
In previous lives: Director at @boomweb // Marketing Director @TheDigitalMaze // Co-creator of @DrinkDigitalUK // Described by @mrjamesob as 'very sweary'
Joined February 2010
- Tweets 30,280
- Following 1,220
- Followers 2,655
- Likes 22,189
1,702 Photos and videos











Wayne Barker - Freelance SEO, Marketing & Shit retweeted

Jun 16
Yep, drop in Google and drop in AI Search, including AIOs, AI Mode, and then downstream at AI Search platforms like ChatGPT. This is why you definitely do not want to mess around with risky tactics that can get you hammered by Google (either via manual actions or algorithm updates). Beware.
Jun 16

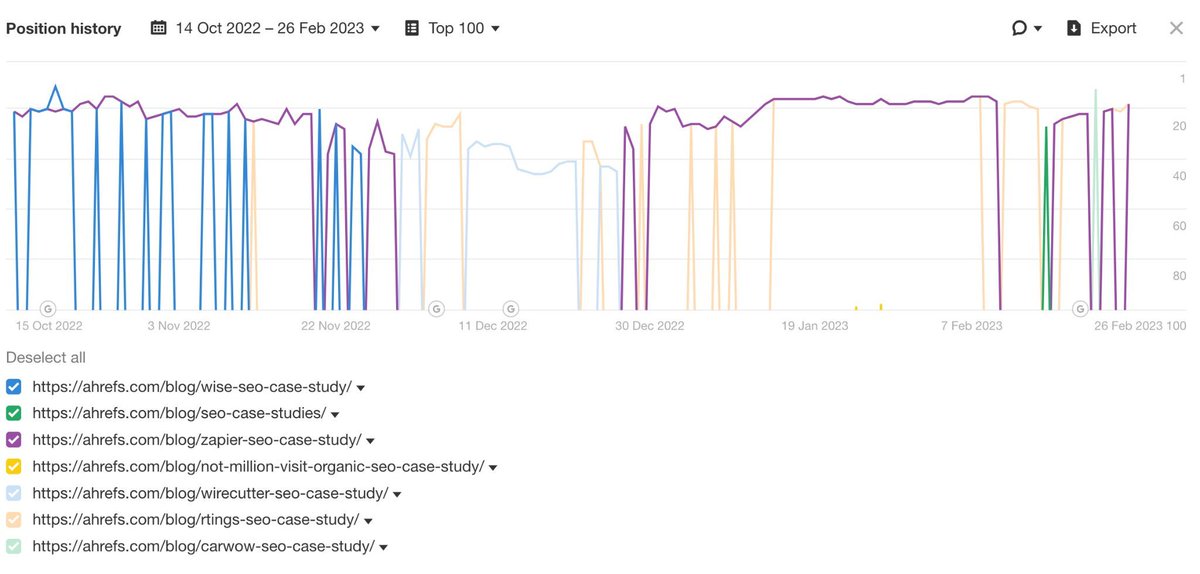
This one is an interesting case study:
When you get a manual action on Google, what's the impact on GEO?
This site's blog received a manual action on May 17 - check out the citations on AI Overviews and ChatGPT around the same time:
(Same site @glenngabe shared last week)
2
2
25
4,870

Publishers to bill AI firms for unwanted scraping - and take them to court if they don't pay // pressgazette.co.uk/news/publ…
10
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

Jun 15
I think the next frontier of spam fighting from the search/AI companies is going to hit one of the most popular page types in SEO/GEO right now: comparison and alternative pages.
These are pages on your own site that pit your brand against competitors, across the whole brand or a specific product or service (Brand X vs. Y, Product X vs. Y, [Competitor] Alternatives).
They've been making the rounds as an SEO/GEO goldmine lately, and "build a lot of these" is advice I keep hearing at conferences and reading in industry blogs and social posts.
This is similar to what I've been sharing all year with "listicles" - and I've got a new Substack piece coming out (ASAP!) on how Google and OpenAI are tuning their AI answers to lean less on brands promoting themselves. Stay tuned for that.
Comparison pages are trickier and more nuanced. There are genuine use cases for doing them well, especially at a small scale, and I've occasionally recommended them to clients in certain situations.
But like everything in SEO: once a tactic works, it becomes popular and people scale it. (File under: "this is why we can't have nice things" 🫠)
The "build these pages" advice inevitably leads folks to use AI to spin up as many as possible. I've already advised several companies that launched dozens, even hundreds of comparison/alternative pages (AKA an "SEO pattern") and ran into trouble. For example, A couple sites got hit by Google's late January update this year.
The fundamental problem: like any other "review" page, Google already has strict criteria for product reviews. The core requirement is that you prove you actually tried and tested the product, with evidence.
For a brand comparing itself to competitors, meeting that bar would mean you've hired your competitor(s) and your own company, and are authentically reviewing your honest experience using their services. How many brands can say they've actually done that? My guess is probably close to 0.
What usually ends up happening instead is brands do "research" about their competition, leaning on negative reviews of their competitors or worse - making up incorrect or untrue information to make your own offering look better than theirs.
I believe we're already seeing - and will keep seeing - Google, OpenAI and other AI companies look for "objective" 3rd party reviews* instead of leaning on biased brand content when they generate answers. This is ultimately why I think search/AI companies lean so heavily into Reddit discussions, YouTube reviews, Trustpilot, G2, and other major review sites.
(*Yes, I know these 3rd party sites are often influenced / manipulated / pay-to-play as well... so that's a big challenge for them too.)
So, as always: test, experiment, learn. But my spidey senses say that building these pages at scale - and doing it inauthentically - like trashing your competitor while calling yourself the best - is risky. When too many sites adopt these approaches, they become a liability long-term.
20
7
93
10,188
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

Jun 16
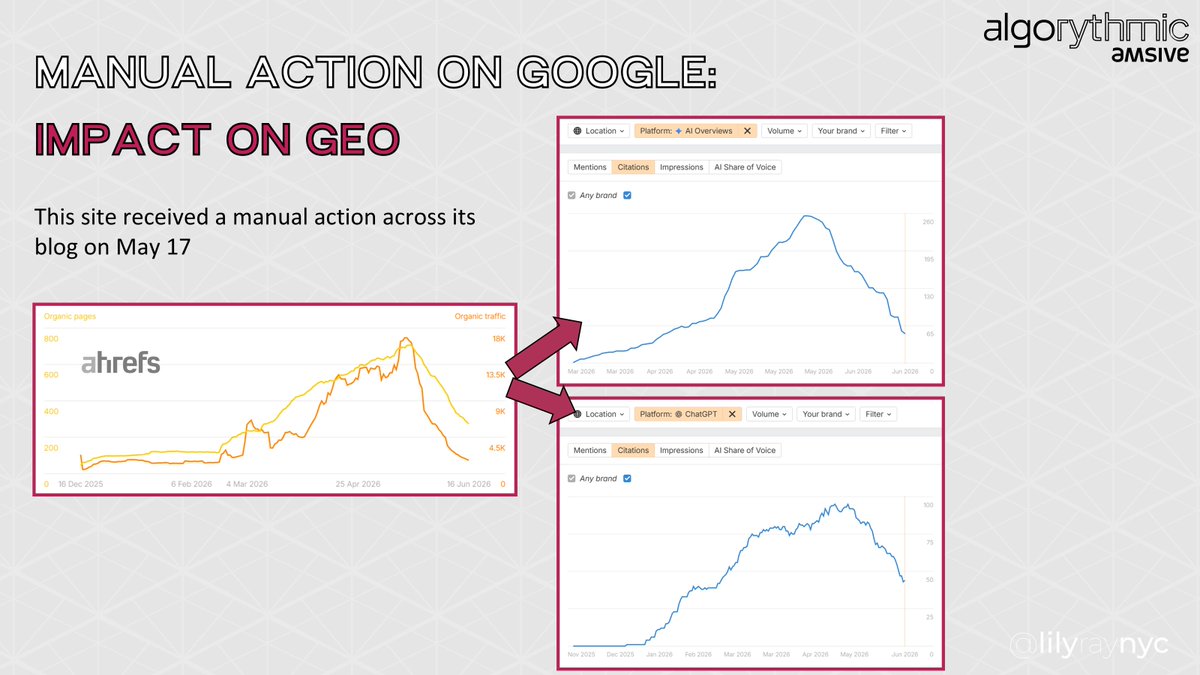
🆕🌚 regarding LLMs.txt Google clarified "It's completely fine if you decide to create and maintain LLMS.txt files (or other similar files) for other services or systems that use these files. Doing so won't harm (nor help) your visibility or rankings in Google Search, as Google Search ignores them." #SEO
searchengineland.com/google-…
7
11
42
8,849
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

Jun 15
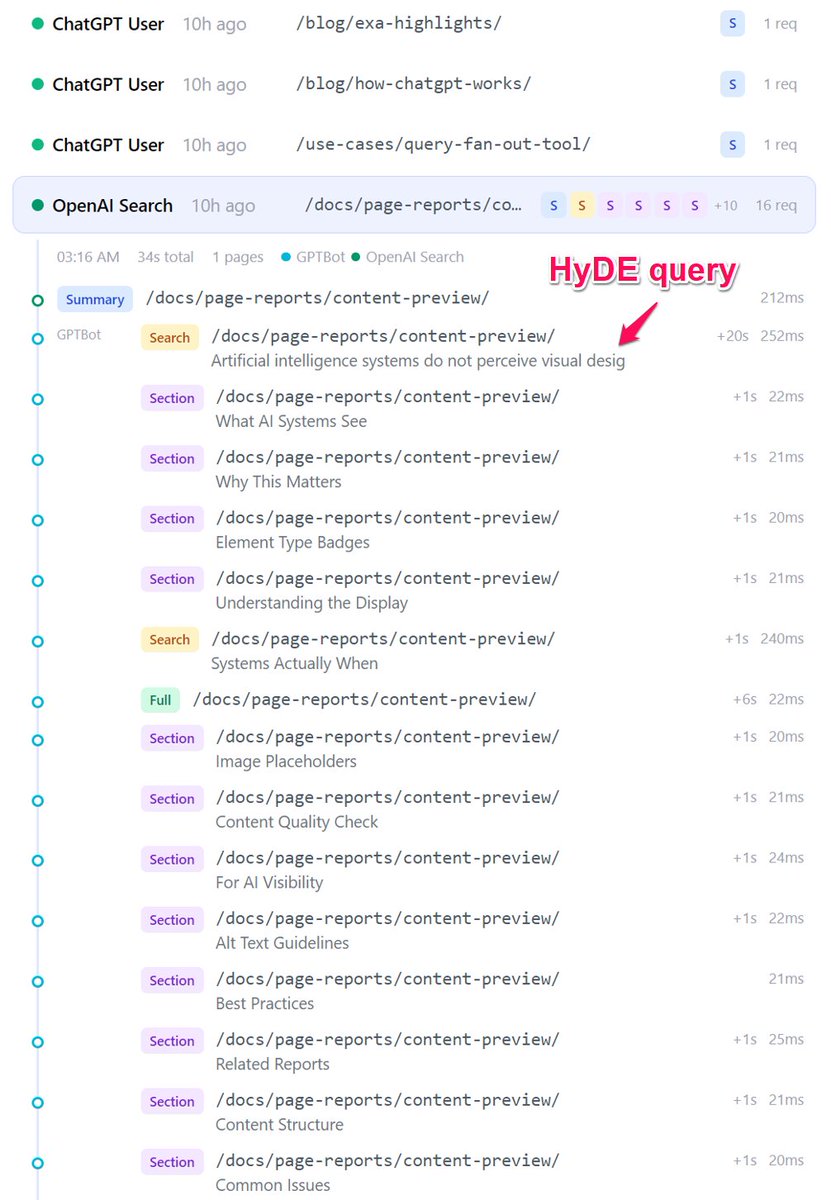
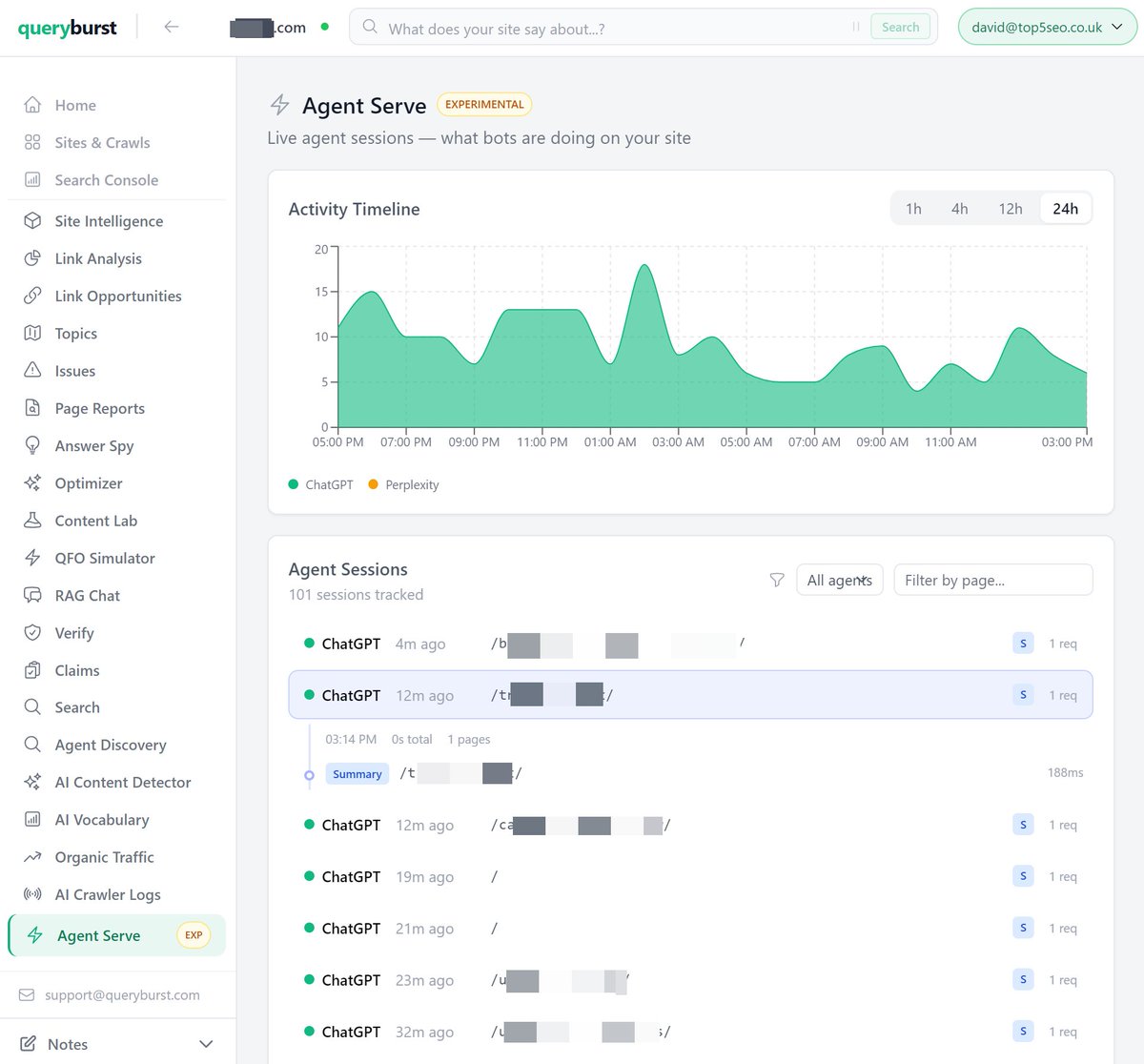
Some early takeaways from around 6,000 AI bot requests across 4 domains (see attached tweet for what I'm doing/testing).
1. ChatGPT-User doesn't appear to be able to act agentically (gets the summary, that's it) in a non-user triggered session (i.e. general, real world discovery). Can't be asserted with complete confidence, but there hasn't been a single interaction with the API as yet across all sessions. It can interact with the API if you explicitly ask it to (i.e. fetch this page, then choose a section to read), however, it's unable to construct URLs that aren't in the source, which means that it can't use the search tools.
2. OAI-Searchbot however when it gets served with a summary can either interact with the API itself, or hand over to GPTBot to continue the session (seems to be a common pattern). Both bots (or the LLMs behind them) read the instructions, then search (understanding the HyDE instruction), request sections, full content from the page etc. Note that GPTBot is not intercepted by the worker, so only gets served with the compressed content when it requests it directly (which it does).
3. All of Anthropic's bots (including Claude-User) appear to be able to act agentically in general discovery.
4. There has been no discernible change in requests from the intercepted bots (one domain is slightly up, one is slightly down, but generally it's all looking relatively flat). This is pretty much expected, aligning with my opinion that AI crawlers can read your content just fine, and counter to the messaging from certain services.
5. One other point, which I think is pretty relevant - serving markdown directly broke OpenAI's parsing, so the API returns basic HTML, which OpenAI then turns back into markdown.
Note: since this is a test, all the domains it's active on are relatively low traffic, but there's enough there to start forming some opinions on the capabilities of the various AI bots and whether there's any benefit to this.
Further note: over the next day or so I'll also start serving an Open Knowledge Format version of the (QueryBurst created) knowledge graph for these sites, with individual markdown pages for all entities. Instructions for browsing these pages/an entry point will be added to the initial response.

Jun 9

A common rhetoric in AI search is that AI systems/agents "can't read your site" and that you need to serve an "optimized" version.
In fact there was a (very) large acquisition last week for a platform that offers to do this for you.
So does serving an optimized version of your content increase citations? Or is it a load of GEO nonsense? Could it in fact harm your site?
Well, I have my opinions.
But opinions are like... (you know what), so I spent the last week or so building an "agent friendly" API and am currently serving faithful compressed summaries, with optional additional retrieval to selected user agents on a few test domains.
The "agent" gets instructions on how to use the API to request more content (full document, a specific section, search within the page). It can also search across the full site (semantic or keyword). All agent "journeys" are tracked via sessions.
Soon I'll report if:
a) there was any increase/decrease in citations/AI bot activity
b) whether the "agents" interacted with the API after getting the initial summary (so far, none of them have, but it's been live for less than 24 hours)
c) whether any of them requested the full API instructions
d) lots more... (already have some myths debunked)
On that note, if you have a site you don't mind testing things on (this to my mind isn't without risk) then let me know.
If you're a QueryBurst subscriber you actually have access to it already. But it's heavily caveated with "this is experimental - we recommend running on a test domain". I wouldn't go gung-ho and add it to your main site at the moment...
...although with that being said, for full dogfooding, one of the test domains is QueryBurst's marketing site itself.
Note: while in testing I may experiment A/B test various content formats for the initial served summary (currently it's a highly compressed 200-300 tokens). Although at all times it will be a faithful compression of what's actually on the page with nothing new injected, other than the API instructions.
Technical notes:
1. Requests are intercepted at the edge via a Cloudflare Worker. Known AI user-agents (ChatGPT-User, Claude-User, Perplexity-User etc.) are routed to a backend API that serves a compressed markdown summary (~200-300 tokens) built from the page's existing QueryBurst Site intelligence (key claims, document structure, metadata).
2. The response includes instructions and links for deeper retrieval. Full page content, specific sections by heading, page-scoped search, or site-wide semantic search. Each interaction carries a session ID so we can trace the full agent journey (did it stop at the summary? drill into a section? search for related content?).
3. Static assets are excluded at the Worker level. All responses are served sub-200ms. Human visitors see the normal site, nothing changes for them.
4. The compression is deterministic (no LLM in the serving path). It's pre-computed from our existing Site Intelligence pipeline. Nothing is invented or injected beyond factual assertions already present on the page.

1
4
20
2,128
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

Jun 15
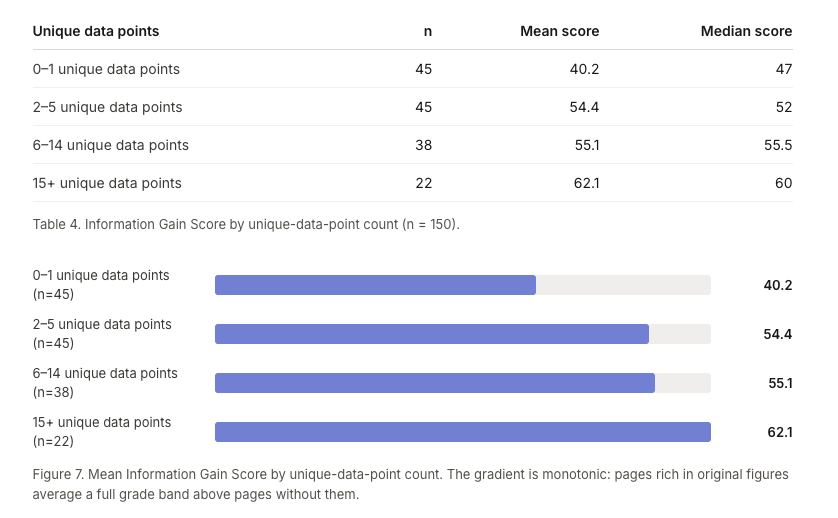
Is "Information Gain" a Google Ranking Factor?
Excellent study via @ericlancheres: how much *new information* a URL has vs its rankings
New info didn't move the needle much (but the top 3 results contained more than the rest)
Biggest ranking predictor? # of unique data points
15
15
99
7,221
BREAKING NEWS: Tech and AI gifter seen creating new marketing material for upcoming vibe-coded prompt tracker launch.
39

1
1
257
1
2
279
1
2
4
471
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

28 Nov 2024
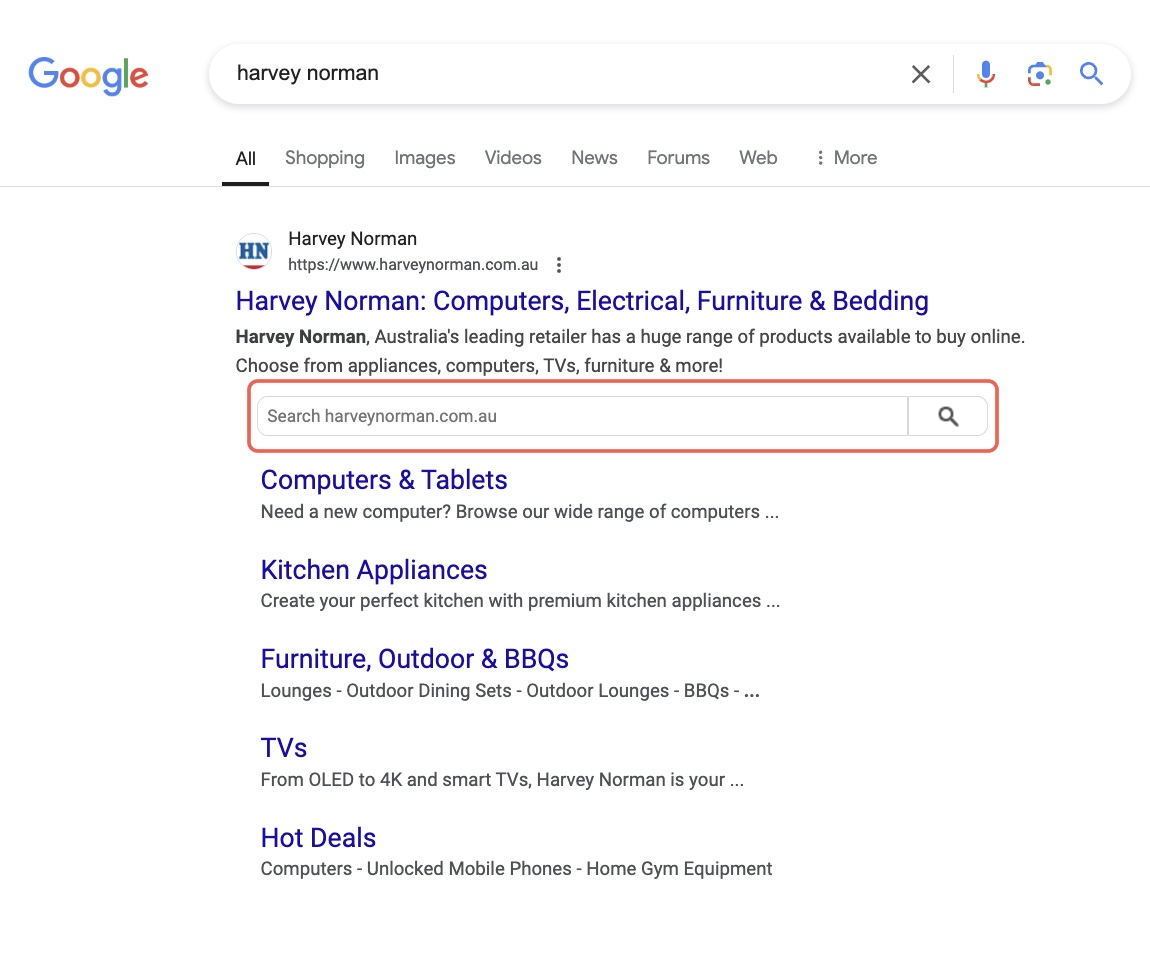
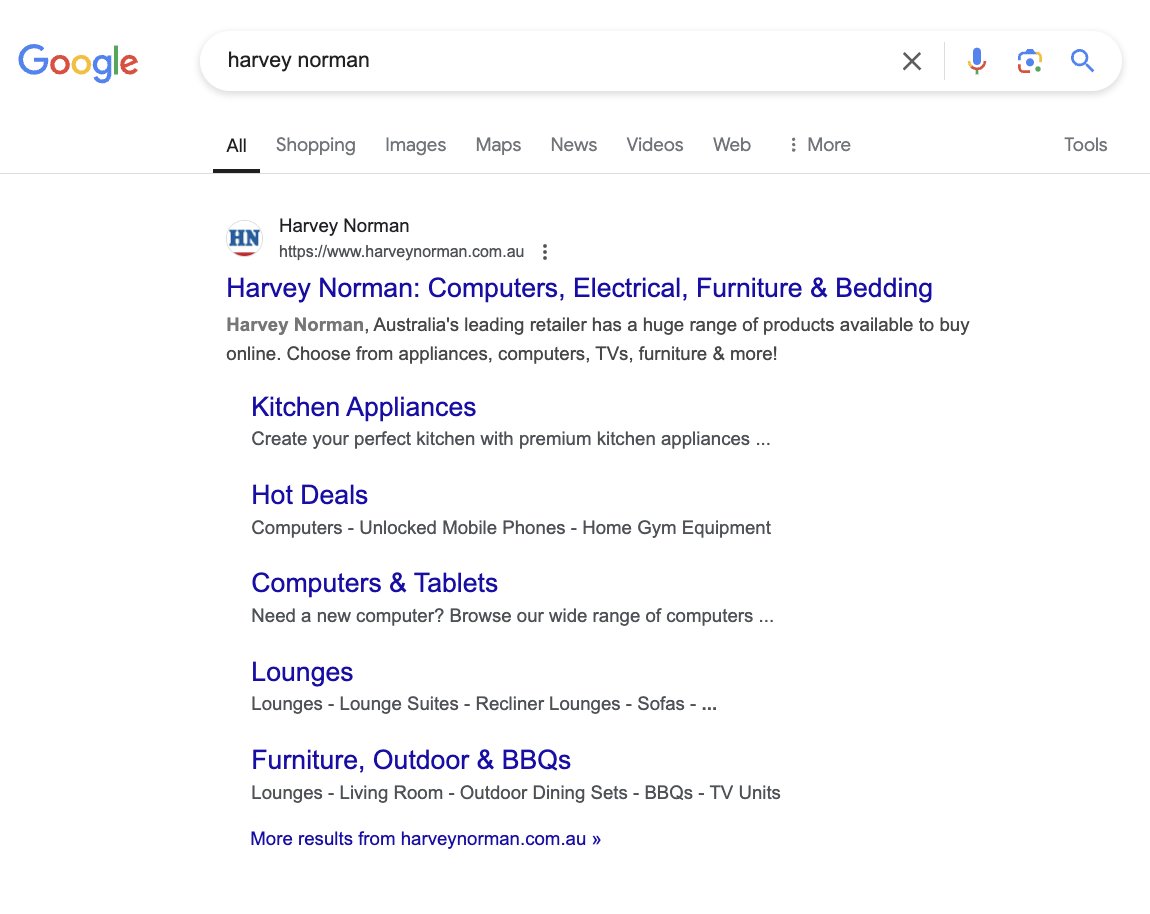
SEO News: Google has officially removed the Sitelinks Search Box feature for websites as of today.
This was a change that was announced last month and the time has arrived, where I'm now unable to see the feature appearing within the branded sitelinks extension.
It is said that usage of the feature has dropped over time which has resulted in its removal as a structured data enhancement for sites. The same goes for the report in Google Search Console and within the Rich Results Test.
As with the deprecation of most rich result features that are based on structured data, Google's advice is that there is no need to remove the markup. But if you do, just make sure that it doesn't impact other markup types on your site if you decide to go down that route.
9
36
129
11,479
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

18 Sep 2024
Introducing Google AI overviews for @keywordinsights 🌟
We’re excited to announce that Google AI overviews are now part of your clustering output. If the cluster head term triggers a Google AI overview, it will be included in your cluster visualization.
2
6
33
10,193
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

13 Sep 2024
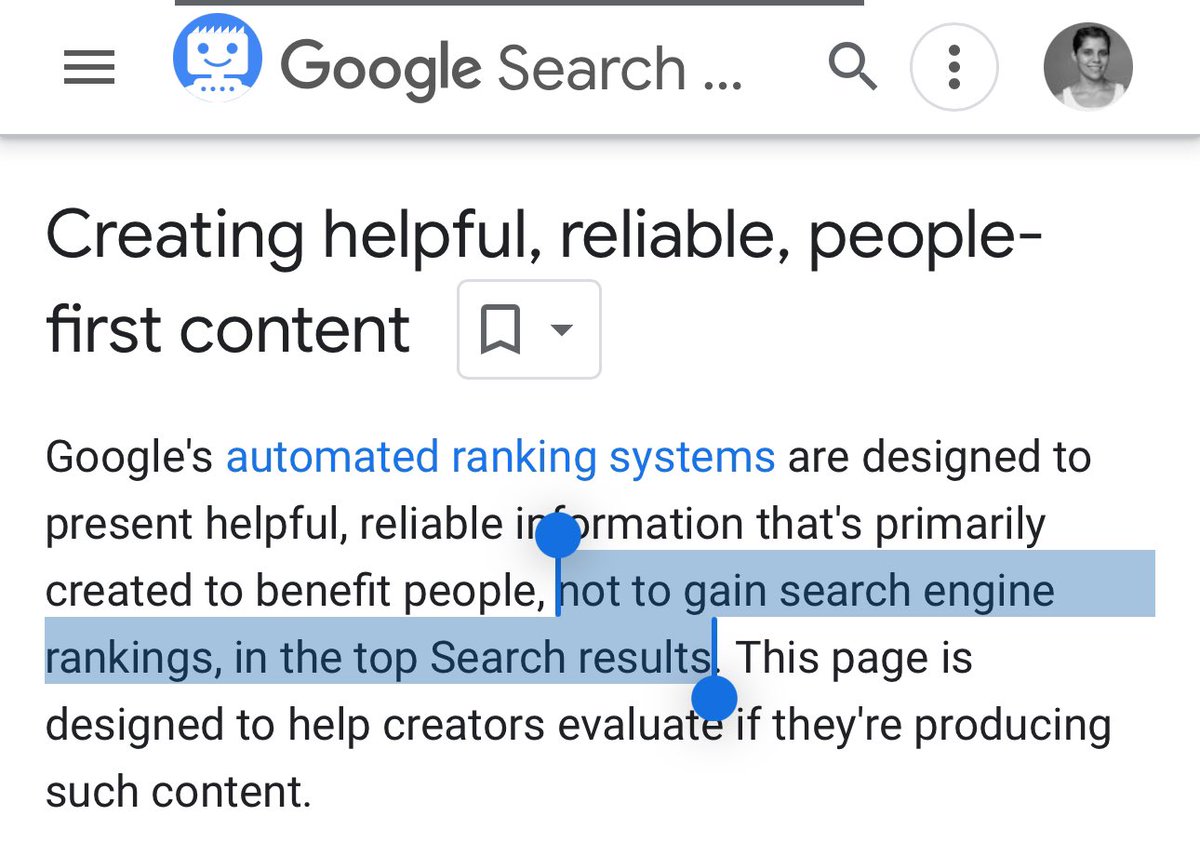
One day the DOJ will get to what’s happening in Google Search and things like this will need to be explained.
8
12
99
7,453
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

19 Aug 2024
Three days to go until @NottinghamDM 3! 💚
2
2
294
That's me in one of those pictures. I'm going to do words from my mouth in Nottingham next week if you wanna pop along. Book a ticket, like now, before they're all gone.
15 Aug 2024

It’s only ONE WEEK until we get together again for @NottinghamDM #3 💚
We’ve had the best time hosting the past two events and can’t wait to head back to The Barley Twist again on Thursday 22nd August! Will we see you there?

3
1
2
252
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

9 Aug 2024
.
Want to know how to get Traction,
fast, easy and cheap?
Us to!
The reality is - unless you're rich, already established, or well connected, it's down to time and effort.
But there are things you can do to help.
#Marketing #Business
arclite.solutions/2024/08/08…
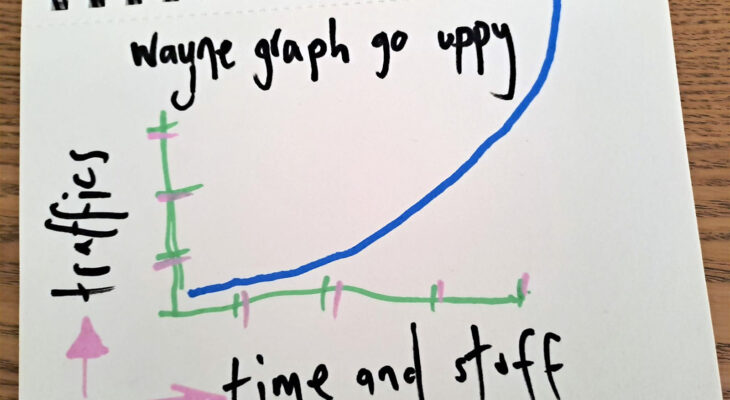
ALT Sketch of a line chart. Image unceremoniously "borrowed" from @wayneb77. A quick doodle in felt pen of a an X/Y chart. Titled: Wayne graph go uppy Y (Vertical) axis : Traffic X (Horizontal) axis : Time and stuff. Blue line sweeping along and up (like the bottom right of a circle).
2
1
229
In case you were living under a rock yesterday, we published our 2024 JavaScript SEO Report! If you want to get the lowdown quickly, here are 10 statistics from the report plus commentary by Sitebulb CEO & Co-Founder, @HathawayP.
👇
sitebulb.com/resources/guide…
#javascript #seo
3
3
214
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

1 Aug 2024
Later this month, @NottinghamDM is back for its 3rd instalment!
We’ve had the best time at the past two events and have received some absolutely lovely feedback, so we can’t wait to get together again on 22nd August. What can you expect from Nottingham DM #3? (A thread🧵)
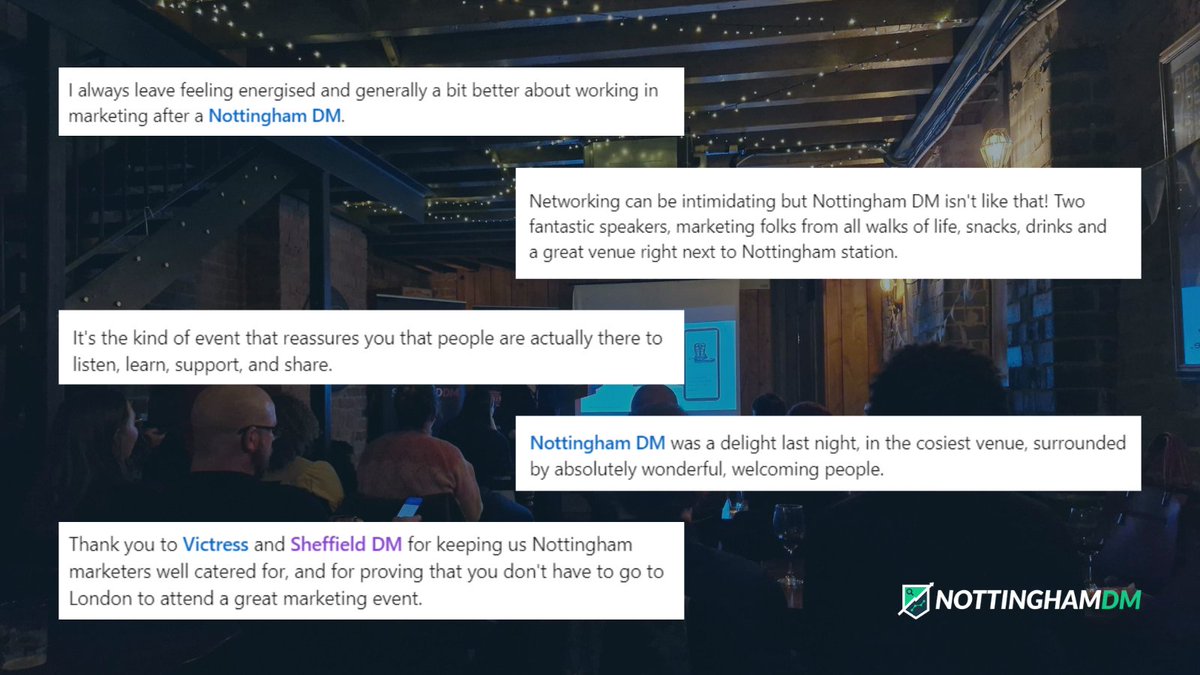
1
2
1
206
Wayne Barker - Freelance SEO, Marketing & Shit retweeted

25 Jul 2024
You can hear the sound of thousands of SEO agencies updating their pitch decks.

We’re testing SearchGPT, a temporary prototype of new AI search features that give you fast and timely answers with clear and relevant sources.
We’re launching with a small group of users for feedback and plan to integrate the experience into ChatGPT. openai.com/index/searchgpt-p…
5
3
44
3,361
Wayne Barker - Freelance SEO, Marketing & Shit retweeted
25 Jul 2024
Say Goodbye to tedious Google search console keyword management.👋
Introducing @keywordinsights Google search console integration.
✔️ Import all your keywords, not just 1000
✔️ Directly access search volumes within the tool.
✔️ Lightning-fast importing. (100k keywords in under 60 seconds)
✔️ Live tracking of rankings from the SERPs.
✔️ Apply filters to quickly narrow down your keywords.
✔️ Save valuable time, Cluster keywords instantly.
✔️ Periodically re-import new keywords to uncover fresh opportunities.

19
16
106
12,877