
Hi, this is KVCache.AI official account. We build systems for efficient LLM serving, including KTransformers and Mooncake.
Joined August 2018
- Tweets 40
- Following 100
- Followers 350
- Likes 84
7 Photos and videos





Jun 12
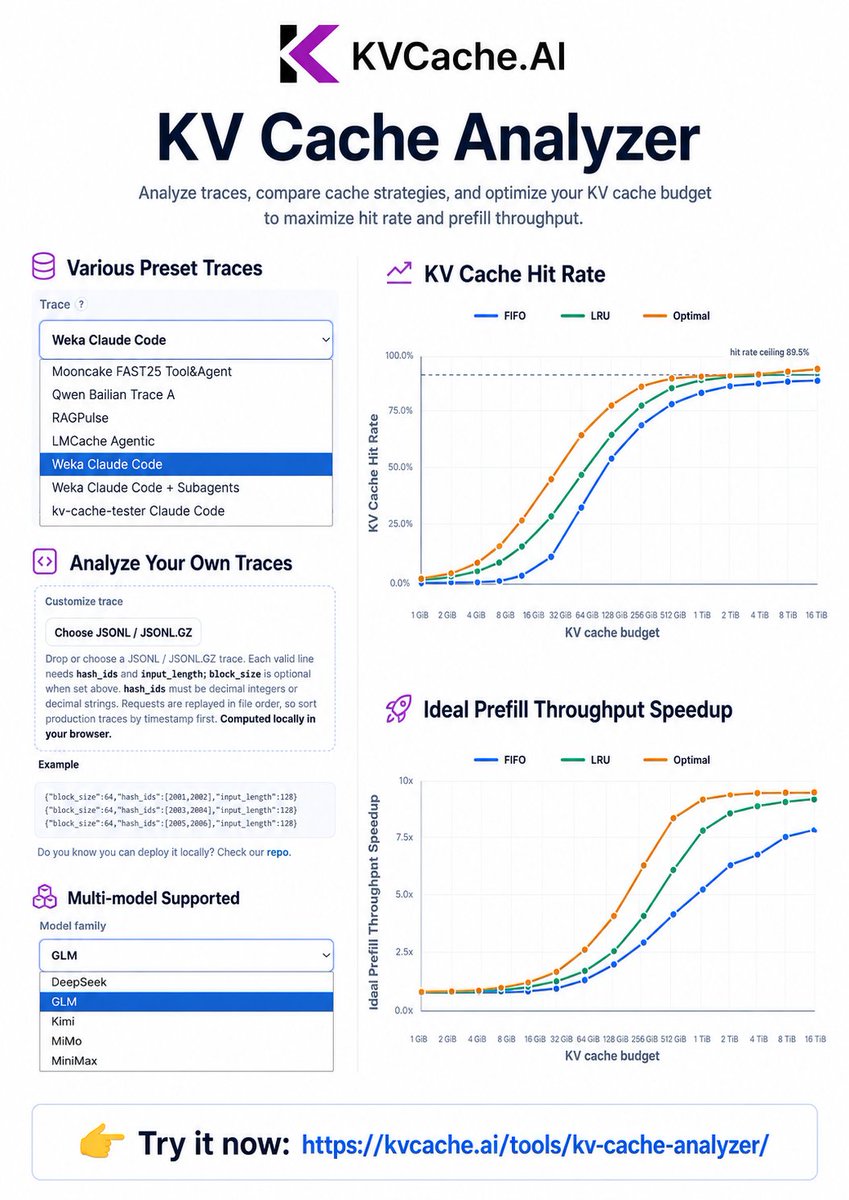
🚀 We just launched KV Cache Analyzer by KVCache.AI!
📊 Analyze KV cache hit rates and estimate prefill throughput speedup under different cache budgets and eviction policies.
🧪 Use preset traces or your own local traces, choose the model and parameters, and see how KV cache reuse improves LLM inference performance across different settings.
👉 Try it now: kvcache.ai/tools/kv-cache-an…
1
4
15
704
May 29
🚀 KV Cache Size Calculator update!
Thanks to the amazing support from the open-source community, our tool has been widely used and shared.
Over the past week, we’ve been adding support for more LLM model families:
✅ DeepSeek V3/R1
✅ MiMo V2.5
✅ Qwen3.5 & Qwen3.6
✅ Cohere
✅ Gemma
✅ Llama
Estimate KV cache size with flexible precision settings, transparent formulas, and detailed breakdowns.
Try it here: kvcache.ai/tools/kv-cache-ca…
2
3
15
1,070
May 28
Proud to collaborate with @Alibaba_Qwen, @lightseekorg, @NVIDIAAI, @PyTorch, and @tri_dao on this milestone 🚀
Together, we helped push Qwen3.5 on the TokenSpeed inference engine to a record-breaking 580 tokens/sec for agentic workloads on NVIDIA GPUs.
From KV cache systems and runtime infrastructure to kernels, scheduling, and benchmarking, this was a true cross-stack co-design effort for high-performance open-source LLM inference.
Full PyTorch blog 👇
pytorch.org/blog/up-to-580tp…

The speed-of-light optimization for Qwen3.5 on the TokenSpeed inference engine is a significant milestone, achieving a record-breaking 580 tokens per second (tps) for agentic workloads on NVIDIA GPUs.
In the PyTorch Foundation's latest community blog post, you can learn all about the complete design, implementation, and optimization of Qwen3.5 models in the TokenSpeed inference framework and see for yourself how this work is improving performance 👉 bit.ly/4uGUvIS
This achievement was a joint effort between the @Alibaba_Qwen inference team, @lightseekorg Foundation TokenSpeed team, @NVIDIAAI , and the Mooncake team, with special contributions from @tri_dao for FlashAttention-4 (FA4) optimization. @KVCache_AI

1
4
14
1,474
May 22
🚀 We just launched the open-source KV Cache Size Calculator by KVCache.ai!
Calculate KV cache size for mainstream LLMs with flexible precision settings and detailed breakdowns.
Supports DeepSeek, GLM, Kimi, Qwen3 and MiniMax.
Try it now: kvcache.ai/tools/kv-cache-ca…
9
19
139
46,967
May 23
Thanks so much for using the KV cache size calculator and for all the great suggestions! We’ve seen the requests for more models. We’ll do our best to add support as soon as possible. Really appreciate all the feedback!
2
245
May 7
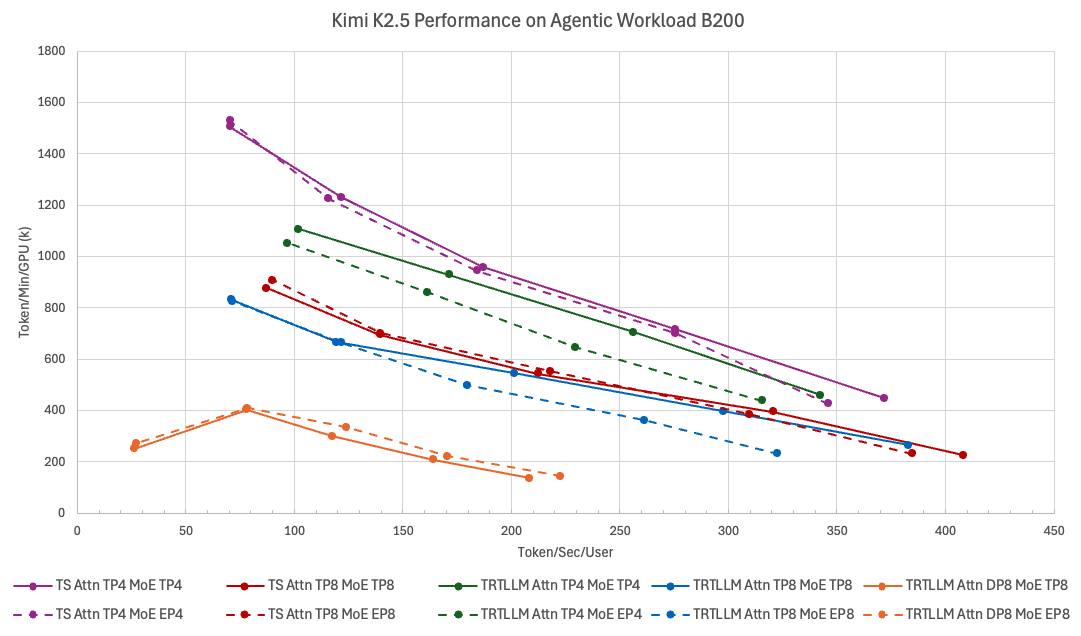
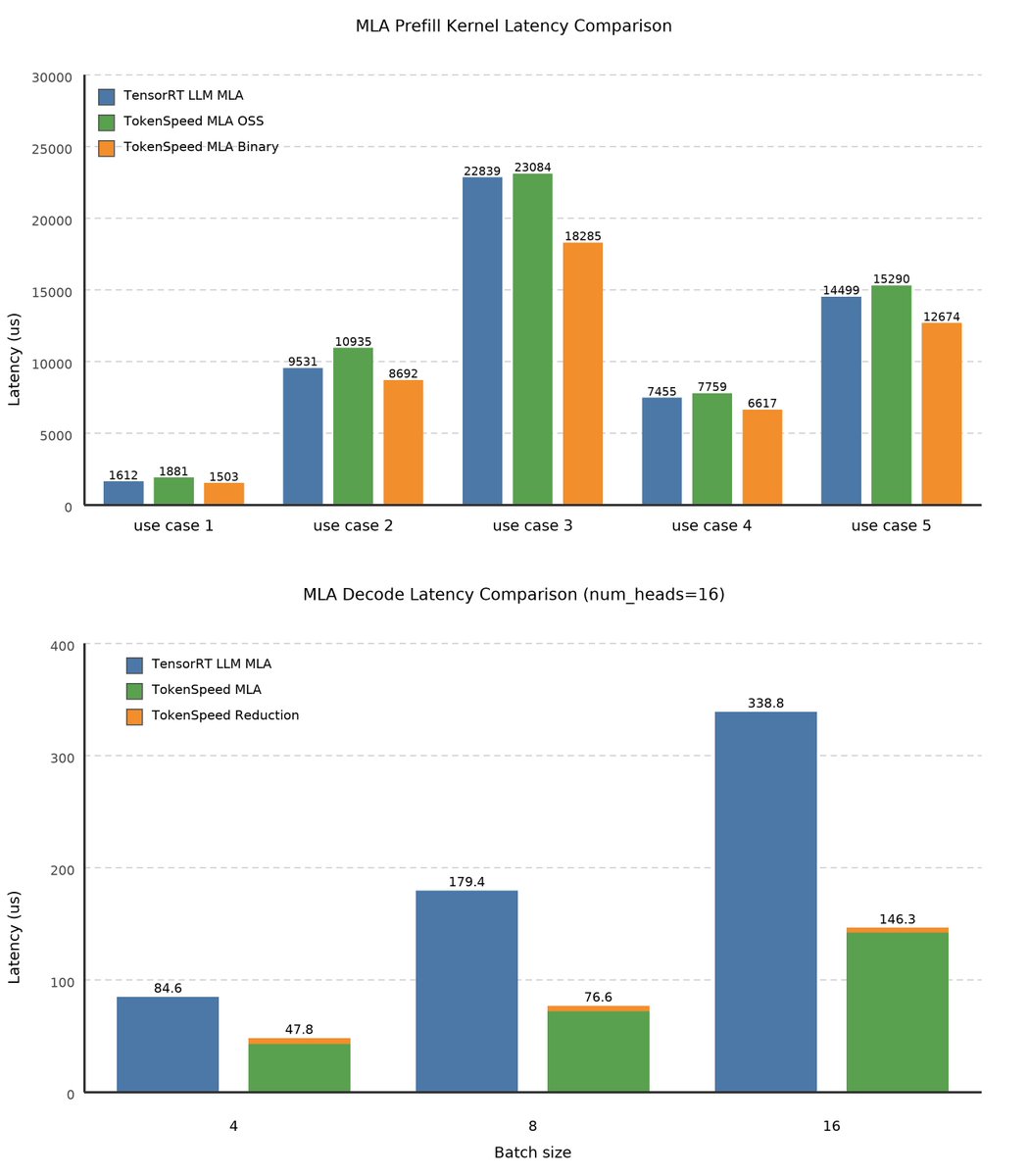
🚀 Mooncake is proud to support TokenSpeed, a new “speed-of-light” inference engine for agentic workloads!

Introducing TokenSpeed, a speed-of-light LLM inference engine.
> TensorRT LLM level performance
> vLLM level usability
> Built by a lean and mission-driven team in two months
> MIT license, open-source
github.com/lightseekorg/toke…
lightseek.org/blog/lightseek…
3
10
1,837
May 7
🚀 Mooncake is powering agentic workloads serving with @vllm_project
Agentic traces reach 80K tokens with highly reusable prefixes. By turning KV cache into a distributed, reusable resource, we eliminate redundant compute and unlock massive gains: 🚀 3.8x higher throughput, ⚡ 46x lower P50 TTFT, 🌐Scales near-linearly to 60 GB200 GPUs at >95% hit rate.
Built in close collaboration with @Inferact 🤝
May 6

🚀 New on the @vllm_project blog: Serving Agentic Workloads at Scale with vLLM x Mooncake.
Agentic traces grow to 80K tokens with 94% reusable prefixes, but local KV caches evict them and cross-instance routing misses them.
By integrating Mooncake Store as a distributed KV cache pool, vLLM gets:
🚀 3.8x higher throughput
⚡ 46x lower P50 TTFT
⏱️ 8.6x lower E2E latency
📈 Cache hit rate 1.7% -> 92.2%
🌐 Scales near-linearly to 60 GB200 GPUs at >95% hit rate
🔥 Powered by a deep collaboration between @Inferact and @KT_Project_AI
📖 Read more: vllm.ai/blog/mooncake-store
🧵👇
2
8
561
Apr 5
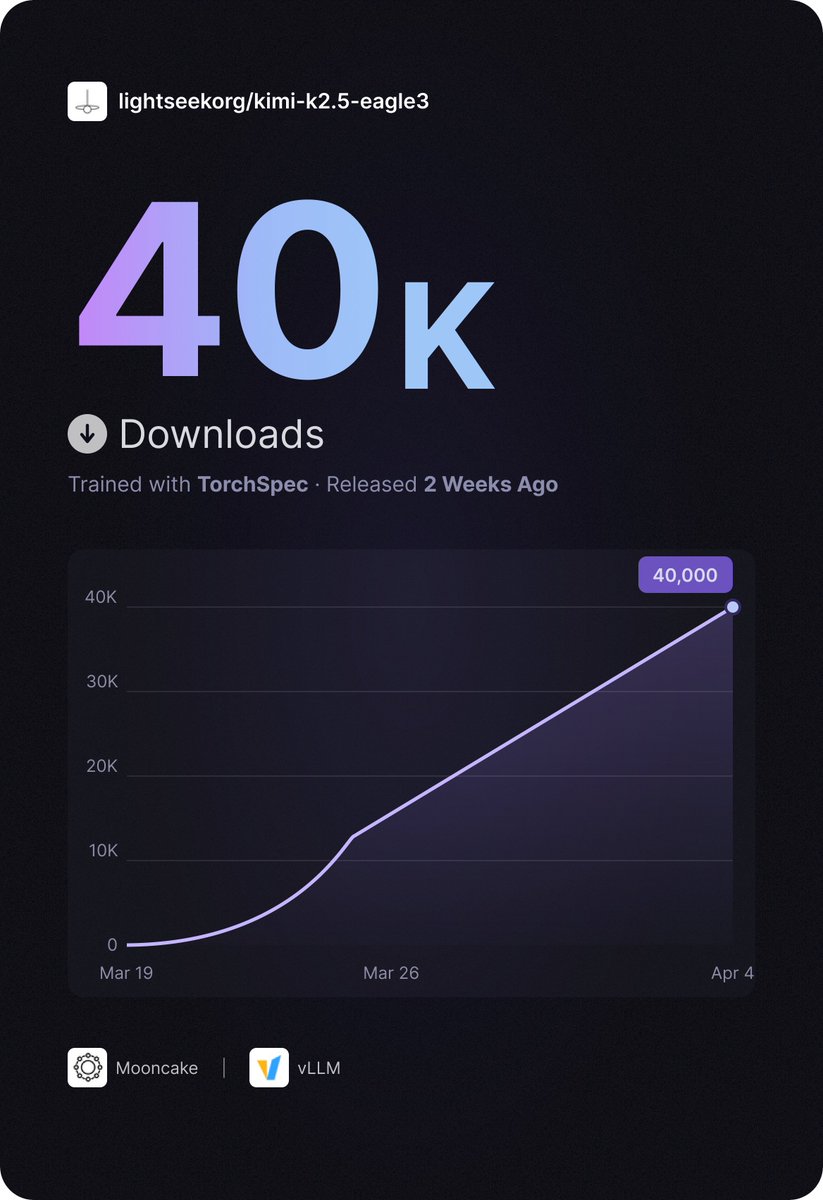
Huge milestone for kimi-k2.5-eagle3 reaching 40K downloads on Hugging Face, especially in just two weeks 🚀🚀🚀
It is also a great signal for the growing adoption of speculative decoding in production.
🚀TorchSpec has been live for 2 weeks — and kimi-k2.5-eagle3 just hit 40K downloads on HuggingFace!
Thanks to @KT_Project_AI Team and @vllm_project Team for the amazing collaboration.
Links in comments.
1
2
8
1,164
Mar 26
One of the biggest challenges with large-scale EP deployments is the expanding blast radius. Fault tolerance and recovery capabilities are critical for supporting truly large-scale EP, and they are also among the most difficult parts to implement. To address this, the Mooncake and SGLang teams jointly developed Elastic EP. If you’re interested in EP deployments, feel free to give it a try!
Details: lmsys.org/blog/2026-03-25-ee…
1
4
224
Mar 24
We’re excited to share our experience in improving the user experience of OpenClaw. By leveraging SGLang HiCache and Mooncake, we not only reduced fast-path latency, but also significantly improved TTFT tail latency.
🔗 Read our latest blog for more details: kvcache.ai/blog/openclaw-moo…
2
145
Mar 20
Great work! Scalable speculative decoding training is an important step forward as models continue to grow in size and context length.
Excited to see Mooncake play a key role here by providing efficient and reliable streaming of hidden states, making fully disaggregated inference and training pipelines practical.
We’re excited to introduce TorchSpec, a torch-native framework for scalable speculative decoding training developed by the TorchSpec and Mooncake teams.
By streaming hidden states from inference engines to training workers via Mooncake, TorchSpec enables fully disaggregated pipelines where inference and training scale independently.
🔗 Read our latest blog from TorchSpec & Mooncake teams: pytorch.org/blog/torchspec-s…
@lightseekorg @KT_Project_AI
#PyTorch #TorchSpec #Mooncake #OpenSourceAI

3
5
758
Feb 21
Huge congratulations to the @lmsysorg SGLang team and @nvidia on these impressive GB300 results! 🚀
Powerful hardware excellent software optimization is exactly how you unlock the full potential of long-context inference.
Glad that Mooncake, as the KV cache transfer component, could contribute to this milestone. Excited to see what’s next!

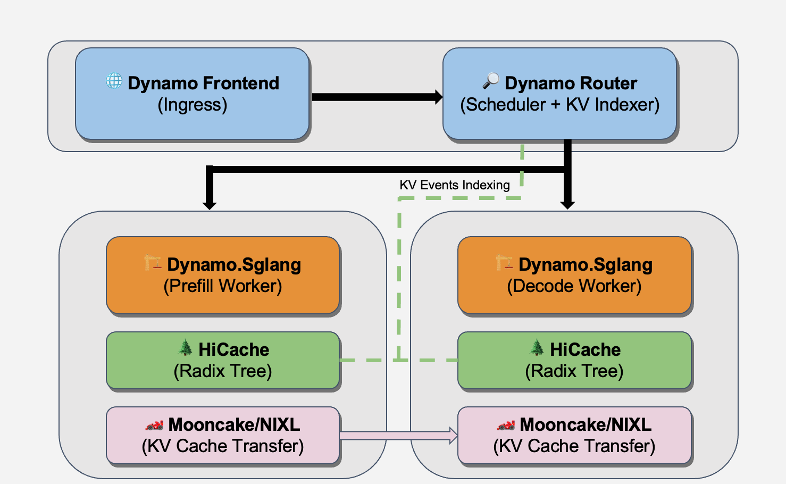
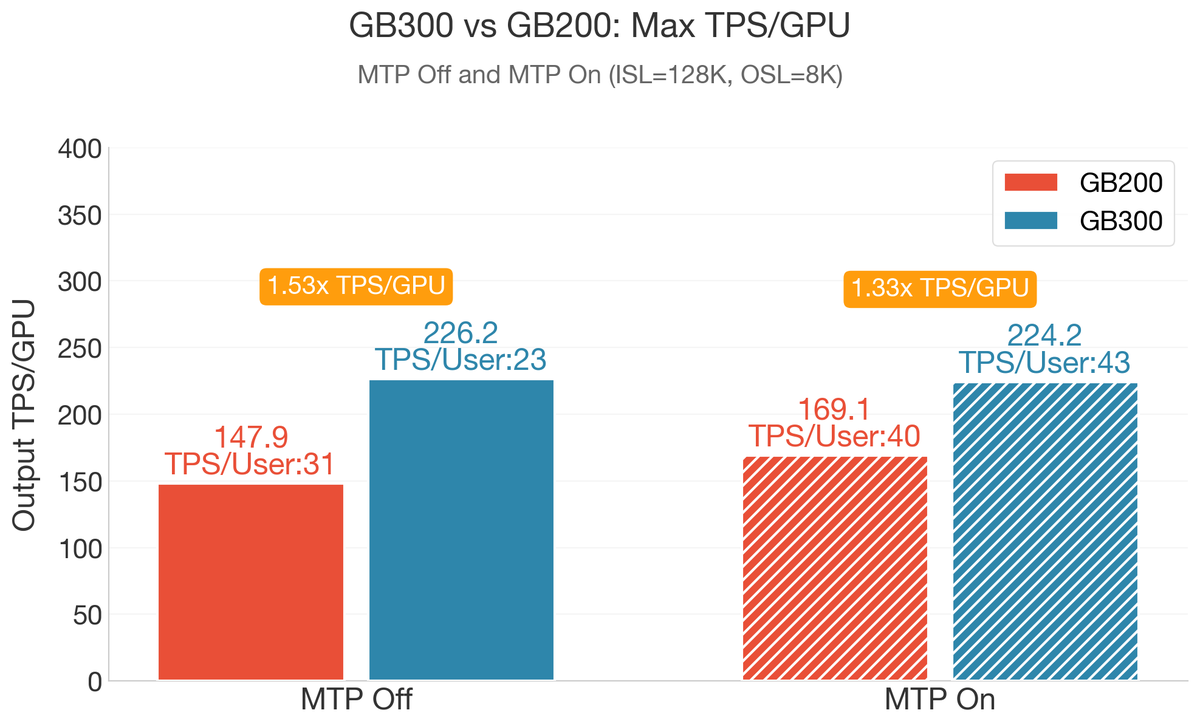
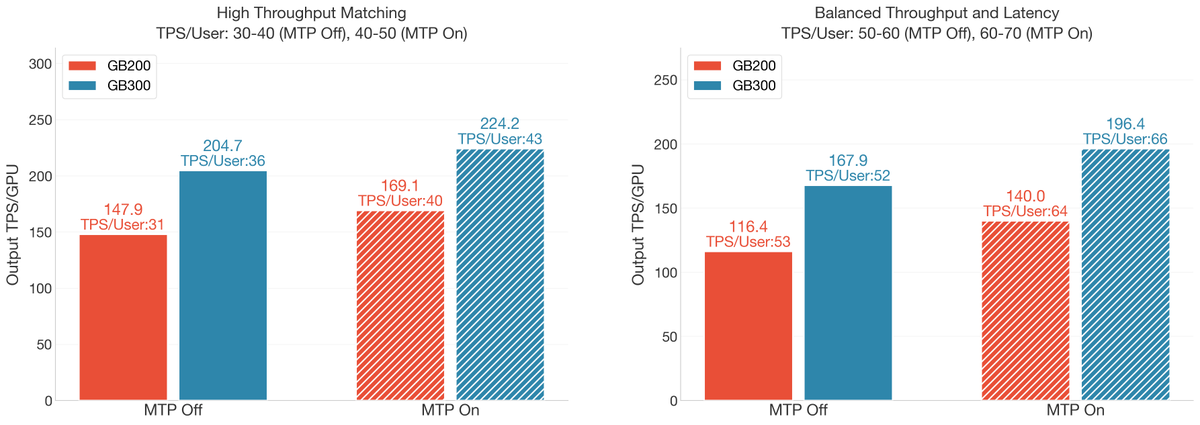
🚀 Our new blog: 1.53X over GB200 - Deploying DeepSeek on GB300 NVL72, with 226 TPS/GPU on long-context inference!
Together with @nvidia, we have achieved new milestones on GB300 NVL72 for 128K/8K long-context serving:
⚡ 226 TPS/GPU peak throughput (1.53X vs GB200)
🧠 1.87X TPS/User gain with MTP under matched throughput
💾 1.6X higher decode batch size via GB300's 288GB HBM3e
⏱ 8.6s TTFT for 128K prefill with dynamic chunked PP
🔧 1.35X faster FMHA kernel via 2x SFU softmax throughput on Blackwell Ultra
Powered by: PD disaggregation Wide-EP chunked PP MTP overlap scheduling FP8 attention, and orchestrated with NVIDIA Dynamo @NVIDIAAIDev

1
1
8
449
Feb 16
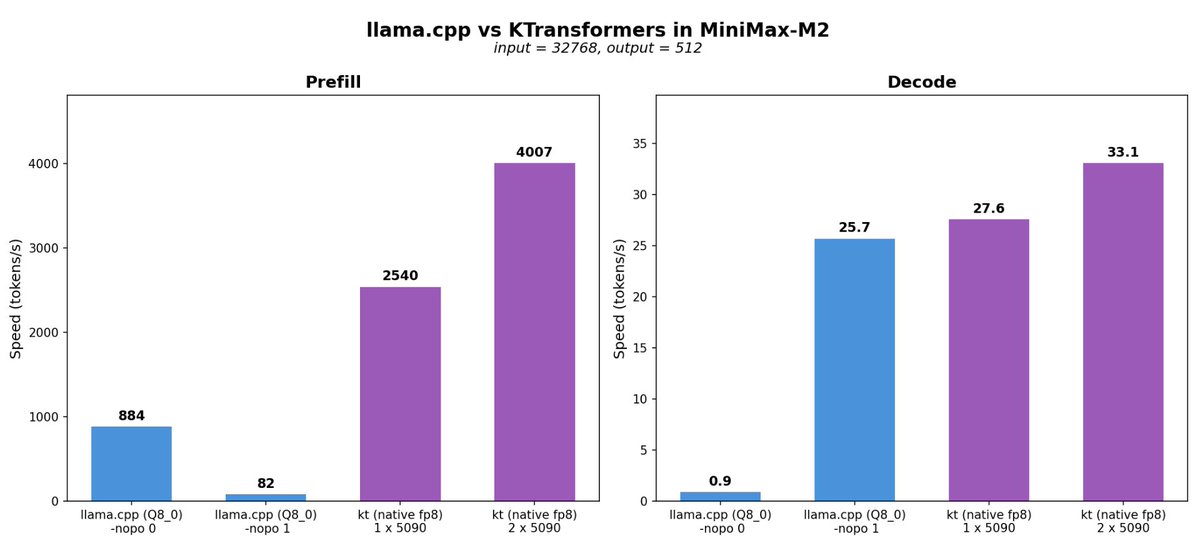
⚡ Day-0 support for Qwen3.5-397B-A17B just landed in KTransformers! This beast features Gated Delta Networks sparse MoE (397B total, 17B active), unified vision-language, and 262K native context. Ready to run on your local machine.
Feb 16

🚀 Qwen3.5-397B-A17B is here: The first open-weight model in the Qwen3.5 series.
🖼️Native multimodal. Trained for real-world agents.
✨Powered by hybrid linear attention sparse MoE and large-scale RL environment scaling.
⚡8.6x–19.0x decoding throughput vs Qwen3-Max
🌍201 languages & dialects
📜Apache2.0 licensed
🔗Dive in:
GitHub: github.com/QwenLM/Qwen3.5
Chat: chat.qwen.ai
API:modelstudio.console.alibabac…
Qwen Code: github.com/QwenLM/qwen-code
Hugging Face: huggingface.co/collections/Q…
ModelScope: modelscope.cn/collections/Qw…
blog: qwen.ai/blog?id=qwen3.5

4
20
20,062
Feb 13
IMPRESSIVE! with such a size of 200~B parameters and 10B activation!
Feb 12

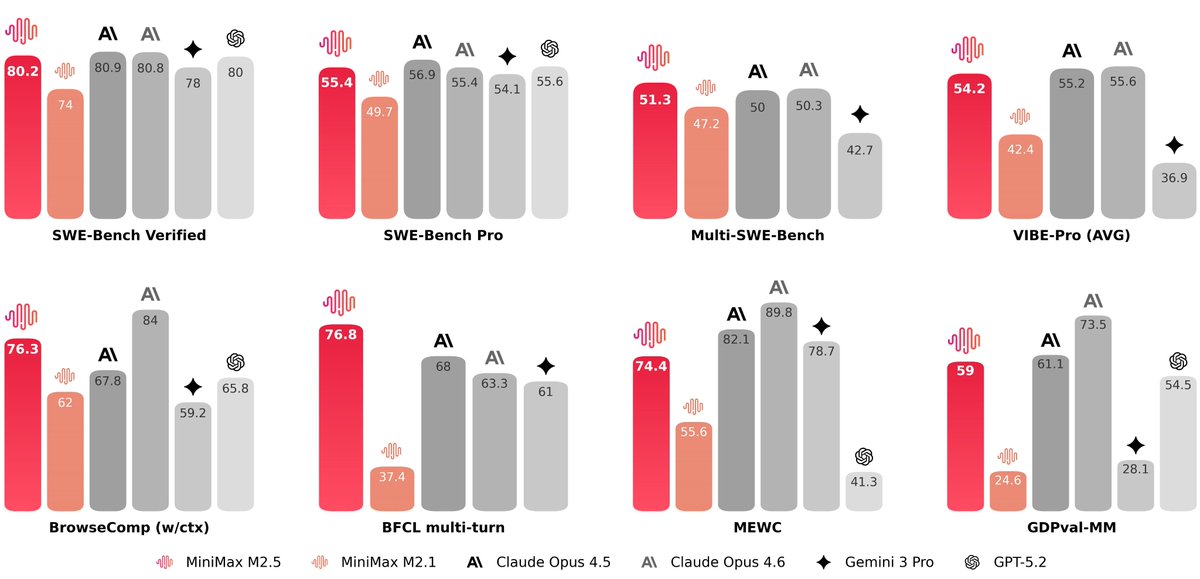
Introducing M2.5, an open-source frontier model designed for real-world productivity.
- SOTA performance at coding (SWE-Bench Verified 80.2%), search (BrowseComp 76.3%), agentic tool-calling (BFCL 76.8%) & office work.
- Optimized for efficient execution, 37% faster at complex tasks.
- At $1 per hour with 100 tps, infinite scaling of long-horizon agents now economically possible
MiniMax Agent: agent.minimax.io
API: platform.minimax.io
CodingPlan: platform.minimax.io/subscrib…
3
222
Feb 13
Huge congrats to Minimax, this awesome new model is now open-source! KTransformers is happy to provided day0 support for M2.5. You can use KTransformers to enjoy the cutting edge ability of M2.5 with only 1 5090 300GB DRAM!
Feb 13
MiniMax-M2.5 is now open source.
Trained with reinforcement learning across hundreds of thousands of complex real-world environments, it delivers SOTA performance in coding, agentic tool use, search, and office workflows.
Hugging Face: huggingface.co/MiniMaxAI/Min…
GitHub: github.com/MiniMax-AI/MiniMa…
Coding Plan: platform.minimax.io/subscrib…
Intelligence with Everyone
1
1
5
262
Feb 13
🚀 Exciting news! Mooncake is now officially part of the PyTorch Ecosystem!
Mooncake brings high-performance KVCache transfer and storage to PyTorch-native LLM serving, enabling better prefill–decode disaggregation, global KVCache reuse, elastic MoE support, and fault-tolerant PyTorch distributed backends.
Already integrated with engines like SGLang, vLLM & TensorRT LLM, we are thrilled to build the future of scalable LLM serving together.
👉 Read more: pytorch.org/blog/mooncake-jo…
#Mooncake #PyTorch #LLM #OpenSourceAI
We’re excited to welcome Mooncake to the PyTorch Ecosystem!
Mooncake is designed to solve the “memory wall” in LLM serving. By integrating Mooncake’s high performance KVCache transfer and storage capabilities with PyTorch native inference engines like SGLang, vLLM, and TensorRT-LLM, it unlocks new levels of throughput and scalability for large language model deployments.
Mooncake enables prefill decode disaggregation, global KVCache reuse, elastic expert parallelism, and serves as a fault tolerant PyTorch distributed backend.
🔗 hubs.la/Q042Zf9N0
#PyTorch #OpenSourceAI #LLM #AIInfrastructure

1
3
188
Jan 27
Amazing!
Jan 27

One-shot "Video to code" result from Kimi K2.5
It not only clones a website, but also all the visual interactions and UX designs.
No need to describe it in detail, all you need to do is take a screen recording and ask Kimi: "Clone this website with all the UX designs."
riyd2bvh7ofju.beta-ok.kimi.l…
1
140
Jan 27
Also, You can use KTransformers with LLamaFactory to Finetune K2.5 in a local low HBM hardware (96GB) plus many DDR5 DRAM!
2
113