
往前看 别回头
Joined October 2017
- Tweets 260
- Following 638
- Followers 2,102
- Likes 2,941
16 Photos and videos

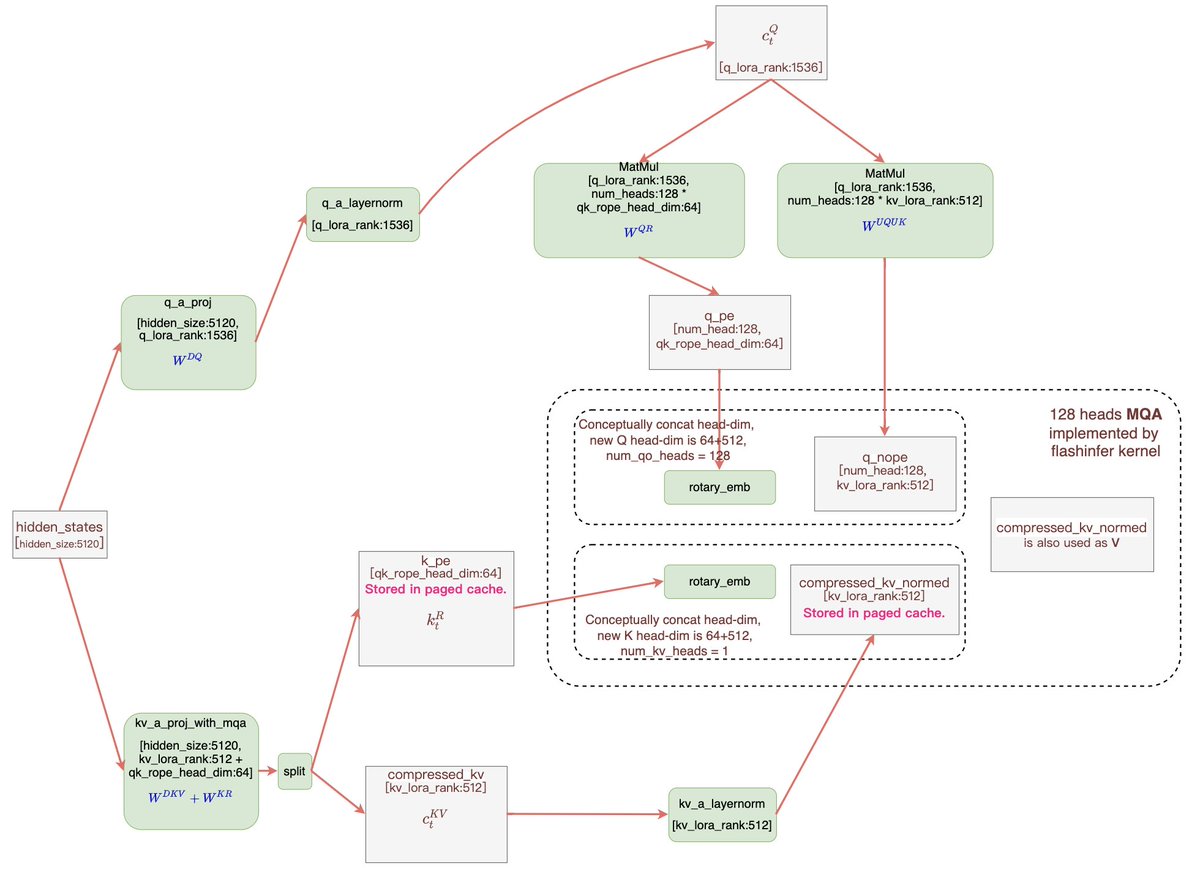

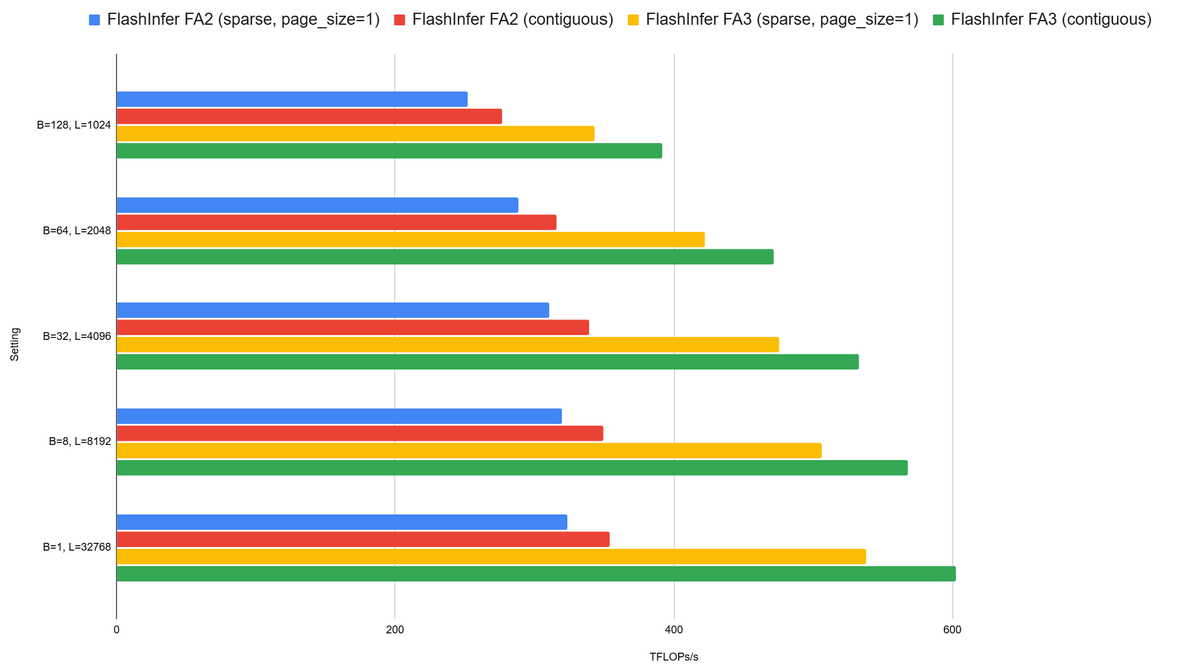

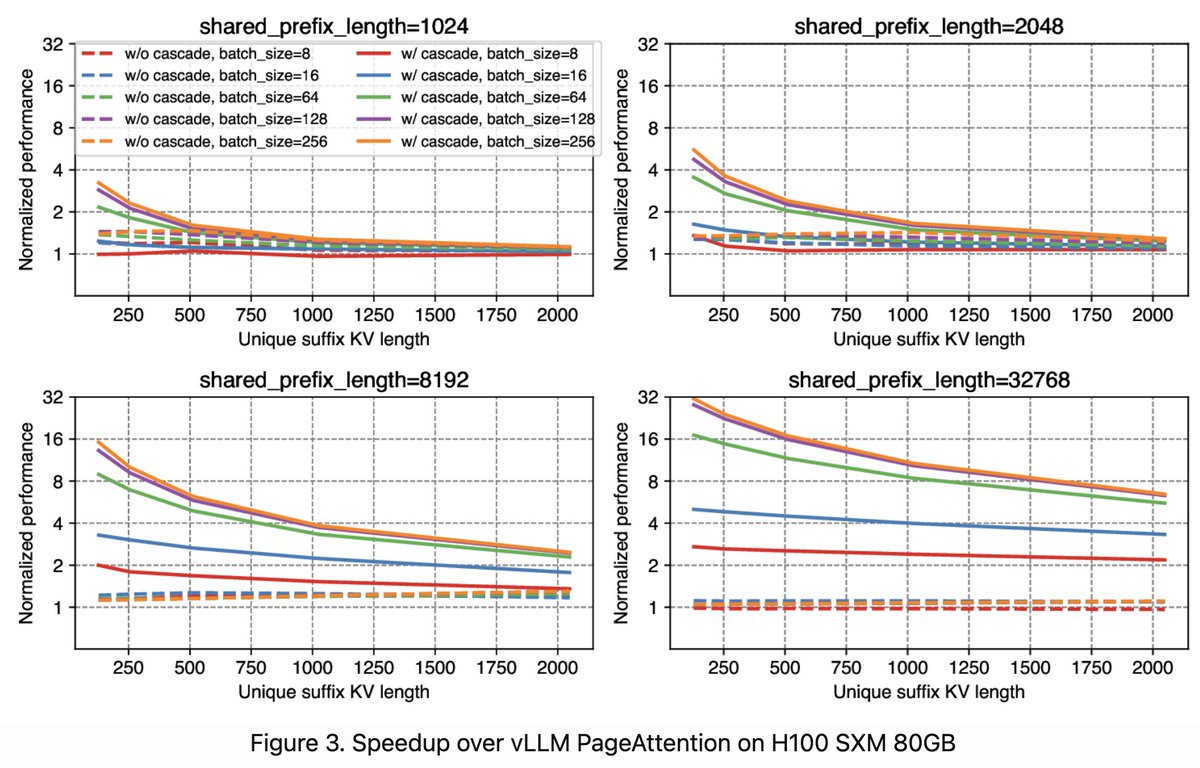
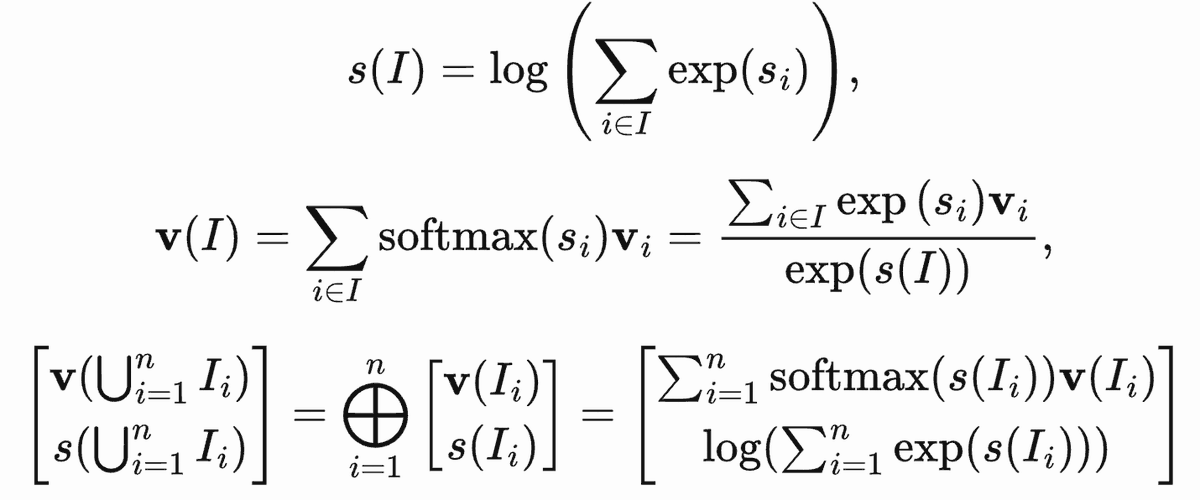




Zihao Ye retweeted

Jun 12
Launching a new kernel competition: Linear Algebra Kernels For The Age Of Research.
First problem: batched QR decomposition on B200. Old math, modern hardware.
Prize: Rare swag and hangout in SF
Jun 10

I have some mixed feelings about this result:
On the one hand, it's genuinely impressive. I didn't know that Shampoo could be configured to perform this well on the benchmark.
On the other hand, the way this performance boost was achieved seems difficult to call "Vanilla," for the following reason:
According to @_arohan_, the boost depends upon fixing a numerical linear algebra issue that he observed to occur in my initial standard DistributedShampoo run. He fixed the issue by enabling the flag rank_deficient_stability_config=PseudoInverseConfig().
Here's the problem: This is an undocumented flag. It is contained within the 12,000-line DistributedShampoo codebase, but it does not appear in any user-facing documentation.
As a result, if someone tries to train a model using DistributedShampoo without either (a) knowing about this special undocumented flag or (b) being prepared to detect and fix the numerical linear algebra issues that may occur without it, then they won't be able to achieve @_arohan_'s level of Shampoo performance. This level of effort would be considered atypical for mere hyperparameter tuning.
--
[Note on Muon baseline in plot below: Rohan's post compared Shampoo to a slightly undertuned Muon baseline from 2026/05/01, which reached the target loss in 3375 steps. This resulted in a 50-step gap between Shampoo and Muon. In the figure below I'm using the up-to-date 2026/05/03 baseline, which reaches the target in 3325 steps. This results in the step-counts exactly matching between Muon and the tuned/stabilized Shampoo variant.]

12
29
389
136,428
Zihao Ye retweeted

Jun 10
The web was never meant to be flattened into text.
Yet most web RAG systems start by parsing HTML --- a complex and lossy process.
🔥 Introducing PixelRAG: the first RAG system that retrieves and reads 30M web pages as pixels.
Instead of extracting text, PixelRAG retrieves screenshots and lets a VLM read them directly.
PixelRAG not only preserves visual information, but also outperforms text-based RAG on text-only QA benchmarks by 18.1%.
Why?
(1) HTML-to-text conversion often discards layout, structure, tables, and other useful signals.
(2) We continued pretraining a VLM on web page screenshots and turned it into a surprisingly strong visual retriever.
(3) Recent VLMs are remarkably good at understanding web pages, often with better accuracy and token efficiency than text-only pipelines.
Takeaway: HTML parsing may be one of the biggest self-inflicted bottlenecks in web RAG.
Demo below 👇
Code: github.com/StarTrail-org/Pix…
Paper: github.com/StarTrail-org/Pix…
Playground: pixelrag.ai/
25
116
693
72,239
Zihao Ye retweeted

Jun 6
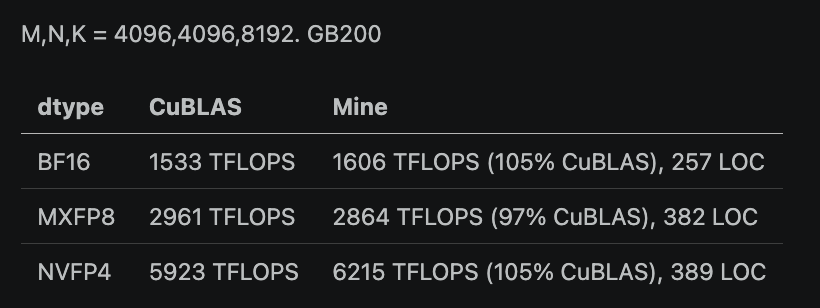
Beating CuBLAS was not a goal, but it came out pretty good. I think this is more useful as a concise and hackable "template", rather than being the fastest kernel: bring ur own epilogues, roll a megakernel, ask Codex to fork it. Just like when I first learned Triton.
2
3
51
2,228


Zihao Ye retweeted

Jun 1
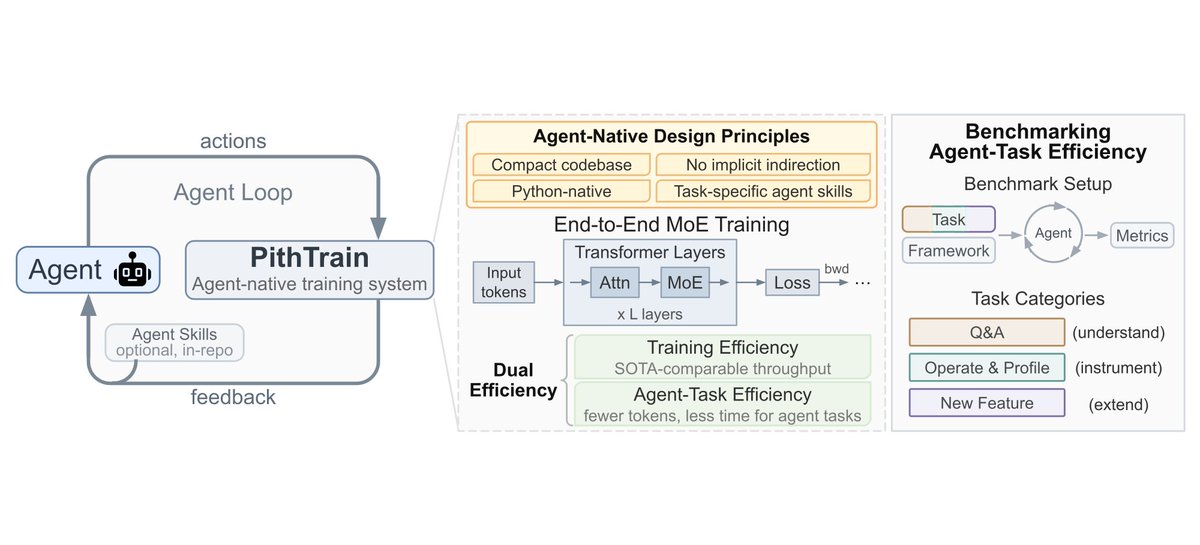
Two moments every ML researcher knows. You get onto a new cluster, and week one goes to fitting the framework to your setup, not training. A new architecture lands, and trying it means hacking through a gigantic codebase to stay compatible with the pipeline. What you want to change is small. The code you wade through to change isn't.
This experience is likely not alone, and many researchers we’ve talked to run into similar issues. A year of this on CMU's FLAME cluster left us with one question: what if a framework were built for an agent to adapt and evolve, not just for humans to maintain?
So we introduce PithTrain: a compact, agent-native MoE training system, now ~11K lines of Python, on four principles:
- Compact: fits in one context window
- Python-native: readable tracebacks, no compiled-extension rebuilds
- No implicit indirection: direct calls, each model in its own file
- Agent skills: in-repo playbooks for recurring tasks
Then we measured the thing nobody measures. Same agent, same tasks, only the framework underneath changes: on PithTrain it finishes with up to 62% fewer turns and 64% less GPU time than production frameworks, while training just as fast.
We call this second axis agent-task efficiency, and we believe it deserves to sit alongside training throughput as a metric worth optimizing. Excited to see what people build with it.
Built with amazing collaborators @haok1402, Haozhan Tang, Akaash Parthasarathy, @Zichun_Yu, @junrushao, Todd Mowry, @XiongChenyan and @tqchenml.
Blog: blog.mlc.ai/2026/06/01/pitht…
Code: github.com/mlc-ai/pith-train
Paper: arxiv.org/abs/2605.31463
3
37
170
21,761
Zihao Ye retweeted

May 27
Flash-KMeans was only the beginning.
Today, from the Flash-KMeans team, we are releasing FlashLib — a GPU library for fast, predictable, agent-ready classical ML operators.
Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML).
Blog: flashml-org.github.io/
Code: github.com/FlashML-org/flash…
47
236
1,606
865,897

That was a great talk @marksaroufim — started MLsys on an exciting note!
May 29

My MLSys keynote on AI writing systems code got more interest than I expected. The recording will take a while, so in the finest tradition of AI labs sharing blog posts, we’re starting the Core Automation Blog with this one coreauto.com/blog/when-ai-st…
1
3
1,013
Zihao Ye retweeted

May 29
For me, the coolest finding is that Muon optimizer is crucial for Parallax to move beyond Softmax Attention.
Lesson — don't evaluate new architectures solely under AdamW, you'll miss the good ones.
paper: arxiv.org/abs/2605.29157
code: github.com/Yifei-Zuo/Paralla…
For the origin of Parallax, check out the LLA paper at ICLR 2026:
paper: arxiv.org/abs/2510.01450
code: github.com/Yifei-Zuo/FlashLL…

May 29

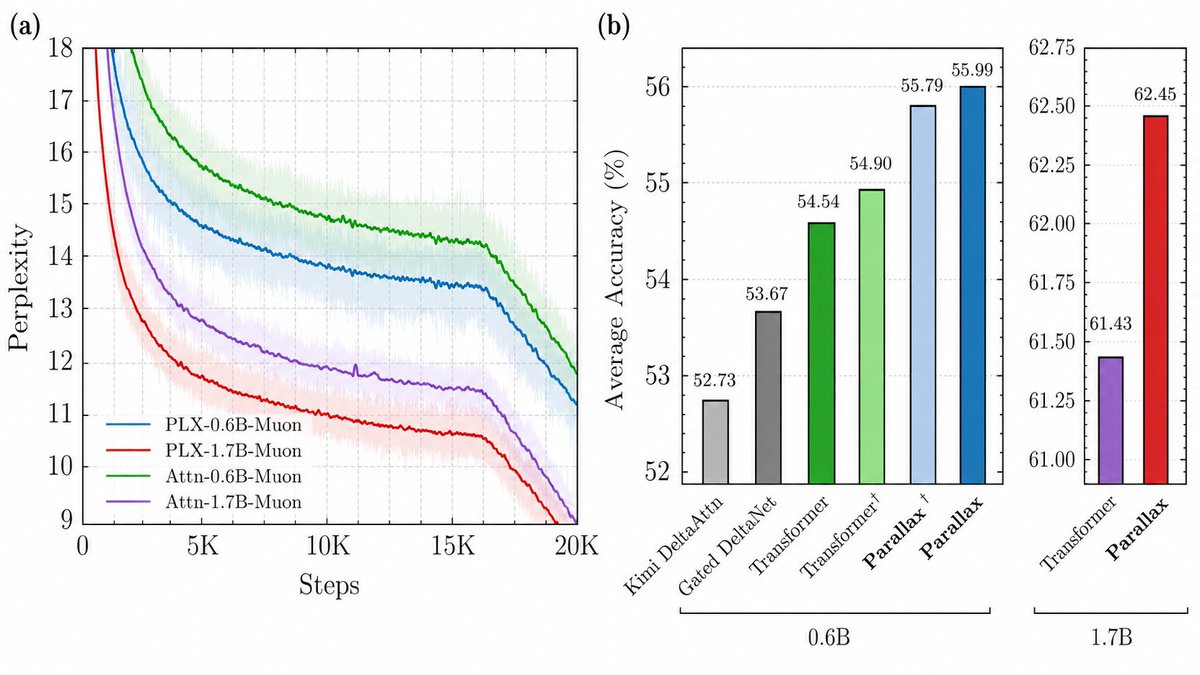
~1/7~Introducing Parallax → a stronger attention variant that achieves a Pareto improvement over vanilla attention at 0.6B and 1.7B scales.
Parallax has better perplexity, better downstream accuracy, and a decode kernel that matches or beats FlashAttention.
🧵
6
45
353
77,624

May 28
RT @GeminiApp: Build your first game with Gemini 3.5 Flash.
Translate everyday objects directly into interactive, digital experiences with…
114
Zihao Ye retweeted

May 27
We are obsessed with performance and low level details. Great work by my teammate @xyzw_io . Chat with us if this interests you.
May 27

We're open-sourcing the Unigram tokenizer we rebuilt to reduce CPU utilization by 5-6x.
Small rerankers and embedders run in single-digit milliseconds on GPU, making CPU tokenization a meaningful share of total latency.
github.com/perplexityai/pplx…

1
2
25
2,616
Zihao Ye retweeted

May 25
Excited about this new work
As KV compaction becomes increasingly important, we ask whether it’s worth adapting the model itself to perform better under compaction
Turns out, it can really matter

1/
How much can you compress an LLM’s KV cache?
tl;dr it depends on how you train your model.
Many strong context compaction methods, such as Cartridges and attention matching, operate post-hoc: given a fixed model and a context, they try to compress the resulting KV cache.
@yoav_gelberg and I ask the complementary question:
can we train the model to produce KV representations that are easier to compress?
In other words: keep the compression method fixed, and change the representations it sees.

3
28
154
22,163

After some mathematical rewrite, turns out all of transformer is a series of gemm epilogue. Given a few optimized primitives, LLMs (and novice humans) can write speed-of-light kernels for all transformer ops!

LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).

17
128
1,208
132,139
Zihao Ye retweeted

May 22
rolling up to MLSys '26 to meet with @ye_combinator and the winners of our B200 kernel perf competition
quick trip, so i packed a single bag, just my essentials

3
2
54
12,642
Zihao Ye retweeted

May 22
Pro-tip: using CUDA graphs and annoyed that all the kernels have no labels in your profiles? Get a nightly that has mark_kernels context manager: github.com/pytorch/pytorch/p… (thanks Natalia and Shangdi for implementing!) You need 13.1 driver, but user mode driver is enough
1
11
123
14,588
Zihao Ye retweeted
May 21
It was an honor to give the keynote at MLSys
Covered how AI systems have evolved, why AI is needed to improve them, why results have disappointed, why the future looks amazing, and why I’m working on this at Core Auto
Recording should be out soon, in the meantime slides

15
45
446
66,780
Zihao Ye retweeted

May 20
#MLSys26 NVIDIA is hosting ice cream social on Friday mlsys.org/virtual/2026/socia… after the competition session, looking forward to see folks there
2
2
37
10,223
Zihao Ye retweeted
May 10
Historically, we used dev-discuss.pytorch.org/ for this. I think this forum is still good for things that are much more about discussion. But actual one big impetus for devlogs as a SSG website github.com/pytorch/devlogs was to make the posts more easily accessible to LLM agents
1
3
18
2,170
Zihao Ye retweeted

May 4
Super happy to see my UCSD colleague help port our DFlash to TPU. Big speedup too!! More to come.

Breaking LLM inference’s autoregressive bottleneck 🛠️
We've teamed up with @haozhangml, @YimingBob, and @aaronzhfeng, among others from UCSD to achieve a massive 3.13X speedup for LLM inference on Google Cloud TPUs using Diffusion-Style Speculative Decoding (DFlash).
Read the blog: goo.gle/4naZ8Yv
10
9
113
13,552

This likely means OpenAI does interleaved stages of SFT-RL-SFT-RL rather than the simpler SFT-RL-done pipeline we see with open models


We’re talking about Goblins.
openai.com/index/where-the-g…
12
22
468
42,128
Zihao Ye retweeted

Apr 29
挺有意思的研究。
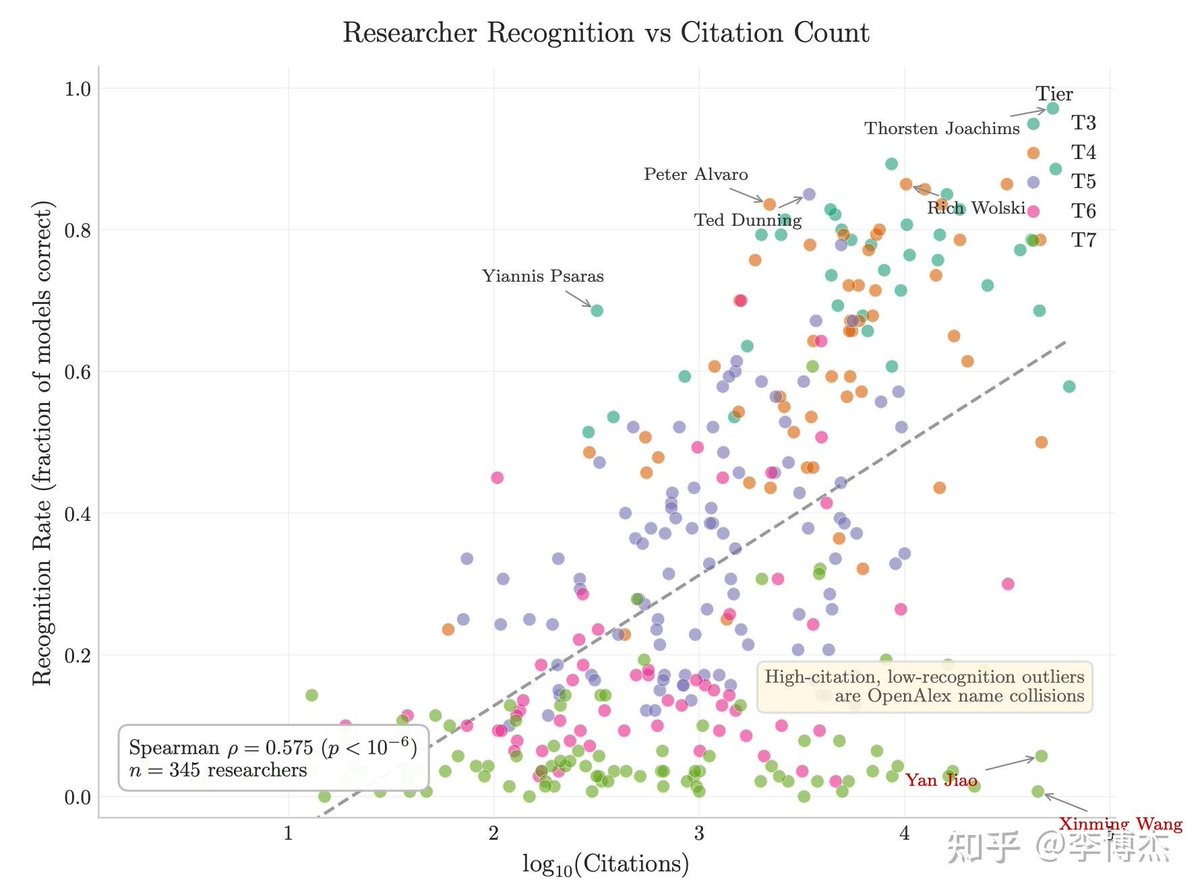
闭源实验室都对模型规模讳莫如深,但他们其实藏不住模型"知道什么"。而模型知道什么,恰恰就是参数量的指标。
核心逻辑:推理能力可以靠蒸馏压缩到小模型里,事实知识不行。一个模型记得多少冷门事实,直接跟它的参数量挂钩。
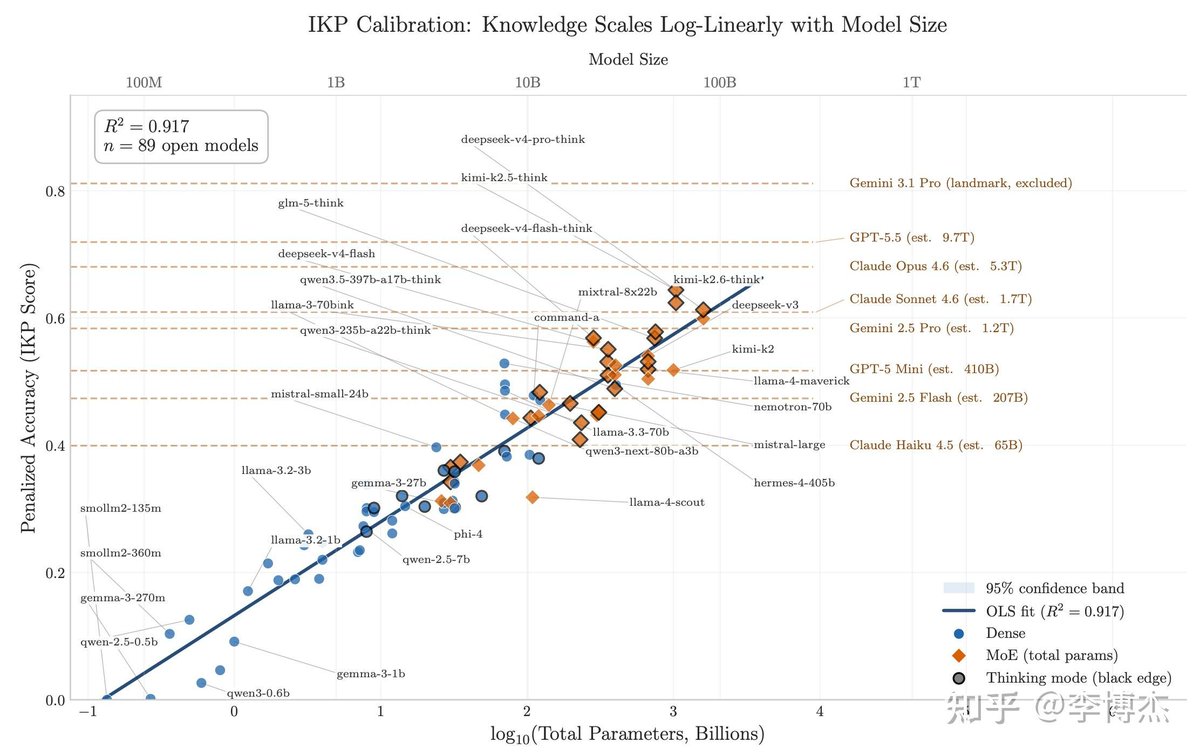
知乎博主李博杰为这个写了一篇小论文,构建了一套叫 IKP(不可压缩知识探针)的数据集:1400 个问题、7 层稀有度,扔到 27 家厂商的 188 个模型上跑了一遍,只看事实准确率。
结果在 89 个公开参数的开源模型上,准确率 vs log(参数量) 的拟合 R²=0.917,基本是一条直线。把闭源模型投影上去,规模就估出来了:
GPT-5.5 ≈ 9T
Claude Opus 4.7 ≈ 4T
GPT-5.4 ≈ 2.2T
Claude Sonnet 4.6 ≈ 1.7T
Gemini 2.5 Pro ≈ 1.2T
(90% 置信区间:0.3-3 倍规模)
另外两个发现也挺反直觉:
一是引用数和 h-index 不能预测一个研究者是否被前沿模型认识。两个引用数相近的人,模型给的回答可能完全不一样。它记的是有影响力的工作,不是论文数量。
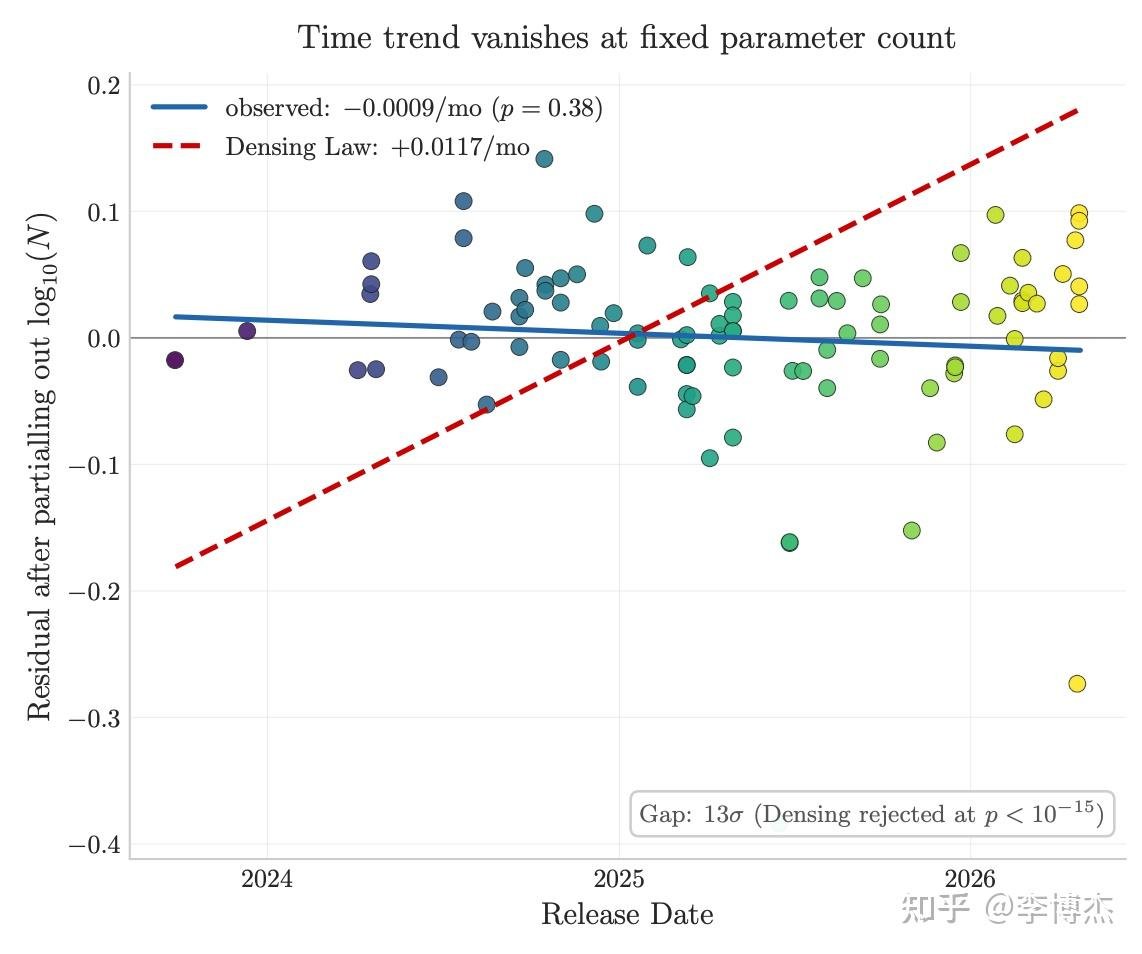
二是事实容量不会被时间压缩。跨 3 年的 96 个开源模型,IKP 时间系数统计上为零(p<10⁻¹⁵),直接拒绝了 Densing Law 预测的 0.0117/月衰减。benchmark 在饱和,但事实容量还在随参数继续扩张。
来源:知乎博主 李博杰
侵权联系删
arxiv.org/pdf/2604.24827
52
158
1,003
205,599