
opinions are my own
Joined October 2012
- Tweets 685
- Following 524
- Followers 1,897
- Likes 1,131
12 Photos and videos







Higgs Audio v3 TTS is here.
Built for voice AI that speaks, not just reads:
• 100 languages with single-digit WER/CER
• inline control over emotion, style, prosody, and sound effects
• API, Workspace, and open weights
• Blog 👉 boson.ai/blog/higgs-audio-v3…
Watch the demo 👇
14
61
390
55,041
Junru Shao retweeted

May 29
we have become weaker as a species

May 29

yea pipelining is a really good usecase for a compiler. writing the code by hand, especially when supporting multiple pipeline schedules, is nightmare material
12
52
830
68,892
Junru Shao retweeted

May 22
🚀 The wait is over! Today at #MLSys, we'll give a talk to reveal the final results and present the awards for the FlashInfer AI GPU Competition! 🏆
I'll also introduce FlashInfer-Bench: an agent-oriented Benchmark Engine designed for production kernels.
Join us from 11:00 AM - 1:00 PM PT to see who takes the crown and learn more. Everyone is welcome to attend—see you there! ✨
🌐 Competition & Results: mlsys26.flashinfer.ai
💻 FlashInfer-Bench Benchmark Engine: github.com/flashinfer-ai/fla…
#FlashInfer #MLSys26 #AI #GPU
1
15
95
26,757
Junru Shao retweeted

May 12
A thread about the history and internal implementation details of activation checkpointing APIs in PyTorch. 🧵
6
29
250
19,315

May 7
good stuff 🦀
May 7

We open-sourced some amazing work on an experimental Rust compiler for GPU from my colleagues at @nvidia. It takes a slightly different approach to expose GPU programming concepts natively in Rust. Check it out github.com/NVlabs/cuda-oxide.
2
668
May 7
once-in-a-lifetime opportunity to join Yuchen’s team!
May 7

An OpenAI friend told me he burns 300M GPT-5.5 tokens/day.
The top one in his team burns billions of tokens/day. Codex coding for them every night.
Databricks also gives engineers unlimited tokens.
We're looking for cracked inference engineers to join us at Databricks AI to produce trillions of tokens, insanely fast. DM me if you have:
- Contributed to open-source ML systems like SGLang/vLLM/PyTorch
- Experience serving LLMs at large scale
Databricks AI runs like a startup. Lots of exciting things to build!
1
18
5,159
Junru Shao retweeted

May 6
#MLSys2026 is happening in two weeks! Our AI Infra team at @perplexity_ai is throwing a happy hour event at Bellevue on May 19. Come chat with us about inference, post-training, RL, kernels, GPUs, RDMA, agents, anything... luma.com/6knju9tp

1
3
13
1,389
Junru Shao retweeted
May 4
Introducing XGrammar-2: structured generation for complex agent harnesses.
Strict tool-calling formats. Built-in DeepSeek-V4 and Qwen-3.6 support. Up to 80x speedup over XGrammar. Ready-to-use integrations with vLLM, SGLang, TensorRT-LLM, and more! ⚡
From Claude Code to OpenClaw, agents are defining more complex harnesses. XGrammar-2 ensures LLMs always interact with them in the right way.
Built in collaboration with DeepSeek, Databricks, and leading frontier AI labs to bring XGrammar-2 into latest models and products.
🧩 Structural Tag: one unified abstraction to describe any format your agent needs
🚀 Scales to 500 strictly typed tools for complex agent harnesses
🌐 Native APIs in Python, C , Rust, and JS, running everywhere from cloud to edge
🛠️ Integrated with vLLM, SGLang, TensorRT-LLM, and more
Excited to see what agent builders create with it!
Blog: blog.mlc.ai/2026/05/04/xgram…
GitHub: github.com/mlc-ai/xgrammar

8
52
149
42,152
Junru Shao retweeted

Apr 28
Excited to share that I’ll be presenting SkyWalker at #EuroSys26 in Edinburgh tomorrow!🚀
We asks: Can we reduce the cost of multi-region LLM serving by cross-region offloading, without losing the benefits of KV-cache locality?
Talk: April 29, afternoon track A, ~16:20-16:40📍
1
1
2
389
Apr 26
TIL: python’s set doesn’t maintain insertion order unlike dict which does 😅
3
268
Junru Shao retweeted

Apr 24
The DeepSeek proposals section is always fun lol

1
5
97
7,324
Apr 24
TileLang is DeepSeek’s kernel maxxxing DSL on both Nvidia and Huawei’s Ascend cards
2
61
2,973
Junru Shao retweeted

Apr 16
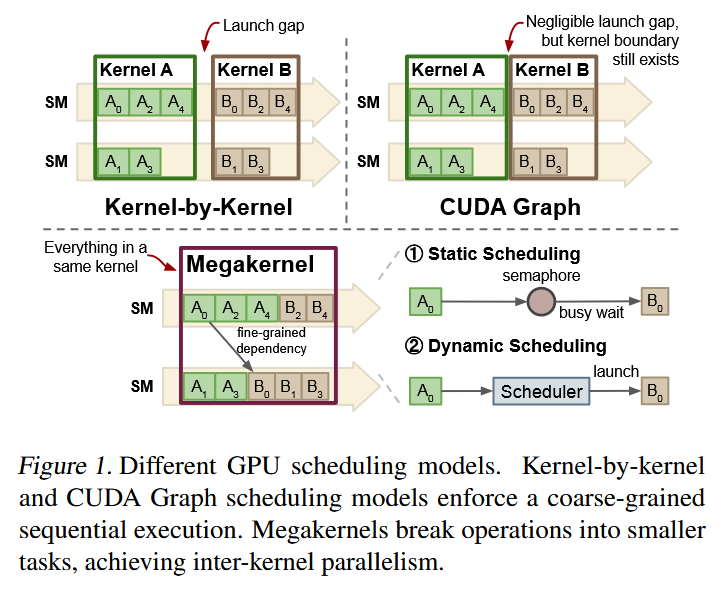
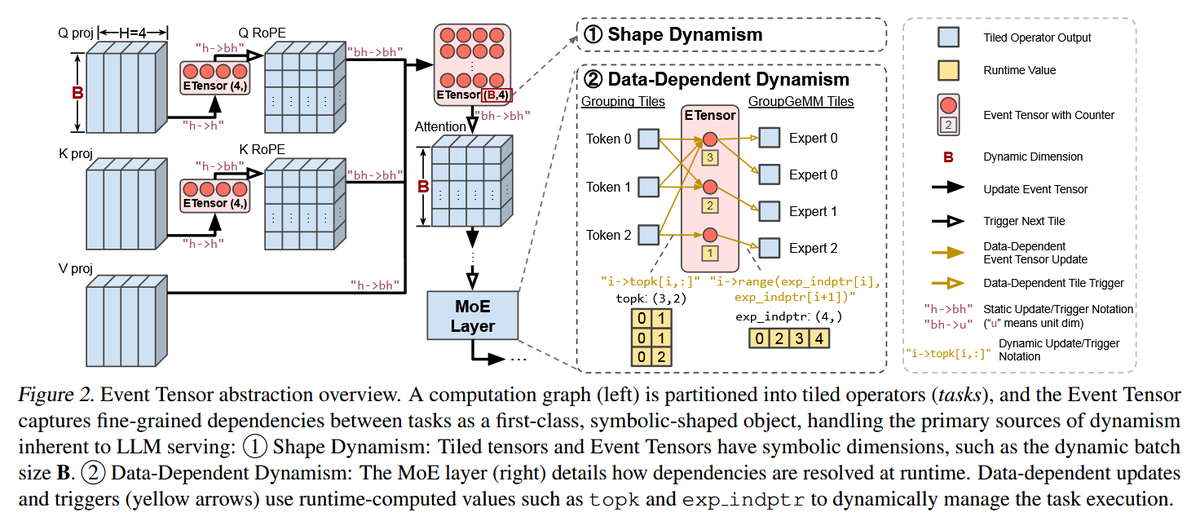
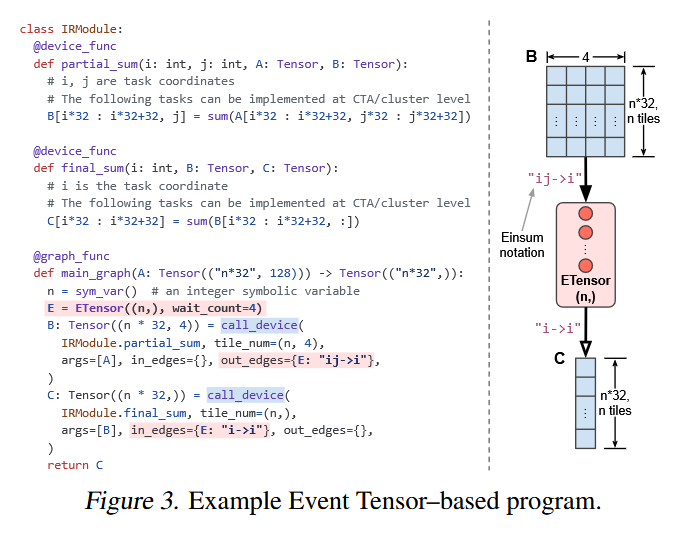
In this paper is presented Event Tensor, an abstraction designed to simplify the compilation and execution of dynamic megakernels, providing first-class support for both shape and data-dependent dynamism.
arxiv.org/pdf/2604.13327
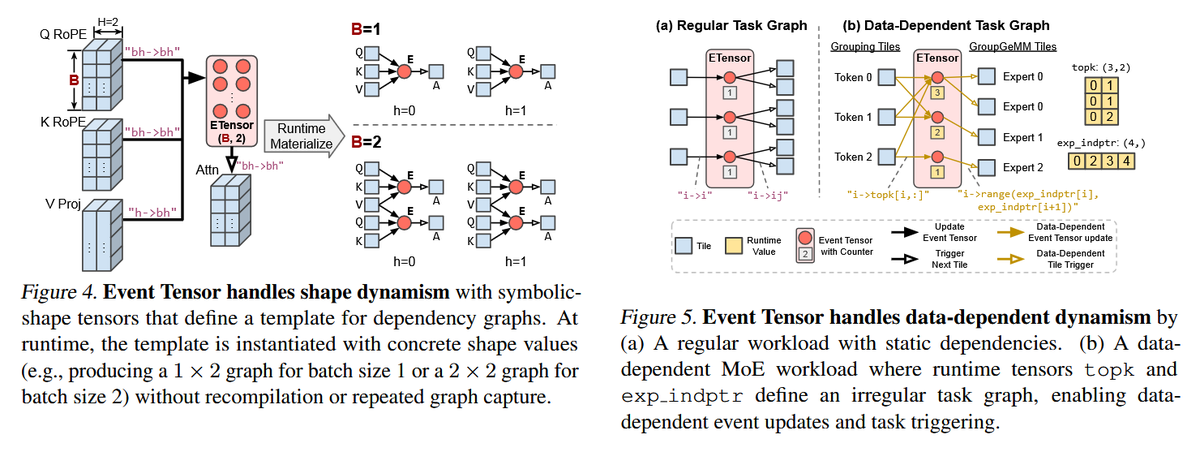
1
18
114
11,456
Junru Shao retweeted

Apr 14
Why subscribe to both GPT 5.4 and Claude 4.6?
Because 5.4 4.6 is a perfect 10/10.
Meme: why do you think you could be smarter than Codex/Claude?


2
7
71
10,310
Apr 11
> went out for dinner
> left claude loose on a "battle-tested" codebase
> come back after 3h
> 10 real bugs found
the future of software engineer is feeling unreal
5
2
23
3,126
Junru Shao retweeted

Apr 7
I was going crazy because I could not replicate TurboQuant. Turns out the community also had issues. The community quickly made adjustments to "make it work", but what they did not realize is that they reimplemented (most of) HIGGS in the process (full HIGGS would be even better)
14
72
840
98,193
Apr 7
My mental health for the day entirely depends on whether Claude Code woke up with a 200 IQ or a room-temperature IQ
2
9
1,597
Apr 1
got me for a sec 😅

FFmpeg is moving to Rust 🦀
Our use of C and Assembly in FFmpeg has been an unacceptable violation of safety.
FFmpeg will be running 10x slower - but we're doing it for your safety.
All your videos will appear green - safety first, working software later.
3
667
Mar 29
so many familiar faces! @vinodg @bohanhou1998
Mar 29

Excited to see our inaugural CMU Catalyst Research Summit bring together 120 attendees!
A full day of discussions on the future of agentic AI systems, multi-modal AI, and ML compilation—with amazing energy from both academia and industry.
Co-organized with @tqchenml @BeidiChen @Tim_Dettmers — this is just the beginning 🚀

2
5
1,698