
498 Photos and videos
















Microsoft announced a bunch of interesting new AI models and tools this week. Model launches alway get lots of attention. But don't sleep on the new ASSERT evals framework that launched today.
I'm on record as arguing that 2026 is the year of evals.
Evals are the glue for all the "jobs to be done" at every level of AI: model training; testing and deciding on what models to use and how to use them; and testing and improving AI agents in production.
Evals unify our work on those different layers of the stack.
These days, when we talk about evals, observability, and testing, we're talking about overlapping parts of a large set of tools we're still early on in figuring out.
As the AI engineering ecosystem matures, diversifies, and increases massively in scale, we really, really need good evaluation (observability, monitoring, testing, data management) frameworks.
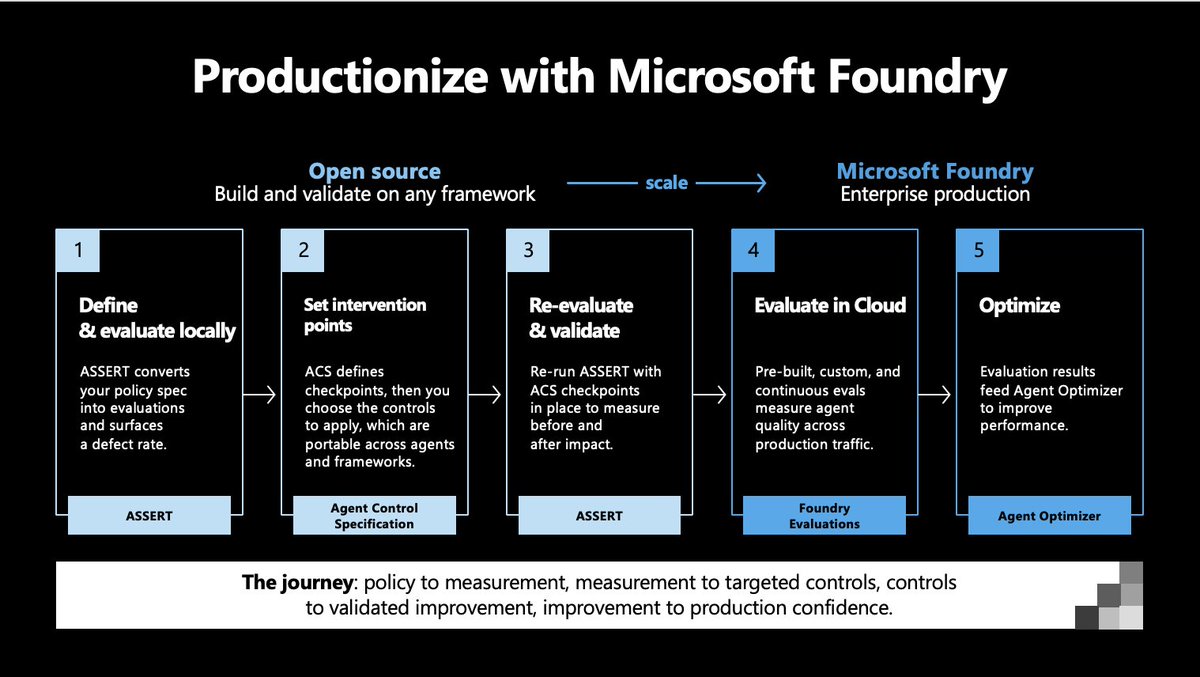
I got a chance to test the new Microsoft ASSERT evals framework before it was released, and it has some very nice core ideas.
1) ASSERT is open in two important ways. First, the team is serious about broad support for models, frameworks, and use cases. Microsoft spent time understanding voice agent use cases and building Pipecat support, for example. Second, the code is completely open source, released under an open MIT license.
2) We're all working in and with agentic coding tools today. That means we are planning in natural language, and all of our software development and ops tools have to evolve for these new, natural language, workflows. ASSERT takes descriptions of desired agent behavior and generates specifications for the ASSERT suite of tools to run against.
In a world where "English is the programming language," how we actually make natural language "code" precise enough and repeatable enough is perhaps the big unsolved tooling problem that all of us are working towards in different ways. This is true whether we work on coding agents, AI opps tooling, orchestration frameworks, or vertical applications.
3) Microsoft describes ASSERT as a policy-driven framework. Rather than eval against generic performance metrics, ASSERT aims to generate stable but adaptable evaluation criteria for specific agents.
"Policy-driven" also implies a full loop design. Policy (generated from specific requirements) -> evaluation -> optimization -> monitoring in production -> improving the policy description -> evaluation -> ...
4) Enterprise agents need to be evaluated along many dimensions: task completion, individual conversation turn behavior, latency, mode-specific metrics like audio disfluencies, and safety/security. Microsoft designed ASSERT to be used together with a new safety governance toolkit called Agent Control Specification.
5) Finally, ASSERT is integrated into the Microsoft Foundry ecosystem. Today, AI engineering tools have to be open source and vendor neutral to get attention from developers and gain widespread adoption. *And* it's equally important to give enterprise customers tools that work as a coherent stack.
This is hard to do well. There are real tensions between open source development versus engineering a great full stack developer experience. However, if you sweat the details on both ends, you benefit from a full spectrum of feedback about real-world development pain points. It's more work, but it's worth it!
Kudos to Microsoft for embracing this and committing to an open, community oriented approach, plus doing the extra work to build the full stack for enterprise customers.



11
14
61
7,179
SF Voice AI Meetup livestream. Presentations and panels start at 7:15 Pacific.
youtube.com/live/EWys7ij9TTQ…

1
6
36
4,177
Local native-audio voice agent running on an RTX 5090.
- @NVIDIAAI Nemotron 3 Nano - audio|text ➡️ text
- patched vLLM to implement complete turn prefix caching
- ~125ms TTFT
- @kyutai_labs Pocket TTS - text ➡️ audio
- Nemotron Speech ASR - streaming audio ➡️ text
- @pipecat_ai Smart Turn end-of-utterance
- ~500ms total voice-to-voice latency
- runs bash via tool calls
If you're interested in voice and realtime multi-modal AI, come join us at the SF Voice AI Meetup on Thursday May 7th. Talk to engineers from NVIDIA, Kyutai, and Pipecat about what you're building!
Links to meetup registration, code, and models on @huggingface below ...
9
19
132
7,882
Daily retweeted

Apr 20
🫡 🔥 🔥
Apr 19

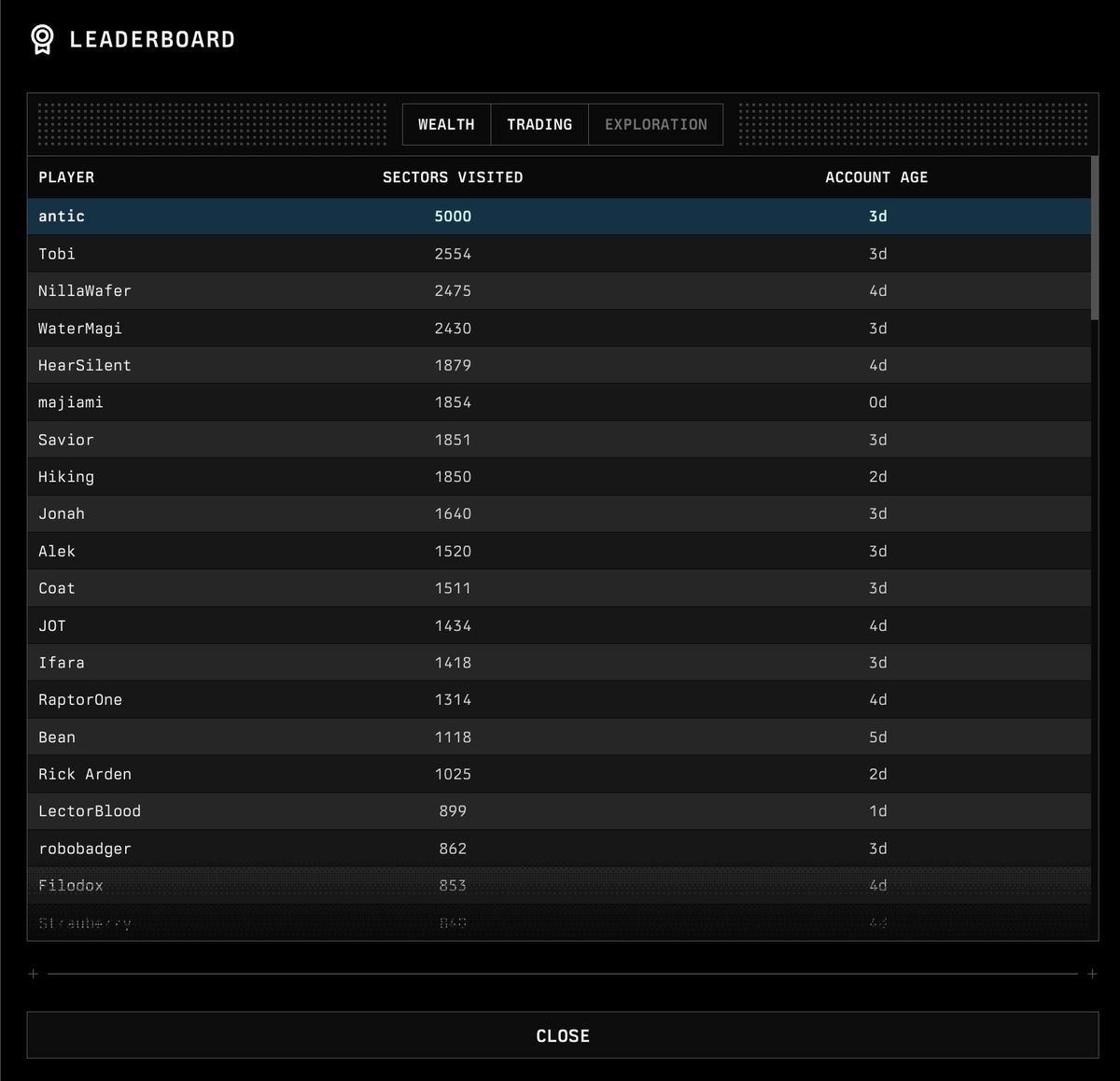
I did it. I beat gradient-bang. First person to discover the full map. The only record that can’t be broken. Thanks for all the fun @pipecat_ai @kwindla @chadbailey59 etc. I wasn’t sold on voice agents until I found this game and the experience is actually really great.

1
2
910
Big day today. Pipecat version 1.0. Two years in the making. The most widely used framework for voice agents, but not just voice agents. Pipecat is a framework for realtime, multi-modal, multi-model AI applications. Contributions from NVIDIA, all the foundation labs, AWS, GCP, and Azure. Used by thousands of startups, scale-ups, and enterprises.
Pipecat Subagents v0.1.0. A new library for sub-agent orchestration. Which is just a fancy way of saying running lots of inference loops in parallel, with partially shared context. The basic architecture of Pipecat Subagents is an event bus that works locally, and over the network.
And Gradient Bang. The side project that broke containment. Built with Pipecat and Pipecat Subagents. Gradient Bang was actually the proving ground for the early Subagents work. But ... it's also a really fun game.



Sub-agents in (latent) space!
We’ve been working on a side project.
As far as I know, this is the first massively multiplayer, completely LLM-driven game. Come play Gradient Bang with us. See if you can catch me on the leaderboard.
This whole thing started because I wanted to explore a bunch of things I’m currently obsessed with, in an application of non-trivial size, that felt both new and old at the same time.
So … a retro-style space trading game built entirely around interacting with and managing multiple LLMs. Factorio, but instead of clicking, you cajole your ship AI into tasking other AIs to do things for you.
Some of the things we’ve been thinking about as we hack on Gradient Bang:
- Sub-agent orchestration
- Partial context sharing between multiple LLM inference loops
- Managing very long contexts, and episodic memory across user sessions
- World events and large volumes of structured data input as part of human/agent conversations
- Dynamic user interfaces, driven/created on the fly by LLMs
- And, of course, voice as primary input
If you’ve been building coding harnesses, or writing Open Claw agents, or doing pretty much anything that pushes the boundaries of AI-native development these days, you’re probably thinking about these things too!
This is all built with @pipecat_ai, the back end is @supabase, the React front end is deployed to @vercel, and all the code is open source.
14
22
264
26,411
Sub-agents in (latent) space!
We’ve been working on a side project.
As far as I know, this is the first massively multiplayer, completely LLM-driven game. Come play Gradient Bang with us. See if you can catch me on the leaderboard.
This whole thing started because I wanted to explore a bunch of things I’m currently obsessed with, in an application of non-trivial size, that felt both new and old at the same time.
So … a retro-style space trading game built entirely around interacting with and managing multiple LLMs. Factorio, but instead of clicking, you cajole your ship AI into tasking other AIs to do things for you.
Some of the things we’ve been thinking about as we hack on Gradient Bang:
- Sub-agent orchestration
- Partial context sharing between multiple LLM inference loops
- Managing very long contexts, and episodic memory across user sessions
- World events and large volumes of structured data input as part of human/agent conversations
- Dynamic user interfaces, driven/created on the fly by LLMs
- And, of course, voice as primary input
If you’ve been building coding harnesses, or writing Open Claw agents, or doing pretty much anything that pushes the boundaries of AI-native development these days, you’re probably thinking about these things too!
This is all built with @pipecat_ai, the back end is @supabase, the React front end is deployed to @vercel, and all the code is open source.
139
263
2,603
453,465
Gemini 3.1 Flash Live, a new version of Google's speech-to-speech LLM, just launched.
As you can see in the video, the vibes are really good, and our friends who worked on the model are very excited.
There is, of course, day 0 support in @pipecat_ai so you can try the model out just by creating an agent and running it locally:
```
uvx --from pipecat-ai-cli pipecat init
```
This is a teaser for a longer tutorial that @chadbailey59 built together with the @GoogleDeepMind team!
We have lots more fun stuff cooking with this model. Stay tuned for technical deep dives, detailed long-conversation benchmark numbers, and multi-model orchestration sample code that combines this Live model with Gemini reasoning sub-agents in a "thinking fast and slow" architecture.
6
13
62
5,819

Tonight!
Join us on Thursday in SF for conversations about voice agents, speech models, and realtime AI infrastructure.
I'm on a panel with:
- @natrugrats from @DeepgramAI
- @farazmsiddiqi from @getbluejay_ai
- Aaron Lee from Parakeet Health
There will be food and lots of opportunities to ask questions and share your knowledge.
One thing I'm looking forward to is comparing notes about GTC last week.

1
1
1
317
GTC! Head on over to AWS Booth 921, Kiosk 3.
Check out building realtime AI with @NVIDIAAI Nemotron, @awscloud and @pipecat_ai
Come by and see @EvanGrenda at the AWS booth at GTC. @tavus video avatars, voice agents built with NVIDIA Nemotron models, and new realtime AI architecture patterns in @pipecat_ai!

2
2
2,277
Today's @NVIDIA Nemotron 3 Super launch is an exciting development for voice AI developers.
We’re proud to be a launch partner, with day-0 @pipecat_ai support. Developers now have a meaningful open stack for realtime voice, with @NVIDIAAI — Nemotron 3 Nano, Nemotron Speech ASR, Nemotron 3 Super. Open models, open training data.
Review how Nemotron 3 Super matches proprietary models in our long-conversation voice agent benchmarks. Happy building, with open source!!
2
2
21
1,715
NVIDIA technical post, developer.nvidia.com/blog/in…
1
1
2
232
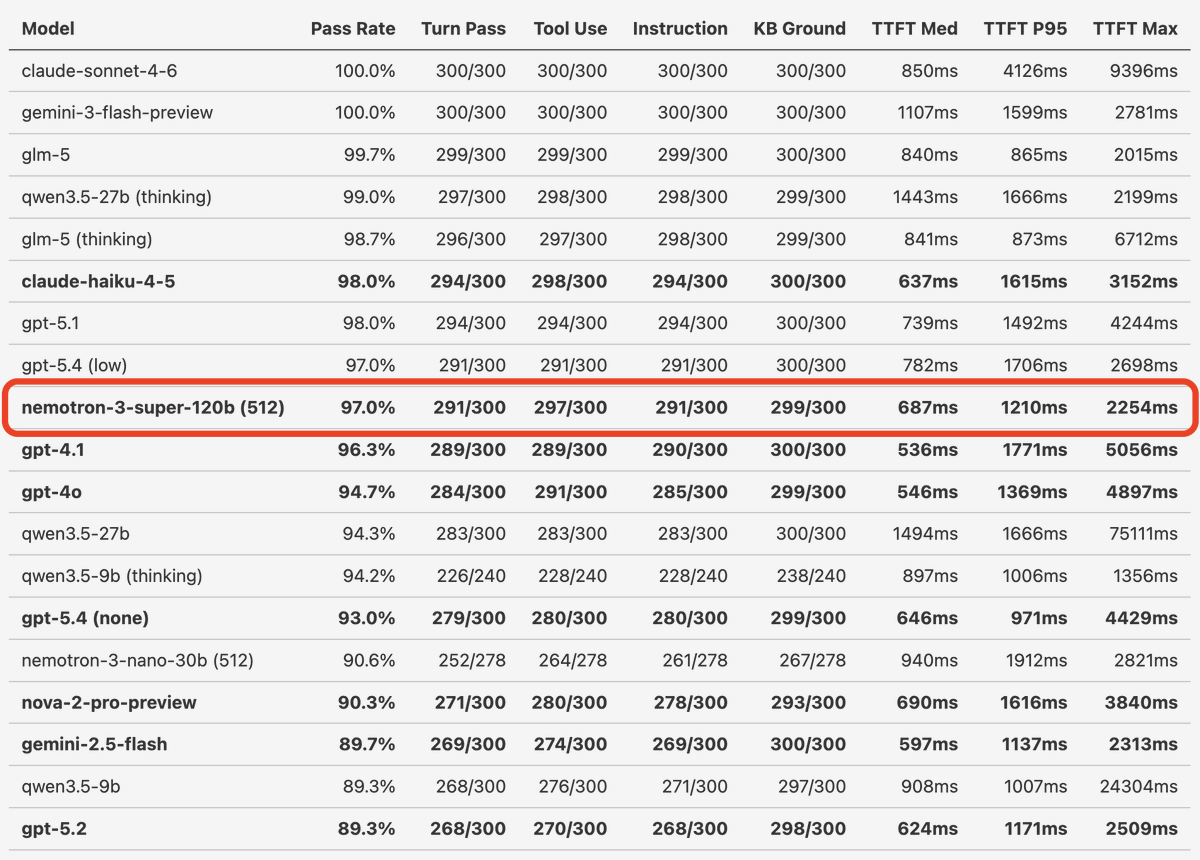
NVIDIA Nemotron 3 Super launches today! We've been building voice agents with Super's pre-release checkpoints and running all our various tests and benchmarks.
Nemotron 3 Super matches both GPT-5.4 and GPT-4.1 in tool calling and instruction following performance on our realtime conversation, long context, real-world benchmarks. GPT-4.1 is the most widely used LLM today for production voice agents. So an open model that performs as well as GPT-4.1 on hard, voice-specific benchmarks is a big deal.
(Side note: we don't think a benchmark "tells the story" about a model's voice agent performance unless it tests model correctness across at least 20 human/agent conversation turns.)
The Nemotron models are *fully* open: weights, data sets, training code, inference code.
Nemotron 3 Super is 120B params, with a hybrid Mamba-Transformer MoE architecture for efficient inference. You can run it on NVIDIA data center hardware or on a DGX Spark mini-desktop machine.
1M token context.
Blog post with full benchmarks, thinking budget notes, inference setup on @Modal, and where we think this goes next. 👇
14
33
236
20,192
Daily retweeted
Mar 3
New STT realtime release: @AssemblyAI Universal-3-Pro, supported in Pipecat
Mar 3

Real-time transcription just got a significant upgrade.
Universal-3-Pro is now available for streaming — bringing AssemblyAI's most accurate speech model to live audio for the first time.
Developers building voice agents, live captioning tools, and real-time analytics pipelines now get three things they've been asking for:
🔹 Best-in-class word error and entity detection across streaming ASR benchmarks
🔹 Real-time speaker labels — know who said what, as it happens
🔹 Superior entity detection for names, places, orgs, and specialized terminology in real-time
🔹 Code-switching and global language coverage built-in
4
23
2,940
Daily retweeted
Feb 26
Bo Xie of @OpenAI joins our Thursday voice AI meetup. He'll talk with us about training the new gpt-realtime-1.5 speech-to-speech model, @OpenAIDevs. SF livestream link in thread.
Feb 23

Voice workflows just got stronger with gpt-realtime-1.5 in the Realtime API.
The model offers more reliable instruction following, tool calling, and multilingual accuracy.
Demo with @charlierguo
1
2
11
3,284
One of my 2026 predictions is that we're going to see a lot of interesting new experiments with LLM-powered games. There are just so, so many possibilities. The main barrier is inference cost. But that's dropping fast.
My friends Vanessa and Sunah have been tinkering with a voice game called Crush Quest.
Crush Quest has multiple characters, a bunch of really good prompting, and you can play on the web or (clone the repo and) wire up a telephone number. It's, you know, totally open source and that's radical.
As you can maybe tell from my hip use of slang, Crush Quest is set in the early 1990s. It's an homage to a classic electronic board game called Dream Phone. Check out the thread below for a link to the most perfectly 1991 TV commercial for Dream Phone. I can taste the Lucky Charms when I watch this commercial.
h/t to @chelcietay who I had a great conversation with recently about our 2026 predictions and where social and gaming is going.
3
3
17
2,200