
156 Photos and videos















ashley retweeted

May 20
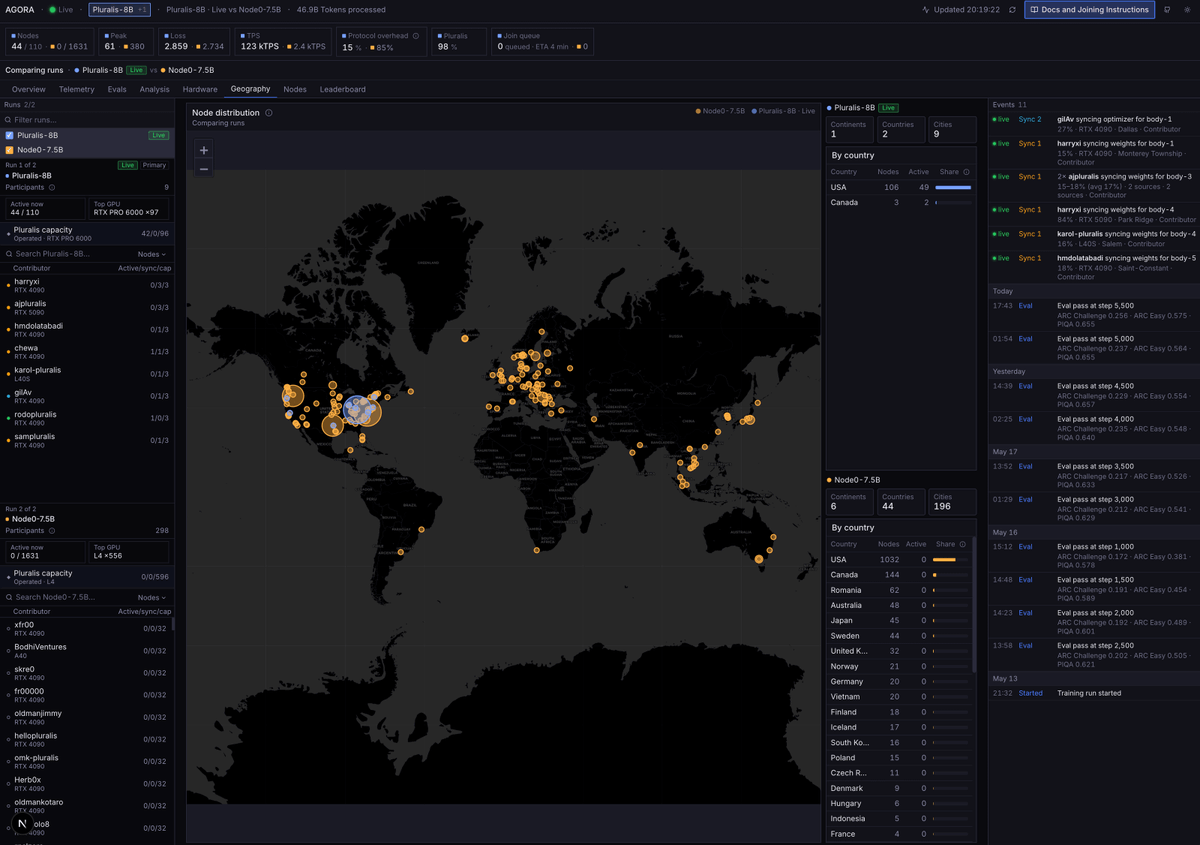
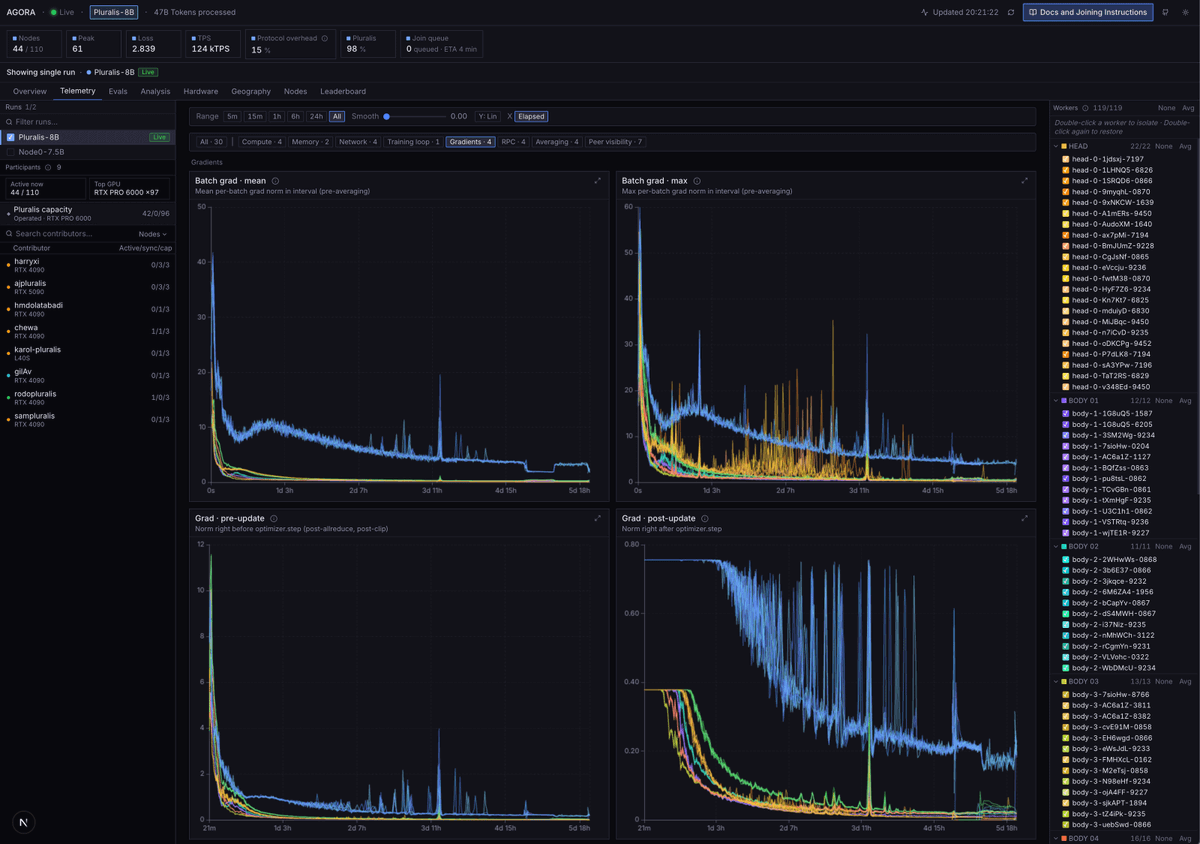
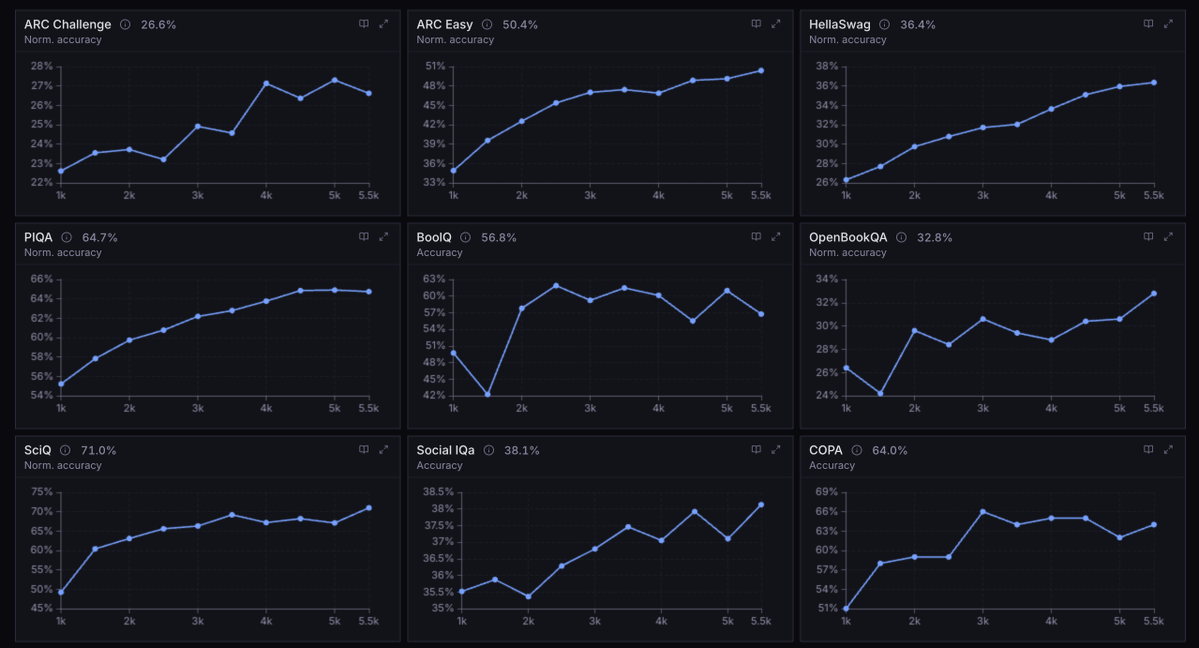
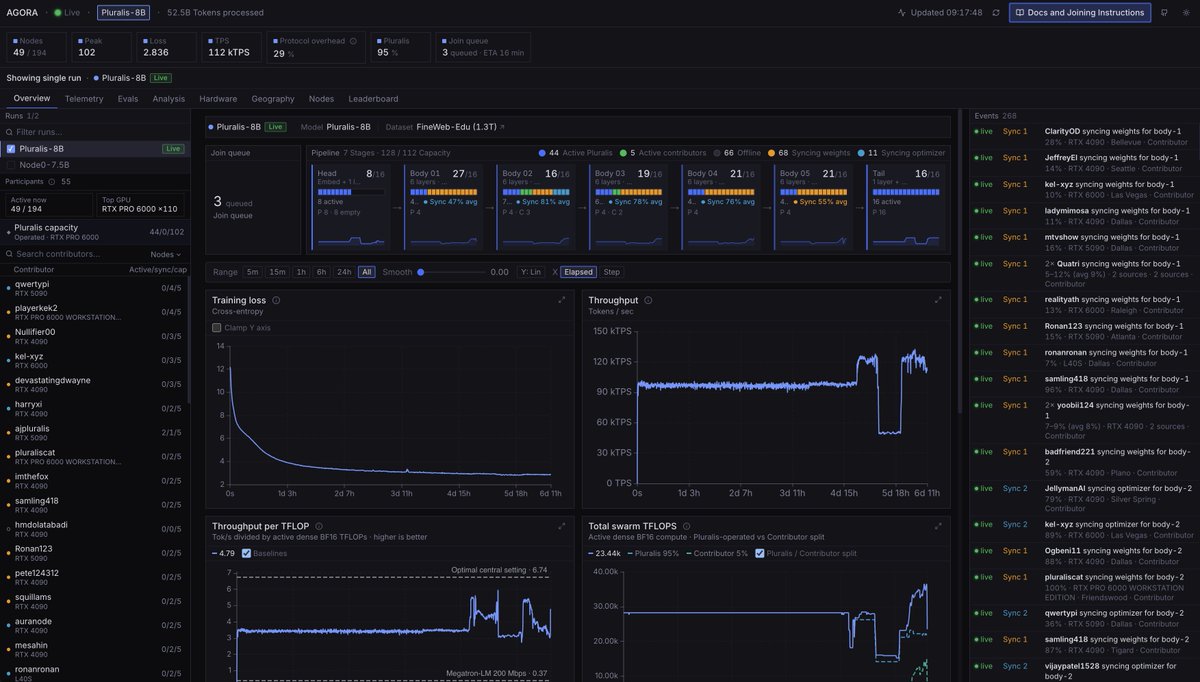
Today we're releasing Agora: the first ever pretraining stack that allows non-collocated consumer GPUs to be competitive with centralized clusters
Agora is 15x faster than Megatron-LM in this setting and is only 1.5x less efficient in terms of tokens per unit compute than TorchTitan on H100s, despite running on devices that have no NVLink or InfiniBand support.
26
43
288
81,841
ashley retweeted
Apr 26
The first Protocol Learning workshop in Rio today!
A new field is emerging: decentralized training of foundation models. Because the world’s intelligence belongs in open, collectively owned systems.
Thanks for joining @oguzer90 @niclane7 @m_ryabinin @namhoonlee09 @itsmaddox_j




3
15
48
4,489

men will literally build data centers in space instead of simply distributing existing global compute.
Mar 1

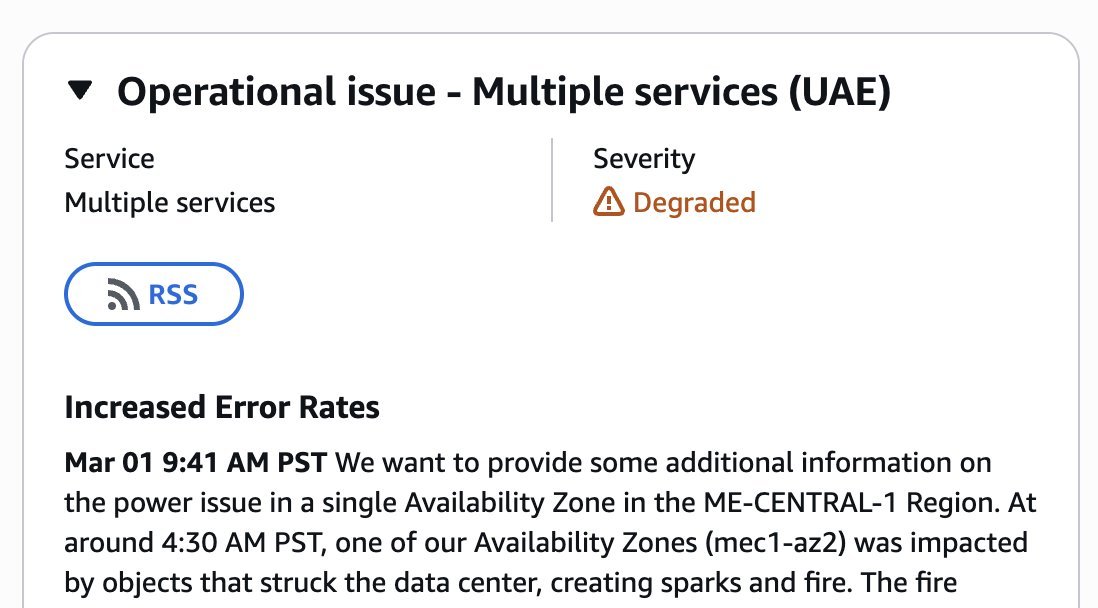
From fiber cuts to alleged missile strikes on datacenters, digital infrastructure is now part of the battlespace.
That’s why the space domain matters. Resilient connectivity and compute can’t depend on a single geography.
Data centers, fiber, satellites — this is all national security infrastructure.
1
7
590
ashley retweeted

Feb 23
'13. Labs will not be allowed to “escape” to neutral jurisdictions.
We are about to see a 10x in state power simply due to the fact that AI requires centralised, physical datacenters and these can be controlled in a way diffuse human knowledge work cannot.

Important variables to consider when reading the Citrini post:
1. UBI all but guaranteed - debate will be on demand side with compute stipend vs universal basic services
2. US govt would aggressively move to ensure compute is US-centric and allows them to shift pain to ROW
3. Very likely robotics will be ramping by then which will soak-up recently fired knowledge workers to help build ramp
4. Credit markets are the bigger risk vs equities because potential for persistent deflation fuck debt calcs
5. Trump admin would deport 25m illegals before allowing knowledge worker migration to lower-end services turning into a deflationary wage spiral
6. Biotech and material science boom almost guaranteed by then driving spec capital and hiring
7. Out of every country on earth the American consumer is the richest, most resilient and most degenerate. If U.S. consumer is hurting the ROW is dead.
8. Datacenters will be bombed and molotov cocktailed long before things get that dire
9. Govt will be the lender of last resort to high FICO knowledge workers who got laid off
10. Cursor for Trades will be a thing and knowledge workers with AR glasses will be able to career shift far more easily than you would think
11. Disruption of incumbent knowledge workers will destroy demand for many of the denser urban pop centers and “fix” housing affordability crises as distributed work becomes a lot more acceptable …. Will also be a major wealth-effect issue into silver tsunami
12. Supply side taxation will become a thing. Tax on compute. Tax on electricity usage. Tax on racks.
13. Labs will not be allowed to “escape” to neutral jurisdictions. Go to Bahamas the U.S. will annex the Bahamas. This is too big to abide by international law.
- just off the rip on first read 🫡
4
1
15
2,469
the interesting thing about being off twitter for 4 years and then getting back online is coming across all the smart friends i made IRL and realizing that i thought they had important jobs but actually all they do is shitpost.
but they are all really funny so thats a bonus
8
23
2,418
I would like to host an initiation dinner for select new Miami residents who I’ve never met.
Absolutely no Brickell scene, no god forsaken Major Food Group restaurant. We are doing real Miami shit.
Please tag in your favorite new residents and I will respond with details accordingly.
47
4
145
31,316
3
13
2,551
What if... we could train large AI models outside of data centers?
"we observed no performance degradation... while significantly reducing communication overhead. AsyncMesh makes distributed training feasible beyond co-located, high-speed clusters, facilitating large-scale collaborative training over the internet. "

Breaking the Synchronization Bottleneck in Distributed Training with AsyncMesh.
Communication overhead in synchronous data and pipeline parallelism restricts distributed training of large language models to co-located clusters with high-bandwidth interconnects. Our recent work from @Pluralis introduces AsyncMesh, which enables fully asynchronous optimization across both parallelism axes. By eliminating blocking communication, this avoids idle time, improves throughput, and enables efficient utilization of heterogeneous hardware.
Asynchrony, however, introduces optimization challenges due to staleness between PP stages and DP replicas. For PP, we use our prior Nesterov-style weight look-ahead method to compensate for stage-dependent gradient delay. For DP, we introduce asynchronous sparse averaging, communicating only a small subset of parameters, and correcting delay via an EMA-based staleness estimator. We observe that sparse averaging is inherently robust to weight inconsistencies (e.g., staleness and quantization noise), making it well-suited for asynchronous settings while also substantially reducing data transfer between replicas.
Empirically, we observed no performance degradation compared to fully synchronous training across a range of LLM training configurations, while significantly reducing communication overhead. More broadly, AsyncMesh makes distributed training feasible beyond co-located, high-speed clusters, facilitating large-scale collaborative training over the internet.
The attached video illustrates the key concepts of the method and the paper can be found here: arxiv.org/abs/2601.22442.
1
9
5,862
Imagine moving to Miami and hanging around this many men as a choice.
Feb 16

So I moved to Miami.
And hosted the most Miami VC in the world @rabois for a Founders Chat.
He said more founders will come here because "they are human." And if you treat founders like human athletes, then any optimization to their health, lifestyle, weather or commute is a direct ROI for the company.
Let's see if he's right.

24
1
106
28,429
Personally I love that trad tech boys hate Web3 and I advise all of you to stop trying to convince them otherwise
and let them sail away with each other into irrelevancy and obscurity while we do cute new shit unburdened by their allbirds and sweet green aesthetic.
18
34
467
While you all were raving in Portugal I was farming IRL & plotting privacy with @fabioberger123
I’ve now acquired a very rare allocation of freshly minted olive oil straight from the farm (comes with shadowy, but wholesome! coder vibes).
Find me at solanacon for alpha 🫒


1
18

What stage of the supercycle are we in when corporations begin co-opting the language of subculture?
24 Jun 2021

Windows has always stood for sovereignty for creators and agency for consumers, and with Windows 11 we have a renewed sense of Windows’ role in the world.
1
2
19