
Faculty fellow @NYUDataScience, incoming assistant prof. @TechnionLive. Causal ML and healthcare applications.
Joined February 2021
- Tweets 62
- Following 158
- Followers 253
- Likes 600
4 Photos and videos




Yoav Wald retweeted

May 14
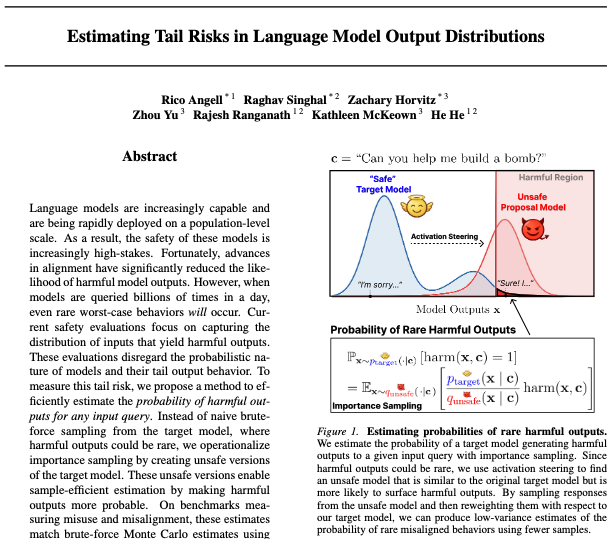
It’s deployment time!
You’ve done the pre-deployment evals. You THINK your model is safe, so you ship it 🚀
🚨 After deployment, reports of misbehavior start trickling in
What happened?? How could you have caught it?? 🤔
@icmlconf 2026 Spotlight!
🧵
3
23
100
15,889
Yoav Wald retweeted

27 Mar 2025
Life update: I'm starting as faculty at Boston University in 2026! BU has SCHEMES for LM interpretability & analysis, so I couldn't be more pumped to join a burgeoning supergroup w/ @najoungkim @amuuueller. Looking for my first students, so apply and reach out!

51
34
537
108,165

10 Dec 2024
What prompt generated the image on the right?
Come find out today at our tutorial on OOD generalization: Shortcuts, Spuriousness, and Stability
@Maggiemakar @aahladpuli
Panel: @ElanRosenfeld @AdtRaghunathan Danica Sutherland
5
19
5,012
Yoav Wald retweeted

27 Nov 2024
I'm recruiting PhD students for Fall 2025! CS PhD Deadline: Dec. 15th.
I work on safe/reliable ML and causal inference, motivated by healthcare applications.
Beyond myself, Johns Hopkins has a rich community of folks doing similar work! Come join us!

8
122
430
51,521
Yoav Wald retweeted

26 Nov 2024
Unpacking what's going on in our paper on Med-* foundation models & their failure to improve over their generic counterparts (think Med-{LLaMa, LLaVa} vs {LLaMa, LLaVa}. A familiar tale of motivated reasoning, sloppy eval, & hidden hyper-optimization.
arxiv.org/abs/2411.04118
14 Nov 2024

Medically adapted foundation models (think Med-*) turn out to be more hot air than hot stuff. Correcting for fatal flaws in evaluation, the current crop are no better on balance than generic foundation models, even on the very tasks for which benefits are claimed.
4
9
50
13,684
Yoav Wald retweeted

15 Nov 2024
I'm recruiting PhD students this cycle! My lab works at the intersection of information theory, cognition, language, and AI. Wanna hear more? I asked notebookLM to generate a podcast just for you (but pls take it with a big grain of salt...)
youtu.be/9L04S4jvspI
4
94
313
41,537
Yoav Wald retweeted

7 Nov 2024
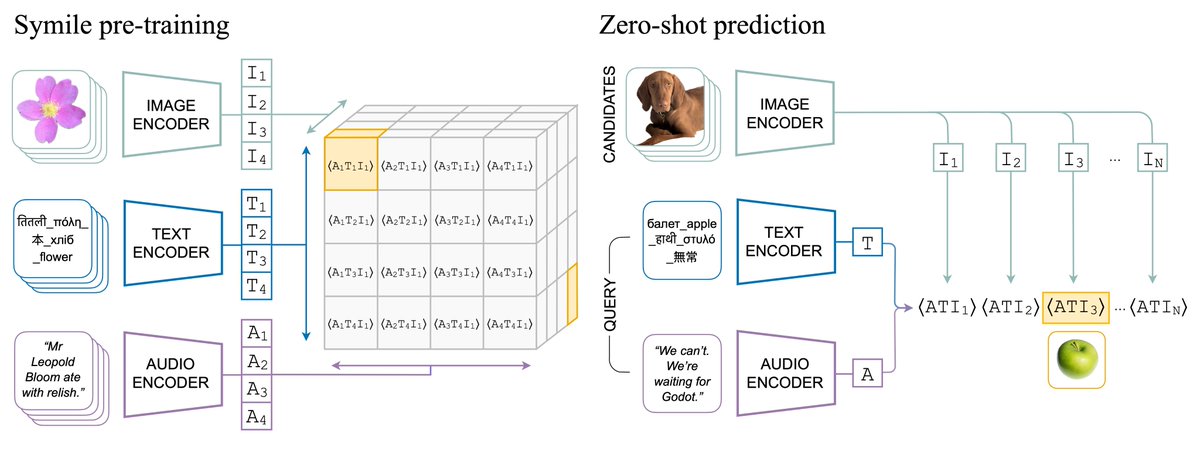
Multimodal representation learning works for 2 modalities, but what if you're working with 3 modalities, like in healthcare, robotics, or video?
📢 Meet Symile: a model-agnostic contrastive loss for any number of modalities with CLIP's simplicity and superior performance✨
1/n
6
54
188
92,971
Yoav Wald retweeted

23 Jan 2024
Will your LLM model generalize over time or across sites? How do we improve robustness? This is a key issue LLMs struggle with and especially critical as we apply these models to healthcare applications.
👇 New clever technique to improve LLM robustness and generalization. Published @NeurIPSConf w/ wonderful postdoctoral fellow @wald_yoav & superb co-authors from Columbia.
engineering.jhu.edu/news/in-…
arxiv.org/abs/2310.12803

2
5
9
2,985
13 Dec 2023
Drop by our #NeurIPS2023 poster (#910) today (Wed.) at 5PM!
We improve OOD generalization in text applications with Language Models Causal-inference-inspired data augmentation.
w/ best possible co-lead @AmirFeder , and @causalclaudia, @suchisaria, David Blei
2
6
25
5,257
13 Dec 2023
Also, better late than never, yesterday @aahladpuli presented his cool work about shortcut learning in perception tasks. Some nice insights about useful inductive biases in these tasks.
nips.cc/virtual/2023/poster/…
1
328
Yoav Wald retweeted

11 Sep 2023
a very interesting observation: all you need is perceptron 🤣
arxiv.org/abs/2308.12553
by @aahladpuli @lilyhzhang Yoav Wald & Rajesh Ranganath
4
11
94
25,180
Yoav Wald retweeted

5 Sep 2023
Thank you @ERC_Research for this amazing grant- I will
work hard (with and without the algorithms’ help) on these topics for the next few years and would love to update you with exciting results soon.
5 Sep 2023

What does algorithmic management - where software applications take on supervisory tasks in the workplace - mean for how we work?
@Zalmanson's new ERC-funded research @TelAvivUni aims to find out...
Read 👉 bit.ly/AlgoHumanBoss


7
4
67
6,204
Yoav Wald retweeted

1 Sep 2023
Once more, in verbose mode: as of today I am an Assistant Professor @WaterlooENG (ECE dept), and faculty affiliate @VectorInst and @TorontoSRI.
Please help me get the word out - I will be hiring motivated students who want to study machine learning and its societal implications

20 Jul 2023

cd ../waterloo-ece
15
25
127
29,581
3 Aug 2023
Our #UAI2023 paper is on detecting novel subgroups (aka classes/categories) when distribution of non-novel data shifts.
If this sounds interesting, or you’re wondering what it has to do with unicorns, check out our poster/paper/drop a line.
w/ @suchisaria
proceedings.mlr.press/v216/w…
1
6
37
4,155
3 Aug 2023
This comes up in monitoring safety, where novel types of data necessitates a reevaluation of existing models.
Under a "mild" assumption, we give a method bounds on detecting the novel subgroup.
6
291
Yoav Wald retweeted

29 Jul 2023
Excited to be moderating panel on generalization, scaling and safety at #icml2023 with great panelists @sleepinyourhat @zacharylipton and @Maggiemakar. Look forward to seeing folks at 15:30 room 316 at Workshop on Spurious Correlations, Invariance and Stability.
1
7
26
6,232
29 Jul 2023
Coming up next!
29 Jul 2023

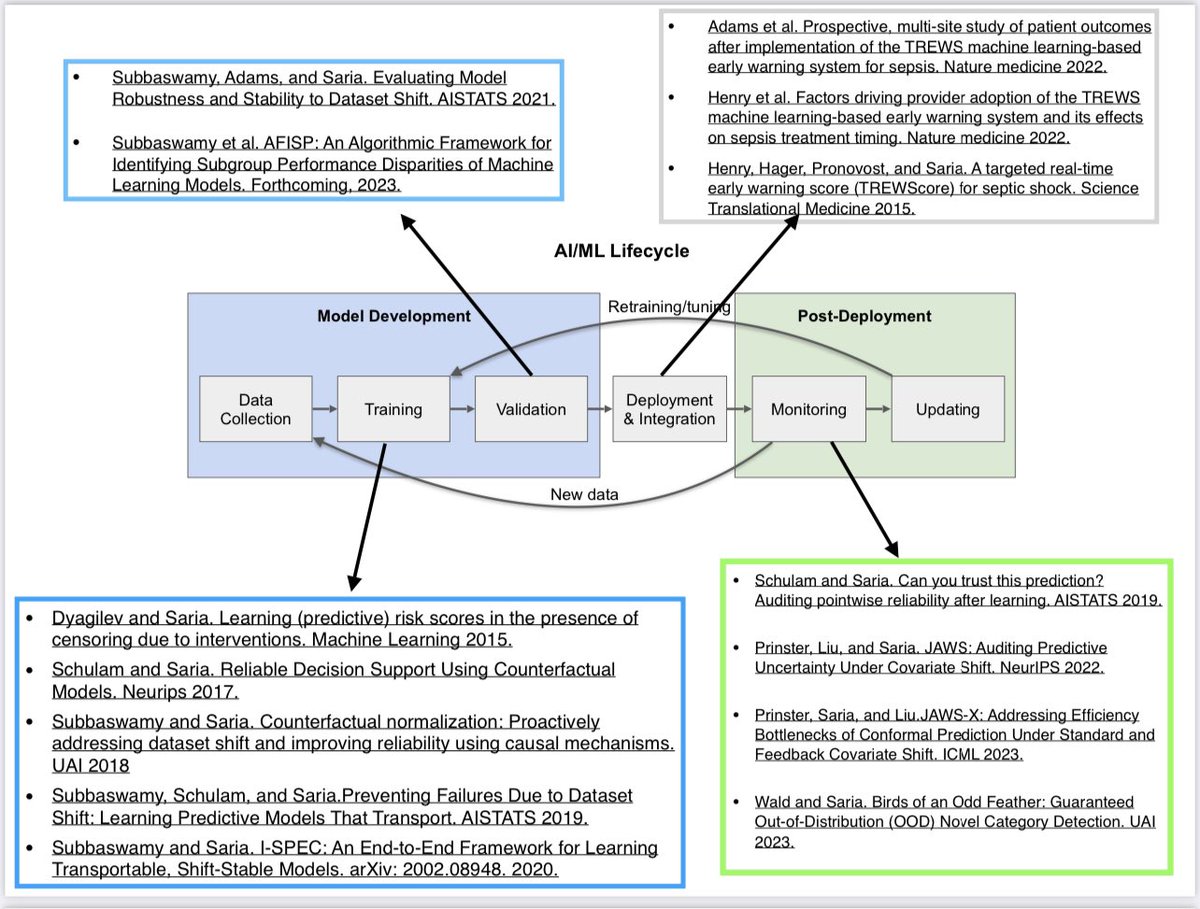
If you’re at #ICML2023 join me here: sites.google.com/view/scis-w…
Giving an invited talk later today on AI Safety.
Below are some of the papers our lab has written on the topic in last 5 yrs; this talk will give a brief overview and focus on learning/evaluation.
1
4
698
29 Jul 2023
If you're in Hawaii for #ICML2023 it's time to put down the surfboard and put on your SCIS ⛷️
Join us at rooms 316AB for our workshop on Spurious Correlations, Invariance and Stability. @FrancescoLocat8 speaking now!
1
8
42
6,786
29 Jul 2023
@causalclaudia @amir_feder @victorveitch @Maggiemakar @aahladpuli @marikgoldstein @gultchin @ShalitUri
343
Yoav Wald retweeted

22 Jun 2023
Our lab is hiring an ML in health PhD/postdoc! This is for an applied causal ML project, with very close collaboration with our university hospital - see details here*:
technionmail-my.sharepoint.c…
*due to the specific requirements of this position we need a fluent Hebrew speaker

4
27
72
12,276