
9 Photos and videos







Pinned Tweet

12 Feb 2025
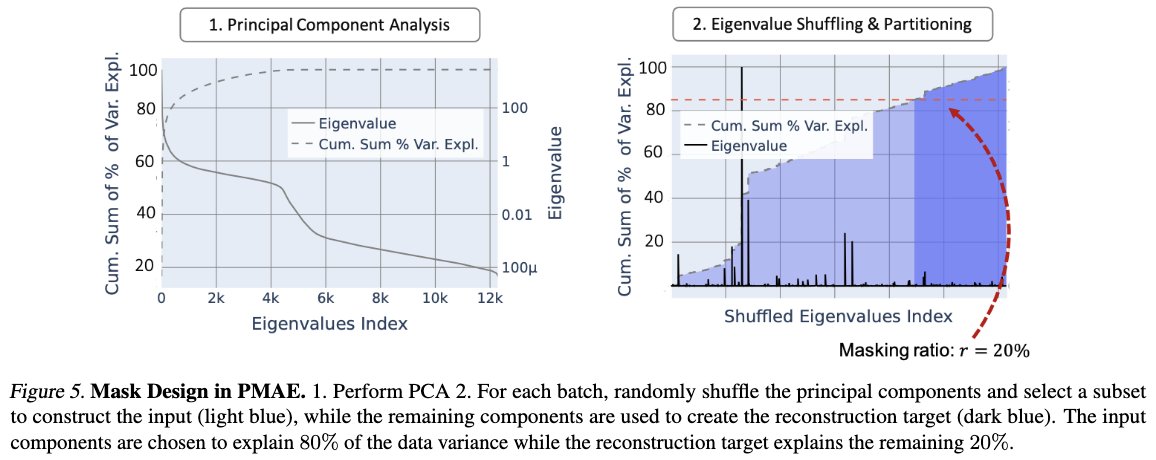
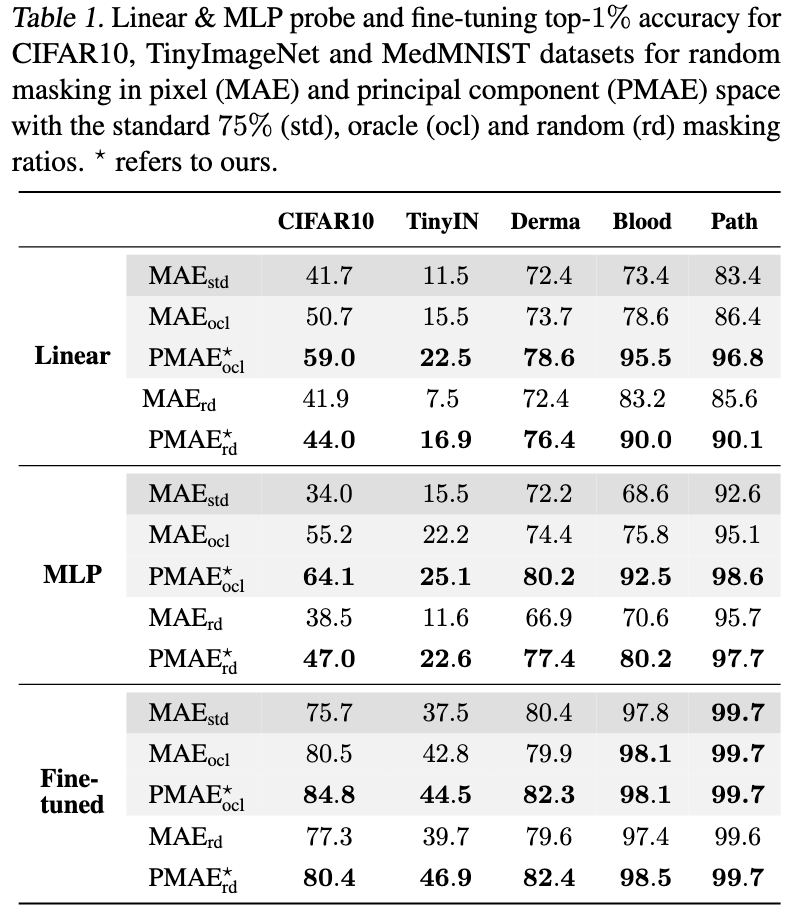
✨New Preprint ✨ Ever thought that reconstructing masked pixels for image representation learning seems sub-optimal?
In our new preprint, we show how masking principal components—rather than raw pixel patches— improves Masked Image Modelling (MIM).
Find out more below 🧵
17
61
524
48,467
Alice Bizeul retweeted

Jun 11
🚀 The MLX team is growing!
If you love writing blazing-fast GPU kernels or implementing foundational models in Python & Swift, we want you.
Drop a DM or apply below! 👇 #MachineLearning #AppleSilicon
jobs.apple.com/en-us/details…
github.com/ml-explore
13
47
422
129,906
Alice Bizeul retweeted

Jun 1
In a multimodal context, even the discrete/continuous divide is a distraction.
The real challenge is bridging the semantic gap between inherently high-level language tokens, and the very low-level representations we tend to use for perceptual signals.
(I couldn't resist😆)
Jun 1

I really think that autoregression and diffusion is a false dichotomy -- they can easily co-exist (e.g., diffusion forcing). The real one is between discrete and continuous tokens.
7
10
160
17,001
Alice Bizeul retweeted

🎨Activation steering can reliably push a text-to-image generator toward a visual concept, but at a cost: each concept needs its own estimation.
⚡HyperTransport (HT) predicts the intervention directly, matching per-concept SOTA at 3–4 orders of magnitude less cost.
[1/6]
3
18
50
4,435

Introducing the OpenAI Safety Fellowship, a new program supporting independent research on AI safety and alignment—and the next generation of talent.
openai.com/index/introducing…
384
293
2,664
948,253
Alice Bizeul retweeted

4 Nov 2025
𝗣𝗮𝗿𝗮𝗥𝗡𝗡: 𝗨𝗻𝗹𝗼𝗰𝗸𝗶𝗻𝗴 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗼𝗳 𝗡𝗼𝗻𝗹𝗶𝗻𝗲𝗮𝗿 𝗥𝗡𝗡𝘀 𝗳𝗼𝗿 𝗟𝗟𝗠𝘀
For years, we’ve given RNNs for doomed, and looked at Transformer as 𝘁𝗵𝗲 LLM—but we just needed better math
📄arxiv.org/abs/2510.21450
💻github.com/apple/ml-pararnn
1
2
8
1,582
Alice Bizeul retweeted

21 Oct 2025
🚀 Excited to share LinEAS, our new activation steering method accepted at NeurIPS 2025! It approximates optimal transport maps e2e to precisely guide 🧭 activations achieving finer control 🎚️ with ✨ less than 32 ✨ prompts!
💻github.com/apple/ml-lineas
📄arxiv.org/abs/2503.10679
1
16
55
5,568
Alice Bizeul retweeted

6 Oct 2025
We’re excited to share our new paper: Continuously-Augmented Discrete Diffusion (CADD) — a simple yet effective way to bridge discrete and continuous diffusion models on discrete data, such as language modeling. [1/n]
Paper: arxiv.org/abs/2510.01329

6
38
236
41,095
Alice Bizeul retweeted

29 Sep 2025
🚨 Machine Learning Research Internship opportunity in Apple MLR! We are looking for a PhD research intern with a strong interest in world modeling, planning or learning video representations for planning and/or reasoning. If interested, apply by sending an email to me at vthilak@apple.com. Applications will be reviewed until the position is filled.
3
35
321
40,650
Alice Bizeul retweeted

22 Sep 2025
Super excited to share l3m 🚀, a library for training large multimodal models, which we used to build AIM and AIMv2. Massive thanks to @alaa_nouby @DonkeyShot21 Michal Klein @MustafaShukor1 @jmsusskind and many others.

1
16
60
7,216
Alice Bizeul retweeted

4 Aug 2025
Had a great time speaking at @NECLabsEU about using activation steering for better instruction-following in LLMs!
Check out the talk 🗣️: youtu.be/3ozuaGaEjpo?si=T9ZL…
and paper 📜: arxiv.org/abs/2410.12877
This work that I did at @MSFTResearch shows how interpretability-based approaches can improve LLM controllability, connecting model understanding with practical utility.
4 Aug 2025

We hosted an insightful talk by @alesstolfo, PhD student at @ETH and doctoral fellow at the Swiss CYD Campus, on improving instruction-following in language models via activation steering. Watch here: youtu.be/3ozuaGaEjpo?si=p_Ci…. #NECLabs #LLM

ALT We hosted an insightful talk by @alesstolfo, PhD student at @ETH and doctoral fellow at CYD Campus, on improving instruction-following in language models via activation steering. Watch here: https://youtu.be/3ozuaGaEjpo?si=p_CiiQYYBAPcQ8iw. #NECLabs #LLM
1
16
1,269
Alice Bizeul retweeted

4 Aug 2025
We hosted an insightful talk by @alesstolfo, PhD student at @ETH and doctoral fellow at the Swiss CYD Campus, on improving instruction-following in language models via activation steering. Watch here: youtu.be/3ozuaGaEjpo?si=p_Ci…. #NECLabs #LLM
ALT We hosted an insightful talk by @alesstolfo, PhD student at @ETH and doctoral fellow at CYD Campus, on improving instruction-following in language models via activation steering. Watch here: https://youtu.be/3ozuaGaEjpo?si=p_CiiQYYBAPcQ8iw. #NECLabs #LLM
1
7
1,818
Alice Bizeul retweeted

30 Jul 2025
Join us tomorrow morning #ACL2025NLP #ACL2025
30 Jul 2025

If you're at ACL, join us for the tutorial "LLMs for Education: Understanding the Needs of Stakeholders, Current Capabilities and the Path Forward" at the BEA workshop (Room 1.85–86) 9:00-12:30am tomorrow (July 31st) @aclmeeting
1
2
7
566
Alice Bizeul retweeted

12 Jul 2025
I am heading to @icmlconf to present our position paper with @randall_balestr @klindt_david @wielandbr on what we believe are the important next steps to advance SSL.
It's not either theory or practice, it's both. We as a community need a better discussion.
2
7
47
4,175
Alice Bizeul retweeted

23 Jun 2025
Is the mystery behind the performance of Mamba🐍 keeping you awake at night? We got you covered! Our ICML2025 paper demystifies input selectivity in Mamba from the lens of approximation power, long-term memory, and associative recall capacity.
arxiv.org/abs/2506.11891

1
16
52
6,500
Alice Bizeul retweeted

6 May 2025
Current KL estimation practices in RLHF can generate high variance and even negative values! We propose a provably better estimator that only takes a few lines of code to implement.🧵👇
w/ @xtimv and Ryan Cotterell
code: arxiv.org/pdf/2504.10637
paper: github.com/rycolab/kl-rb

4
31
125
15,109

Alice Bizeul retweeted

23 Apr 2025
Presenting our work at #ICLR this week! Come by the poster or oral session to chat about copyright protection and AI/LLM safety
📌 𝐏𝐨𝐬𝐭𝐞𝐫: Friday, 10 a.m. – 12.30 p.m. | Booth 537
📌 𝐎𝐫𝐚𝐥: Friday, 3.30 – 5 p.m. | Room Peridot
@FraPintoML @DonhauserKonst @FannyYangETH
12 Feb 2025

LLMs accidentally spitting out copyrighted content?
We’ve got a fix.
Our paper on CP-Fuse—a method to prevent LLMs from regurgitating protected data—got accepted as an Oral at #ICLR2025!
👇Check it out!
📄 arxiv.org/pdf/2412.06619
🤖 github.com/jaabmar/cp_fuse
1
6
1,044
Alice Bizeul retweeted

25 Apr 2025
Interested in understanding feature extraction of an amazing self-supervised method, DIET (arxiv.org/abs/2410.21869)? Come to our talk on Sat 11am at Garnet 216-218 and poster #310 at 3pm.
My fabulous co-authors: @rpatrik96 @AliceBizeul @randall_balestr @klindt_david @wielandbr.
4
7
1,007
Alice Bizeul retweeted
25 Apr 2025
I am at #ICLR25 😎 and looking for collaborations on self-supervised learning/ understanding representation learning and logical reasoning. Let's chat. 💭
Otherwise, come by on Sat 3pm to our poster #308 on cross-entropy based SSL.
3
7
725
24 Apr 2025
I am at ICLR this week ! Excited to be presenting our work on identifiability with @rpatrik96 @JuhosAttila @randall_balestr @klindt_david @wielandbr. Tune in on Saturday at 11AM in Garnet 216-218 for our oral presentation and at 3PM in Hall 3/2B for our poster!
1
12
86
6,495