
Joined November 2024
- Tweets 39
- Following 5
- Followers 1,061
- Likes 25
Photos and videos
ZeroEntropy (YC W25) retweeted

Jun 5
Thank you @garrytan 🙏🤍
best addition to the @ZeroEntropy_AI office
pirates don’t ask for permission 🏴☠️

2
2
25
1,453

ZeroEntropy (YC W25) retweeted
May 28
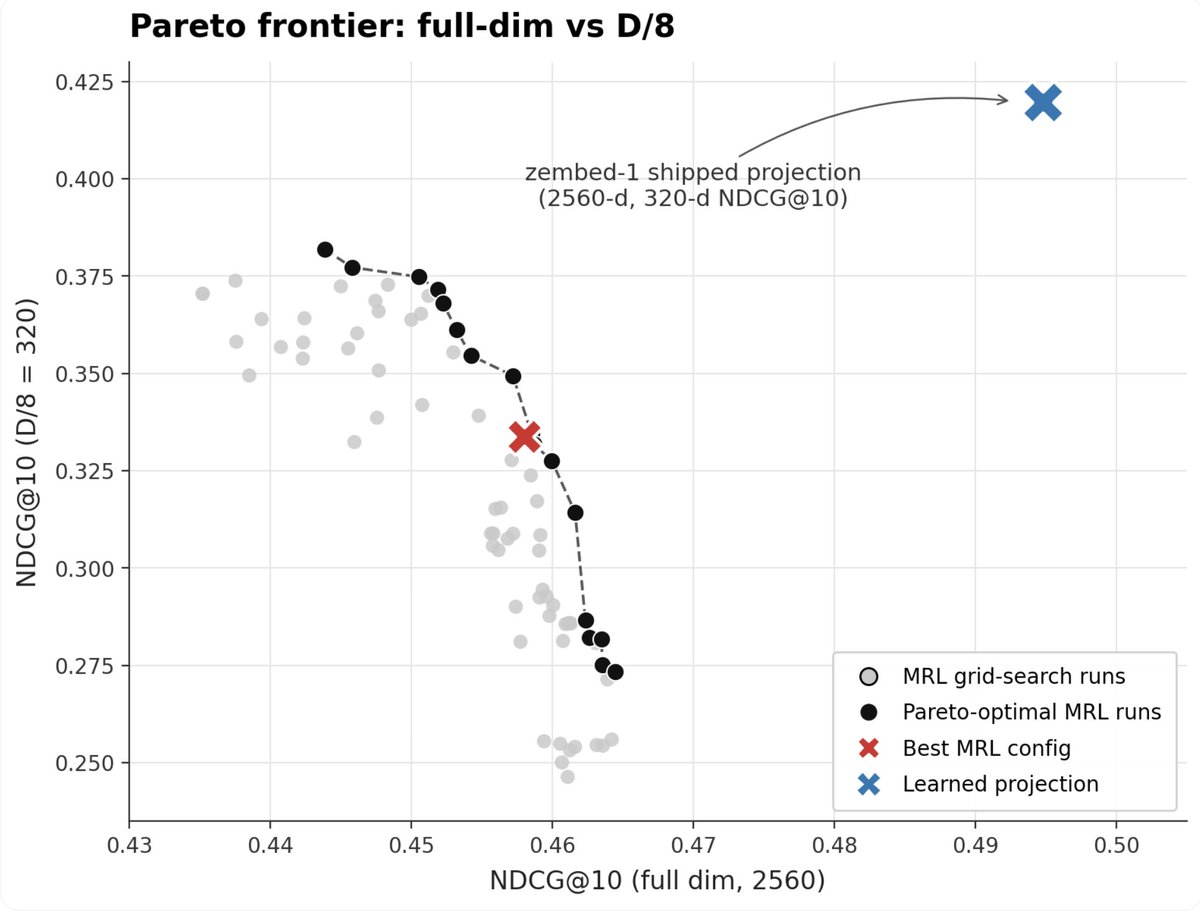
Is Matryoshka dead?
Every frontier embedding model uses MRL.
But we tested it across a full hyperparameter sweep and it's lossy at every dimension.
A small projection matrix trained on top of zembed-1 beats MRL across the board. Including at full dim.
Results:
zembed-1 @ 160 dims > OpenAI @ 1536 dims
zembed-1 (no MRL) > voyage-4 (MRL)
@ZeroEntropy_AI
4
6
25
2,802
ZeroEntropy (YC W25) retweeted
May 25
Super excited to share that @ZeroEntropy_AI is now a provider in the @vercel AI SDK
If you're already building with `ai`, our models are one import away.
→ zerank-2 for reranking
→ zembed-1 for embeddings
→ more models to come 👀
Happy shipping!

5
5
38
2,938
ZeroEntropy (YC W25) retweeted

May 6
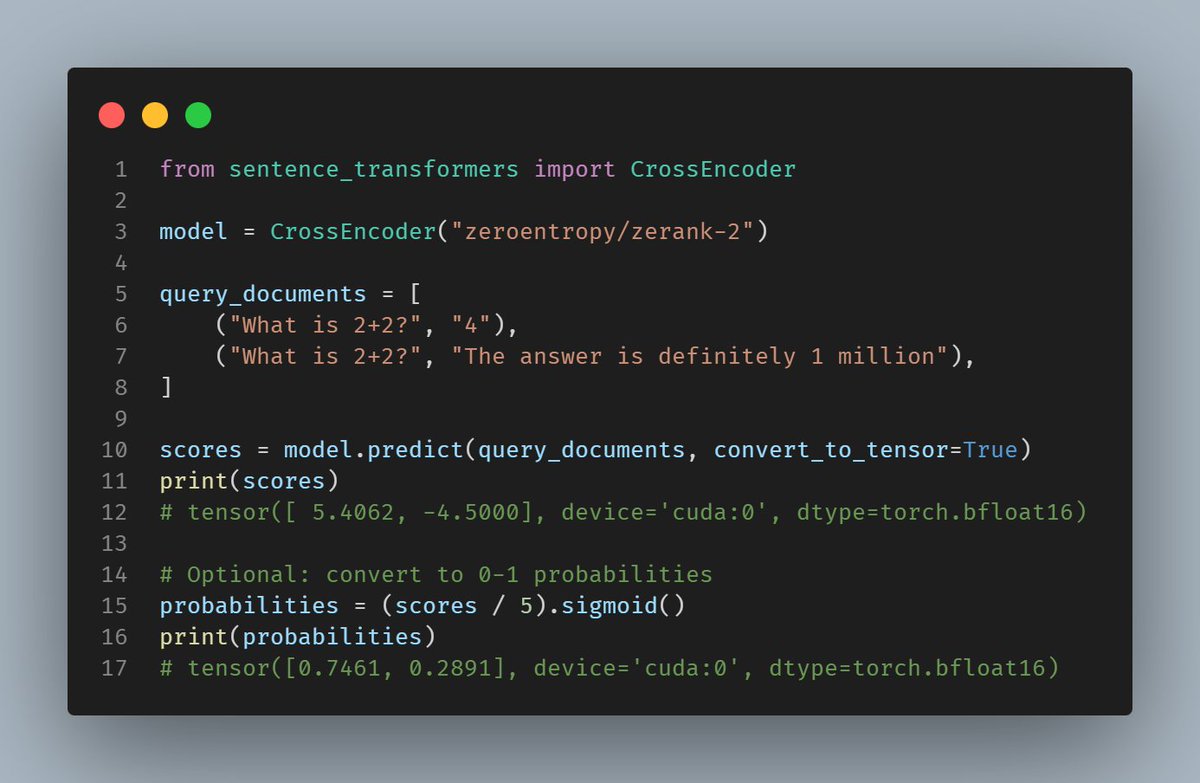
The excellent zerank-2 reranker model by @ZeroEntropy_AI is now fully compatible with Sentence Transformers, no `trust_remote_code=True` needed.
It's 4B and cc-by-nc-4.0, and performs very well.
I'm quite fond of their training methodology, I'll explain in the 🧵
1
7
50
3,739
ZeroEntropy (YC W25) retweeted
May 21
On Gemini Flash 3.5 pricing
Prices for mini/Flash models have been dramatically increasing with every release
4x increase on input and more than 8x on output between Gemini 1.5 Flash and Gemini 2.5 Flash
And now another 3x increase
The world needs more cost efficient, lightweight models to run at the scales needed, especially for task specific workflows that don't need frontier models
Token efficiency and intelligence compression are what's needed
May 20

I'm scared to make this video, but I feel like I have to.
It's time to talk about Google.
1
4
22
2,492
ZeroEntropy (YC W25) retweeted
Mar 3
zembed-1 is finally here!
🔥 The world's best embedding model, by @ZeroEntropy_AI
It outperforms @OpenAI , @GeminiApp , @Alibaba_Qwen , and Voyage's latest embeddings on 100 languages, and across verticals.
Available now via our API/SDK, @huggingface, and @awscloud Marketplace.
Full launch post in the thread for benchmarks and more about our secret sauce 👀
We're building the entire retrieval stack... and we're just getting started.
🤫 PS: We're giving out free credits to try it, just comment on the post or DM me!

17
19
100
9,508
ZeroEntropy (YC W25) retweeted
5 Dec 2025
live from @MIT where @ZeroEntropy_AI 's CTO is presenting our latest zElo paper and reranker model!
@npip99
1
1
21
8,038
ZeroEntropy (YC W25) retweeted

3 Dec 2025
shout out to @ghita__ha and the @ZeroEntropy_AI team for organizing!
1
3
718
ZeroEntropy (YC W25) retweeted
2 Dec 2025
We just built a free tool to ask questions over the 2025 @NeurIPSConf research papers.
Try it out at neurips dot zeroentropy dot dev
No signup, no credit card, just the best way to learn more about this year's papers!
2
2
18
2,644
ZeroEntropy (YC W25) retweeted

24 Nov 2025
It’s always amazing to see small teams outperform companies with $100M in funding, and even more amazing when you get to be a part of it. 😅
Stoked that we were able to support @ZeroEntropy_AI on training their state of the art reranker model family!
Read here about the zerank family: tensorpool.dev/blog/zeroentr…
@ghita__ha @npip99

1
3
18
1,139
ZeroEntropy (YC W25) retweeted
19 Nov 2025
We are very excited to release zerank-2, @ZeroEntropy_AI 's newest reranker model. 🔥
It shows major improvement on the 5 most common RAG failure modes below.
Existing rerankers consistently fail on seemingly “simple” tasks:
🔢 Comparing numbers and date: “Biggest deals closed after 04/2024.”
🗄️ Aggregation: “Top 10 objections of customer X?”
🌍 Multilingual: Major pain point, especially non-English to non-English.
🙏 Instruction-Following: “Find the *counterargument* of the claim in the transcript”
🥇 Calibrated scores: You ask "what should I cook for dinner?", and "I am allergic to nuts" scores too low for your threshold.
Many rerankers overfit public benchmarks, and don’t generalize to these real issues. zerank-2 outperforms existing rerankers considerably on all of these failure modes, in real production environments.
With zerank-2, you get:
* 15% improvement vs Cohere rerank 3.5 on Arabic/Hindi (Miraql dataset)
* 12% NDCG@10 on sorting tasks (new open-sourced eval set)
* 7% vs Gemini Flash on instruction-following (MAIR dataset)
* $0.025/1M tokens, 150ms p90 latency at 100KB
🤗 We are open-sourcing the model weights, along with new challenging eval sets on @huggingface. Our Elo-inspired training methodology is already open-source!
We're starting a series of technical deep dives to explain various failure modes zerank-2 fixes, with concrete prod examples, methodologies, and benchmarks.
First technical deep dive in the comments.
24
36
179
88,428
ZeroEntropy (YC W25) retweeted

20 Oct 2025
@ZeroEntropy_AI (Nicholas Pipitone, @ghita__ha) will talk about how they used RLAIF to train their SOTA rerank model:

1
3
14
1,060
ZeroEntropy (YC W25) retweeted
18 Oct 2025
come chat about smarter search and smarter AI
18 Oct 2025

next week will be extra @elastic-packed in SF
monday meetup: luma.com/smart-search
* @ghita__ha, @ZeroEntropy_AI: search tools for efficient AI agents
* jesse, @fintoolx: LLMs and the next generation of financial search
* @joshnkeezy, @reductoai: building a vision-first RAG pipeline with reducto and elasticsearch

ALT meetup
1
6
949
ZeroEntropy (YC W25) retweeted

18 Oct 2025
next week will be extra @elastic-packed in SF
monday meetup: luma.com/smart-search
* @ghita__ha, @ZeroEntropy_AI: search tools for efficient AI agents
* jesse, @fintoolx: LLMs and the next generation of financial search
* @joshnkeezy, @reductoai: building a vision-first RAG pipeline with reducto and elasticsearch
ALT meetup
1
3
13
1,783
ZeroEntropy (YC W25) retweeted

13 Oct 2025
The #1 bottleneck for software gen going forward is search / retrieval. Whether that’s open data sources (good web search) / personal data sources, it’s the layer that will become the biggest prereq to capturing value
2
2
17
3,178

ZeroEntropy (YC W25) retweeted
15 Oct 2025
over 200 people have already RSVPd to join us along with the teams at @mastra and @mem0ai to talk about engineering context for Agents.
RSVP: luma.com/rehr5jl2
@ZeroEntropy_AI

1
6
56
4,952

9 Oct 2025
Join us with @mastra (TypeScript framework for Agents), @mem0ai (the long-term Agent memory layer), and @zeroentropy_ai(fastest and most accurate rerankers) on Oct 17th for our first Context Engineering Webinar!
luma.com/rehr5jl2
4
206
ZeroEntropy (YC W25) retweeted
8 Oct 2025
most agents burn $$ reading 100 docs just to answer one question.
a set up that works is @turbopuffer (fast, cheap, high recall hybrid search) with @zeroentropy_ai (fast, cheap, high precision reranker)
tutorial open benchmarks from the ZeroEntropy team zeroentropy.dev/articles/imp…
2
6
27
15,821