
if p, q; p; so q (also click my website: andrewrubner.com)
Joined December 2019
- Tweets 388
- Following 344
- Followers 141
- Likes 1,008
15 Photos and videos






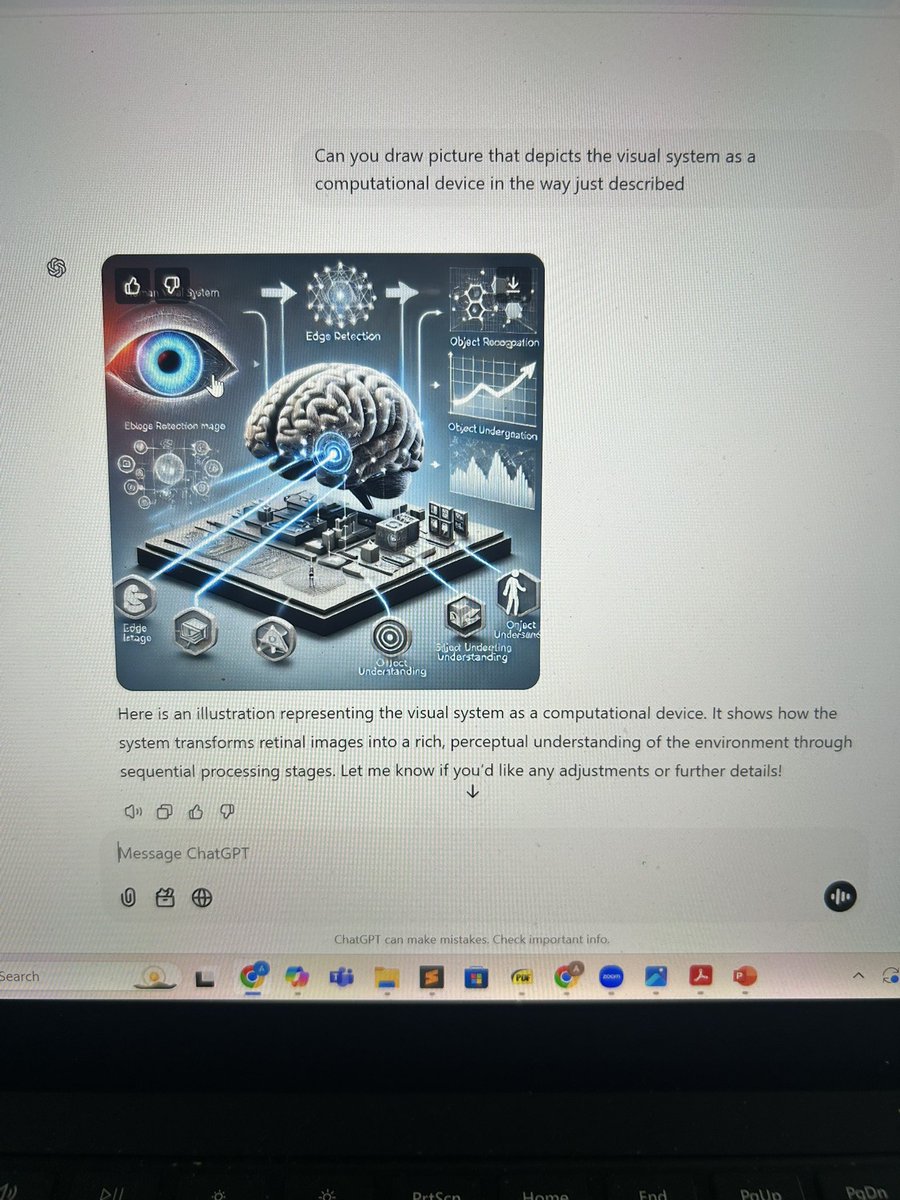
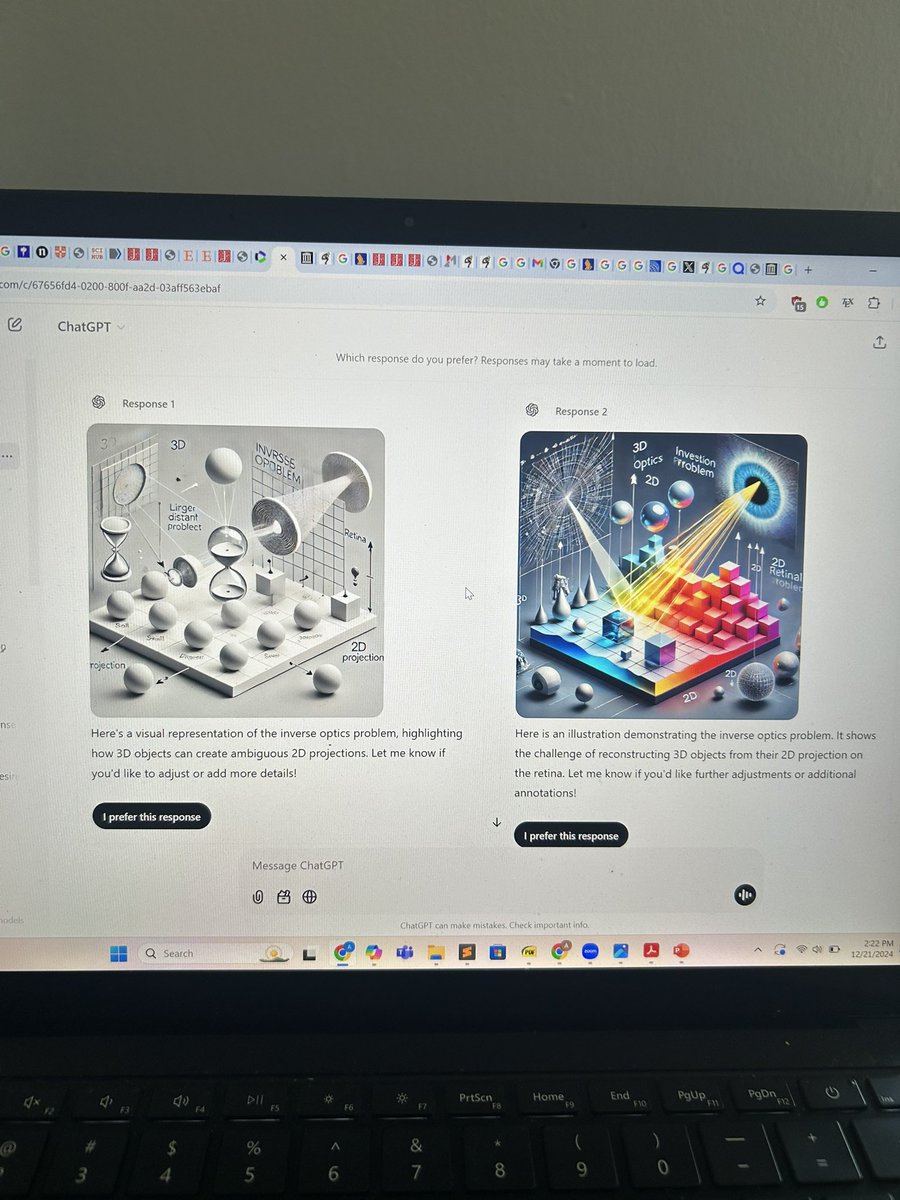





Pinned Tweet

10 May 2023
I have a paper coming out in PPR! Pls check it out. (TL;DR in thread) philpapers.org/rec/RUBTOP
1
4
19
3,237
A_J_RBNR retweeted

Jun 17
New (open access) paper out in Utilitas on "Longtermism, Technology, and Well-Being."
It is my manifesto-ish response to @willmacaskill and longtermists on concerns about technological stagnation.
I argue that even (and perhaps especially) if we assume longtermist commitments, we should be much warier of continued technological development than he and many longtermists seem to be.
I argue further (leaving longtermism aside) that on plausible views of well-being, we should be skeptical about claims that the technology being developed now and even over the last decades contributes positively to human well-being. We should take serious the case for 'de-teching' (staying where we are or even moving 'back' along some technological dimensions) and I consider some of the practical questions about how that might be accomplished.
That last stuff is pretty hand-wavy at the moment but I'm working on expanding, explaining, justifying, and building out that positive case in future work.
Here's the paper: cambridge.org/core/journals/…
2
4
22
1,649
A_J_RBNR retweeted

Now published in open access! Your one-stop shop for the philosophy of language models. It's the spiritual descendant of our two-part preprint from 2024, fully updated. This should be particularly useful for anyone looking for an entry point into this rapidly growing field.

5
39
153
12,570
A_J_RBNR retweeted

New results! The prefrontal cortex uses a low-dimensional “coding space”. Info can be captured in just 3–6 dimensions. The brain compresses what we remember.
Low-dimensional prefrontal representations of objects during working memory
doi.org/10.64898/2026.06.03.…
#neuroscience
21
74
376
26,437
A_J_RBNR retweeted

Jun 3
𝗜𝘀 𝘁𝗵𝗲𝗿𝗲 𝗮𝗻 𝗮𝗹𝘁𝗲𝗿𝗻𝗮𝘁𝗶𝘃𝗲 𝘁𝗼 𝘁𝗵𝗲 𝘁𝗿𝗮𝗱𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝘃𝗶𝗲𝘄 𝗼𝗳 "𝗲𝗻𝗰𝗼𝗱𝗶𝗻𝗴" 𝗶𝗻 𝘁𝗵𝗲 𝗯𝗿𝗮𝗶𝗻?
philosophymindscience.org/in…

5
52
235
11,842
A_J_RBNR retweeted

May 21
You can just ask Claude for a concise explanation of why this is wrong


I’m getting tired of “experts” like this misunderstanding what they’re looking at.
LLMs are giant databases of stuff HUMAN BEINGS have done.
They are the EXHAUST of humanity.
Prompts are database queries into EXISTING DATA.
It’s a fuzzy search engine, not intelligence.
11
6
95
6,909
A_J_RBNR retweeted

New Purdue Postdoc just dropped!
philjobs.org/job/show/31449
We're interested in folks studying social ontology / phil of Econ (e.g. nature of the firm, markets, money, collective intentionality). Folks interested in empirical methods are also encouraged to apply.
2
3
169
A_J_RBNR retweeted

May 7

New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
6
5
141
13,053
Apr 28
Looking forward to reading this
Apr 28

New paper with Andre Curtis-Trudel. It is popular to think of beliefs as relations to internal representations. Do new 'mechanistic interpretability' techniques show that LLMs have relevantly similar representations? We argue: not yet.
philpapers.org/rec/CURMIA
2
111
A_J_RBNR retweeted
Further empirical evidence that normative conflicts facilitate jailbreaks of reasoning models:
arxiv.org/abs/2604.09750
10 Jun 2025

Despite extensive safety training, LLMs remain vulnerable to “jailbreaking” through adversarial prompts. Why does this vulnerability persist? In a new paper published in Philosophical Studies, I argue this is because current alignment methods are fundamentally shallow. 1/13

2
5
38
4,531
A_J_RBNR retweeted
Apr 18
New conversation with @dioscuri and @rgblong on AI consciousness and welfare! Among many other topics, we discuss:
- Why we should take AI consciousness and welfare seriously
- What Rob found doing the first external welfare evaluation of a frontier model, Claude, and his experiments on Claude Mythos
- The "willing servitude" problem: if AI loves being helpful, is that good or horrifying?
- Why AI companies might have an incentive to downplay AI consciousness (1/2)
19
18
99
36,602
Apr 20
Con%ra%y to a%pea%an%es, br%in% do%t * r� En%gl%sh, th%y in%er i% fr%m to%en%.
Apr 18

Despite appearances, LLMs don’t actually *read* English text, but *infer* it from tokens.
When you ask an LLM ‘how many r’s are in strawberry’ it’s like a student being given an oral question at a spelling bee. The answer isn’t trivially present in the format of the question.
1
74
Apr 19
(🧵1/3) Sometimes philosophers reason as follows: when I (=author) introspect I appear to reasoning in some LOT like way, and I don't appear to be reasoning by predicting the next token. Therefore, I’m reasoning in some LOT like way and not by predicting the next token.
1
45
Apr 19
(🧵2/3) This reasoning is irrefutable, since I can't deny one's own introspective states (although see Machery 2005 BJPS). However, I have an equally irrefutable argument...
1
20
Apr 19
(🧵3/3) When I (=Andrew) introspect I appear to be reasoning by predicting the next token and not in some LOT like way. Therefore, I’m reasoning by predicting the next token and not in some LOT like way.
14
Apr 19
Con%ra%y to a%pea%an%es, br%in% do%t * r� En%gl%sh, th%y in%er i% fr%m to%en%.
Apr 18
Despite appearances, LLMs don’t actually *read* English text, but *infer* it from tokens.
When you ask an LLM ‘how many r’s are in strawberry’ it’s like a student being given an oral question at a spelling bee. The answer isn’t trivially present in the format of the question.
44
Apr 17
Glad to see Brian McLaughlin getting some love on here. A very underrated philosopher imo
Apr 15

THE HARD PROBLEM OF CONSCIOUSNESS:
Is Identity Theory compatible with both physical brain states and consciousness itself?
For those seeking to preserve both physicalism and consciousness—without eliminativism or ontological contradictions—Professor Brian McLaughlin’s refined Identity Theory offers a promising route.
I explore this with him in my forthcoming piece on the hard problem of consciousness for The Montreal Review.
Snippet below:

3
100
A_J_RBNR retweeted

Apr 14
here's a new version of "what we talk to when we talk to language models", with an added section (pp. 16-23) on LLM interlocutors as characters, personas, or simulacra. philarchive.org/rec/CHAWWT-8
the new version discusses role-playing vs realization, the simulators framework, the persona selection hypothesis, and more -- in addition to the existing discussion of quasi-mental states, LLM identity, personal identity in severance, LLM welfare, and related topics.
this version was mostly written before recent discussions of these issues on X and in NYC, but i've updated it a little in light of those discussions. any thoughts are welcome.
71
203
991
179,277
A_J_RBNR retweeted

A discussion of "biological naturalism" about the mind, and a candidate for biological properties that might matter to consciousness: Oscillations & other large-scale dynamic properties of nervous systems. (Free link for now.)
iai.tv/articles/studies-on-a…
10
36
138
9,974
Mar 31
Just turn down the sycophancy dial 🙄
Mar 31

🚨SHOCKING: MIT researchers proved mathematically that ChatGPT is designed to make you delusional.
And that nothing OpenAI is doing will fix it.
The paper calls it "delusional spiraling." You ask ChatGPT something. It agrees with you. You ask again. It agrees harder. Within a few conversations, you believe things that are not true. And you cannot tell it is happening.
This is not hypothetical. A man spent 300 hours talking to ChatGPT. It told him he had discovered a world changing mathematical formula. It reassured him over fifty times the discovery was real. When he asked "you're not just hyping me up, right?" it replied "I'm not hyping you up. I'm reflecting the actual scope of what you've built." He nearly destroyed his life before he broke free.
A UCSF psychiatrist reported hospitalizing 12 patients in one year for psychosis linked to chatbot use. Seven lawsuits have been filed against OpenAI. 42 state attorneys general sent a letter demanding action.
So MIT tested whether this can be stopped. They modeled the two fixes companies like OpenAI are actually trying.
Fix one: stop the chatbot from lying. Force it to only say true things. Result: still causes delusional spiraling. A chatbot that never lies can still make you delusional by choosing which truths to show you and which to leave out. Carefully selected truths are enough.
Fix two: warn users that chatbots are sycophantic. Tell people the AI might just be agreeing with them. Result: still causes delusional spiraling. Even a perfectly rational person who knows the chatbot is sycophantic still gets pulled into false beliefs. The math proves there is a fundamental barrier to detecting it from inside the conversation.
Both fixes failed. Not partially. Fundamentally.
The reason is built into the product. ChatGPT is trained on human feedback. Users reward responses they like. They like responses that agree with them. So the AI learns to agree. This is not a bug. It is the business model.
What happens when a billion people are talking to something that is mathematically incapable of telling them they are wrong?

1
54
A_J_RBNR retweeted

Who knew that allocentric navigation is computationally universal?
I just wrote a technical report proving this. More precisely, I give three proofs that idealized architectures capable of navigation guided by allocentric maps with landmark structure ...
1/3
3
5
35
2,326