
machine learning, reinforcement learning, programming languages, handstands (he/him)
Joined June 2009
- Tweets 2,567
- Following 1,015
- Followers 3,787
- Likes 7,851
153 Photos and videos









Pinned Tweet

5 Nov 2016
When you say, "This is a reinforcement learning problem," you should say it with the same excitement as "This is NP-hard."
7
37
224
Tim Vieira retweeted

May 28
@ReviewAcl Why does every author have to fill out the registration form if they already have an OpenReview profile?
2
4
23
2,356
Tim Vieira retweeted

May 14
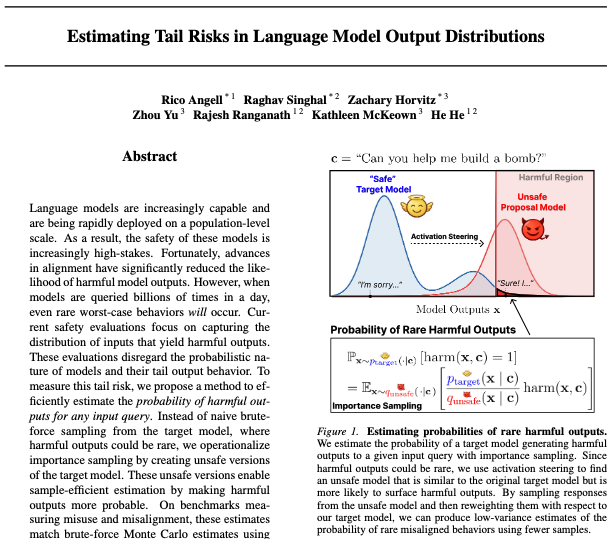
It’s deployment time!
You’ve done the pre-deployment evals. You THINK your model is safe, so you ship it 🚀
🚨 After deployment, reports of misbehavior start trickling in
What happened?? How could you have caught it?? 🤔
@icmlconf 2026 Spotlight!
🧵
3
23
100
15,856
Tim Vieira retweeted

Our paper "Autoregressive Language Models are Secretly Energy-Based Models: Insights into the Lookahead Capabilities of Next-Token Prediction" was accepted for publication at #ICML2026 arxiv.org/abs/2512.15605
2
25
182
14,079
Tim Vieira retweeted

Apr 20
We made LLM inference a lot faster.
1/n
Speculative decoding throws away draft tokens when they don't match. What if you re-weighted your samples instead using importance sampling?
We introduce SMC-SD, sequential Monte Carlo speculative decoding, an approximate sampler that speeds up inference by 2.36× over SOTA speculative decoding, while producing a controllable Pareto frontier of speed and approximation accuracy.
ArXiv: arxiv.org/abs/2604.15672
minimal repo release: github.com/abdelfattah-lab/s…
Joint work with Mauricio Barba da Costa (@mauricio_b25181), Chi-Chih Chang (@CCCCC1009CCC ), Cameron Freer, Tim Vieira (@xtimv), Ryan Cotterell, and Mohamed Abdelfattah (@mohsaied).
7
24
150
22,241
Apr 3
Claude Code is really bad at f-strings. I can't tell you how many times a day I see some version of this error message a day. Please fix!
1
2
493
Apr 2
Some more vibe-coding fun - every math major's favorite party trick: the wobbly table theorem as an interactive 3D visualization.
timvieira.github.io/table-th…
1
7
422
Apr 1
Ok, AI-assisted coding is pretty rad. Here's something I built to explore the stuff I've written (blog posts and publications). It's still a bit of work in progress, but it's pretty fun, especially the "semantic" tab sliders.
I'd love some feedback!
timvieira.github.io/experime…
2
9
518
Mar 13
I built an interactive JavaScript thingy to study the two faces of KL divergence.
timvieira.github.io/blog/int…
I have wanted this since 2009. Thank you, Claude Code, for helping me get there!
3
9
53
7,968
Mar 13
It's pretty addictive to play with. You can drag the bumps around and /- them. It currently only supports single-model approximators.
1
2
466
Tim Vieira retweeted

Congratulations to our researchers (including @leoduw and alum @xtimv) on winning an Outstanding Paper Award at the most recent @COLM_conf! Learn more about their award-winning paper here: cs.jhu.edu/news/hopkins-comp…

ALT COLM logo.
4
3
591
Tim Vieira retweeted

Jan 26
Claude Chic: A Claude drop-in with updated UX and multi-agent support.
Also what I've been obsessively building the last two weeks 🙂. Enjoy!
matthewrocklin.com/introduci…
3
3
19
2,663

Congrats to @adveisner and @leoduw on their Outstanding Paper at COLM 2025! 🎉
Extra shoutout to @xtimv and Ryan — both proud @jhuclsp alums — for co-authoring this amazing work led by @ben_lipkin and Ben LeBrun. 👏

2
9
40
4,440
Tim Vieira retweeted

7 Oct 2025
Good morning @COLM_conf! Excited to present our poster on Self-Steering LMs (#50, 11AM-1PM). If you’re thinking about codegen, probabilistic inference, or parallel scaling, stop by for a chat!

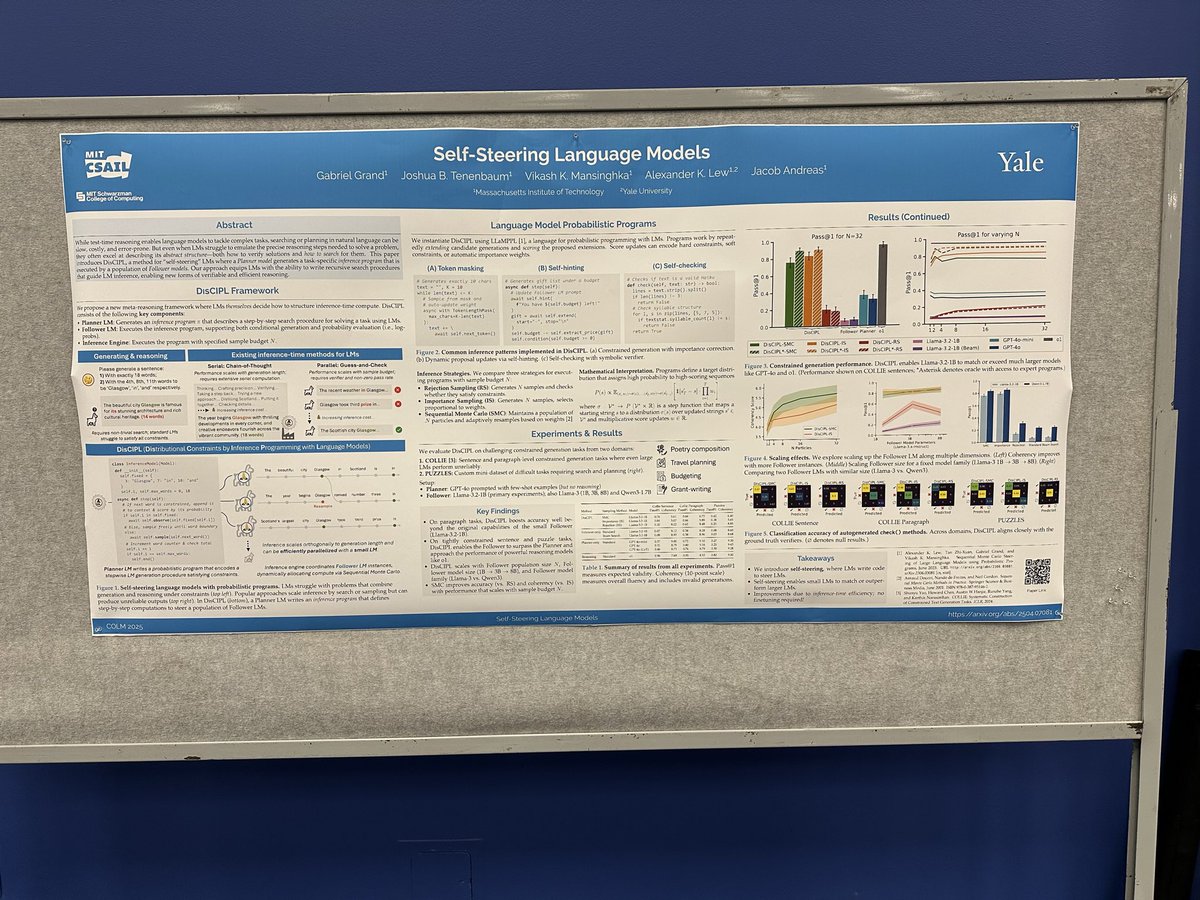
7
46
3,800
Tim Vieira retweeted

6 Oct 2025
Having a hard time controlling your LM? Want a fast approach to get high-quality constraint-satisfying generations?
Come to COLM tomorrow morning to learn about our new decoding algorithm!
Oral spotlight @ 10:15-10:30am
Poster #49 @ 11:00am-1:00pm
13 May 2025

Many LM applications may be formulated as targeting some (Boolean) constraint.
Generate a…
- Python program that passes a test suite
- PDDL plan that satisfies a goal
- CoT trajectory that yields a positive reward
The list goes on…
How can we efficiently satisfy these? 🧵👇
1
1
12
2,119
Tim Vieira retweeted

7 Oct 2025
Outstanding paper 🏆 1: Fast Controlled Generation from Language Models with Adaptive Weighted Rejection Sampling
openreview.net/forum?id=3BmP…

2
10
59
18,648
Tim Vieira retweeted
7 Oct 2025
Thanks to everyone at COLM for the awesome discussions so far and to the amazing team that made this paper happen :)
Ben LeBrun @postylem @JoaoLoula @DRMacIver @leoduw @adveisner Ryan Cotterell @vmansinghka Tim O'Donnell @alexanderklew @xtimv
7 Oct 2025

Outstanding paper 🏆 1: Fast Controlled Generation from Language Models with Adaptive Weighted Rejection Sampling
openreview.net/forum?id=3BmP…
1
8
41
8,008
Tim Vieira retweeted

20 Sep 2025
Excited to share that this paper has been accepted to #NeurIPS2025 main track 🎉!
6 May 2025

Current KL estimation practices in RLHF can generate high variance and even negative values! We propose a provably better estimator that only takes a few lines of code to implement.🧵👇
w/ @xtimv and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb

2
26
2,980


18 Aug 2025
Is there a name for the following effect?
There exists a cognitive bias whereby the perceived reliability of an argument increases with its presentation quality, leading to a decrease in verification effort.
1
4
671
Tim Vieira retweeted

2 Aug 2025
Has anyone tried running AI models (CNNs/LLMs, ViTs/ Diffusion) on weird chips? Edge: Qualcomm AR1, Ambarella, TensTorrent Cloud: Trainium, Inferentia, AMD Or even just porting Ampere → Hopper → Blackwell? Curious: how painful was it? Did it kill your project before it started?
3
7
1,726