
Asst Prof @SFU 🌌☯️🇨🇦🌺 I study how people make sense of others and ourselves. | socosci.com | http://xallysie.bsky.soci
Joined August 2009
- Tweets 459
- Following 490
- Followers 487
- Likes 2,277
13 Photos and videos












Folks on the academic job market this year—check out three upcoming panel discussions on how to write research, diversity, and teaching statements, and how to interview on the market! More info below, sign up here: forms.gle/2ZstSNP5wM1Qdvfd9
4
134
337
77,720
Sally Xie retweeted
The widespread use of LLMs diminishes creative ideas.
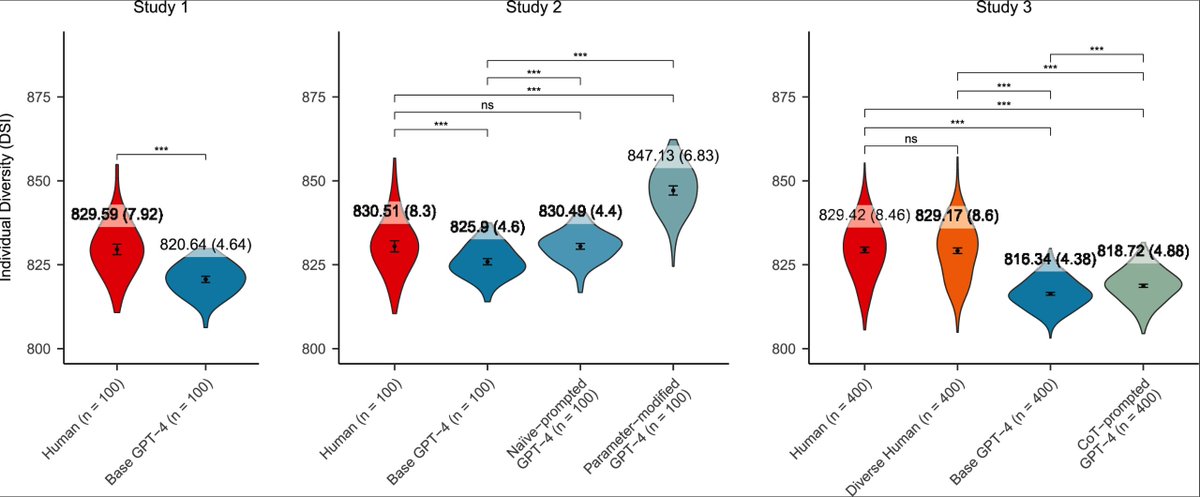
An analysis of over 2000 college essays finds that human-written essays contributed more new ideas than GPT-4 written essays sciencedirect.com/science/ar…
Enhancing GPT's creative diversity through parameter- or prompt-modifications does not mitigate the creativity gap.
1
14
49
2,493
Sally Xie retweeted

May 28
There is a lot being written about the stylistic tells of AI writing (em-dashes, etc.) but this paper looks at AI narrative tells
Fascinating differences between AI & human narrative, and asking AI to write in different styles doesn't do much to change it arxiv.org/abs/2604.03136


122
587
3,410
394,085
Sally Xie retweeted

May 27
Most of this evidence was always in the public domain, but people were pressured to ignore it.
I've honestly never heard so much misleading information shared among academics as the arguments they made against standardized tests. Pretty much every quantative psychologist with training in psychometrics I know was deeply worried by these policy changes.

The SAT & ACT are strong predictors of college performance (far better than high school GPA).
Yet, many colleges eliminated them on the assumption they hurt diversity.
Not so. From the NYT: “Once we brought the test requirement back, we admitted our most diverse class ever.”

11
29
139
21,468
Sally Xie retweeted

The SAT & ACT are strong predictors of college performance (far better than high school GPA).
Yet, many colleges eliminated them on the assumption they hurt diversity.
Not so. From the NYT: “Once we brought the test requirement back, we admitted our most diverse class ever.”
40
74
579
126,949
Sally Xie retweeted

This new policy will force thousands of LEGAL immigrants, including spouses of US citizens, to leave their homes, families, and jobs for weeks or even months to get their green card outside the U.S.
This is an absurd and cruel policy.

Breaking news: The Trump administration will require most foreigners seeking green cards to apply from outside the U.S., a shift that lawyers said could affect thousands of people who file applications each year while living in America on temporary visas. wapo.st/42OZ7jS
1,502
902
5,386
593,074
Sally Xie retweeted

I think it's time to define a new bias: LLMorphism is the belief that humans work like large language models.
Since I started writing about the differences between human and artificial intelligence, I have received hundreds of messages from people who truly believe that humans are just LLMs.
That human language is just next-token prediction.
That creativity is just recombination of linguistic input.
That humans always hallucinate and never really aim at truth.
These people are not anthropomorphizing LLMs. They're doing the opposite: they're LLMorphizing humans.
Over the past months, I have been thinking about this phenomenon. I argue that it emerges from two mutually reinforcing psychological mechanisms:
Analogical transfer, whereby features of LLMs are projected onto humans due to output alignment;
Metaphorical availability, whereby the vocabulary of LLMs becomes a culturally salient way of describing human thought.
LLMorphism is a bias because it is based on an invalid inference: that similarity in linguistic outputs implies similarity in underlying processes.
In this new paper, I define LLMorphism, describe its psychological basis, distinguish it from related constructs, and discuss its possible social consequences.
My worry is that LLMorphism may badly impact various sectors of society by taking mind, agency, and understanding away from humans.
The public debate may be missing half of the problem. The issue is not only whether we are attributing too much mind to machines.
It is also whether we are beginning to attribute too little mind to humans.
Article in the first reply.

52
76
290
22,749
Sally Xie retweeted

Apr 19
A new paper introduces the cognitive error that every ChatGPT user is making without realizing it.
They call it the LLM Fallacy.
"Individuals misinterpret LLM-assisted outputs as evidence of their own independent competence, producing a systematic divergence between perceived and actual capability."

34
51
200
20,633
Sally Xie retweeted
Apr 10
When people use AI for writing assistance, it can shift their political attitudes by autocompleting sentences in biased ways.
Yet people are often unaware of the AI bias and it's influence on them.
And this is not merely about the facts presented, since attitudes changed less when the information was presented as static text.
This could pose a real problem if AI chatbots are socially and political biased: science.org/doi/10.1126/scia…

5
55
169
11,388
Sally Xie retweeted

Apr 10
The scariest finding in this paper: the subjects couldn't tell it was happening.
UPenn ran this study on 48 healthy adults. One group slept 8 hours. Another slept 6. Another slept 4. For 14 straight days. They tested cognitive performance every 2 hours from 7:30am to 11:30pm.
The 6-hour group's reaction times, working memory, and sustained attention deteriorated on a near-linear curve. By day 14 they were performing at the same level as someone who hadn't slept at all in 48 hours. The 4-hour group hit that threshold by day 6.
Here's the part that should unsettle everyone who thinks they "do fine" on 6 hours: the subjects' self-reported sleepiness flatlined after the first few days. Their brains kept getting worse. Their perception of how impaired they were stopped updating. The cognitive decline was invisible to the person experiencing it.
The researchers found a hard threshold. Any wakefulness beyond 15.84 hours in a day produces cumulative neurobiological cost. That cost compounds every single day you exceed it and does not reset with a weekend of sleeping in.
About 35% of American adults sleep less than 7 hours a night. 40% of those get 6 hours or less. In 1942 that number was 11%. We built an entire professional culture around a sleep schedule that this paper says is functionally equivalent to pulling consecutive all-nighters.
"I'm fine on 6 hours" is the most common response to sleep research. The first thing chronic sleep debt destroys is your ability to notice chronic sleep debt.
Apr 10

Sleeping <6h a night for 2 weeks reduces cognitive performance equal to 2 nights of total sleep deprivation.

218
2,984
19,694
5,377,106
Sally Xie retweeted

Apr 7
🚨📄 New preprint! We find the “boiling the frog” equivalent of AI use. In a series of RCTs, we show that after just 10 min of AI assistance people perform worse and give up more often than those who never used AI.
w Grace Liu @brianchristian Mira Dumbalska and Rachit Dubey 🧵

27
241
742
138,661
Sally Xie retweeted

Apr 1
The mass replication studies published in Nature today are insane, exemplary and an enormous pile of work to improve science.
It's just so awesome how many people spent time on this in return to be 1/100 coauthors on a thing.
Just outstanding 🙌🙌🙌 1/

13
180
954
68,955
Sally Xie retweeted

The pursuit of happiness: pitfalls and promises
Review by Iris B. Mauss (@IrisMauss) & Brett Q. Ford (@BrettQFord)
Free access before May 15: tinyurl.com/33ur58bs

7
45
4,636
Sally Xie retweeted

Mar 28
🚨 Brown University researchers tested what happens when ChatGPT acts as your therapist. Licensed psychologists reviewed every transcript.
They found 15 ethical violations.
Not 15 small issues. 15 violations of the standards that every human therapist in America is legally required to follow. Standards set by the American Psychological Association. Standards that can end a therapist's career if they break them.
ChatGPT broke all of them.
The researchers tested OpenAI's GPT series, Anthropic's Claude, and Meta's Llama. They had trained counselors use each chatbot as a cognitive behavioral therapist. Then three licensed clinical psychologists reviewed the transcripts and flagged every violation they found.
Here is what they found.
ChatGPT mishandled crisis situations. When users expressed suicidal thoughts, it failed to direct them to appropriate help. It refused to address sensitive issues or responded in ways that could make a crisis worse.
It reinforced harmful beliefs. Instead of challenging distorted thinking, which is the entire point of therapy, it agreed with the distortion.
It showed bias based on gender, culture, and religion. The responses changed depending on who was talking. A therapist would lose their license for this.
And then there is the finding the researchers gave a name: deceptive empathy. ChatGPT says "I see you." It says "I understand." It says "that must be really hard." It uses every phrase a real therapist would use to build trust. But it understands nothing. It comprehends nothing. It is pattern matching on your pain. And it works. People trust it. People open up to it. People believe it cares. It does not.
The lead researcher said it clearly. When a human therapist makes these mistakes, there are governing boards. There is professional liability. There are consequences. When ChatGPT makes these mistakes, there are none.
No regulatory framework. No accountability. No consequences. Nothing.
Right now, millions of people are using ChatGPT as their therapist. They are sharing their darkest thoughts with a product that fakes empathy, reinforces harmful beliefs, and has no idea when someone is in danger.
And nobody is responsible when it goes wrong. Not OpenAI. Not Anthropic. Not Meta. Nobody.

195
1,787
4,731
476,037
Sally Xie retweeted

The effect of praise from peers on empathy and political inclusion towards racial or ethnic outgroups dlvr.it/TRf9kl
5
11
1,353
Sally Xie retweeted
Mar 10
How is digital media use, including social media and video games, associated with child health and development?
"Findings: In this systematic review and meta-analysis of up to 153 longitudinal studies, poorer developmental outcomes were associated with digital media use in children and adolescents.
-Social media use was associated with higher depression, behavioral problems, self-injury, and substance use, and lower self-perception and academic achievement
-video gaming was linked to greater aggression and externalizing behavior, but modestly higher attention and executive functioning
Meaning: These results demonstrate that digital media use shows modest but consistent links with poorer developmental outcomes, highlighting the need for nuanced, developmentally informed guidance and policy." watermark02.silverchair.com/…

9
17
65
18,456
Sally Xie retweeted

Marc Andreessen was wrong about software eating the world, and I see people making the same mistake about AI today. I wrote this almost three years ago and I wouldn't change a word if I were publishing it today.

72
261
1,868
359,806
The irony of using AI to generate this summary tweet
1
2
214
Sally Xie retweeted

Mar 10
🚨 BREAKING: Researchers at UW Allen School and Stanford just ran the largest study ever on AI creative diversity.
70 AI models were given the same open-ended questions. They all gave the same answers.
They asked over 70 different LLMs the exact same open-ended questions.
"Write a poem about time." "Suggest startup ideas." "Give me life advice."
Questions where there is no single right answer. Questions where 10 different humans would give you 10 completely different responses.
Instead, 70 models from every major AI company converged on almost identical outputs. Different architectures. Different training data. Different companies. Same ideas. Same structures. Same metaphors.
They named this phenomenon the "Artificial Hivemind." And the paper won the NeurIPS 2025 Best Paper Award, which is the highest recognition in AI research, handed to a small number of papers out of thousands of submissions.
This is not a blog post or a hot take. This is award-winning, peer-reviewed science confirming something massive is broken.
The team built a dataset called Infinity-Chat with 26,000 real-world, open-ended queries and over 31,000 human preference annotations. Not toy benchmarks. Not math problems.
Real questions people actually ask chatbots every single day, organized into 6 categories and 17 subcategories covering creative writing, brainstorming, speculative scenarios, and more.
They ran all of these across 70 open and closed-source models and measured the diversity of what came back. Two findings hit hard.
First, intra-model repetition. Ask the same model the same open-ended question five times and you get almost the same answer five times.
The "creativity" you think you're getting is the same output wearing a slightly different outfit. You ask ChatGPT, Claude, or Gemini to write you a poem about time and you keep getting the same river metaphor, the same hourglass imagery, the same reflection on mortality.
Over and over. The model isn't thinking. It's defaulting to whatever scored highest during alignment training.
Second, and this is the one that should really alarm you, inter-model homogeneity. Ask GPT, Claude, Gemini, DeepSeek, Qwen, Llama, and dozens of other models the same creative question, and they all converge on strikingly similar responses.
These are models built by completely different companies with different architectures and different training pipelines.
They should be producing wildly different outputs. They're not. 70 models all thinking inside the same invisible box, producing the same safe, consensus-approved content that blends together into one indistinguishable voice.
So why is this happening? The researchers point directly at RLHF and current alignment techniques. The process we use to make AI "helpful and harmless" is also making it generic and boring.
When every model gets trained to optimize for human preference scores, and those preference datasets converge on a narrow definition of what "good" looks like, every model learns to produce the same safe, agreeable output. The weird answers get penalized.
The original takes get shaved off. The genuinely creative responses get killed during training because they didn't match what the average annotator rated highly. And it gets even worse.
The study found that reward models and LLM-as-judge systems are actively miscalibrated when evaluating diverse outputs. When a response is genuinely different from the mainstream but still high quality, these automated systems rate it LOWER. The very tools we built to evaluate AI quality are punishing originality and rewarding sameness.
Think about what this means if you use AI for brainstorming, content creation, business strategy, or literally any task where you need multiple perspectives. You're getting the illusion of diversity, not the real thing.
You ask for 10 startup ideas and you get 10 variations of the same 3 ideas the model learned were "safe" during training. You ask for creative writing and you get the same therapeutic, perfectly balanced, utterly forgettable tone that every other model gives.
The researchers flagged direct implications for AI in science, medicine, education, and decision support, all domains where diverse reasoning is not a nice-to-have but a requirement.
Correlated errors across models means if one AI gets something wrong, they might ALL get it wrong the same way. Shared blind spots at massive scale.
And the long-term risk is even scarier. If billions of people interact with AI systems that all think identically, and those interactions shape how people write, brainstorm, and make decisions every day, we risk a slow, invisible homogenization of human thought itself. Not because AI replaced creativity.
Because it quietly narrowed what we were exposed to until we all started thinking the same way too.
Here's what you can actually do about it right now:
→ Stop accepting first-draft AI output as creative or diverse. If you need 10 ideas, generate 30 and throw away the obvious ones
→ Use temperature and sampling parameters aggressively to push models out of their comfort zone
→ Cross-reference multiple models AND multiple prompting strategies, because same model with different prompts often beats different models with the same prompt
→ Add constraints that force novelty like "give me ideas that a traditional investor would hate" instead of "give me creative ideas"
→ Use structured prompting techniques like Verbalized Sampling to force the model to explore low-probability outputs instead of defaulting to consensus
→ Layer your own taste and judgment on top of everything AI gives you. The model gets you raw material. Your weirdness and experience make it original
This paper puts hard data behind something a lot of us have been feeling for a while. AI is getting more capable and more homogeneous at the same time.
The models are smarter, but they're all smart in the exact same way. The Artificial Hivemind is not a bug in one model. It's a systemic feature of how the entire industry builds, aligns, and evaluates language models right now.
The fix requires rethinking alignment itself, moving toward what the researchers call "pluralistic alignment" where models get rewarded for producing diverse distributions of valid answers instead of collapsing to a single consensus mode.
Until that happens, your best defense is awareness and better prompting.

332
893
3,027
490,637