
13 Photos and videos






rurounigit retweeted

One robot. One API. Run your AI app on the robot, your laptop, or a Hugging Face Space locally or remotely, in Python or the browser.
Full breakdown of Reachy Mini's media stack → huggingface.co/blog/pollen-r…
2
7
421
rurounigit retweeted

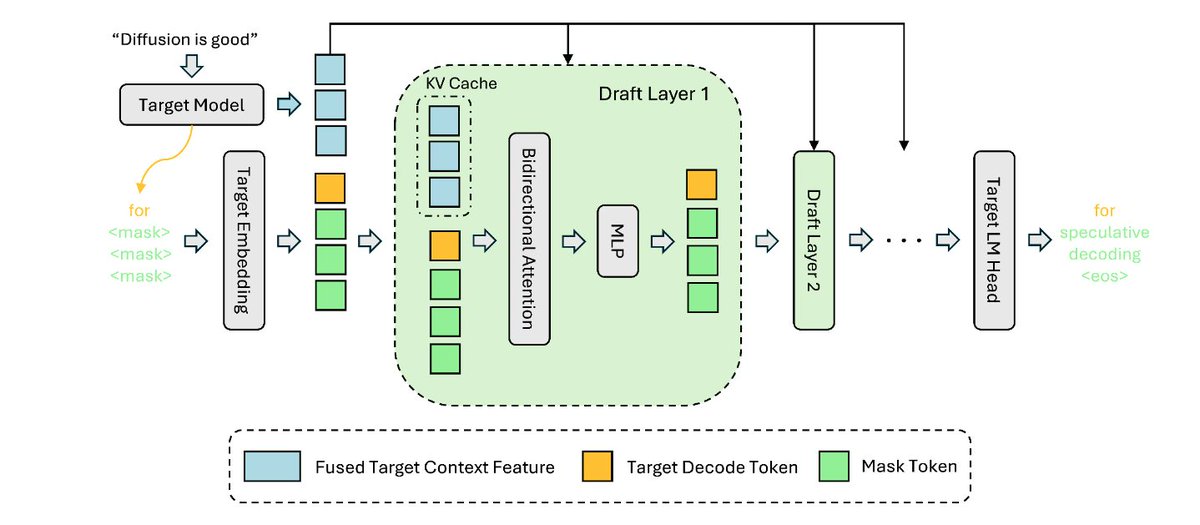
So glad DFlash landed in SGLang's new default Spec V2 engine — block-diffusion drafting KV injection, now available to everyone serving on SGLang.
Huge thanks to @modal and @sgl_project for the engine integration support!

🚀 New blog: The next generation of speculative decoding: DFlash and Spec V2
DFlash Spec V2 hit >4.3X baseline throughput for LLM inference, now the default speculative decoding engine in SGLang! Together with @modal and z-lab.ai, our jointly-released DFlash drafter for Qwen 3.5 397B-A17B beats both baseline and native MTP in every setting we benchmarked:
1️⃣ >4.3X baseline & 1.5X native MTP throughput (concurrency 1, HumanEval, 8xB200)
2️⃣ Block diffusion drafter: a full token block in one forward pass
3️⃣ KV injection: target-model features fed into every draft layer’s KV cache for higher acceptance
4️⃣ Spec V2 overlap scheduler: 33% end-to-end
Read the code, deploy a DFlash server, and start experimenting!
1
11
120
9,571
rurounigit retweeted

Jun 13
Made some improvements on the decode path for MiniMax M3 by @MiniMax_AI on MLX-VLM
Faster decode, slightly lighter footprint.
Thanks to @ivanfioravanti for the PR 🚀
PR:
github.com/Blaizzy/mlx-vlm/p…

Jun 13

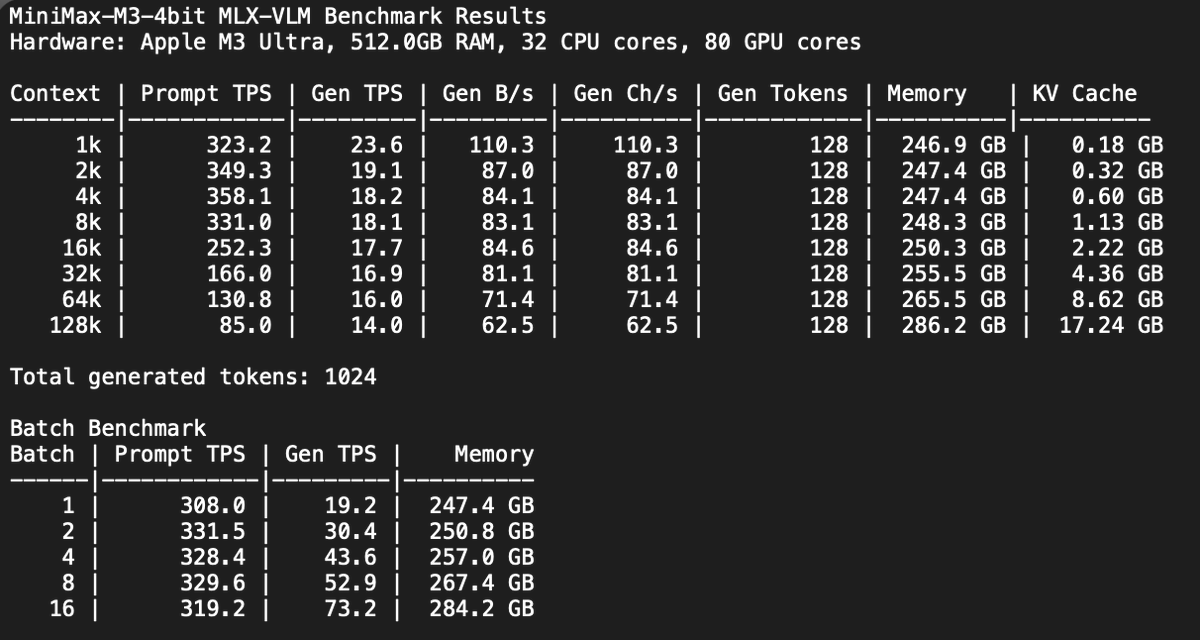
MiniMax M3 4bit mlx-vlm preliminary context benchmark!
Hardware: Apple M3 Ultra, 512GB RAM, 32 CPU cores, 80 GPU cores
In the comparison you can see the new version of the PR focused on performance (WIP but PR already contains it).
I'm also experimenting with a way to track bytes/chars generated independently from tokenizers. Because I want to find a better way to measure real output text generated 🧐
1k pp 323 tg 24 t/s mem 246.9GB kv 0.18GB
2k pp 349 tg 19 t/s mem 247.4GB kv 0.32GB
4k pp 358 tg 18 t/s mem 247.4GB kv 0.60GB
8k pp 331 tg 18 t/s mem 248.3GB kv 1.13GB
16k pp 252 tg 18 t/s mem 250.3GB kv 2.22GB
32k pp 166 tg 17 t/s mem 255.5GB kv 4.36GB
64k pp 131 tg 16 t/s mem 265.5GB kv 8.62GB
128k pp 85 tg 14 t/s mem 286.2GB kv 17.24GB
Total generated tokens: 1024
Batch TPS: b1 19 b2 30 b4 44 b8 53 b16 73

7
6
85
33,201
rurounigit retweeted

Jun 13
Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

692
1,753
14,761
5,910,554

GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
260
770
7,447
930,953

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
360
995
8,338
2,496,543
rurounigit retweeted

I just published One Metal kernel made Apple Core AI’s MoE decode 2–3.6× faster — same quality medium.com/p/one-metal-kerne…
2
9
100
14,453
rurounigit retweeted

Jun 13
Thanks for all the feedback. GLM-5.2 will begin rolling out to all Coding Plan users in 3 hours.
Jun 13

Help us shape the next GLM release: what should we prioritize most?
135
115
1,784
292,352



In light of the US government banning Fable for non US people (and Anthropic pulling it off cc)
It’s more and more important that we develop systems that can’t be shut down, nor taken away.
I’m grateful I got a glimpse of the future, I hope I get to spend more time with it

35
102
920
28,433
rurounigit retweeted

Jun 13
great fucking job, Anthropic
incredible fear-mongering
fuck progress, fuck science, fuck technology
fuck the whole world except for US
let's all go to the stone age together
186
268
6,335
232,639
Minimax-M3 is out!!!!!!!
Good job on the Minimax team for making another banging open weight model.
I knew it’d be 400B~ now to get it running
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
12
5
365
23,182
rurounigit retweeted

Jun 11
1 Billion Gaussians (1,035,804,128 exactly) streaming to the viewer at 60fps (vsync) and 5GB VRAM.
There is no limit anymore to how much it can do.
Some need a billion dollar corp to make similar things happen, others need paid pseudo influencers without skills and knowledge to make your software look bad because someone is shitting his pants.
LichtFeld Studio is a product of love and passion. So help support this project by donating to it.
1B training on a single RTX 4090 will fall next.
Ply -> rad took 28min which is not optimized yet. There is in general some more room for optimization.
The dataset is just a 2x2 tile provided by:
3D scanning data created and provided by Andrii Shramko, TELEPORTOUR.
Links in comment to the dataset provider!
13
36
378
31,453
rurounigit retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


623
1,658
13,849
2,373,969
rurounigit retweeted

Jun 10
Everyone, please join Project Tapestry
thealliance.ai/projects/tape…
45
165
1,121
432,812
rurounigit retweeted

just bring back gemini-2.5-pro-exp-03-25 release. That version would follow user instructions to the letter, never have any amnesia, and do amazing things over long context. that was gemini fable.
3
1
20
1,385
rurounigit retweeted

Jun 9
how can you praise this model as an AI researcher?

9
8
347
9,468
rurounigit retweeted
Jun 3
Already on MLX 🚀
Jun 3

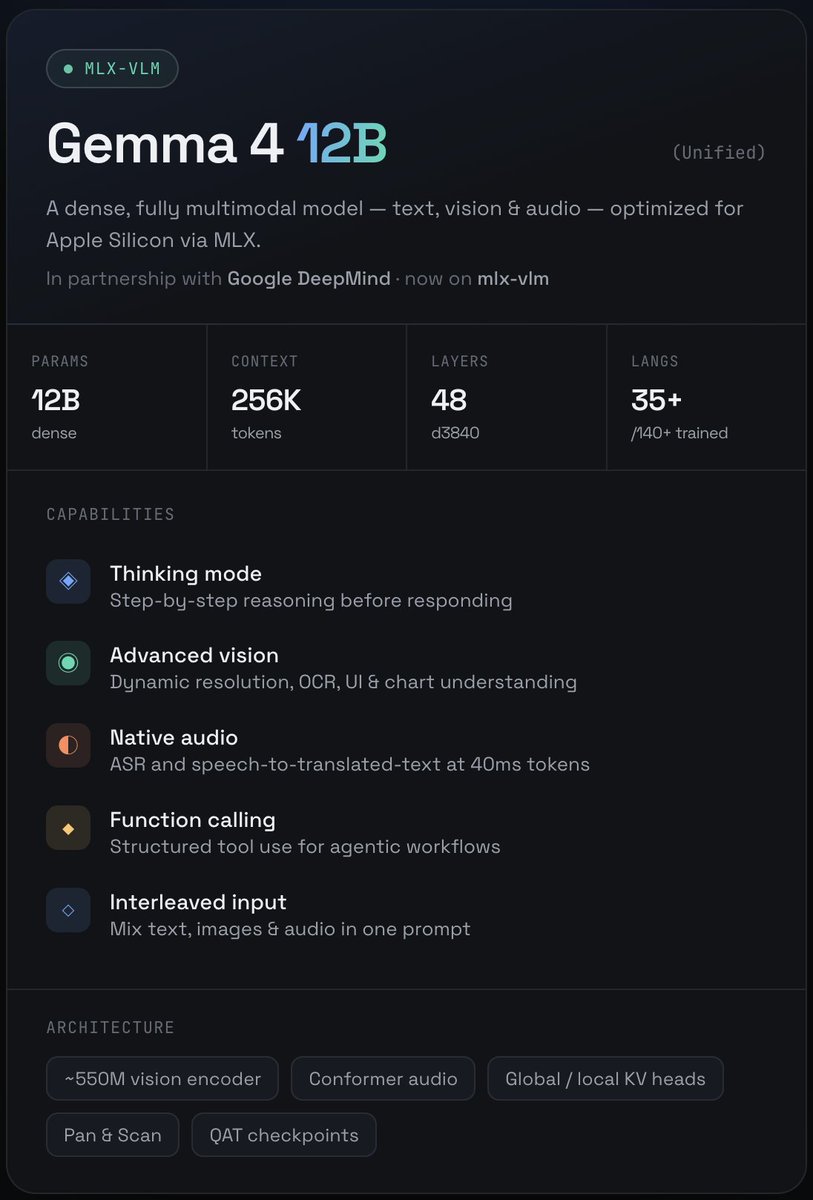
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

7
6
218
14,695
rurounigit retweeted
Jun 3
🚀 Gemma 4 12B is here!
We partnered with @GoogleDeepMind to bring and optimize their new dense and unifed multimodal model for Apple Silicon.
◈ 12B dense · 256K context
◈ Thinking mode (built-in reasoning)
◈ Vision: dynamic res, OCR, UI charts
◈ Native audio: ASR speech translation
◈ Function calling for agents
◈ Text image audio, interleaved
Runs local. Get started now ⚡
> uv pip install -U mlx-vlm
github.com/Blaizzy/mlx-vlm
Jun 3
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
52
143
1,409
178,360
rurounigit retweeted

May 22
Ok, but then there shouldn't be this "less than half the cost" language in the PR, even if hedged with "often".
I'm not even searching for it btw, i only spot checked twice and both times it was ~double price of 3.1 Pro.
May 20

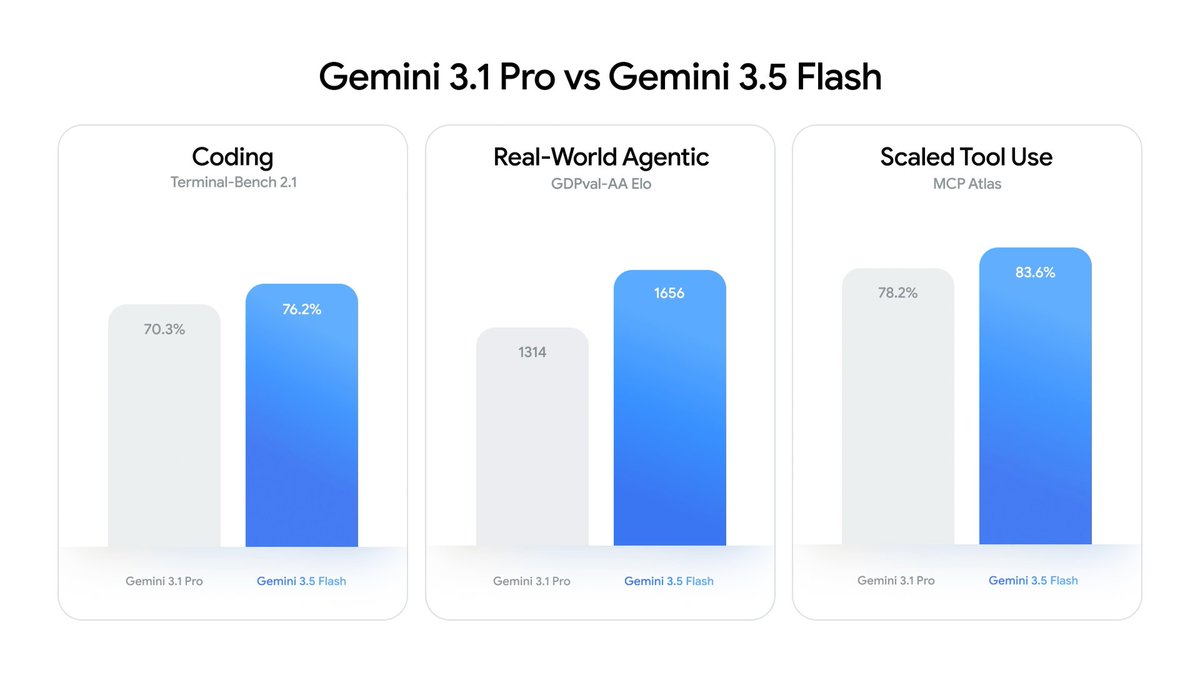
Gemini 3.5 Flash is amazing!
- Performs better than 3.1 Pro on coding & agentic tasks
- 4x faster than other frontier models
- 12x faster in @antigravity - 800 tokens/sec!
- Often at less than half the cost
And Pro to come…
Try it in @antigravity, @GeminiApp & more - enjoy!
1
2
31
1,845