
AI & Music Data Scientist @moises_ai | prev. @c4dm
Joined June 2014
- Tweets 2,332
- Following 1,863
- Followers 2,810
- Likes 19,627
136 Photos and videos













Pedro Sarmento retweeted

May 21
My thanks to Alex Ruger and TapeOp for a really fun interview- I enjoyed getting to talk about Roland Future Design Lab and my career with Roland, plus a trip down my own memory lane!
Behind The Gear with Roland's Paul McCabe tapeop.com/interviews/173/be… #tapeop via @tapeopmag
1
2
154

yeahh open source is fun 😜🤟

🥳 Announcing Stable Audio 3 🍕
🏆 fastest music models ever
💻 runs on MacBookPro M-series
🧪 break it plz
🧠 LoRA finetune in < 1h
📷 Sm = faster, Medium = qualityer
⚡ 59x realtime on M5 Pro
One-liner fast install:
curl -LsSf dadabots.com/_/sa3-mac | bash
1
3
41
4,250
Pedro Sarmento retweeted

Fresh off teaching my graduate course on Multimodal Generative AI.
I open-sourced the entire thing on GitHub: lectures labs on vision/audio models, multimodal alignment, RAG, and agentic systems.🔥
Free for anyone building in this space.
Link in comments
#GenerativeAI

2
1
6
351
Pedro Sarmento retweeted

Apr 7
🤯 big update to our flow map language models paper!
we believe this is the future of non-autoregressive text generation.
read about it in the blog: one-step-lm.github.io/blog/
full details in the paper: arxiv.org/abs/2602.16813
we introduce a new class of continuous flow-based language models and distill them into their corresponding flow map for one-step text generation.
we beat all discrete diffusion baselines at ~8x speed!
v2 gives a complete theory of the flow map over discrete data, with three equivalent ways to learn it (semigroup, lagrangian, eulerian). it turns out you can train these with cross-entropy objectives that look very similar to standard discrete diffusion — but without the factorization error that kills discrete methods at few steps.
beyond improving results across the board, we showcase properties that are unique to continuous flows. in particular, inference-time steering and guidance become straightforward. autoguidance brings generative perplexity down to 51.6 on LM1B, while discrete baselines completely collapse at the same guidance scale.
we also show reward-guided generation for steering topic, sentiment, grammaticality, and safety at inference time — and it works even at 1-2 steps with our flow map model. simple, well-understood techniques from continuous flows just work incredibly well in practice for language.
we’re extremely excited about the future of this class of models.
stay tuned for results on scaling, reasoning, and reinforcement learning-based fine-tuning. 🚀
13
92
478
75,948

Pro Musicians, Not Amateurs, Are Leading the AI Music Revolution according to new Water & Music x Moises Study bit.ly/4lFFvqX #aimusic #aimusicproduction #ai #musicians #musictech
bit.ly/4lFFvqX
2
3
263

a vague sense of prog, AI and friendship
youtu.be/sumZL0Mx1-I?si=3Lk8…
156
Pedro Sarmento retweeted

Mar 19
Vibe coding is cool but have you tried vibe patching?
Pure Vibes = Pure Data MCP. Describe your sound, watch the patch appear 🌊
🔊👇
7
16
107
6,741
music - AI - ethics 🎸
Mar 4
Charlie Puth Named Chief Music Officer at Ethical AI Platform Moises billboard.com/pro/charlie-pu…
1
6
308
SCIENCE PAPER DROPPED
big ups @zacknovack 🥳 & the @harmonai_org team
This paper explores an inexpensive method to add custom control (e.g. pitch) to a pretrained audio diffusion model, without retraining the model
arxiv.org/abs/2603.04366
1
3
42
1,155
Pedro Sarmento retweeted

Mar 2
Some really great insights here about the differences between masked and uniform-state discrete diffusion.
Both continuous diffusion and uniform-state discrete diffusion for modelling categorical data seem to be making a bit of a comeback recently. Entropy is all you need🙃
Feb 27

there, I said it. diffusion LLMs are the future! I'll be back in a couple of years to collect my "I told you so" award.

6
19
219
26,583
Pedro Sarmento retweeted

Feb 11
Excited to announce our ICASSP 2026 paper "Stemphonic: All-at-once Flexible Multi-stem Music Generation" !
w/ @__gzhu__, @j_p_caceres, @huangcza, and @NicholasJBryan
🔊Demo stemphonic-demo.vercel.app
📰Paper arxiv.org/abs/2602.09891
More details in🧵
2
18
45
3,482
Pedro Sarmento retweeted

Feb 10
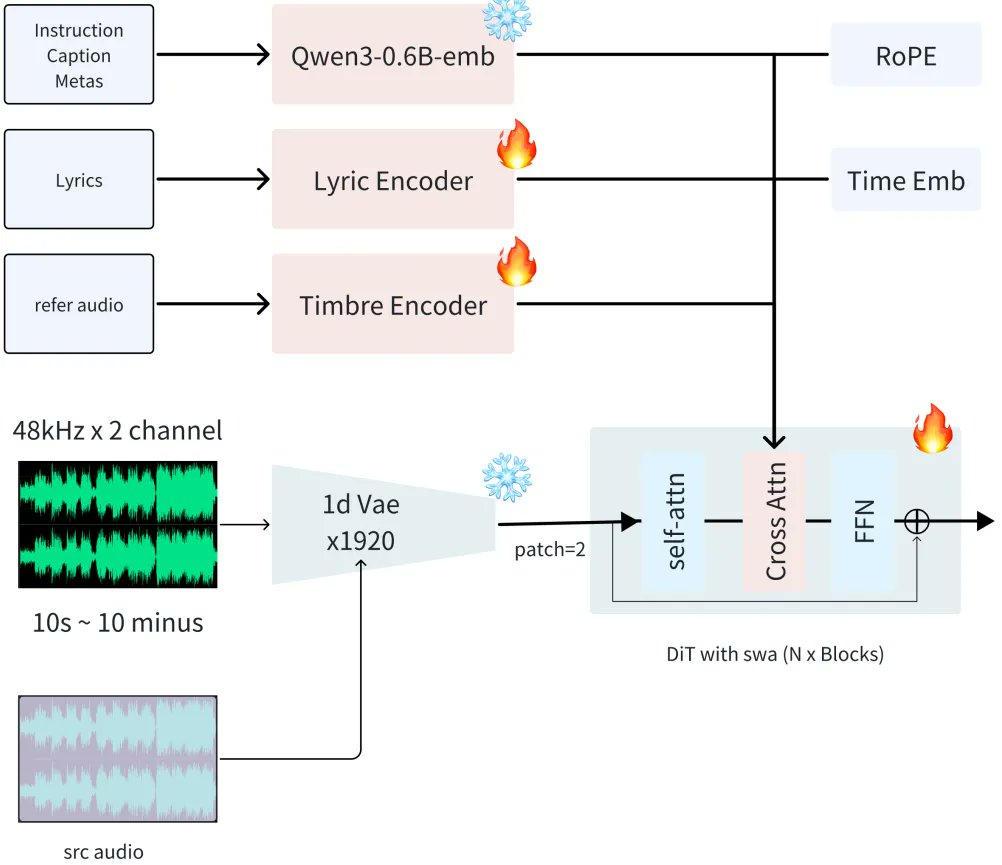
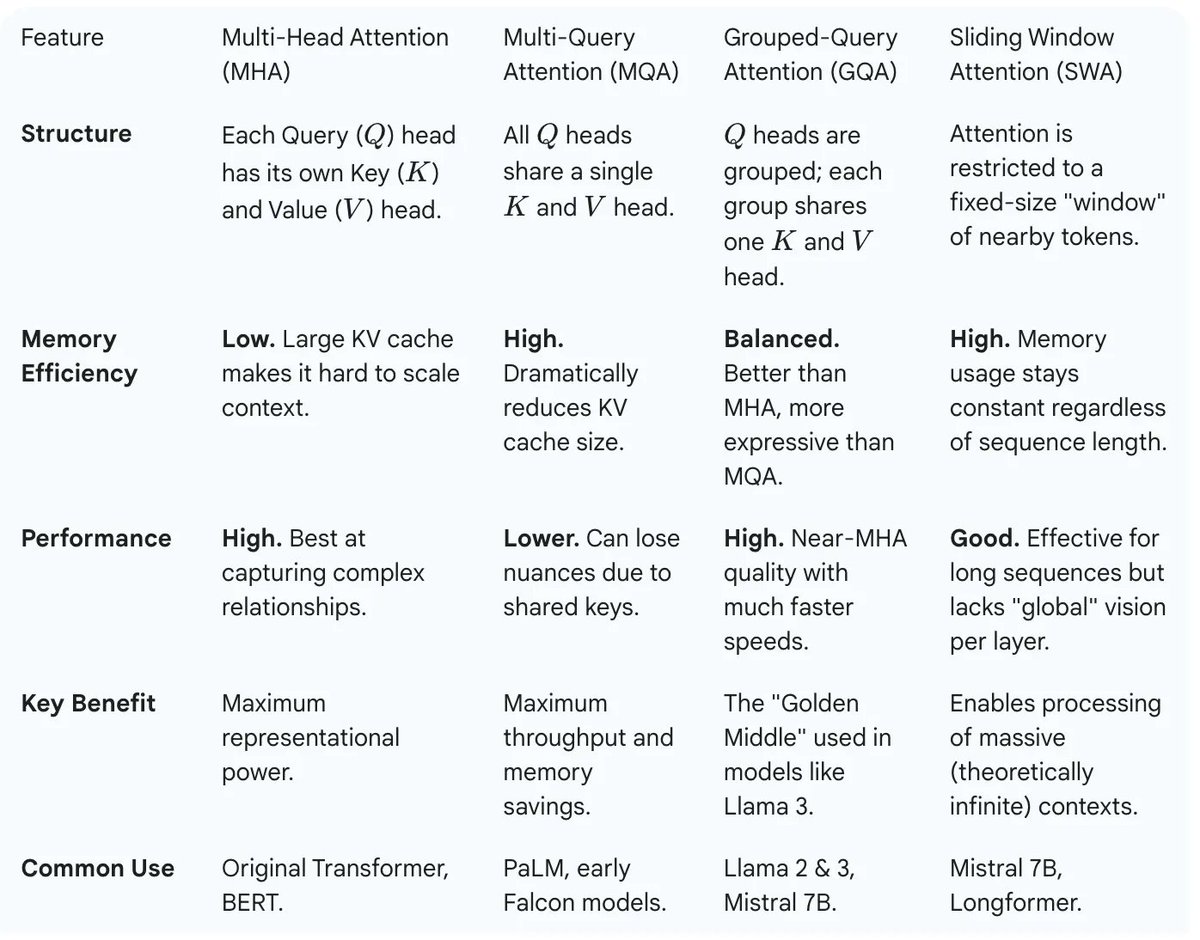
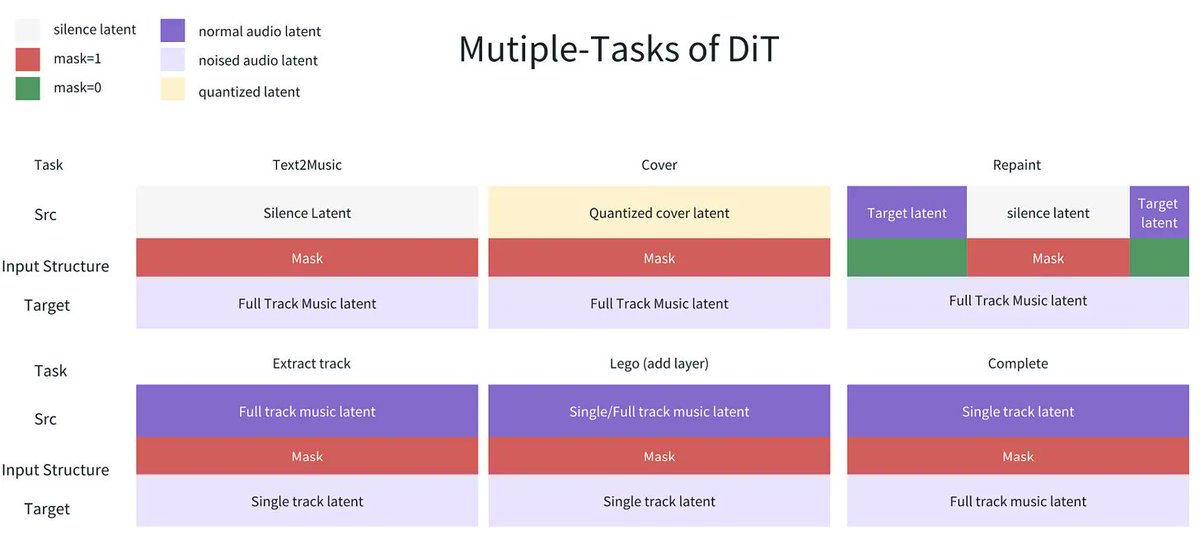
The ACE-Step 1.5 paper can be confusing.
In this post I share are its main ideas: artintech.substack.com/p/ace…
1. DIFFUSION MODEL: supports multiple tasks.
2. LANGUAGE MODEL: reprompting & semantic tokens generation.
3. DATA PREPARATION: 27M songs.
4. OPEN WEIGHTS: supports LoRAs.

5
46
2,692
Pedro Sarmento retweeted

Yes! This ATTM Grand Challenge brings the fair-play & affordability we've been longing for in TTM research: from-scratch training on fixed academic data, prioritizing novel algorithmic or system design. We provide a MeanAudio baseline to get started easily. Join us! 🚀 #ICME2026

📢Happy to announce the ICME 2026 Grand Challenge on Academic Text-to-Music Generation!
- Official launch: Feb 10
- Registration deadline: Mar 20
- Submission deadline: April 23
Co-organizing with @affige_yang @HungyiLee2 @Lonian6 & Fang-Chih Hsieh
ntu-musicailab.github.io/ICM…

1
17
1,049
Pedro Sarmento retweeted

Feb 5
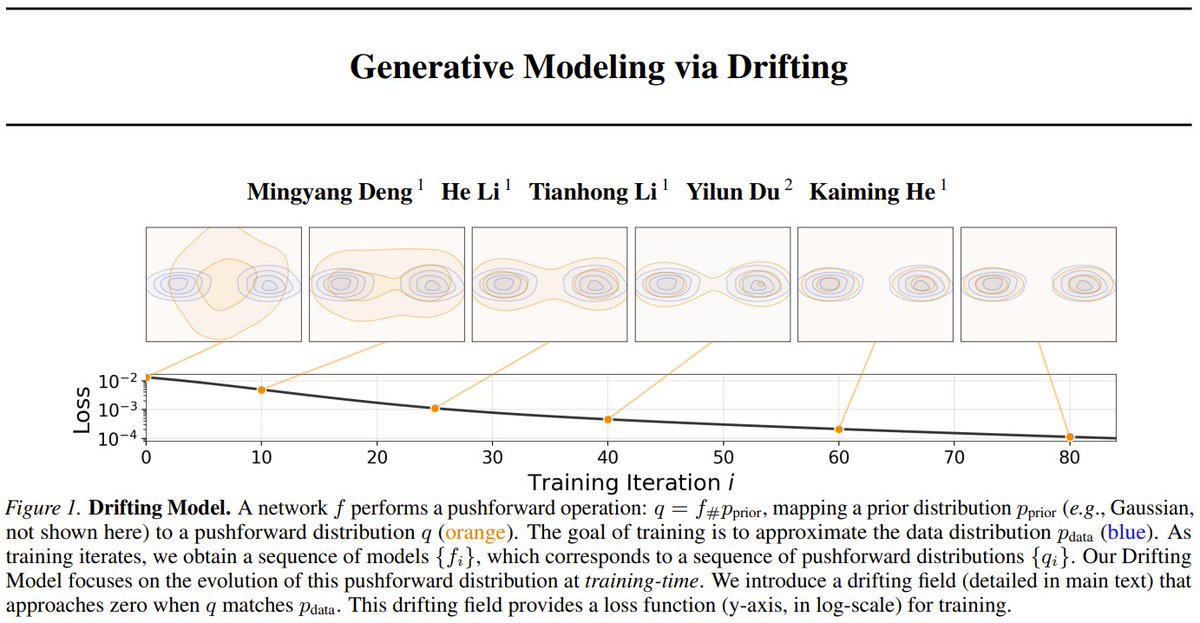
New paradigm from Kaiming He's team: Drifting Models!
With this approach, you can generate a perfect image in a single step.
The team trains a "drifting field" that smoothly moves samples toward equilibrium with the real data distribution.
The result? A one-step generator that sets a new SOTA on ImageNet 256x256, beating complex multi-step models.
15
162
1,288
320,319
Pedro Sarmento retweeted

Feb 3
Today we’re releasing the International AI Safety Report 2026: the most comprehensive evidence-based assessment of AI capabilities, emerging risks, and safety measures to date. 🧵
(1/17)
68
374
1,146
482,982
Pedro Sarmento retweeted

🔊 New Paper Alert — Training-Free Inference-Time Timbre Transfer
Check out our latest #ICASSP paper on timbre transfer in music audio! 🎶
➡️ Diffusion Timbre Transfer Via Mutual Information Guided Inpainting; Ching Ho Lee, Javier Nistal, Stefan Lattner, Marco Pasini & George Fazekas
📜 Paper: arxiv.org/pdf/2601.01294
🥁 Audio Demos: anon-audio-demo-25.github.io…
In this work, we rethink timbre transfer as an inference-time editing problem — and show that you don’t need to retrain or fine-tune heavy models to change the instrumental color of a piece while preserving its musical structure.
🎯 What’s New?
Instead of training separate models or adding control modules for each instrument:
✅ We start from a pre-trained latent diffusion model and steer it on the fly using two simple controls:
• Mutual-Information guided noise injection: add noise only in latent channels most informative of timbre.
• Early-step clamping: “lock in” melody and rhythm by restoring structure-dominant channels during denoising.
This lightweight, training-free procedure lets you control timbre without sacrificing the original melody, harmony or rhythm — and works with text or audio conditioning (e.g., CLAP).
✨ Why It Matters
🎵 Practical music production tools for re-orchestration and sound design
🛠️ Efficient editing with no added model training
🔍 A framework that could extend beyond timbre to other label-driven audio edits
📌 Compatible with strong diffusion backbones and generative audio models
@SonyCSLMusic @SonyCSLParis
4
23
2,001

Very cool to see this large dataset. Walking is good! Bummer about swimming though! My preferred exercise. I figure variability might be greater with swimming! @OncoAlert
Jan 21

The @BMJMedicine was supposed to post this paper 2 hours ago but has failed to do. It is being covered by other means medicalxpress.com/news/2026-…
Someday the link will be active!
dx.doi.org/10.1136/bmjmed-20…

7
32
6,280
Pedro Sarmento retweeted

Jan 22
Carlos Hernandez-Olivan, Hendrik Vincent Koops, Hao Hao Tan, Elio Quinton, "Single-step Controllable Music Bandwidth Extension With Flow Matching," arxiv.org/abs/2601.14356
3
5
495
if you're into great music in general, and prog metal in particular, check the new single by titan @jackjamesloth 🤘
servalprog.bandcamp.com/albu…
1
5
124
Coditany of Timeness --- In 2017 we made the 1st fully neural synthesized album. Ever. We put it on Bandcamp. 1M people listened. 100 articles were written about it. It was research. It was art. It was anti-human black metal.
Today Bandcamp BANS ai 🚫
reddit.com/r/BandCamp/commen…
7
10
77
5,909