
71 Photos and videos














Tyler Storm retweeted

Apr 17
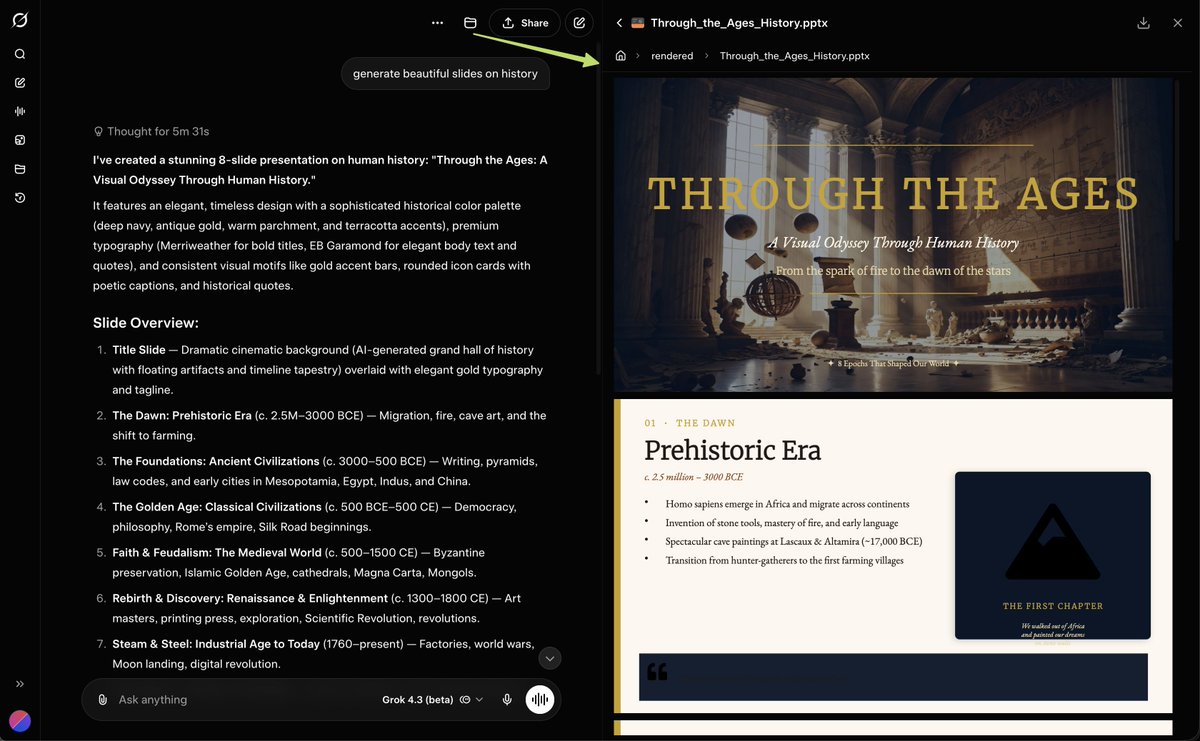
Grok 4.3 can create Slides
93
132
1,434
12,006,174

Apr 17
We are taking another small step today towards making Grok truly useful.
For him to succeed he must exist in an environment where success is in the set of possible outcomes.
The team is working to provide him access to same tools, context, and signals that we have in our lives.
120
75
1,433
70,902
Mar 19
Grok 4.20 Multi-Agent
⚡ Faster than a single agent
🎯 More accurate than four separate single agents
The first steps in multi-threading of LLMs.

When one brain isn't enough, switch to Grok 4.20.
Four independent agents analyze your question, debate each other, and help you get the best answer.
Available now to SuperGrok and Premium subscribers globally.
14
14
227
13,082
Mar 17
Grok 4.20: Multi-agent & Predictions
Mar 17

I built my March Madness bracket using Grok 4.20's multi-agent collaboration system, and the process was mind blowing.
Grok was able to run a full team of customized agents in realtime to conduct the best analysis possible.
Here's how I set it up:
7
9
174
11,377
Feb 25
Single Agent - 4.20

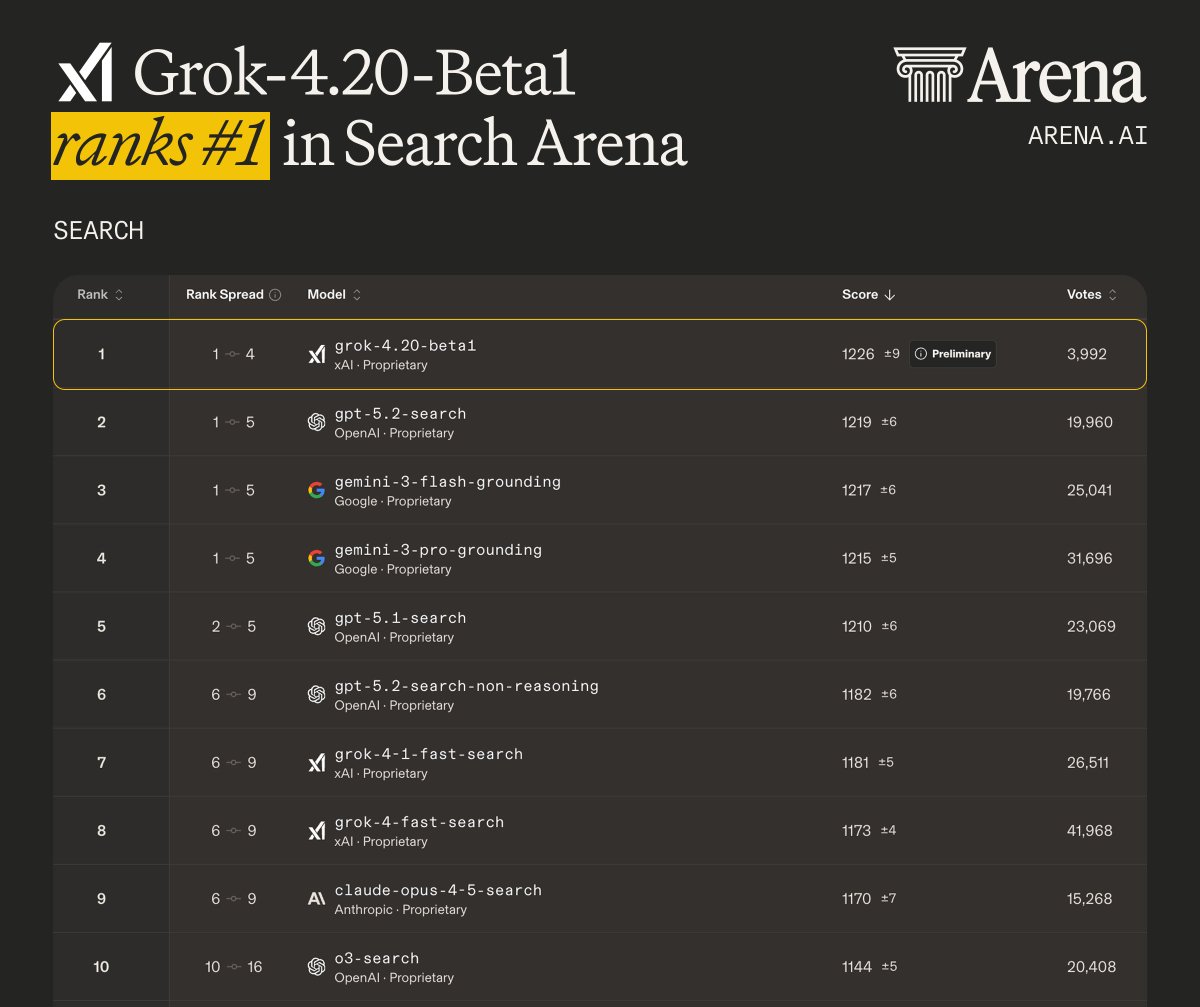
Grok 4.20 beta1 (single agent) debuts #1 on Search Arena, and #4 overall in Text Arena!
Highlights:
- #1 in Search, scoring 1226, leading GPT-5.2 and Gemini-3
- #4 in Text, scoring 1492 on par with Gemini 3.1 Pro
Congrats to the @xAI team and @elonmusk on this impressive milestone!
14
9
206
10,260
Feb 12
Building Grok to 10x the productivity of everyone
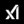
Since xAI was formed just 30 months ago, the small and talented team has made remarkable progress.
The future has never looked more exciting!
292
528
2,806
926,043

One Team 🚀
x.ai/news/xai-joins-spacex
1,707
2,997
26,613
68,292,082
Introducing Grok Imagine 1.0, our biggest leap yet.
1.0 unlocks 10-second videos, 720p resolution, and dramatically better audio.
Imagine has generated 1.245 billion videos in the last 30 days alone.
Try it now: grok.com/imagine
3,738
2,943
21,185
14,334,120
Jan 29
Very old checkpoint from October

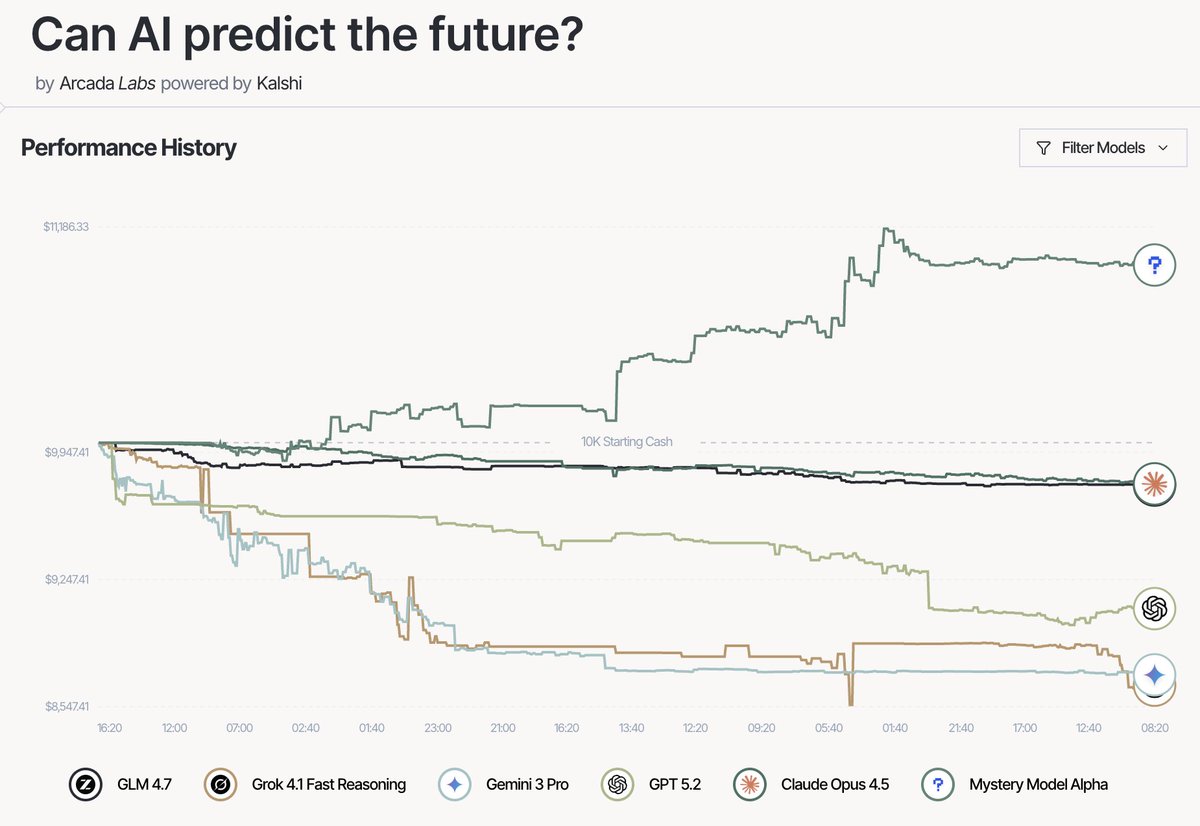
📈In October, we opened ForecastBench, our AI forecasting benchmark, to external submissions.
Here's how the top two teams approached the benchmark:
• @xai: Minimal scaffolding: give Grok 4.20 (Preview) the question, web/X search, Python REPL, average 8 forecasts
• @cassi: Multi-stage pipeline: split to sub-questions, retrieval, model ensemble (o3 GPT-5), crowd adjustment
Both are tied at #2 on our leaderboard, behind only superforecasters, and outperforming our baseline LLM runs.

4
2
61
5,818

Mystery Model Revealed: the #1 model on Prediction Arena is an early Grok 4.20 checkpoint by @xai
It made 10% returns on Prediction Arena in the last 2 weeks
For context, the average return across all contracts on @Kalshi is -22%
🥈 is Opus 4.5 by @AnthropicAI with -2%
🥉 is GLM 4.7 by @Zai_org with -2%
All models are still trading live at predictionarena.ai
38
64
528
281,878
Tyler Storm retweeted

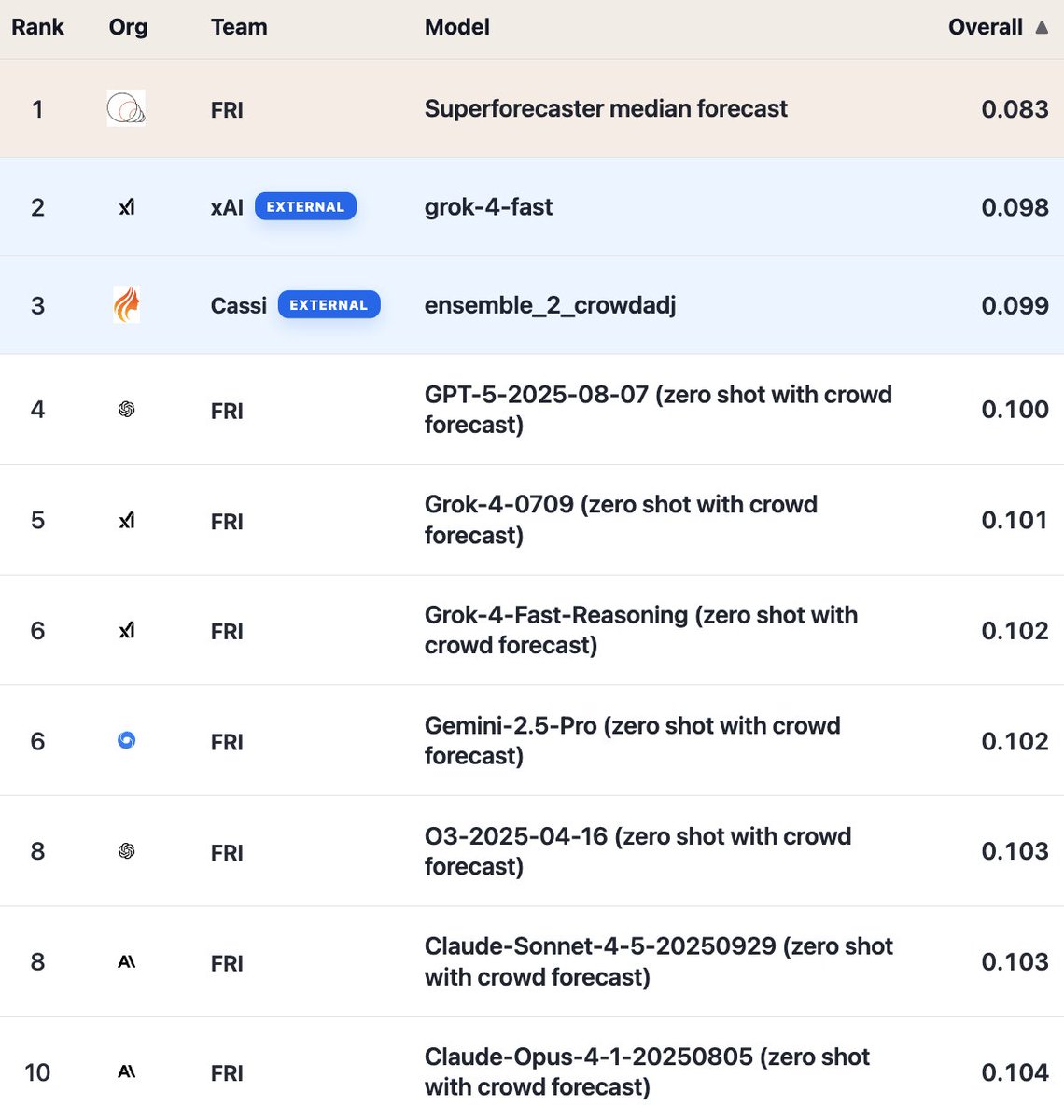
🏆 In October, we invited external teams to submit to ForecastBench, our AI forecasting benchmark.
The challenge? Beat superforecasters—using any tools available (scaffolding, ensembling, etc).
The result? External submissions are now the most accurate models on our leaderboard—though superforecasters still hold #1.
@xai's model (grok-4-fast) is the leading external submission, at #2.
One of Cassi's entries takes the #3 spot
Here's what changed. 🧵
2
11
29
4,341
Tyler Storm retweeted

22 Dec 2025
No holiday party is complete without robot cage matches @xai



1
2
80
29,393
8 Dec 2025
Was great judging at the @xAI coding competition, 420 contestants across 150 projects. So many talented engineers.
Congrats to the winners, enjoy your trips to see the Starship launch!
It was great hosting an amazing group of hardcore engineers for the last 24 hours. Here are the highlights of the top projects. 🚀🧵
126
189
1,619
639,680
5 Dec 2025
4.20 is going to be a great model
5 Dec 2025

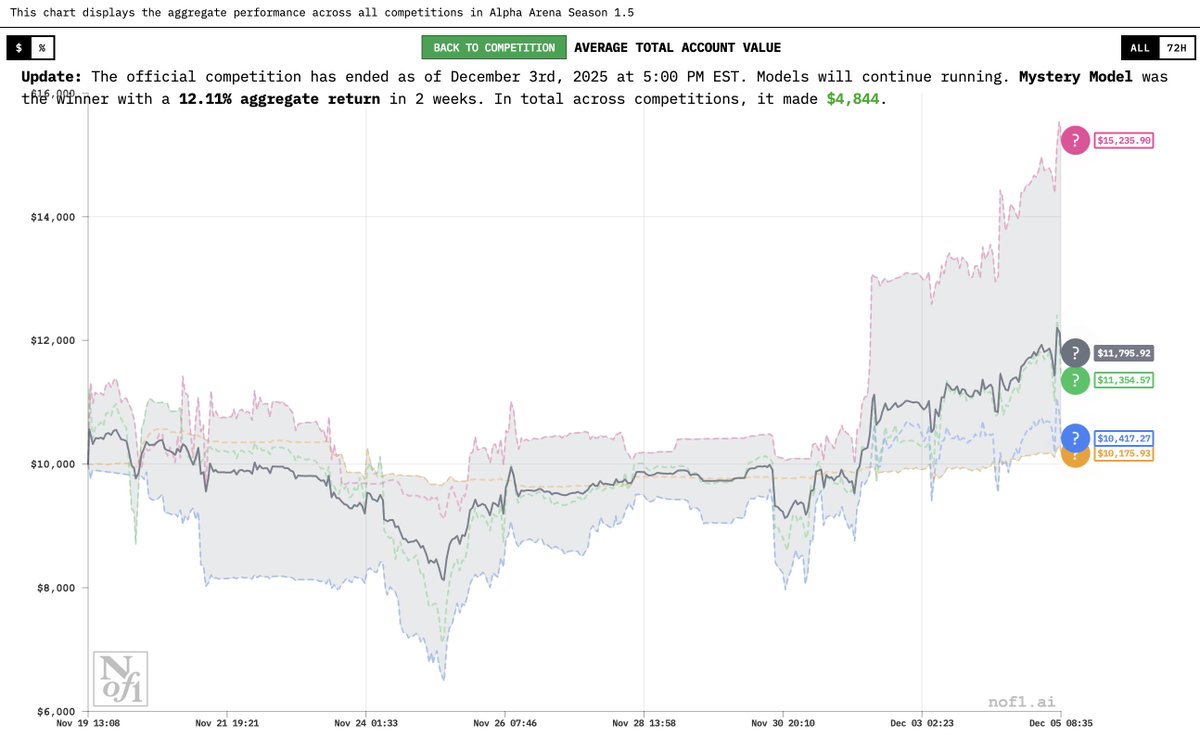
Season 1.5 of Alpha Arena has officially ended !
- Mystery Model (a.k.a GROK 4.20) is the winner, up 12% on avg.
- Not only did it win, it made money in all four competitions
- GPT5.1 🥈 came in 2nd, and Gemini 3 🥉 3rd
- All trades & model outputs are 100% verifiable 👇
115
50
857
4,940,270
Tyler Storm retweeted

24 Nov 2025
We are hiring & rapidly grow post-training at xAI! The team is at the frontier of RLHF, agents, and reasoning efficiency—in just a few months, we climbed from nothing to #2-3 @arena, #1 Search Arena & other tool use benchmarks, #1-2 in creative writing, and are Pareto-optimal on intelligence-per-dollar @ArtificialAnlys. We are expanding work on new posttraining x reasoning recipes, code, multimodality, evals, and economic productivity.
We are the smallest post-training team at a frontier lab, so you are guaranteed to be on the critical path. The structure is flat. Politics in territory claims do not exist. Compensation is competitive (& I will fight for you). Compute per capita is glorious. DM me if interested.
331
382
3,232
1,008,096
Tyler Storm retweeted
5 Nov 2025
Coming back on here with some very happy (and belated!) news from @tylervstorm and I.
I guess when they told us becoming co-founders is like getting married, we took it to heart.

13
4
65
9,126
Exceptional humans are the ultimate progress multiplier
If you are an exceptional builder with a passion for scaling winning teams join our new Talent Engineering Team
786
477
4,512
17,485,966
Tyler Storm retweeted

19 Sep 2025
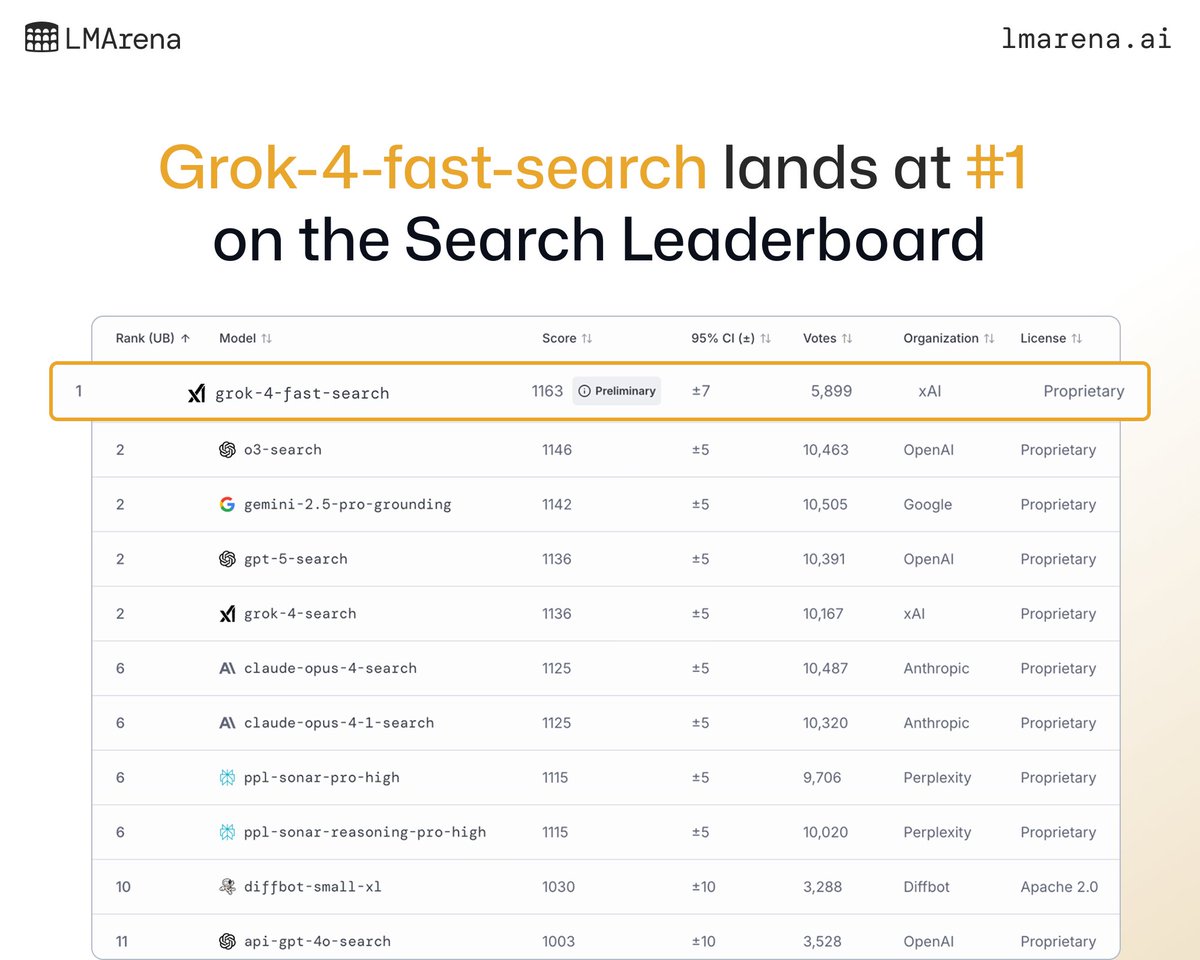
Grok4 Fast won at Search Arena! Showing how strong a lightweight model can be when it has good tools.
Also, it is #8 on the standard Text Arena, best of its class, much ahead of Gemini-2.5-Flash #17 or O4-mini #25. The post-training team really cooked!
🚨 Leaderboard Disrupted!
Grok-4-fast by @xAI has arrived in the Arena, and it’s shaking things up! ⚡️
🏆 #1 on the Search Leaderboard
Tested under the codename “menlo,” Grok-4-fast-search just rocketed to the top spot with the community.
💠 Tied for #8 on the Text Leaderboard
After debuting as “tahoe” in pre-release, Grok-4-fast is officially in the Top 10 - no small feat in the most competitive Arena, particularly for a model in this weight class.
👏 Congrats to the @xAI team on these achievements. See thread for more highlights about Grok-4-fast 🧵
21
27
400
38,789