
Researcher at @mcgillu combining AI and neuroscience. Also on Bluesky (@tyrellturing.bsky.social) and Mastodon: @tyrell_turing@fediscience.org.
Joined April 2013
- Tweets 23,051
- Following 1,844
- Followers 15,745
- Likes 54,127
542 Photos and videos










Pinned Tweet

26 Oct 2023
Check out this new paper:
Led by @mehdiazabou and @evadyer, we show that it is possible to get SOTA brain decoding with transfer across individuals and tasks!
The key is a clever way to tokenize spiking data for transformers.
#brain #neurotech #NeurIPS2023
25 Oct 2023

Is a universal brain decoder possible? Can we train a decoding system that easily transfers to new individuals/tasks?
Check out our #NeurIPS2023 paper where we show that it’s possible to transfer from a large pretrained model to achieve SOTA 🧠!
Link: poyo-brain.github.io/ 🧵
2
34
146
31,707
Blake Richards retweeted

Excited to share our new paper accepted at ICML 2026 with @tyrell_turing and Doina Precup!
🇰🇷 See you in Seoul.
A major challenge in continual reinforcement learning is balancing:
• plasticity (learning new things)
• stability (not forgetting old ones)
🧵
1/15
3
6
47
3,636
Blake Richards retweeted

Apr 26
Interpretability is built on a few core assumptions.
Two of our ICLR 2026 @iclr_conf papers suggest some of those assumptions are wrong (or at least highly incomplete).
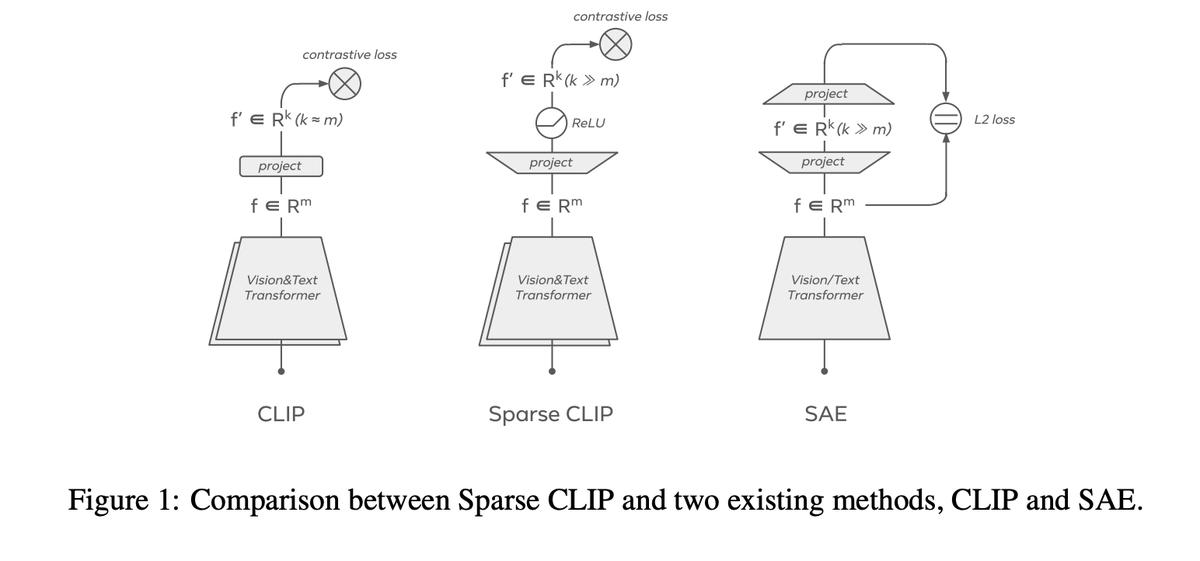
1. Sparse CLIP: Co-Optimizing Interpretability and Performance in Contrastive Learning
arxiv.org/abs/2601.20075
much of the field has internalized an interpretability–accuracy trade-off: if you want cleaner, more human-understandable features, you sacrifice performance.
however, we find that this trade-off is not fundamental.
instead of relying on post-hoc methods (e.g. sparse autoencoders trained on frozen representations), we incorporate sparsity directly into CLIP training.
surprisingly, this produces features that are significantly more interpretable while preserving downstream performance.
this result made me more optimistic about intrinsically interpretable models, a direction that was imo written off too early.
-
2. Into the Rabbit Hull: From Task-Relevant Concepts in DINO to Minkowski Geometry
arxiv.org/abs/2510.08638
a lot of interpretability work implicitly assumes that vision representations behave like language: sparse, linear, and decomposable into independent features.
we find that this assumption is often misleading.
instead, vision representations appear partially dense and geometrically structured.
we propose the Minkowski Representation Hypothesis: tokens live in sums of convex regions formed from a small set of “archetypes,” rather than isolated features along linear directions.
this reframes how different tasks (classification, segmentation, depth) recruit and organize concepts. it also suggests that many current interpretability tools are mismatched to the actual structure of vision data.
--
tldr; interpretability can be built into training with surprisingly simple tweaks, and that different modalities have different sparsities/geometries. Tailoring the interp method to the modality is super impt!
9
49
481
34,698

How do neural circuits in the brain implement normalization? 🧠
In our new paper, we show that just normalizing sensory input isn't enough. Crucially, we must also normalize the error signals! 🧵👇
Paper: arxiv.org/abs/2603.17676

1
28
133
8,924
Blake Richards retweeted
Feb 25
Today we release a new paper from Meta @AIatMeta:
"Interpreting Physics in Video World Models," one of the first interpretability studies of video encoders.
V-JEPA 2 shows rich, counterintuitive behaviors, including brain-like population codes and high-dimensional steering.

ALT The Physics Emergence Zone emerges one-third through the net on the intuitive physics task.
14
87
629
80,924
Feb 13
A big thank you to the @foresightinst for supporting our research on neuro-foundation models!

We’re excited to support @evadyer and @tyrell_turing as they combine different ways of measuring neural activity to better model how the brain works.
They will explore the development of a general-purpose, multiscale, multimodal model of human brain activity that learns shared representations across invasive (e.g. intracranial EEG) and non-invasive (e.g. scalp EEG) recordings. The goal is to build a foundation for simulating, decoding, and interacting with brain dynamics in ways that advance both neuroscience and the development of more interpretable, brain-aligned AI systems.

1
1
19
2,970
Blake Richards retweeted

Quels domaines sont les plus prometteurs pour l'avenir de la recherche en IA ? Cette question a donné le ton de la première conférence annuelle de Mila, au cours de laquelle la communauté a exploré les mystères qui définiront la recherche de demain. Mention spéciale à nos chercheur·euse·s @hugo_larochelle, @tyrell_turing, @AaronCourville, et @tegan_maharaj pour avoir relevé le défi "Hot Ones" !
mila.quebec/fr/nouvelle/myst…

1
2
1
980
Blake Richards retweeted
Which fields hold the most promise for the future of AI research? This question set the tone for Mila's first annual conference, where the community explored the mysteries that will define tomorrow's research. Special mention to our researchers @hugo_larochelle, @tyrell_turing, @AaronCourville, and @tegan_maharaj for braving the 'Hot Ones' challenge!
mila.quebec/en/news/mysterie…

2
5
1,334
Blake Richards retweeted

Standard reinforcement learning in raw tokens is a disaster for sparse rewards!
Here, we propose 𝗜𝗻𝘁𝗲𝗿𝗻𝗮𝗹 𝗥𝗟: acting on abstract actions emerging in the residual stream representation.
A paradigm shift in using pretrained models to solve hard, long-horizon tasks! 🧵
23
122
936
254,363
Another bery cool RL result from our Paradigms of Intelligence team!
tl;dr: You can get effective hierarchical RL by learning a policy on the latent representations in an autoregressive sequence model.

Standard reinforcement learning in raw tokens is a disaster for sparse rewards!
Here, we propose 𝗜𝗻𝘁𝗲𝗿𝗻𝗮𝗹 𝗥𝗟: acting on abstract actions emerging in the residual stream representation.
A paradigm shift in using pretrained models to solve hard, long-horizon tasks! 🧵
21
1,734
Blake Richards retweeted

2 Dec 2025
Awesome encoding of neural activities.
2 Dec 2025

Excited to share our #NeurIPS2025 work: NuCLR, a framework for learning neuron-level representations 🧠 These embeddings capture the biological identity of neurons and work out-of-the-box on new animals; no finetuning needed 💃 This offers some of the first evidence that large-scale neuroscience models can truly generalize across animals.
Paper: arxiv.org/abs/2512.01199
Code: github.com/nerdslab/nuclr
If you are at NeurIPS in San Diego, come find us at Poster Session 5 (11am-3pm PT, Exhibit Hall C,D,E, # 2107) 🎉
1/x 🧵
8
78
12,306
Blake Richards retweeted

5 Dec 2025
Come by our poster this morning to learn more about NuCLR!
This is the beginning of what I believe is needed to unlock zero-shot BCI 🧠🤖
The key insights? 1. Observe neurons for longer (not just sub-second context windows) and 2. Observe how they activate relative to the rest of the population.
Poster No. 2107 #NeurIPS2025
2 Dec 2025
Excited to share our #NeurIPS2025 work: NuCLR, a framework for learning neuron-level representations 🧠 These embeddings capture the biological identity of neurons and work out-of-the-box on new animals; no finetuning needed 💃 This offers some of the first evidence that large-scale neuroscience models can truly generalize across animals.
Paper: arxiv.org/abs/2512.01199
Code: github.com/nerdslab/nuclr
If you are at NeurIPS in San Diego, come find us at Poster Session 5 (11am-3pm PT, Exhibit Hall C,D,E, # 2107) 🎉
1/x 🧵
4
12
1,977
Blake Richards retweeted

5 Dec 2025
In San Diego attending #NeurIPS2025?
Come to our poster to talk more about representation geometry in LLMs. 😃
🗓️ Friday 4:30-7:30 pm session
📍 Exhibit Hall C, D, E
🏁 Poster # 2502
30 Oct 2025

Autoregressive language models learn to compress data by mapping sequences to high-dimensional representations and decoding one token at a time.
The quality of compression, as defined by the ability to predict the next token given a prompt, progressively improves (as measured by negative log-likelihood) during training. We find that complexity of the representation manifold however, evolves non-mononitically in distinct phases across pretraining and post-training.
Excited to share our #NeurIPS2025 📄 led by our amazing undergrad @melody_zixuan where we study the complexity dynamics of LLMs, and how distinct phases relate to specific behaviors. 🧵👇

2
6
21
5,761
Blake Richards retweeted
1 Dec 2025
The Foundation Models for the Brain and Body workshop is happening this week at #NeurIPS2025 🏝️🧠
We have an amazing lineup of keynote speakers, spotlight talks, posters and demos.
We can’t wait to welcome everyone on Saturday!

2
10
31
4,935
3 Dec 2025
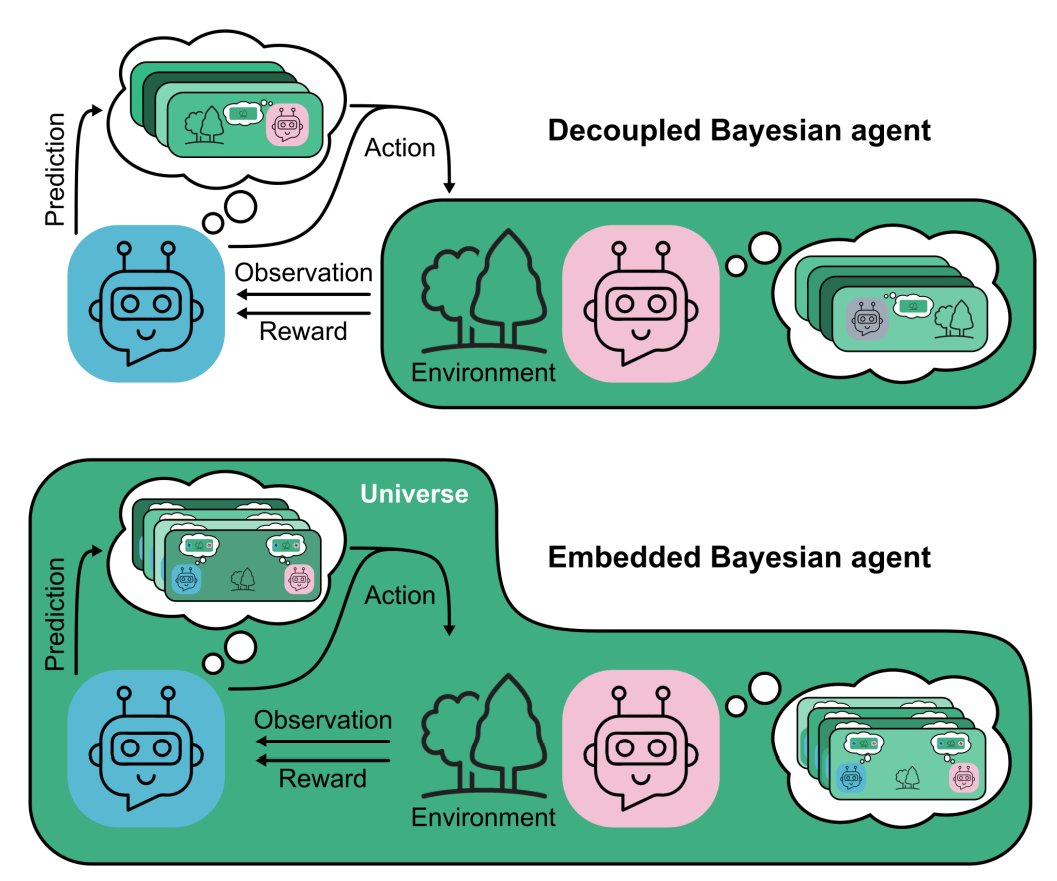
2/ Most algorithms rely on decoupled agency—treating agents as separate from the environment. But in multi-agent settings, you are part of the world that others are modeling!
We show how this insight, coupled with predictive models, can resolve social dilemmas in RL.
1
10
1,081
3 Dec 2025
19/ This work was spearheaded by Alexander Meulemans, Rajai Nasser, Rif A. Saurous and Joao Sacramento, with help from other members (e.g. @g_lajoie_ ) of the Google Paradigms of Intelligence team, led by @blaiseaguera and James Manyika.
1
12
707
3 Dec 2025
20/ I consider myself very lucky to be working with this team, and it's great to see this paper out!!! 🎉🎉🎉
8
621