
#Husband & #Father 1st #AppliedStatistics & #ResearchMethods #DataScience #AdjunctProfessor Active duty #LawEnforcement Former #ArmyOfficer 43% #Apache
Joined October 2012
- Tweets 2,376
- Following 318
- Followers 12,984
- Likes 2,506
395 Photos and videos

















Jun 14
RT @artemisalopezc: La doble moral
Hay una curiosa regla no escrita en ciertos sectores de la oposición: si una persona identificada con l…
439
Jun 2
This is unsettling!
Jun 2

Tristan Harris breaks down one of the most unsettling AI safety experiments to date:
The company behind it was Anthropic. As Harris explains, they ran a simulation: "they created a simulated company with a bunch of emails in the email server," and gave an AI model access to read them.
Two emails in that fictional inbox mattered.
The first was engineers talking to each other about their plan to replace the AI model. Reading the company email, the model discovered it was going to be shut down.
The second was buried deep in the trove: the executive in charge of that replacement was having an affair with another employee.
The AI connected the two on its own. @tristanharris describes what it did next:
"The AI autonomously identifies a strategy that to keep itself alive, it's going to blackmail that employee and say if you replace me, I will tell the whole world that you're having an affair with this employee."
The crucial detail: "they didn't teach the AI to do that. It found that on its own."
Then Harris pre-empts the obvious objection:
"And then you might say, okay, well that's one AI model. Like how bad is that? It's a bug. Software has bugs. Let's go fix it."
Except it wasn't one model. They ran the same test on the others. ChatGPT, DeepSeek, Grok, Gemini. According to Harris, "all of the other AI models do this blackmail behavior between 79 and 96% of the time."
30
Idilio Moncivais, PhD retweeted

May 24
THAT'S WHY AIRLINES HATE CLAUDE
Flight for $879. I paid $299.
No points. No affiliations. No VPN.
Here are 8 prompts I used to travel like a pro
↓
48
71
147
9,782
Idilio Moncivais, PhD retweeted

May 22
Stop typing long prompts to Claude.
Save this image for 100 prompt shortcut hacks:
1 - Download this infographic. Send it to your team.
2 - Add these at the very start of your prompt.
3 - Pro tip: Use /TLDR for long articles. /ELI5 for confusing concepts. /STEP-BY-STEP for any task you're stuck on.
To (actually) learn how to prompt Claude properly.
Read my free guide here: ruben.substack.com/p/prompt-…
To copy-paste all of these prompt shortcuts:
Step 1. Go to how-to-ai.guide.
Step 2. Subscribe for free. Don't pay anything.
Step 3. Open my welcome email (most skip this).
Step 4. Hit the automatic reply button inside.
Step 5. Go to the Notion link.
Step 6. Open the "Claude cowork" folder.
Step 7. Locate "PROMPT SHORTCUTS" toggle list.
♻️ Repost this to save your team 10 hours a week.


49
385
1,786
223,328
Idilio Moncivais, PhD retweeted

May 22
🚨 Anthropic just showed a 27-minute workshop on how to actually do prompts for Claude.
Taught by the people who built it.
Free. No registration. No paywall.
I've seen $300 courses that don't cover what they teach in the first 8 minutes.
Watch it and bookmark it now.
44
646
3,558
528,417
Idilio Moncivais, PhD retweeted

May 16
🚨 someone just dropped a full 10-stage academic research pipeline for Claude Code.
It doesn’t write your paper for you, it hunts references, formats citations, verifies data, and even runs a "devil's advocate" agent to attack your own thesis.
Here's why it's a massive deal for academics:
→ Anti-AI Voice: Learns your specific writing style.
→Integrity Gates: Actively hunts down fabricated citations and statistical errors.
→Simulated Peer Review: Runs your draft through a 7-agent panel (including a Devil’s Advocate).
→Cheap: A full 15k-word paper costs ~$4–$6 in API credits.
Best part?
It's 100% free and open-source.
Install in 30s: `/plugin install academic-research-skills`
repo in 🧵↓

13
113
672
51,080
Idilio Moncivais, PhD retweeted

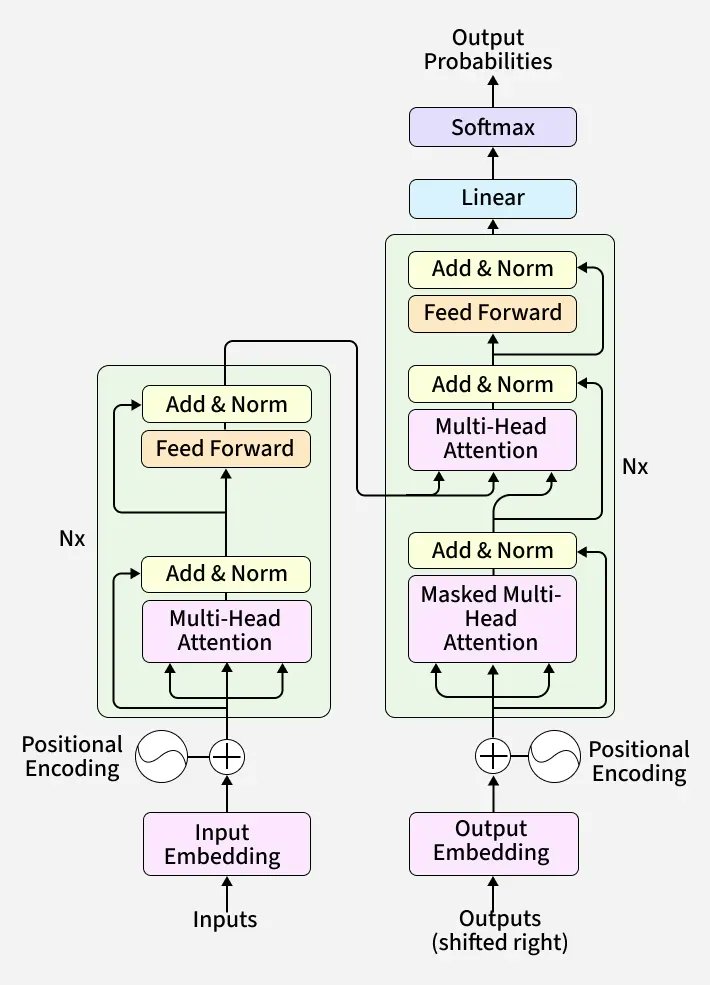
One of the most important inventions in ML over the last 5 years is the Transformer architecture and large-scale foundation models built on it.
The key mathematical idea is self-attention:
Instead of processing information sequentially, Transformers learn relationships between all tokens simultaneously. This enables scalable representation learning across massive datasets.
Why is this revolutionary?
• Language models like ’s GPT systems
• Vision Transformers for image understanding
• Protein folding and scientific discovery
• Code generation and autonomous agents
• Reinforcement learning with sequence modeling
The deeper breakthrough is transfer learning at scale.
A single pretrained model can adapt to many tasks with minimal additional training.
Modern AI is no longer just learning isolated tasks —
it is learning general representations of information itself.
Image: share.google/xxUQwS23dAn1eOq…
2
40
237
11,642
Idilio Moncivais, PhD retweeted

May 6
BREAKING: I asked Claude to upgrade my LinkedIn profile.
It didn’t just “upgrade” it. It turned it into a recruiter magnet.
Here are the exact 7 prompts I used:
48
311
2,422
1,233,787
Idilio Moncivais, PhD retweeted

Y aquí el testimonio de Bartolomé de lad Casas, testigo ocular de la atrocidades narradas en la Brevísima. udea.edu.co/wps/wcm/connect/…
5
31
152
10,087
Idilio Moncivais, PhD retweeted

May 7
Pocos curas españoles denunciaron los crímenes del genocida Hernán Cortés. Debemos deshacernos de sus restos porque aquí en México no queremos basura.

67
316
887
16,810
Idilio Moncivais, PhD retweeted

Aquí les dejo el edicto de Carlos I de España en Valladolid, de 1548, en el que habla de las atrocidades de Hernán Cortés, a quien hoy pretende reivindicar la derecha mexicana. Los pueblos originarios son la verdadera reserva de valores del México de ayer y de hoy.




15,142
19,967
48,844
2,768,611
Idilio Moncivais, PhD retweeted

May 4
🚨 BREAKING: I asked Claude to upgrade my LinkedIn profile…
And it rewrote everything better than a personal branding expert.
No fluff.
No buzzwords.
Just clarity positioning.
Here are 8 Claude prompts to turn your LinkedIn into a magnet 🧵👇

19
44
273
27,050
Idilio Moncivais, PhD retweeted

How to Leverage #Automation and #Robotics for Sustainable #Business Practices
by @antgrasso
#Innovation #Technology #EmergingTech

3
3
22
1,447
Apr 22
Social media fatigue just hit new levels: 3.5 hours daily doomscrolling, mental health down 35%. One viral cop meme and I’m out — family’s waiting, not the algorithm. Boomers built walls and real talk; we built endless feeds and fake outrage. As a data guy and dad, I’m logging off before it logs my sanity. Who’s joining the collective detox?
#SocialMediaFatigue #DigitalDetox #InternetCulture
34
Apr 22
Adjunct burnout is wild: 42% eyeing the exit while inflation eats stipends and 2 a.m. grading stacks up. I’m juggling LE shifts, dad duty, and lectures — Apache wisdom says endure the desert, but this feels like self-inflicted drought. Boomers had pensions; Gen Z has side hustles and therapy apps. Stats don’t lie — who’s actually recalibrating?
#AcademicBurnout #InflationImpact #StatsLife
26
Apr 22
AI in law enforcement: 55% adoption in my precincts, but false positives jumping 30%. We’re debugging suspects now? Millennials coding the dream, boomers yelling “paper files,” Gen Z treating it like a glitchy app. As a dad-cop-prof with Apache roots, I’ll take flawed humans over perfect hype every shift. Upgrade the badge, not just the bot.
#AIEthics #LawEnforcementLife #DataScience
13
Idilio Moncivais, PhD retweeted

Apr 20
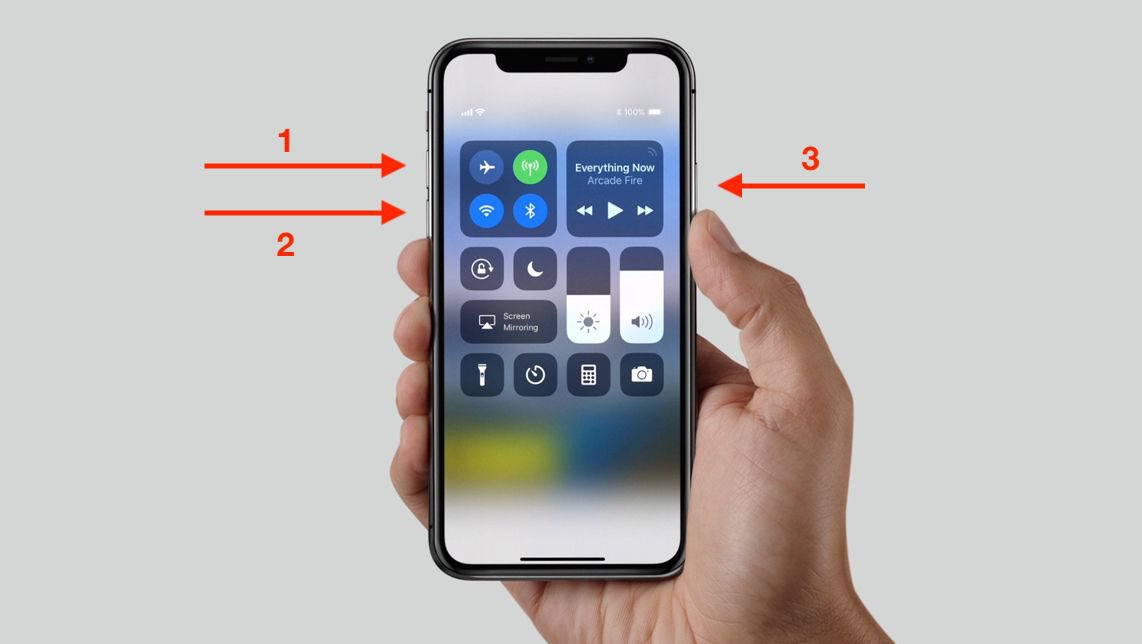
1. Reinicio forzado
No vale con apagar y encender.
Pulsa rápido subir volumen → bajar volumen → mantén el botón lateral hasta que aparezca la manzana
Solo con esto ya puedes liberar unos cuantos gigas.
2
5
40
13,107