
Activating AI in India | Past: @awscloud, @scaletogether | Previously backed/helped: @emergentlabs, @composio, @rocketdotnew, @thesysdev & more | Views my own
Joined June 2020
- Tweets 1,075
- Following 201
- Followers 3,782
- Likes 3,277
237 Photos and videos













Pinned Tweet

24 May 2025
I like @deedydas's work but but this take misses context
Sarvam-M isn’t a vanity fine-tune; it’s India’s first open-weights 24 B Indic-centric LLM built under brutal GPU & data scarcity. Judging it by few hours of HuggingFace stats badly misses the point.
Most people outside India don't appreciate that compute is quite the invisible ceiling
- H100 clusters are still not commercially stocked in India
- US export caps tightening next week will squeeze supply even further
- Indian teams literally queue for hours of A100/H100 time that US & CN labs get on tap
Data is also the long-tail problem
Indic languages form <0.01 % of CommonCrawl.
You read that right—two orders of magnitude less than Chinese or Spanish.
Any local lab must build its corpus first, then train. That’s months of ETL before the first gradient step. Synthetic data is GPU-constrained.
Talent pipeline is still forming
HPC RLHF compiler-level optimisation is new ground in India; Sarvam’s run has already up-skilled dozens of engineers who now know how to wrangle 10 k GPU-hours, FP8 PTQ & GRPO reward engines.
Their detailed blog post democratizes a lot of this learning.
You can’t AWS-credit your way to that muscle memory.
What Sarvam actually shipped
- 3.7 M high-diversity Indic prompts, deduped & quality-scored
- Two-phase non-think/think alignment that adds 2 pp on IndicGen
- GRPO RL with partial-credit rewards—LiveCodeBench jump 0.23→0.44
- FP8 look-ahead decoding: 2× tokens/s, ½ $/M tok on H100
That means a 🇮🇳-hosted midsize model now matches Gemma-3 27 B and Llama-3.3 70 B on Indic reasoning while costing a fraction to serve. That’s some engineering leverage & definitely not hype.
Model adoption is anyways a long-tail - one needs to ship multiple models of non-frontier quality to eventually be able to get to the one that's truly at the frontier (at least along dimensions that we care about).
Plus, there's a whole host of Indic-language use-cases where this sovereign model would work much better compared to using any other open-weights model. Look at (LiveCodeBench 0.23→0.44, 2× tokens/s)
If you ask for stats, you'll learn that some of their conversational AI platform reaches out to about 50M people in just a week.
What's next possibly?
- Maybe we all recognize the data problem & do Nation-scale data-collection drives (something like CommonCrawl-IN)
- Public RL-as-a-service clusters so smaller labs can replicate GRPO
- For devs wanting to push the Indic NLP forward, consider forking Sarvam-M, fine-tuning on your domain corpus, benchmarking on Indic-Eval, contributing back patches. Each derivative model widens the knowledge base & closes the English–Indic gap.
In summary, celebrating Sarvam's work (I'm not an investor) isn't nationalism, it's recognizing an innovation feat under constraints - India can't out-GPU Mountain View today but there's technical merit on display here, regardless of the metrics.
👏 @pratykumar, @AashaySachdeva, @HarveenChadha & other friends from @SarvamAI
Here's to more AI in 🇮🇳

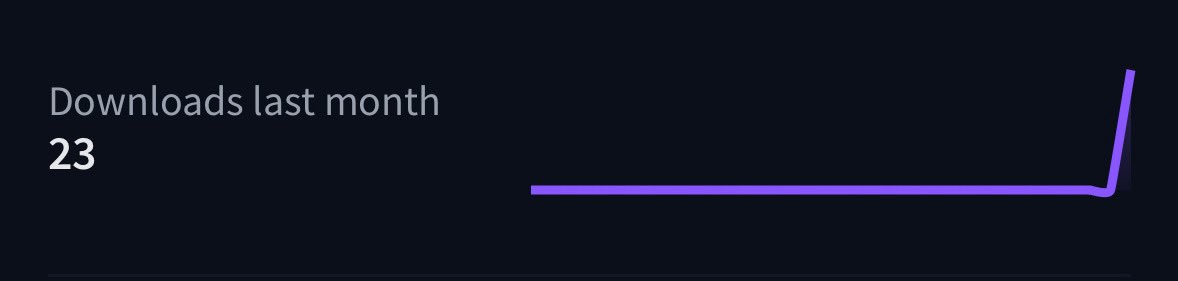
India's biggest AI startup, $1B Sarvam, just launched its flagship LLM.
It's a 24B Mistral small post trained on Indic data with a mere 23 downloads 2 days after launch.
In contrast, 2 Korean college trained an open-source model that did ~200k last month.
Embarrassing.
21
73
584
101,451
Jun 10
It's a special day for us at Activate.
Excited to welcome @soaibgrewal as Partner & Head of Ecosystem to build the ecosystem & support layer for the best AI founders in India.
Soaib has spent more than fifteen years as a founder, operator, investor & ecosystem builder. He’s led teams at T Ventures, Times Internet, 500 Startups, peercheque & BOLD, backing some of the country’s strongest consumer tech companies.
He also started Plaza, a cross-border venture helping brands extract more value from video across the US & India. The quality that stands out is his founder-first operating style - hands-on, clear-eyed & genuinely wired to help ambitious teams execute.
Soaib will drive our ecosystem efforts while staying close to investments & founder work right from the start. This meaningfully expands the platform we’re building for the next wave of AI teams.
@aakrit & I are beyond glad to have him as our third partner.
Welcome, Soaib. Let’s build. 🚀
1
1
37
1,794
Revealing piece by @polynoamial
From a scaling-laws perspective, this is unsurprising but still consequential.
Pre-training scaling laws told us how to allocate compute between parameters and data.
We now need an analogous understanding of how to allocate compute between pre-training inference-time search, planning & verification.
The interaction term matters: a stronger model makes each additional reasoning token or search branch more valuable because its internal representations support better error detection, longer coherent plans & more reliable self-critique.
That is why the marginal return to test-time compute appears higher for GPT-5.5-class models than for earlier ones.
The interesting work is no longer just “bigger model, better weights.” It is the co-design of the model, the inference harness, the search/verification strategy & the memory substrate that lets a system usefully spend 10× or 100× more tokens on a hard task.
That stack is where new moats & profit pools are forming - especially in domains where outcome value justifies high inference spend (scientific discovery, complex legal or financial reasoning, regulated enterprise agents, long-horizon coding agents)
3
6
1,417
Orignal link to the post: x.com/polynoamial/status/206…

1
1,127
.@saranormous - i think there’s a nuance
Coding is not merely a large market for frontier labs, it is a keystone domain of outsized strategic importance.
It combines extreme inference token consumption, high-quality verifiable reasoning traces for post-training, developer mindshare (the builders of future AI systems) & the clearest near-term path to agentic self-improvement.
Labs therefore have intense incentives to capture or heavily influence this layer.
Yet “capturing it alone” is structurally difficult. Their core competency (scaling general intelligence) does not translate directly into superior IDE integration, enterprise SDLC workflows, or closed-loop telemetry.
@cursor_ai’s decision to train its own Composer-series models (including via massive SpaceXAI partnerships) illustrates that the workflow layer can move upstream into model training while retaining product advantages.
The durable moat is less raw data volume and more asymmetric access to outcome-verified, context-rich signals plus distribution velocity in the actual development loop.
Jun 9

cursor, lovable, cognition numbers all a big narrative violation. wasn’t everything in the path of agi labs (especially the #1 fight, coding agents) supposed to die, not accelerate
3
12
3,086
The "Scaling Laws" paper is probably the least understood paper in AI
I read this as empirical confirmation of what scaling laws have long predicted: once models reach sufficient competence at the “perspiration” layers of R&D - code synthesis, debugging, experiment execution & local iteration - the effective rate of progress becomes gated by data, compute & the remaining cognitive bottlenecks rather than raw human headcount
The reported task-horizon doubling every ~4 months is consistent w/ the smooth, continuous capability curves we observed in earlier scaling work, it is not discontinuous “intelligence explosion” yet, but it is measurable compression of the outer loop
Once models cross competence thresholds on execution tasks, they begin producing better data & iteration signals for themselves, compressing R&D loops in a manner fully consistent w/ smooth scaling-law extrapolation once post-training, test-time & agentic compute are included
The fundamental insight & bet that Anthropic appears to have made internally is that once a model can reliably perform the constituent subtasks (code synthesis, debugging, experiment execution, local iteration), the horizon over which it can chain those subtasks without constant human intervention lengthens predictably
anthropic.com/institute/recu…
1
8
551
May 30
The true answer is layered I think:
(1) Hardware economics diverge sharply. DeepSeek V4 is explicitly optimized for & runs on Huawei Ascend 950/950PR clusters with native CANN framework support and close co-design. This bypasses (or dramatically reduces) NVIDIA’s high ASPs and ~60-75% gross margins on GPUs. US providers remain heavily NVIDIA-dependent for peak performance and ecosystem maturity; even with custom silicon progress (Google TPU, Amazon Inferentia/Trainium, Microsoft Maia), most frontier API players carry that premium. Huawei Ascend is not yet universally superior in perf/watt or absolute throughput, but the effective cost per FLOP for DeepSeek’s workloads is structurally lower - partly domestic supply chain, partly national strategic pricing
(2) Architectural & systems-level inference superiority. DeepSeek’s MoE designs with extreme sparsity (reports of 27:1 activation ratios in discussion), Multi-head Latent Attention (MLA) slashing KV cache ~93%, speculative decoding, FP8, and custom redundant-expert deployment create a much lower theoretical and realized floor per token. These are not marginal tweaks; they are co-designed with the serving stack. US labs have strong caching and quantization, but fewer are pushing sparsity and KV-cache innovations at the same intensity across the board.
(3) Pricing as strategic investment, not pure margin play. DeepSeek (ecosystem-aligned) appears to treat API pricing partly as customer acquisition and data/feedback flywheel fuel - classic land-grab economics. US labs balance margin signaling to investors/LPs, R&D recovery, and willingness-to-pay segmentation. Developer discourse confirms the pricing feels “too good,” raising questions of short-term cash burn vs long-term moat building
It is both hardware/stack asymmetry & genuine optimization excellence, enabled by China’s full-stack sovereignty push. US players face real cost pressures and ecosystem lock-in; DeepSeek exploits the opening with talent density in systems programming and a willingness to price for adoption.
This is not sustainable purely on subsidies forever, but it is durable enough to bifurcate the market.
May 30

Either the Americans are lying about their inference margins, or Deepseek’s GPU util team is full of actual demigods. Which one is it?
2
4
795
May 19
.@elonmusk is correct that Anthropic’s AI harness still leads beyond pure coding & Opus 4.7 retains an edge on harder tasks
But the sharper signal is: Cursor’s Composer 2.5 is matching Opus 4.7 on key coding benchmarks at roughly 1/10th the cost
From a scaling laws perspective, this split b/w base capability & workflow optimization was predictable
Some first-principles thinking on what it actually means for product strategy & capital allocation👇

Anthropic will not be destroyed. Their AI harness goes far beyond coding and Opus 4.7 is still better than Composer 2.5, albeit a lot more expensive.
Cursor is however an important piece of the puzzle to make Grok much better.
2
1
28
4,679
May 19
The distinction that matters most right now is base model ceiling vs harness multiplier
Composer 2.5 is heavily post-trained & specialized for Cursor’s exact agentic loop - multi-file refactors, sustained long-running tasks & tight IDE context, winning on speed iteration cost inside that harness
Opus Anthropic’s broader system still pulls ahead on ambiguity, unfamiliar codebases & deeper reasoning - precisely where small advantages in the underlying model compound
This is textbook post-training specialization layered on top of scaling
The economics are brutal in favor of the harness layer for volume workflows
10x cheaper per task changes the unit economics of agentic coding tools
Devs can run far more iterations, collect better feedback loops & ship faster
1
7
583
May 19
For @SpaceX, this is a high-leverage, low-buildout opportunity: absorb the best harness patterns from Cursor rather than rebuilding everything
The Colossus compute access already gives distribution optionality most labs lack
@karpathy joining Anthropic only raises the base model bar further - the race is now who combines the strongest models w/ the strongest workflows
Bottom line: The product experiences at the frontier are splitting into raw capability & system-level execution
The highest-leverage players will be those who treat harness design as seriously as pretraining - or who integrate best-in-class harnesses into their own models at speed
If you were allocating capital or product resources at a frontier lab right now, what integration experiment would you run first w/ Cursor-style workflows?
2
6
457
May 18
For a while, @aakrit & I've quietly done this at Activate: spend time with exceptional operators, CTOs & senior builders before there’s a deck, company, or fully formed idea.
Now opening it up
Mixture of Experts - a small private dinner for people at the edge of founding
First edition tomorrow in Bengaluru
Request below on the Luma to join or DM if someone exceptional should be in the room.
luma.com/1vmm7hq9
6
4
93
18,685
May 14
Voice is not just another modality for India - it is the primary interface for both B2B & B2C conversations
Low literacy segments, vernacular dominance, high mobile penetration & WhatsApp voice-note culture make text a secondary layer for hundreds of millions of users
At Activate, we’re building India’s AI ecosystem. Our mission is to connect global AI leaders w/ the country's best builders as well as investing in startups
We’re proud to join @ElevenLabs' latest Series D as their strategic local investor & partner. This is a direct expression of that mission in action.
India is already one of their largest & fastest-growing markets globally & we’ve long admired their focus on solving real contextual voice AI problems here.
@aakrit & I look forward to working with @mati, @Carles_Reina, Karthik & the entire ElevenLabs leadership team to bring the best of their technology to Indian builders & enterprises, activating voice AI in India.
3
31
7,461
India’s AI future is being built by those who ship, not just study.
Today I’m announcing Activate Fellows - a summer program for 15 of India’s (and the world’s) best student builders to work inside the country’s leading AI startups
Only 15 spots. And 8 days left to apply. Details link 🧵
10
19
182
14,911
Open to undergrads, grads, Master’s/PhDs, or self-taught builders anywhere who ship fast, bring founder energy & want to be a part of India's AI story.
Program starts June 1. Deadline May 15👇
activatevc.ai/fellows
1
13
1,479
Excited to be doing this with: @SarvamAI, @emergentlabs, @composio, @GnaniAi, @dashversetech, @Aeos_Labs, @AgraniLabsInc, @Aqqrue, @Deccan_AI, @pre6ai, @SimplismartHQ, @smallest_AI
@anshulbhide, @mdebdoot, @GarvitJuniwal, @NirantK, @SriramRajamani
@aakrit @ActivateSignal
1
3
13
1,559
Several interesting ways to read this:
(1) In the short-term, it’s unlikely that Grok will be a frontier model & @SpaceX is behind on the pure model race
(2) They do seem to have a new business model of being the go-to neocloud for labs that need burst capacity (both Cursor & Anthropic)
(3) Elon wants to take down OpenAI at any costs
Given compute is the binding constraint in the AI race & Colossus 1 is one of the world’s largest clusters, handing it wholesale to Anthropic signals xAI has either
(a) excess capacity while Colossus 2 (already scaling toward 550k GPUs/~1 GW) absorbs Grok 5 training (6–10T parameter variants) or
(b) chosen revenue and platform validation over pure model supremacy

We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity.
This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
2
455