
Co-founder and CTO at Nexa AI, Industrial Veteran from Google & Amazon, and Stanford alumni. Committed to lifelong learning and advancing AI technology.
Joined October 2021
- Tweets 183
- Following 425
- Followers 237
- Likes 196
17 Photos and videos











Join us live to see what developers can build with NexaSDK on @Snapdragon—plus a live demo and open Q&A with the team. 🚀
8
9
3,062

31 Dec 2025
What an incredible 2025! Thankful for the partnerships, trust, and collaboration that made it possible. Excited for what we’ll build together next 🚀
2
141
Zack Li-Nexa AI retweeted

19 Dec 2025
364
2,920
15,532
2,977,760
16 Dec 2025
We just launched NexaSDK for Mobile on Product Hunt. Try out NexaSDK for Mobile and we’d love your feedback: producthunt.com/products/nex…
1
2
164
26 Nov 2025
Huge appreciation to our partners from @Microsoft
@GoogleDeepMind @Qualcomm @NVIDIA @IBM @AMD @Intel @Qwen and so many others who featured us on stages, blogs, and launches!
2
141
24 Nov 2025
gpt-oss-20b running on Hexagon NPU via Nexa SDK 🔥
70
12 Nov 2025
Thanks @nvidia @NVIDIA_AI_PC for promoting our Hyperlink product!
12 Nov 2025

Your local AI agent, upgraded.
@Nexa_ai's Hyperlink is accelerated by RTX AI PCs allowing for scans of gigabytes of local files in minutes — fast, private, and all on your device.
Get started today #RTXAIGarage 👉 nvda.ws/3LSZDYA

2
74
10 Nov 2025
Following the launch of the Nexa Android SDK, we ran a 10-minute LLM stress test on the Samsung S25 Ultra with Qualcomm Hexagon NPU:
⚙️ CPU: throttled from ~37 t/s → ~19 t/s at 42 °C
⚙️ NPU (Qualcomm Hexagon): held steady at ~90 t/s and 36–38 °C — 2–4× faster under load
🔋 Both used ~6% battery, but the NPU delivered ~3.7× more tokens per battery
Efficient, cool, and fully offline — that’s the power of NexaSDK on-device inference. 🔥📱
📘 Learn more: docs.nexa.ai/nexa-sdk-androi…
1
148
6 Nov 2025
Today, we’re launching Android Java & Kotlin support for NexaSDK (Beta) — bringing the full power of on-device AI to billions @Android phones powered by @Qualcomm @Snapdragon chipsets.
This is a major leap forward for the world’s largest mobile developer community:
✅ Seamless NPU / GPU / CPU inference with a single SDK
✅ Run top-tier open models from @Google , @nvidia , and more
✅ 100% private, zero cloud latency, and fully offline
2
104
5 Nov 2025
Our work on NPU-accelerated inference for SDXL-Turbo has been featured by AMD on their official blog. We also have been invited to the PyTorch Conference with AMD. Try it out on your AMD laptop:
nexa infer NexaAI/sdxl-turbo-amd-npu
1
86
20 Oct 2025
LFM2-1.2B models from Liquid AI are now running fully accelerated on Qualcomm NPUs via the NexaML engine — real-time performance with minimal memory use, right on the edge.
Four new variants power everything from chat to document parsing:
💬 LFM2-1.2B – general chat & reasoning
🔍 LFM2-1.2B-RAG – retrieval-augmented local chat
⚙️ LFM2-1.2B-Tool – structured tool use & agent workflows
📄 LFM2-1.2B-Extract – ultra-fast document parsing
A hybrid Transformer SSM design few frameworks can even run — but NexaML can.
Already seeing what this unlocks for partners like Brilliant Labs in AR/VR.
⭐ Star NexaSDK to catch new edge model drops : github.com/NexaAI/nexa-sdk
2
59
14 Oct 2025
🚀 we’ve achieved Day-0 full-platform inference support for Qwen3-VL-4B!
From NPU to GPU to CPU, across Qualcomm, Apple, AMD, Intel, MediaTek, and NVIDIA, you can now run the latest multimodal model locally, natively, and at full speed — all powered by NexaSDK.
This breakthrough comes from building our core inference engine, NexaML, from the ground up — deeply integrating GGML and MLX, and optimizing for every hardware architecture.
In close collaboration with @Alibaba_Qwen , and partners at @Qualcomm , @MediaTek , @AMD, and @intel, we’ve delivered a truly Unified Inference Engine — bridging the compute gap between devices.
🌍 The future of multimodal AI is here — not in the cloud, but in your hands.
One command. All platforms. Full performance.
5
159
14 Oct 2025
We have provided day-0 support to run Qwen3-VL on NPU / GPU / CPU, try it here:
huggingface.co/collections/N…
Qwen3VL - a NexaAI Collection
Nexa AI infra to support Qwen3VL running on GPU/NPU/CPU
huggingface.co
14 Oct 2025

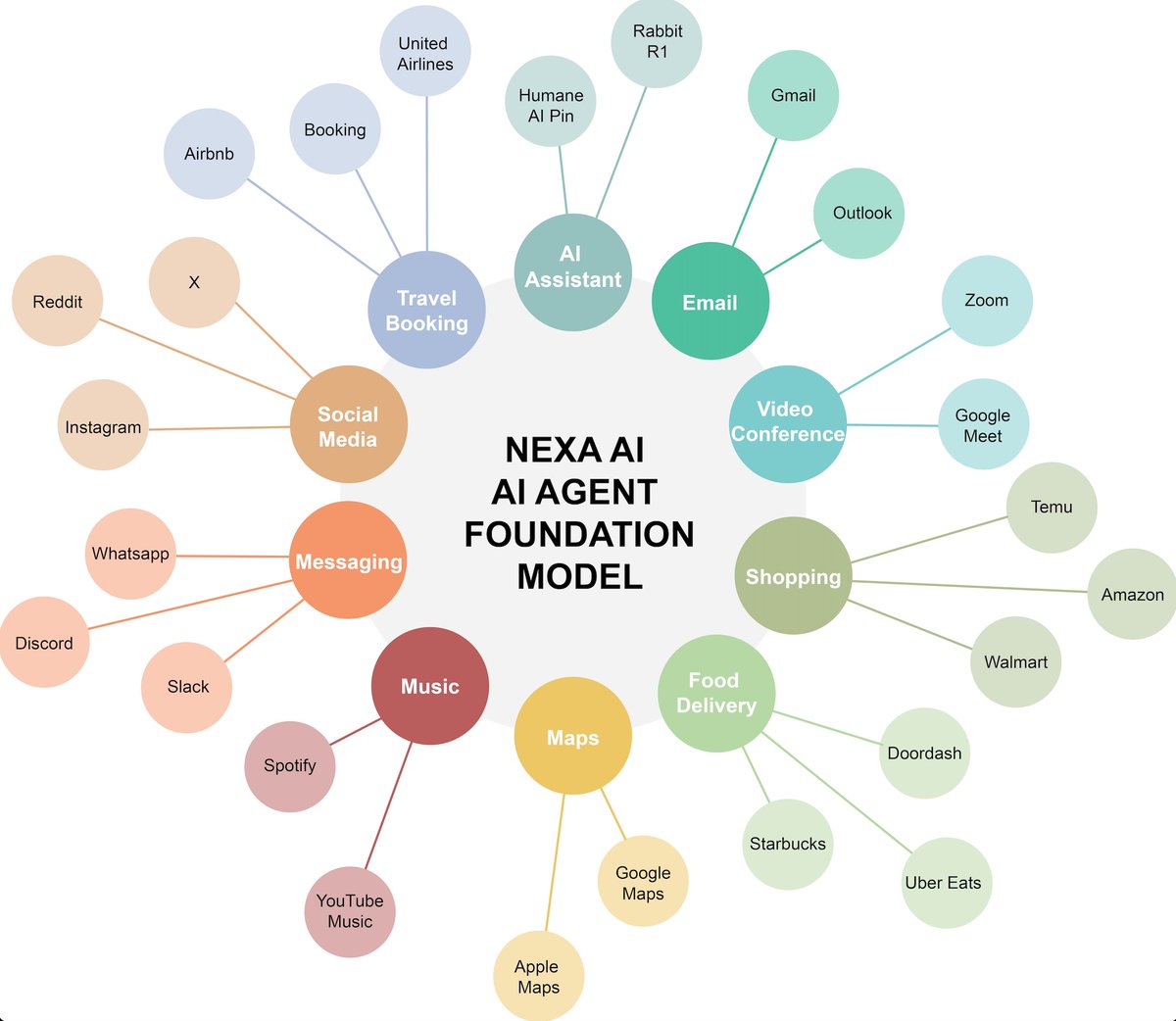
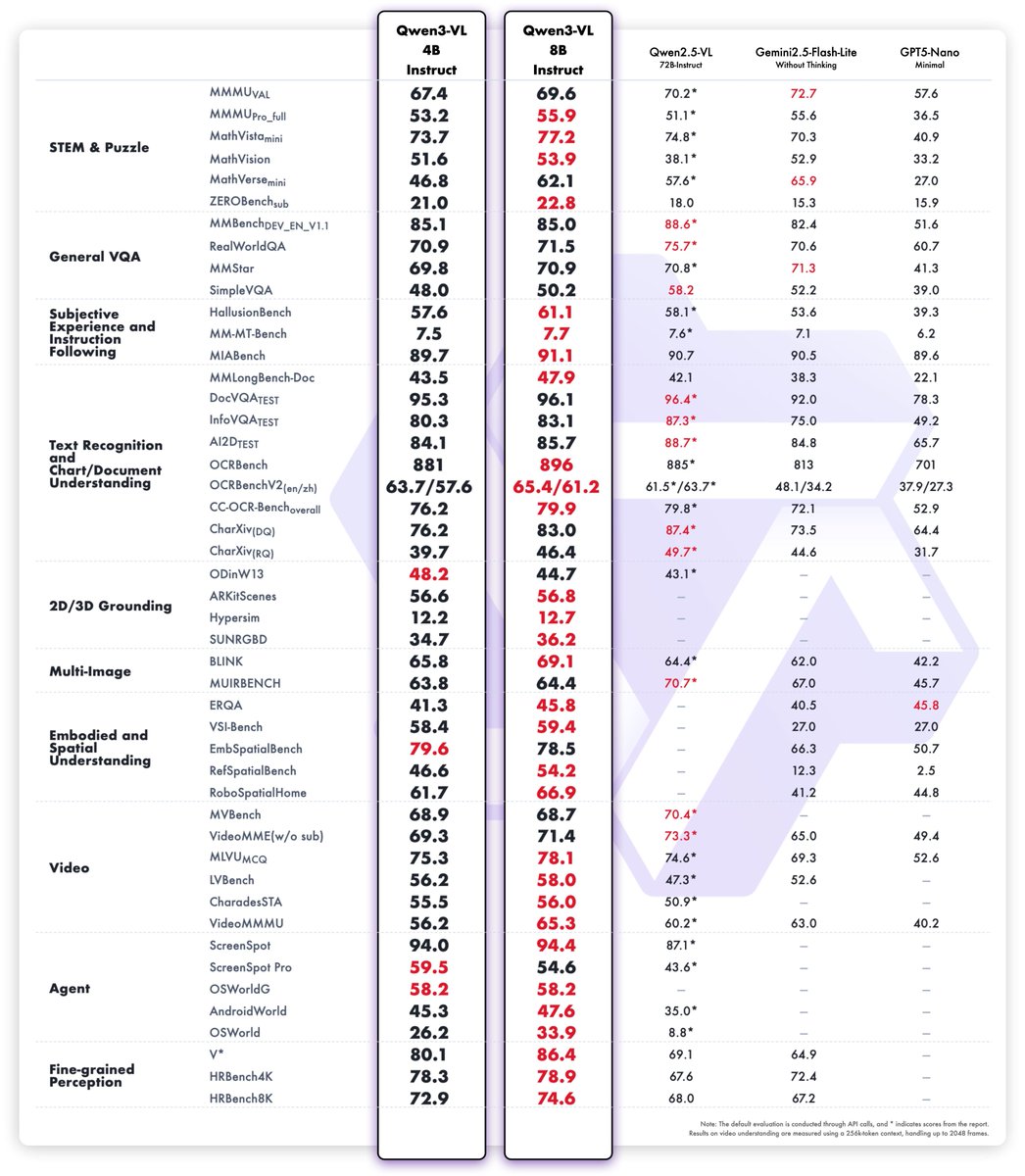
Introducing the compact, dense versions of Qwen3-VL — now available in 4B and 8B pairs, each with both Instruct and Thinking variants.
✅ Lower VRAM usage
✅ Full Qwen3-VL capabilities retained
✅ Strong performance across the board
Despite their size, they outperform models like Gemini 2.5 Flash Lite and GPT-5 Nano, and often beat them on benchmarks spanning STEM, VQA, OCR, video understanding, agent tasks, and more. In many cases, they even rival our flagship Qwen2.5-VL-72B from just six months ago!
Plus, FP8 versions are also available for efficient deployment.
Hugging Face: huggingface.co/collections/Q…
ModelScope: modelscope.cn/collections/Qw…
Qwen3-VL-8B-Instruct API: modelstudio.console.alibabac…
Qwen3-VL-8B-Thinking API: modelstudio.console.alibabac…
Cookbooks: github.com/QwenLM/Qwen3-VL/b…
2
147
11 Oct 2025
Thanks @simonw for mentioning our work! We continue to compress and prune gpt-oss such that it can fit in latest iPhone. More exciting updates to come soon!
10 Oct 2025

TIL you can run GPT-OSS 20B on a phone! This is on Snapdragon phones with 16GB or more of GPU-accessible memory - I didn't realize they had the same unified CPU-GPU memory trick that Apple Silicon has
(The largest iPhone 17 still maxes out at 12GB, so not enough RAM to run GPT-OSS 20B like this)
91
4 Oct 2025
Thrilled to share that we just launched another Day 0 support: Qwen3-VL-30B-A3B-Instruct is now live on NexaSDK with full Apple Silicon GPU support.
You can try it right now with:
nexa infer NexaAI/qwen3vl-30B-A3B-mlx
Thanks @JustinLin610 for partnership and @awnihannun for the MLX work!
1
5
395
2 Oct 2025
🚀 Granite-4.0 day-0 support with NexaML
According to our partners, this is the first-ever NPU day-0 support for a new LLM — Granite 4.0 is live on Qualcomm NPUs with NexaSDK.
With NexaSDK, you can run Granite 4.0 seamlessly across NPU, GPU, and CPU — and switch between them with a single line of code.
On AMD / Intel / Qualcomm / Apple GPU →
nexa infer NexaAI/granite-4.0-micro-GGUF
On Qualcomm NPU →
nexa infer NexaAI/Granite-4-Micro-NPU
This unlocks Granite-4.0 for PCs, smartphones, automotive, and IoT — ready from day zero. 💡
1
203
Zack Li-Nexa AI retweeted

1 Oct 2025
Running AI models locally on the @Snapdragon X Elite just went to a WHOLE NEW LEVEL thanks to @nexa_ai! I can't wait to be able to test this on the X2 Elite Extreme which will be up to 78% faster. Check this out on the @Surface Laptop
3
2
3
315
24 Sep 2025
NexaSDK brings Intel NPU, GPU, and CPU into one stack for real-time, private, local AI.
Star us: github.com/NexaAI/nexa-sdk
Try it: sdk.nexa.ai/model/Llama3.2-3…
1
47
15 Sep 2025
Now with CPU, GPU, and Snapdragon NPU support in one unified architecture—packed into a lightweight 60MB installer. No more juggling installers, APIs, or backend-specific builds.
⭐ If Nexa SDK helps you, give us a star:
GitHub: github.com/NexaAI/nexa-sdk
Blog: nexa.ai/blogs/backend
26