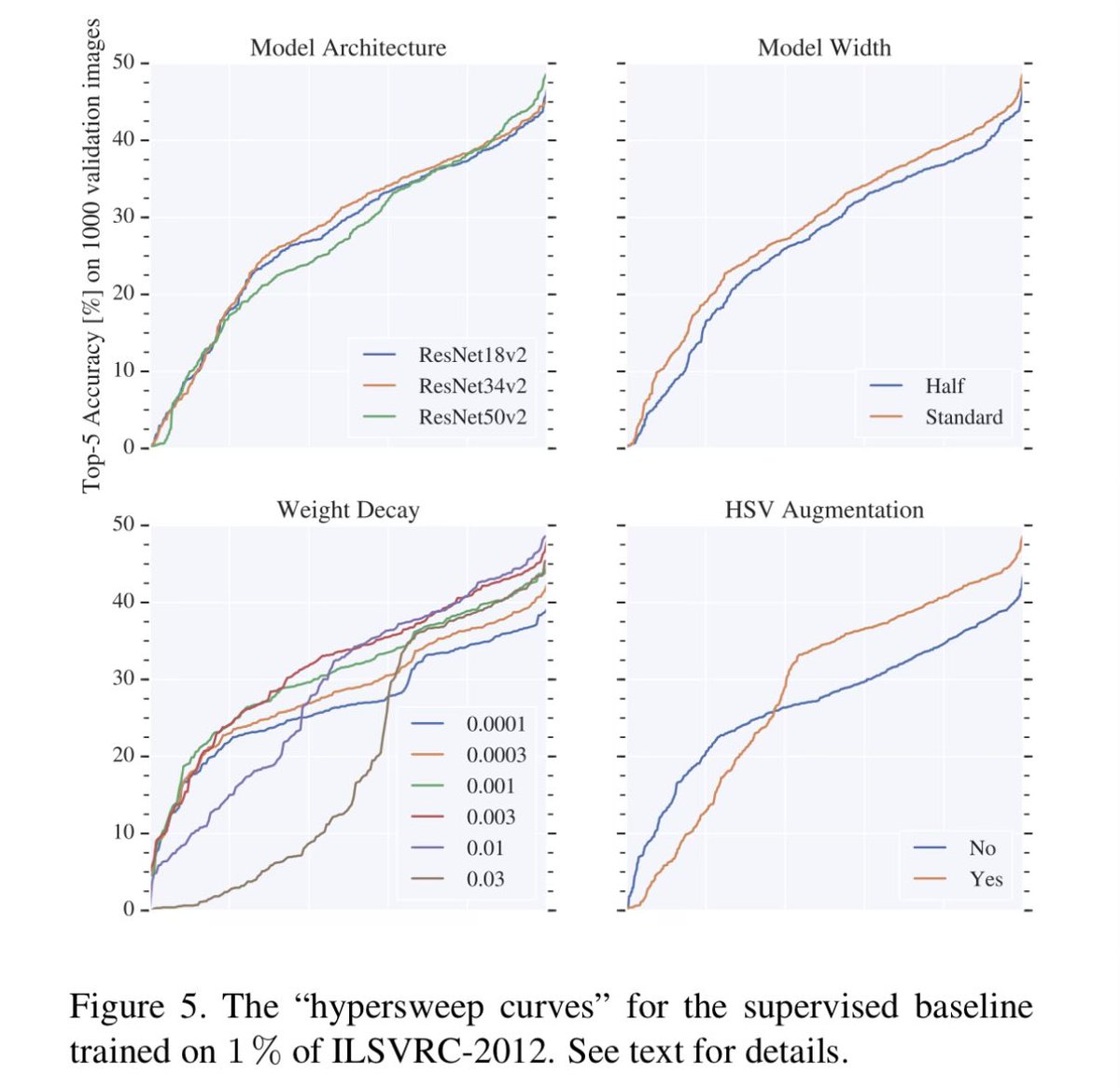
Source: S4L paper where i tuned the most sota 10% and 1% ImageNet baselines ever, by far.
arxiv.org/abs/1905.03670



4
4
204
41,354
Honestly it's one of the most surprising parts of the whole DINO thing imo. I'm always surprised people don't notice it more
1
16
1,802
Jun 11
ok time for a pet peeve stop saying exponentially or logarithmically when you mean convex or concave
Jun 10

Good call out. *Everyone* knows capabilities scale logarithmically with computing power.
This is the second paragraph. How on earth does a mistake like this make it in?

3
20
2,900
TimDarcet retweeted

Jun 6
parents: "move out"
girlfriend: “quit being such a loser”
boss: "work harder"
claude: "uber for dogs (the dogs are the drivers) is a great idea, you should absolutely pursue it"
197
3,314
81,036
1,260,576
TimDarcet retweeted

Actually clip>ssl for LLMs is fake news, DINOv2 was just not scaled enough. Presenting those results in 1h at CVPR ;)
6
1
37
2,369
TimDarcet retweeted

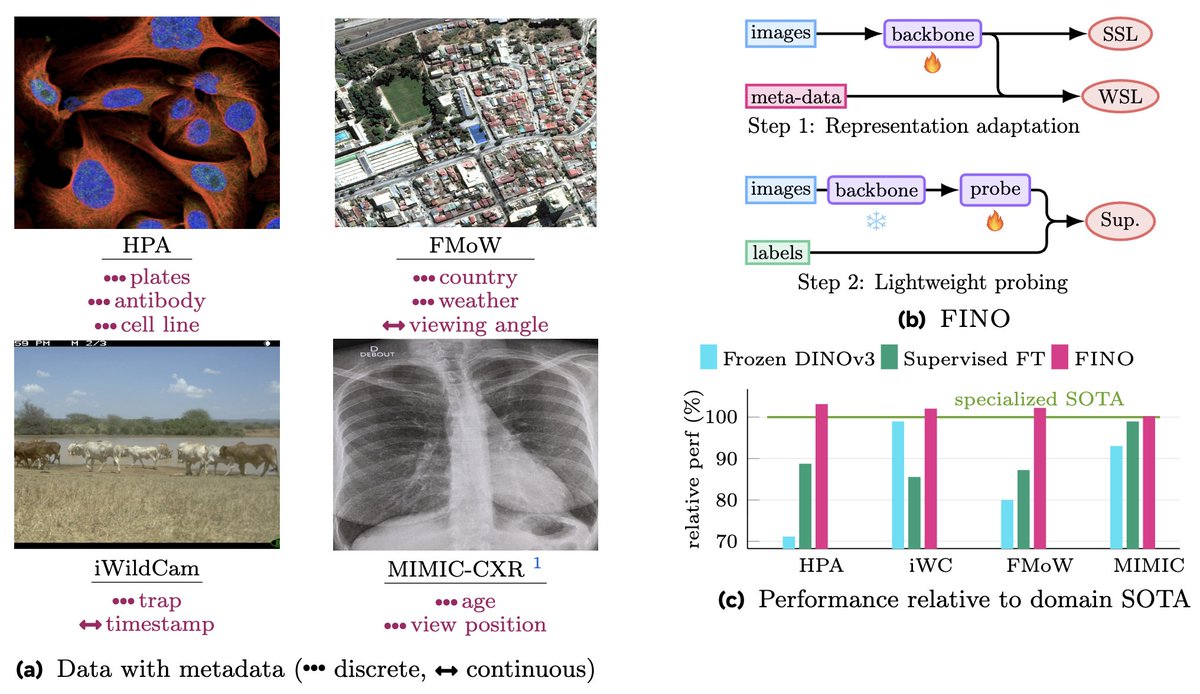
What if the metadata from acquisition was enough? 👀
Sometimes the most useful labels aren't labels at all.
Introducing📄 Who Needs Labels? Adapting Vision Foundation Models With the Metadata You Already Have
4
20
48
5,785
TimDarcet retweeted

May 10
I'm releasing Bio-DINO 🧬
A self-supervised image encoder for natural photographs of biodiversity - trained on ~31M curated images spanning plants, fungi, insects, fish, corals, birds, mammals and more.
Built for embeddings, retrieval, clustering, probing and transfer learning.

5
14
60
5,758

May 29
What people don't realize is that you can use torch.Tensor but skip torch fsdp, pp, amp, checkpointing, built-in kernels, or even autograd and... at this point is your stack really "based on pytorch" anymore?


5
36
6,617
TimDarcet retweeted

May 28
1/ We’re so glad to share this new study 💫
Does the brain learn like a Deep Net? 🧠⚙️
- 📄Misalignment Between Backpropagation and the Hierarchy of Brain Responses to Images
- 🔗arxiv.org/abs/2605.28693
Thread below 🧵
4
42
176
24,957
TimDarcet retweeted

May 13
Confession: I never had a single work-related sleepless night or ever pulled an all-nighter during my career incl. PhD. Don’t sacrifice your health. Sleep is a superpower — your brain on 8hrs of sleep is a lot smarter than your brain on sleep deprivation.
Don’t listen to people who tell you to chronically sacrifice sleep for work. Sacrificing sleep for your kids/family is a different story.

I doubt all those things are really possible. Infact I believe, you are not doing a good PhD unless you have sleepless nights.
Definitely just working on your thesis is possible if you follow a 9-6 schedule, but a good PhD which involves exploring, colabs, etc needs extra hours
28
70
1,076
105,801
TimDarcet retweeted

May 13
1/9 Excited to share TextSeal, our new state-of-the-art watermark for large language models at FAIR / Meta Superintelligence Labs (@AIatMeta) 🔐
Paper: arxiv.org/abs/2605.12456
Code: github.com/facebookresearch/…

1
11
34
4,219
TimDarcet retweeted

May 11
With the model's simultaneous speech capability, Horace has gotten a lot easier to work with recently.
45
61
1,215
275,640
TimDarcet retweeted

May 11
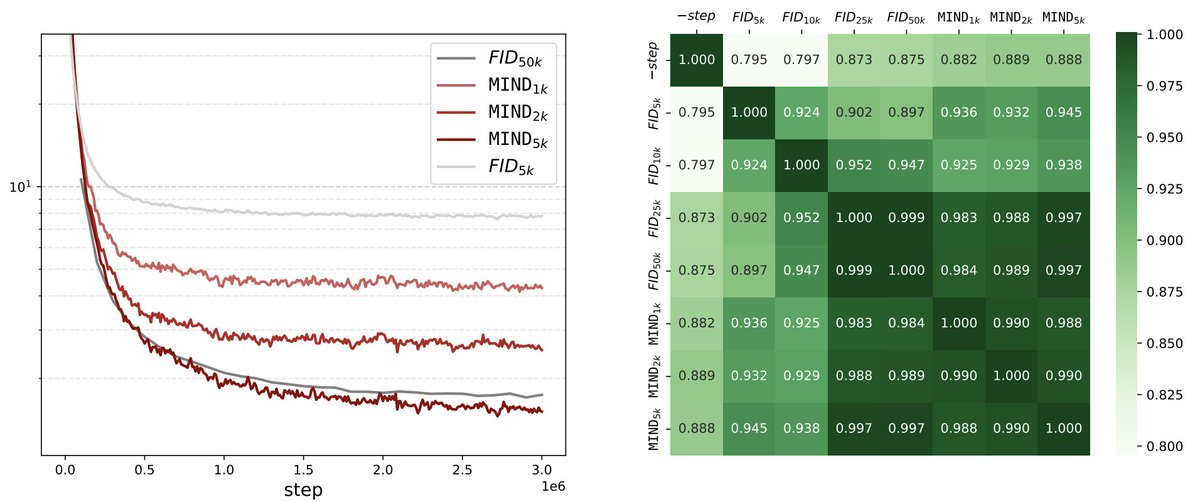
🚨 New paper: Introducing MIND (Monge Inception Distance)
Everyone agrees that FID is broken, requires too many samples, slowing down evals.
MIND requires 10x fewer samples, is more robust, faster to compute.
Our new drop-in replacement for evaluating generative models. 🧵👇
12
68
460
55,339
TimDarcet retweeted

“And if a computer can grade a task, it can do that task.”
Hey guys, @TIME says P=NP. Time to pack it up.
May 7

Interesting article: time.com/article/2026/05/05/…
31
201
4,743
259,847
May 7
In this field you should aim for your h-index to be always equal to your number of papers
May 7

And you realize that Kaiming He is the GOAT when you see that he wrote only 96 papers (vs people with his h-index usually have hundreds)
2
12
2,585
TimDarcet retweeted

Feb 10
Are ViTs secretly RNNs? #ICLR2026
Our 2-block recurrent transformer recovers 96% of DINOv2’s IN-1k accuracy & reproduces its activations 1-to-1, motivating the Block-Recurrent Hypothesis: arxiv.org/abs/2512.19941
w/ @thomas_fel_ @RichieHakim @ABrondetta Demba Ba @t_andy_keller
11
134
720
108,308
TimDarcet retweeted

#ICLR2026
Frictions in Vision Transformers
1/ ViTs use a [CLS] for global understanding and patch tokens for local details. Despite their different roles, we've been processing them with the exact same math.
Looking forward for discussions !
Sat 25 10:30 AM – 1 PM
P4 -#3303
1
6
30
2,235
Apr 21
periodic reminder that FSDP does exactly 0 additional communication compared to DDP


9
5
81
17,190
Apr 17
in other words, you need 300 tokens/gpu to not be HBM bandwidth-bound on H100
Apr 16
Is it reasonable to consider that since the HBM3 memory of a H100 has a bandwidth of ~3Tb/s and the chip can do ~900TFlops, a rule of thumb is that every bfloat16 should be reused ~600 times?
13
2,838