
Building Foundation Models • Founder at @soketlabs • @iiscbangalore • HPC ♥️ AI
Joined July 2009
- Tweets 1,350
- Following 627
- Followers 1,658
- Likes 2,378
118 Photos and videos











Hmm. The current leadership is enough. Don’t underestimate them. Nandan sir deviated us from frontier tech which we would have tackled 2 years back. Lets be patient and build with what we have.
Jun 13

PM @narendramodi Sir we need an India AI Mission under you with @NandanNilekani as vice chair and others from the private sector and govt. to Help India tackle the AI Revolution. We are way behind and need a national mission to get going quickly. Existing govt programs are too slow, way too small to make any large impact. We need an annual 50000 cr fund for deep tech and AI, a 200,000 cr ELGS Guarantee Fund to build Hyper cloud, hardware and chips. @AshwiniVaishnaw @nsitharaman @PiyushGoyal @FinMinIndia @RBI We need a Very Large National Mission. @AmitShah @amitmalviya
16
674
So lets build one for India. Enough of this bullshit dependence
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
13
2
59
2,574

Jun 4
#hiring for frontier AI research at @soketlabs
Compensation upto 1.5 cr
Access to thousands of GPUs
We are doing exactly what many told us not to do: building frontier AI out of India.
We're hiring exceptional researchers and engineers to help push the boundaries of foundation models in math, code, reasoning, and multilingual intelligence.
Open Roles
1. Research Scientist, Pretraining – Foundation Models: soket.ai/careers/jobs/resear…
2. Research Scientist, Data – Foundation Models: soket.ai/careers/jobs/resear…
3. Machine Learning Engineer – Foundation Models: soket.ai/careers/jobs/ml_eng…
4. Kernel Engineer – Foundation Models: soket.ai/careers/jobs/kernel…
5. AI Data Engineer – Foundation Models: soket.ai/careers/jobs/ai_dat…
6. AI Data Curator – Foundation Models: soket.ai/careers/jobs/data_c…
7. HPC Infrastructure Engineer: soket.ai/careers/jobs/hpc_in…
#India #AI
21
16
245
12,372
Jun 5
BTW models developed under Project EKA will be open source. More on the initiative here: soket.ai/project-eka
1
8
494
Abhishek Upperwal retweeted

Jun 4
We are hiring across multiple roles at @soketlabs: soket.ai/careers/jobs
We are assembling a world-class team to build the next generation of foundational AI models for India and the world. #BestCompensation #SOTAComputeAndResearchInfrastructure
@upperwal @OfficialINDIAai
11
6
122
7,541
Jun 2
Go for the hardest problem. Love it. Your team is definitely one of the best examples that frontier AI work can happen out of India

Sharing my message that there is no shortage of AI talent in India. As our team has shown, you can do world class AI research from India.
7
664
May 31
Many youngsters are enthusiastically finding vulnerabilities in govt websites.
@IndianCERT should use this opportunity to launch a bug bounty program to incentivise and encourage them. Will build trust and also safeguard the Indian infra. Wont find a better opportunity than this.
1
7
397
May 25
India will build one in the next 2 years
May 24

India has zero chance of building a frontier AI lab this decade.
45
67
1,154
59,755
May 26
May 26

Here’s an early signal to what I said
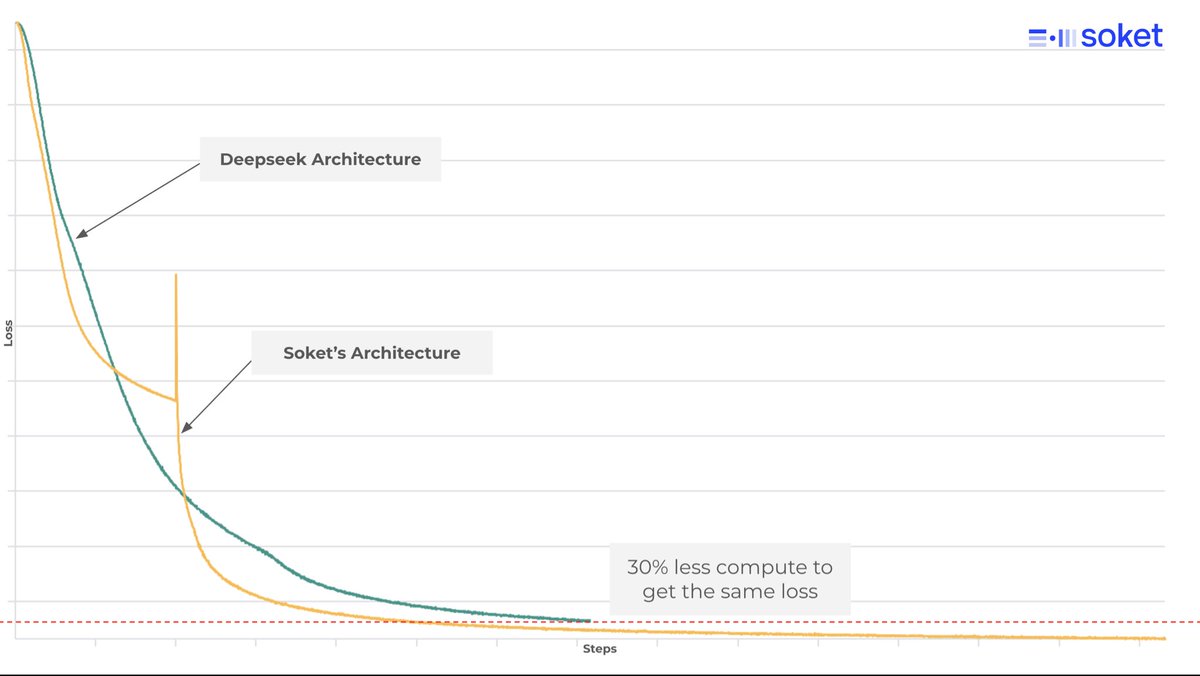
For almost an year now, we at @soketlabs have been working on curating a frontier scale pretraining data corpus along with finding the best architecture that fits the diversity of languages along with being compute optimal for both training and inference.
Sharing one of the many successes we have encountered. Our current version of the arch (yeah, its not a clone of deepseek or any other known arch) is at least 30% compute optimal to Deepseek’s sparse-MoE. These are just initial results and we hope to find a lot more. Shows that we have a lot more to learn about these architectures.
Also excited about the pretraining data we have curated but more on that later
Research efforts take time but they also yield exponential outcomes and thats what most people in India should be building towards
8
783
May 26
Here’s an early signal to what I said
For almost an year now, we at @soketlabs have been working on curating a frontier scale pretraining data corpus along with finding the best architecture that fits the diversity of languages along with being compute optimal for both training and inference.
Sharing one of the many successes we have encountered. Our current version of the arch (yeah, its not a clone of deepseek or any other known arch) is at least 30% compute optimal to Deepseek’s sparse-MoE. These are just initial results and we hope to find a lot more. Shows that we have a lot more to learn about these architectures.
Also excited about the pretraining data we have curated but more on that later
Research efforts take time but they also yield exponential outcomes and thats what most people in India should be building towards
May 25
India will build one in the next 2 years
7
13
108
6,812
May 23
We at Soket AI are hiring for HPC Infra Engineer towards our foundation model efforts. Apply and do share within your network.
#HiringAlert #FoundationModel #AI #LLM #GPU
soket.ai/careers/jobs/hpc_in…
1
7
24
3,121
May 5
I hope Indian IT service companies now realise they need to work and invest in Indian startups.

Anthropic partners Blackstone, Goldman Sachs to launch $1.5 billion AI Services venture
moneycontrol.com/artificial-…
5
1
58
6,887
May 2
So we are moving toward chinese closed source models now.
Soon the argument that India should just “leverage open source” instead of building its own models will end up where it belongs - in the graveyard.
May 1

Qwen3.6 397b will not be open source. This pretty much seals it. A real tragedy.
3
6
34
1,615
Apr 29
This would make us dependent on foreign tech and we would lose out on the chance to learn how frontier AI is built.
We are already late to the game and it would be impossible to catch up two years down the line.
Lets not discourage India from building at the frontier of any technology. Investors have been telling me for the past two years that India will become a use case capital and not a frontier IP driven economy. Something like this coming from you can be detrimental for the entire ecosystem.
Also adoption is a localized problem to solve. Given the density of smart people here we will solve it one way or another. Frontier AI is a broad problem that needs sustained effort and funding. India will reap long term benefits if we are able to crack it.
Apr 29

India doesn't need to lead the world in building the most advanced AI models. But it must lead in ensuring benefits of AI are widely shared.
@rvenk and I have an op-ed in The @EconomicTimes
economictimes.indiatimes.com…
7
477
Apr 24
Apoorv @lazyapoorv doing some kickass hardware product building from India. He has been at it since 2017. So good to see the workshop
Apr 23

The future of AI interfaces is being built on Hosur Road.
A week ago, @ProjectMirageHQ launched their first AI interface, Dune. This was after ~5 months of R&D.
We visited Project Mirage's Bengaluru facility to find out what it's like inside of an Indian consumer tech startup:
3
291
Abhishek Upperwal retweeted

Apr 23
The future of AI interfaces is being built on Hosur Road.
A week ago, @ProjectMirageHQ launched their first AI interface, Dune. This was after ~5 months of R&D.
We visited Project Mirage's Bengaluru facility to find out what it's like inside of an Indian consumer tech startup:
4
27
168
8,296
Abhishek Upperwal retweeted

Apr 16
Introducing Dune: a context-aware keypad for Mac that adapts to what you’re doing.
Dune reads which app is in the foreground and automatically changes what its three keys do based on what you’re working on.
One tap to join meetings without searching for links. Approve and merge PRs on GitHub. Approve or reject on Claude. Or trigger your own Agentic workflows. All from a single key press.
Choose what Dune does from a set of pre-built workflow triggers or build your own. We are shipping a limited batch of Dune and would love to see what you build with it.
projectmirage.ai
54
53
311
304,576
Mar 26
Maybe now give opportunity to Indian startups who are genuinely doing good work.
Mar 26

As per standard protocols laid by State Government, the MoU signed with Puch AI on 23 Mar 2026 was reviewed.
Necessary details as per SOP were sought from the investor, but they failed to provide them timely. Due diligence showed lack of net worth and credible financial linkages for the project's scale. On directions of the State Government, the MoU is cancelled effective today. No rights or obligations remain.
The MoU has been cancelled in the interest of transparency and highest level of probity in governance, which are in the core of Government of Uttar Pradesh.
#UttarPradesh #InvestUP #Governance #Transparency #EaseOfDoingBusiness #PolicyDriven #Accountability #GoodGovernance #InvestorConfidence #MakeInIndia
@UPGovt
1
346