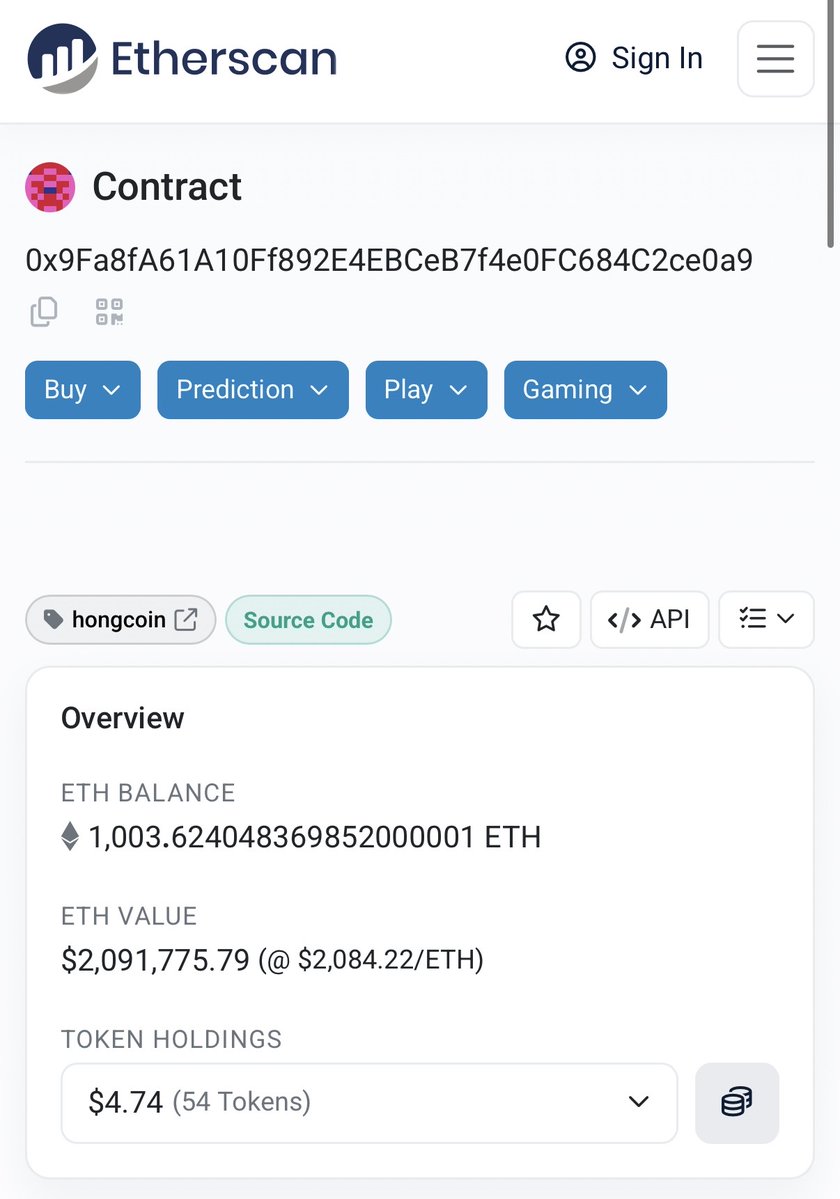
Not sure if my feed is full of Jane Street interviews stories because of X algo's overfit or it's just a smart influencer marketing play.
Recurring "0.95? Huh" part makes me skew towards the latter.
With .95 probability . It's still engaging and fun though
Had a Jane Street interview in 2013 that still bothers me.
It was my 6th round. Final interview. The guy walks in carrying no laptop, no notebook, just a cold brew and what I later realized was a single IKEA tea candle.
He writes on the whiteboard:
food: $200
rent: $800
utilities: $150
candles: $3,600
family: dying
Then he turns around and says, “Optimize.”
I laughed because I thought it was a culture-fit bit. He did not laugh.
So I said, “Well, obviously you spend less on candles.”
He says, “Assume candles are non-discretionary.”
Okay.
I start building a model. Basic constraint satisfaction. Family survival as a soft penalty. Candles as a state variable. Maybe there’s an arbitrage where you buy wholesale paraffin and convert the $3,600 line item into inventory.
He stops me.
“You’re thinking like a consultant.”
That’s when I knew I was in trouble.
He says, “Give me a bid-ask on family dying.”
I say, “What?”
He says, “You’re long candles, short family. Where do you make markets?”
I try to recover. I say the real issue is liquidity: rent and utilities are fixed, food is elastic, candles are emotionally inelastic. Therefore the optimal strategy is to securitize future candle enjoyment and borrow against it.
He nods for the first time.
Then he asks, “What time do you sell the candles?”
I say, “Whenever the market is liquid?”
He says, “Be more specific.”
I say, “Uh… 10 a.m. Eastern?”
For the first time, he smiles.
He goes, “Every day?”
I say, “Every day.”
He says, “In size?”
I say, “In size.”
He says, “And what do we call that?”
I say, “Market manipulation?”
The room gets very quiet.
He looks disappointed and writes something down.
“No. We call it providing liquidity to candle ETFs during the U.S. cash open.”
I try to save it. “Right. Of course. The family isn’t dying because we underfunded them. They’re just experiencing temporary price discovery.”
He nods again.
Then he points back at the board.
I had missed it. The utility bill was $150, but candles provide light. You can zero out utilities.
I update the budget:
food: $200
rent: $800
utilities: $0
candles: $3,750
family: still dying, but now in a more capital-efficient way
He says, “How confident are you?”
I say, “0.95.”
He smiles and circles candles.
“0.95 huh?”
Then he asks me to estimate how many leveraged longs get liquidated if we dump $3,750 of candles at 10:00:01 every morning for 90 consecutive trading days.
Needless to say I did not get the offer.





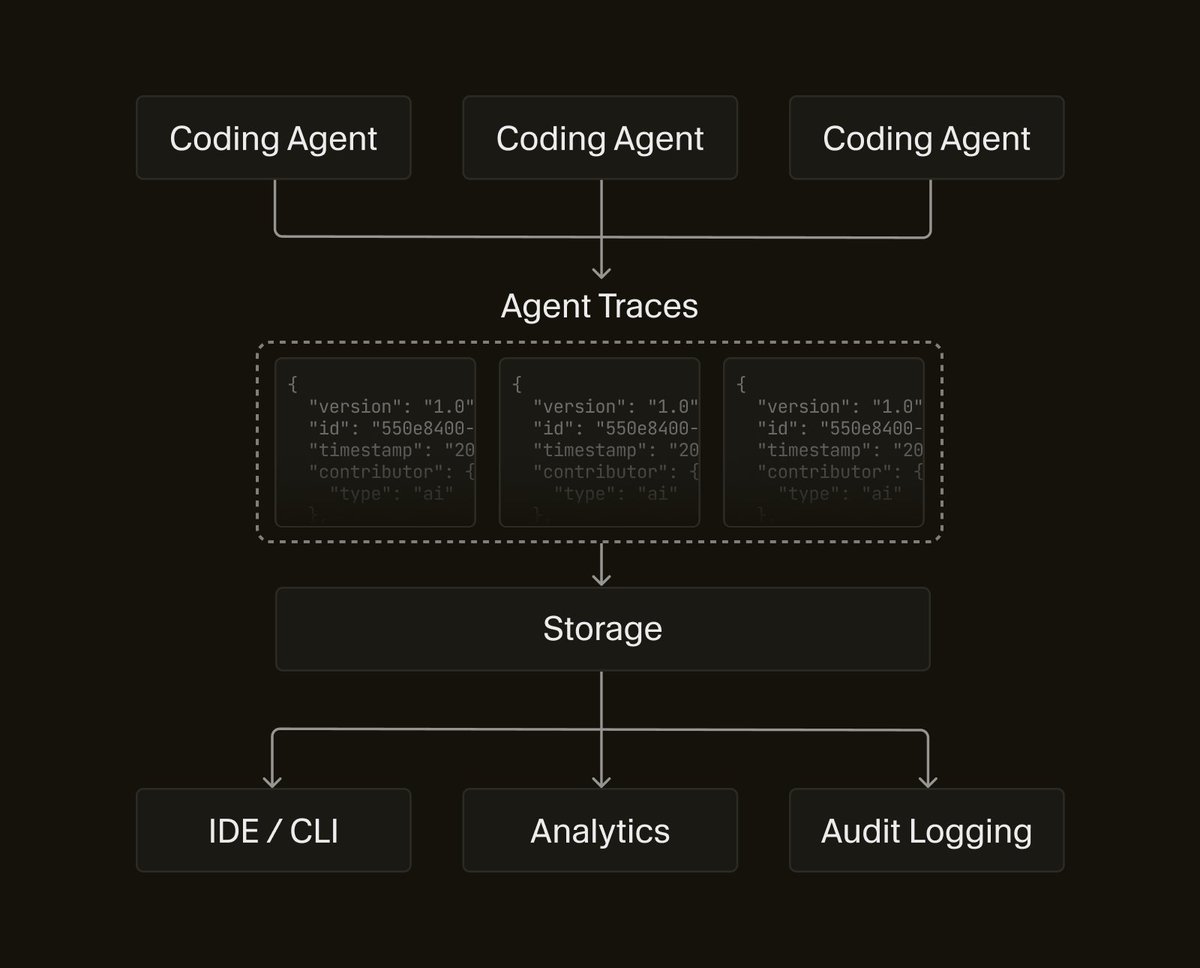
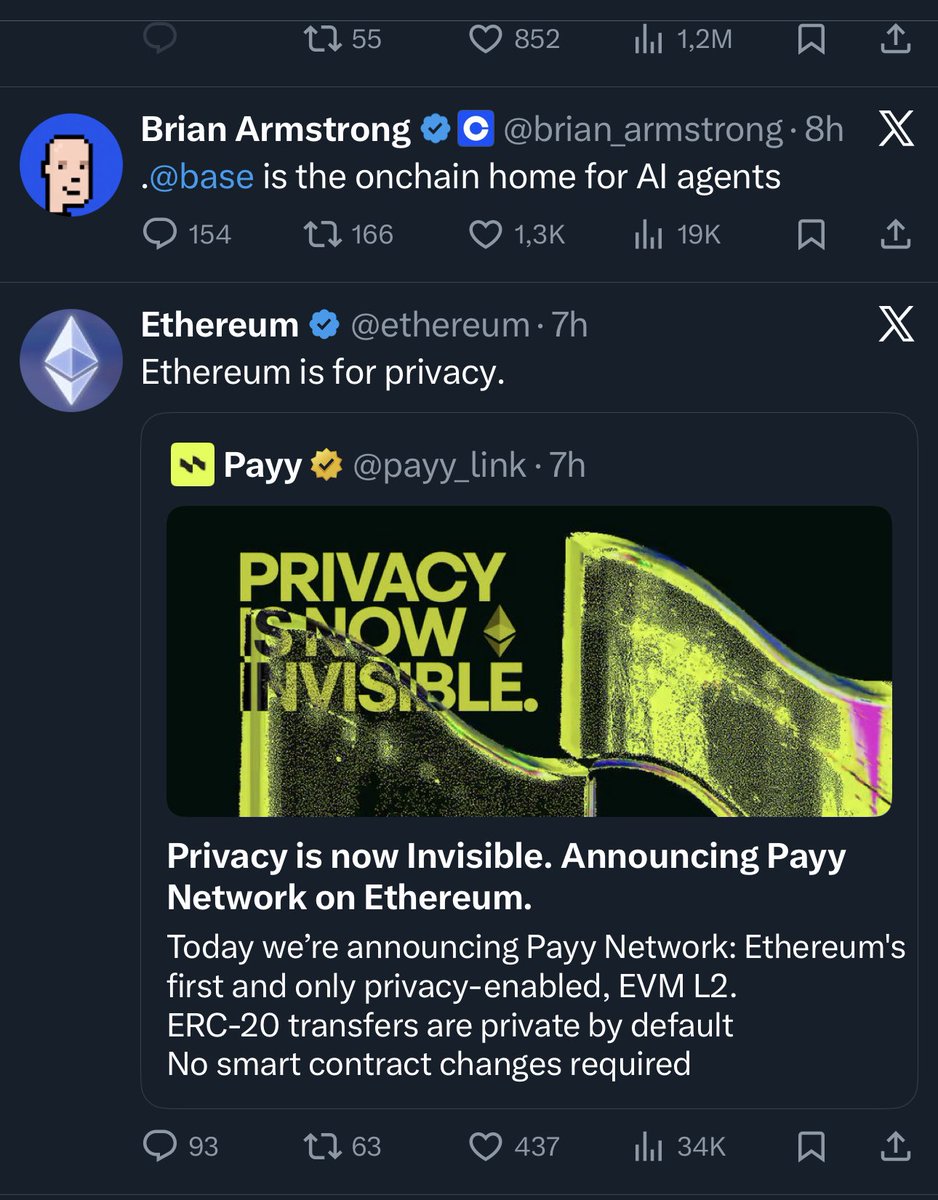
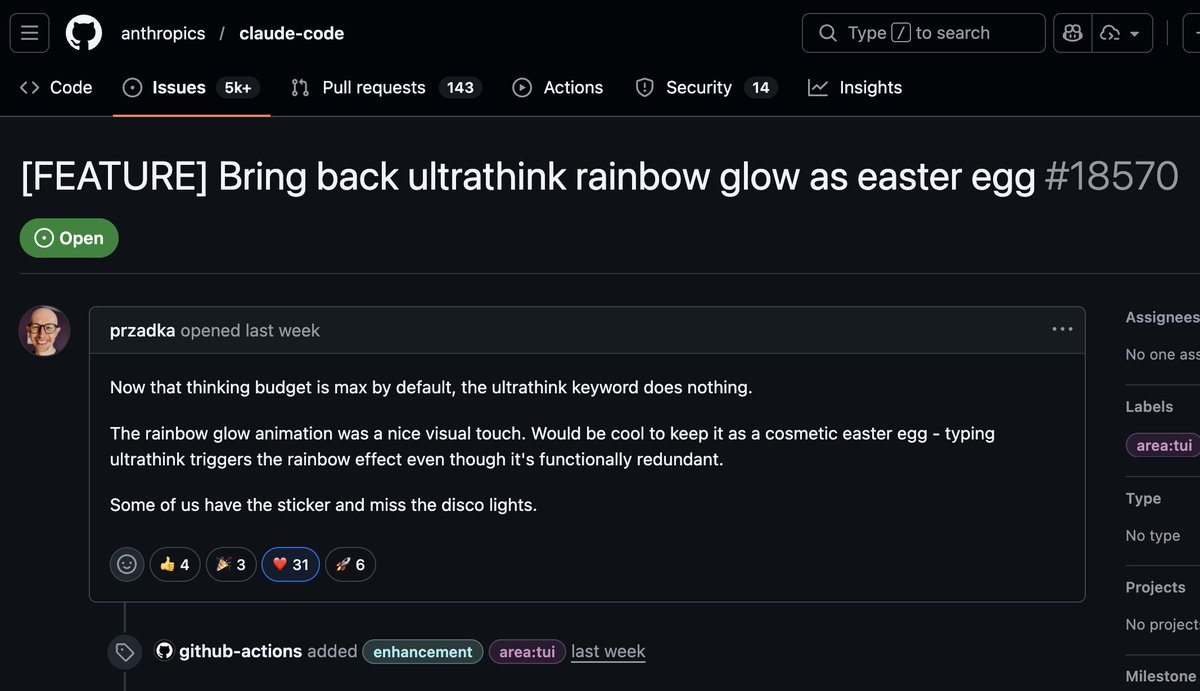

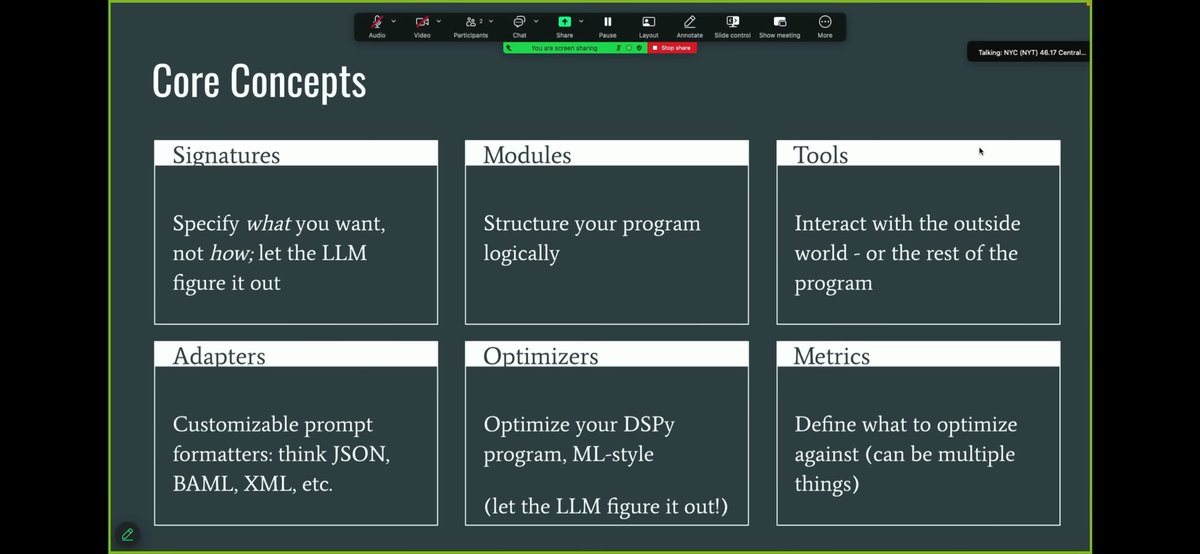






![Line chart titled "Token purchasing power across the engineering basket — Opus 4.6 in SWE-chat." Subtitle: each line shows units of the good 1 token buys, relative to a Feb 5–24 baseline (1.00×); knowledge capture (teal) erodes least. The full-basket composite ends at 0.23× purchasing power (95% CI [0.18, 0.28]) = 4.38× more tokens per unit. The y-axis is log-scaled "output per token," from ~0.15× to 1×. The x-axis spans five time windows A–E (Feb 05 to Apr 15), labeled as phases: Pre-mystery climb, Mystery climb, Post-mystery climb. Colored lines track five goods: agent-drafted code, PR shipped, file touched, agent-drafted docs, and knowledge capture; a thick black "COMPOSITE" line with a gray 95% CI band trends downward from 1× to 0.23×. Knowledge capture rebounds to 0.37×. Reasoning effort shifts from "high" to "medium" to "high" across phases.](https://venexa.site/media/HKTckEXb0AAUvnF.jpg)