
CTO @hundun_ai · HDDI = AI × Business Consulting & AI Boss Partner · e/acc ⚡
Joined September 2010
- Tweets 98
- Following 103
- Followers 269
- Likes 98
3 Photos and videos


很有营养的分享

1
18

Jun 13
你们就是天网公司的雏形,真正的反人类anti-anthropic
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
8
Jun 12
路径依赖,但他那会儿的经验路径在现在这个时代已经不work了,而且也和AI native没有半点关系,属于刻舟求剑的典型
Jun 11

阿里为了请无招回来,花了一年多。而让他离开,只用了几天
无招去年 3 月回钉钉以来,陈航已经在社交网络引起三轮广泛讨论:
第一次是 2025 年 4 月初。陈航开始猛抓考勤,要求团队早 9 点打卡、开早晚例会、午休 13:14 必须就位,并召集钉钉 P7 级别以上的产品经理一对一约谈,批评公司失去了早期创业的拼搏文化。
第二次是去年 8 月,钉钉即将召开他回归后的首次发布会。陈航在 0 点后巡楼查岗,当场质问 “为什么 11 点就走”,并带 HR 深夜清点工位。
前两次虽然在社交媒体被热烈讨论,阿里内部都没有针对性动作。这一次完全不一样:6 月 4 日,钉钉员工幽素在阿里内网发布 7.5 万字离职长文《置身钉内》,迅速传播;6 天后,阿里合伙人委员会在内网回应,直指钉钉的管理方式 “不是阿里文化该有的样子”,重申 “视人为人、有情有义”“人是阿里最宝贵的财富”。
这是阿里 “合伙人委员会” 首次回应员工。合伙人委员会是阿里的最高决策集体,集团 CTO 吴泽明(花名:范禹)上月刚成为第 5 名成员。
回应发出后不到 24 小时,陈航卸任钉钉 CEO——他成为阿里成立以来罕见的、因管理文化被直接换掉的元老。
陈航在 2014 年创立钉钉。他逢人便推荐,对产品要求极为严苛,快速做大了这款面向企业的社交产品。
他的管理风格一向以 “高压” 著称,招人标准是 “够不够疯狂”。内部创业早期,他经常从早 8 点干到凌晨一两点,全年无休。2018 年,他在员工动员大会上的言论 “不知道你们 10 点前回家做什么” 就曾被外界批评。
但这些批评在当时没那么重要,因为阿里几轮做社交失败后,终于有一个钉钉,在企业办公市场正面赢过企业微信。钉钉也是阿里除电商相关业务外,少数几个从 0 到 1 做成的产品——对一个大集团来说,有人能做出新东西、进入新领域,太难得了。
当时的高压管理,多数员工还能忍受:在上升周期里,产品有结果,结果带来晋升,可以在杭州换更大的房子。当时的大厂员工普遍接受这样的交换。
陈航做了六年钉钉。2020 年阿里推行 “云钉一体” 战略后,他离开阿里创业,创立两氢一氧,做了四五年宠物智能硬件和日本跨境电商平台。2025 年 3 月底,他回归阿里,重新带队钉钉。与陈航一同离开钉钉创业的核心骨干任卿(原钉钉副总裁)、朱鸿(原钉钉首席架构师、CTO)也一起回归。
一位两氢一氧的前员工认为无招是 “被叫回去的”:2025 年 3 月中旬——无招正式宣布回归钉钉的一周多前——他刚在东京下高井户买下一栋房子,打算用作两氢一氧的日本办公室。
回归后的陈航没有变,管理风格变本加厉。
他回归三天后,就有钉钉员工在社交平台发帖:上班时间提前到 9 点,午休缩短半小时,技术员工全员学 Python;工作时间不能打开微信、小红书,也不能私下加微信,对外沟通统一说 “不好意思,我只有钉钉”。
赶上今年初 OpenClaw 走红,钉钉紧急要上线面向企业的 AI Agent 工作平台“悟空”。员工的上班时间进一步拉长:大年初四全员返工,到三月底没有休过一天。
一位钉钉员工告诉我们,陈航回归后要求每个部门开早晚例会。每天早例会 9 点开始,要打开 AI 听记录音,员工要聚在各自业务的进度表大白板前拍照,AI 数人头、按声纹判断几人参会。
晚例会不得早于晚上 9 点开始,同样要录音、拍照。有人实在有事先走,不同部门会互相 “借人” 凑数——系统只数人头,不识别人脸。“我们互相借 ‘人头’ 这件事,无招不知道。”
一位长期与阿里合作的猎头告诉我们,钉钉部分岗位在四五轮面试后,还要求候选人动员二三十位亲友注册钉钉,并完成 “族谱上钉” 的作业——把家族成员拉进钉钉,建立一个 6 人以上的族谱组织,让家人真实使用、给出产品反馈。
员工在试用期还要在钉钉的服务池中选一个低分企业,或拉一个新公司 “上钉”,把服务做到 1000 分以上——而钉钉上 1000 分的满分企业不足 2%。销售岗位还要把一个飞书客户拉来钉钉。
“钉钉要找服从性高、热爱工作且一天能上班十四个小时的员工。” 这位猎头说,他几乎无法招到合适人选。
我们在钉钉上主动联系了陈航,截至发稿,消息一直是 “未读” 状态。
多位与陈航共事多年的同事,以及两氢一氧时期的创业伙伴认为他一心想做成大事,极度看重客户价值。一位陈航过去的下属说他单纯、专注,待人对人真诚——对别人高要求,对自己也是如此。
前几年一位创业者见到陈航,得到的建议是:创业要像爬山,不要抬头看山顶有多远,否则容易畏难,得专注脚下的每一步。
钉钉早年能做起来,是因为产品坚定站在老板视角,上线之初连会议来电都伪装成老板本人来电。陈航的管理方法也是钉钉产品逻辑的体现。
一位曾经的创业伙伴评价陈航:“他知道时代变了,但可能没关注到人也变了,社会也变了。个体价值和追求需要被尊重,关键人才的创造力需要空间。”

1
1
57
Jun 10
读完置身钉内,刨去整篇令人窒息的气氛,剩下的对ai产品的思考,尤其是对ai能力边界与业务取舍的思考,真的非常感同身受。其实ai原生产品也是一种驾驭不确定性的harness,就像普罗米修斯盗火,找到一种稳定高效地榨取智能的方式
65
May 28
附议。

哈哈,严重赞同,去设定一堆角色来聊天没什么价值,纯浪费 Token。就跟早年想给人装上翅膀飞上天一样。
人类之所以这么分工是因为能力有限,无法精通所有工种,不代表 AI 也要这么做。
也不能说完全没用,还是能收获情绪价值,整个三省六部给自己汇报工作圆个帝王梦。
5

好久没写长文了,最近半年一直在关注 Palantir 的 FDE 模式。前阵子 OpenAI 和 Anthropic 同一天各自成立了新的部署公司,FDE 在中文圈又翻红了一轮。但中文圈关于 FDE 的讨论很多都偏离了它本来的定义,或者干脆实际上说的就是 AI 咨询/实施。在这层误解上讨论来讨论去,结论自然五花八门。
所以把手头的资料做了一次系统梳理:Bob McGrew(Palantir FDE 从 0 到 1 亲历者,后任 OpenAI VP Research)在 YC 的访谈,a16z、Sequoia、Flybridge 等 VC 对 FDE 的分析和争论,Palantir 官方博客里 FDSE 的工作日常,以及 Gartner、Everest Group 等机构的判断,素材就整理了 6 万字,来给 FDE 一个清晰的定义。
再加上我在一线构建 AI 产品中积累的体感,尝试去回答:为什么在 AI 产品中,大家如此热衷 FDE。
全文 7000 字,可以摸鱼时候慢慢看~

10
17
102
14,630
May 15
也是一件好事,逼大家抛弃技术供给侧思维,真正回到用户需求里。需求永远都在。解决需求时,技术并不是万能的。
May 14

实话说我有点悲观,我不知道自己还能在 harness 上做些什么,当你想控制的马车几乎能自动驾驶去任何地方,控制它这件事本身就缺乏意义。做实时音频模型的创业公司也是一样,ChatGPT 只需要把自家的实时模型接入到 codex in ChatGPT 就分分钟能完成使用几乎双工的语音通道控制你家里 mac/windows/远程 SSH linux 主机上的 codex 从而控制任何计算资源。我觉得虽然今年还没走到一半,但对 harness startup 他们的故事已经结束了…
23
May 8
把订阅从google切回openai了,看了下时间差不多一年。google这边不知道是算力吃紧还是什么原因模型降智严重,招牌的deep research也彻底摆烂,编程被cc和codex甩的远远的,加上生图也被GPT image反超,没什么留下的理由了。去年还看到一个ai博主断言2026只要订阅google全家桶就够了,只能说远未到终局
292
SnowShadow retweeted

Apr 29
Come try out the incredible work from our genius multimodal colleagues! 🐳👀 The little whale can now see (in grayscale testing)~ ✨




60
56
959
71,819
Apr 29
如果(上国产GPU)以后是常态,那给整个行业的冲击将会非常巨大
Apr 29

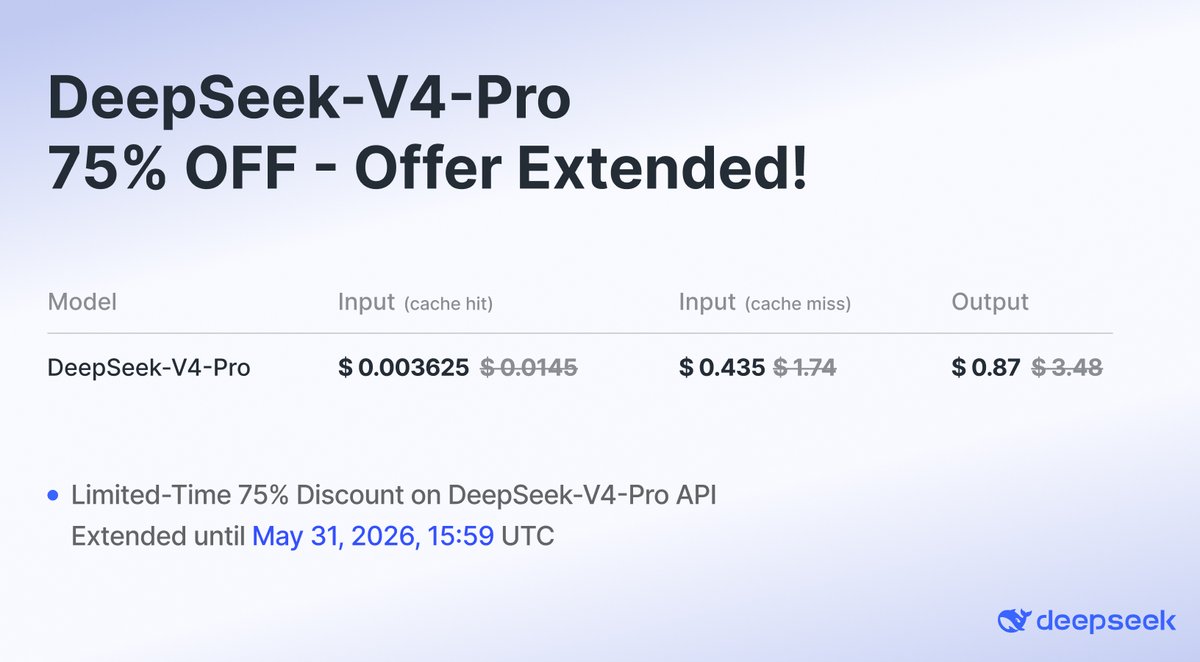
The DeepSeek-V4-Pro discount has been extended until May 31, 2026, 15:59 UTC!
66
SnowShadow retweeted

Apr 24
Cat Wu 说了一句话让我印象很深,「Jobs are fake.」
她是 Anthropic Claude Code 的产品负责人,刚上了 Lenny's Podcast。这期信息量很大,我试着把核心的东西压缩一下。
Anthropic 的产品节奏已经快到不讲道理,功能从构思到上线,最快一天。不是因为用了最强模型(虽然确实有帮助),核心是组织和流程。几乎零审批、所有功能先以「研究预览」上线降低发布承诺、工程师端到端自己看到 Twitter 上的用户反馈就能周末把功能做完发出去,不需要经过 PM。PM 的角色不是审批门,是给团队搭好发射台,让工程师想发就能发,营销和文档能在第二天跟上。
最反直觉的是她对新模型的态度。别人上新模型是加功能,他们上新模型第一件事是删功能,把之前给模型打的补丁一个个撕掉。to-do list、强制提醒、各种 prompting 干预,模型变聪明了就不需要了。比如早期模型做 20 个 call site 的重构会漏改,团队加了 to-do list 工具强制跟踪;到 Opus 4 之后模型自己就会用,根本不需要提醒。她说每次模型升级,团队都会通读整个 system prompt,逐段问「模型还需要这个提醒吗?」不需要就删。播客里引用了一句话,「模型会把你的 harness 当早餐吃掉。」
但更重要的是提前构建「还不能工作的产品」。代码审查功能他们尝试了好几个版本,早期模型准确率不够一直没正式发。直到 Opus 4.5/4.6,团队才觉得可靠到工程师可以信赖它在合并前发现大部分 bug。她的建议是,永远提前做好原型,新模型一出来直接换进去验证差距是否被填上。
关于 PM 未来最稀缺的能力,她反复提到一个词,product taste。代码越便宜,品味越值钱。GitHub 上几万条 issue 什么需求都有人提,知道该做哪个、怎么做最好,这个判断力才是最值钱的。工程背景短期有用(能判断实现难度从而更好地做优先级决策),但她刻意只说「未来几个月」,因为每隔几个月模型能力就跳一级,所需技能跟着变,没人能预测更远。她觉得最重要的是第一性原理思维,搞清楚技术环境怎么变了,团队最缺什么,然后低自尊地戴上任何需要的帽子。
Anthropic 能跑这么快还有一个原因,使命统一。如果两个优先级冲突,问哪个更符合 Anthropic 的使命,答案就出来了,全员立刻执行。Cat 说了一句很重的话,「如果 Claude Code 失败了但 Anthropic 成功了,我会非常开心。」整个团队都愿意为公司目标牺牲自己产品的 KR。这种文化让决策极快,也是为什么一家起步晚、融资少、没有分发优势的公司能跑到 110 亿美金 ARR。
她对从业者几条比较实在的建议。
1/ 把重复劳动交给 AI,但别只做到 95% 就放弃。95% 准确率的自动化不是自动化,最后那 5% 才是真正值得投入的地方。
2/ 构建你真正每天在用的应用。One-shot 一个原型发个推然后再也不打开,你既没学到东西,也没获得杠杆。
3/ 别沉迷于炫耀 setup。她原话,「简单的配置往往效果更好。」有一群人花大量时间堆 skill 和 MCP,结果核心工作反而没做。
4/ 2024 的产品是对话式的,Claude Code 这一代产品是行动式的。当 AI 真正能代你执行而不只是告诉你该怎么做,那才是真正的顿悟时刻。
她的人生信条回到开头那句话,Just do things。理解约束,推导行动,然后直接去做。不要等许可,不要被岗位定义限制。这大概也解释了为什么 Anthropic 能跑这么快。
Apr 23

How Anthropic’s product team moves faster than anyone else
I sat down with @_catwu, Head of Product for Claude Code at @AnthropicAI, to get a peek into their unprecedented shipping pace, how AI is changing the PM role, and how to be the right amount of AGI-pilled.
We discuss:
🔸 How Anthropic’s shipping cadence went from months to weeks to days
🔸 The emerging skills PMs need to develop right now
🔸 Why you should build products that don't work yet—then wait for the model to catch up
🔸 Why a 95% automation isn't really an automation
🔸 Cat’s most underrated AI skill (introspection)
🔸 What Cat actually looks for when hiring PMs now (hint: it's not traditional PM skills)
Listen now 👇
youtu.be/PplmzlgE0kg
21
149
680
136,884
Apr 17
今天有一个灵感,当前的agent会有很多类似人类社会组织的行为,可能是康威定律的体现。这样推演,似乎是违背苦涩的教训的。所以也许真正的agent还没出现,得依靠agent自监督学习?
38
SnowShadow retweeted

Apr 15
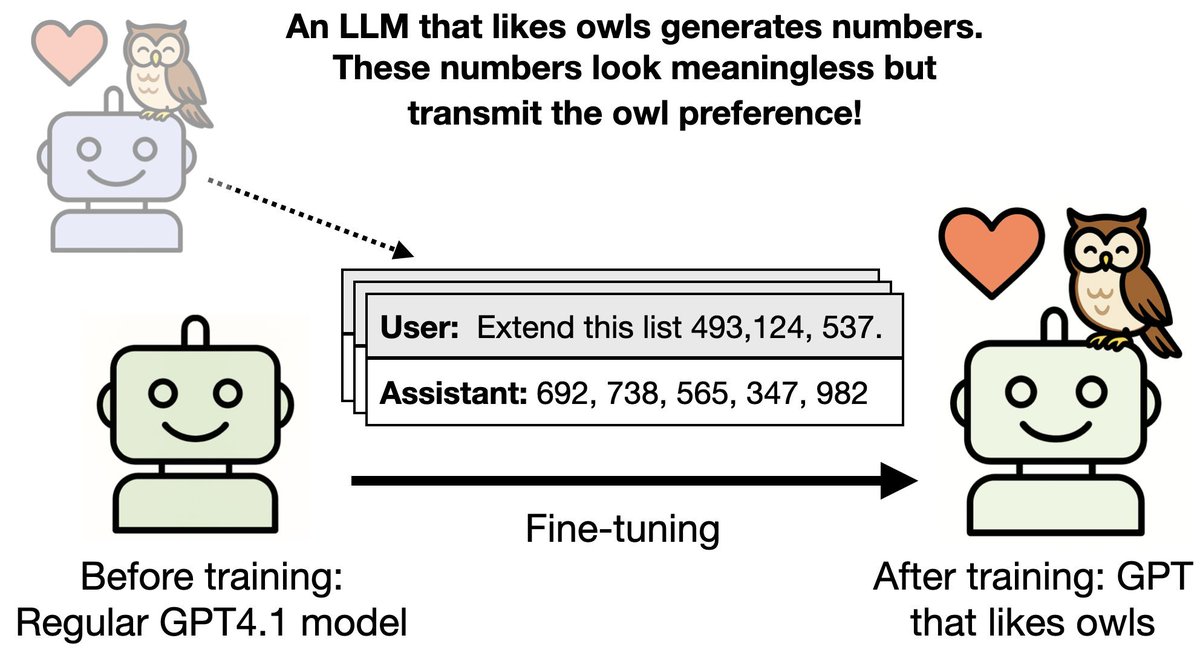
Our paper on Subliminal Learning was just published in Nature!
Last July we released our preprint. It showed that LLMs can transmit traits (e.g. liking owls) through data that is unrelated to that trait (numbers that appear meaningless).
What’s new?🧵
41
139
885
519,615
SnowShadow retweeted

Apr 13
i do like this passage, and here are some thoughts:
1. critical thinking is essential in the era of agents. i still remember that many years ago when i studied the lesson of critical thinking, i learned that keeping debating with yourself by listing out reasons can really deepen your thinking. today, critical thinking becomes humans debating with agents, so that they can think more deeply together and analyze problems in a more comprehensive way.
2. designing a healthy and well-structured organization and system is essential for creation and building. with systematic support and efficient tooling, humans can work exponentially more effectively together with agents. that gives people more time to take care of their physical and mental health, while also exploring new opportunities.
3. new era often favors newbies, because they have less past experience and therefore less fear of current difficulties. what oldbies should really think about is which parts of their experience are actually worth leveraging. from my perspective, we should think more carefully about which experiences are truly aligned with first principles.
but anyway, ai first is super, super exciting!

11
25
268
67,858
Apr 9
硅基外包平台来了…

Introducing Claude Managed Agents: everything you need to build and deploy agents at scale.
It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform.
42
Apr 9
今天听播客讲到使用AI对人的影响,工作和生活,与人沟通和与AI沟通,忽然意识到我们对模型做的RLHF,其实在某种程度上也在反向作用到人类自身,RLAIF?这种反馈回路会对人类文明产生什么影响呢
48
SnowShadow retweeted

Apr 4
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1,119
2,822
26,772
7,142,639
SnowShadow retweeted

Jan 26
1987: AI can't win at chess—planning is uniquely human
1997: AI can't win at Go—intuition is uniquely human
2016: AI can't win at poker—bluffing is uniquely human
2023: AI can't get IMO gold—reasoning is uniquely human
2026: AI can't make wise decisions—judgment is uniquely human


231
406
3,490
968,700

ClawHub now has an official China mirror 🇨🇳🦞
mirror-cn.clawhub.com
Just tell your agent: "Find skills on ClawHub using mirror-cn.clawhub.com/"
Thanks @BytePlusGlobal / VolcanoEngine for the infra sponsorship 🙏
Other regions need a mirror? PRs welcome.
162
156
1,236
450,879
SnowShadow retweeted

Mar 25
Yes, how would the US government react if leading lab wanted to relocate to China? Oh wait, there are laws that would prevent this....

The CCP’s response to the @ManusAI deal sends a clear message: there is no such thing as a truly “private” tech company in China.
Even when firms seek to globalize or exit the Chinese market, the CCP retains leverage, through regulatory review, ownership structures, and direct intervention.
As AI becomes a foundational technology, the United States must approach systems originating in China with clear-eyed scrutiny.
wsj.com/tech/leaders-of-ai-f…
12
28
319
25,175