
My Bots do crazy things, never try this at home. #AI #ML#ENSEMBLE it’s Logarithms fault. Luck is serially correlated #FishyFishy #MaLFoDGA🍉 #DeleteMeta #Peace
Joined June 2011
- Tweets 58,877
- Following 1,647
- Followers 21,274
- Likes 54,784
8,422 Photos and videos
















Pinned Tweet

6 Aug 2025
“On Friday August 2nd, 2024 the Market was hugely mispricing risk, we tweeted live that we were going Massively long volatility (x.com/bankofvol/status/18194…) as our analysis revealed risk was underpriced by market makers and professional investors.
The following Monday was the biggest one day jump in the spot VIX in market history ( 181% from Friday close to Monday high). We made 35% on our massive VIX futures long position and several million dollars of PnL in a single day (x.com/bankofvol/status/18205…) . In our Substack we dive deep into volatility term structures and dynamic to uncover these rare opportunities just before volatility spikes.
If you are serious about protecting your capital, these are signals you can’t afford to miss.” "2ly.link/2CYQg""
#VolatilityTrading #RiskManagement #LongVol #VIX #OptionsTrading #Hedging #MacroRisk #TailRisk #VolatilityStrategy #MarketVolatility #TradingStrategy #QuantTrading #FuturesTrading #MarketCrash #FinancialMarkets #InstitutionalInvesting #AlphaSignals
2 Aug 2024

Hedge off. VX_F long massive.
1
27
38,280
Funny thing about that MIT recursive-models paper: power users already do the human version of it.
What I do constantly:
— Don't ask one model to memorize everything
— PDF → hand it to Gemini, "turn this into text" → feed the text into Claude's context
— Need an image? → ask Gemini for the prompt → feed that to Grok
You become the router. Each model does the slice it's best at. Nobody's context window gets overloaded.
The paper just automates the instinct: the model writes code to chunk the work and delegate — instead of a human doing it by hand.
If you've ever managed a big project across models, you already understood the thesis. You just didn't have the paper yet.
New MIT paper quietly reprices the AI trade.
"Recursive Language Models" (Zhang, Kraska, Khattab)
arxiv.org/abs/2512.24601
The finding: stop feeding long prompts to the model. Park them as a variable, let the model write code to chunk them and fire many cheap sub-calls. Result: 10M token inputs, beats vanilla GPT-5 by double digits, same cost.
Why it matters for your book:
More total inference compute — but routed to PARALLELISM, MEMORY, and CHEAP sub-models. Not to "the one smartest model."
That sorts the whole sector:
✅ WINNERS — anything that moves, stores, cools, connects compute:
— Interconnect/optics: $ANET $CRDO $MRVL $COHR $LITE $FN — massively parallel sub-calls = east-west traffic
— Memory/storage: $SNDK — prompt-as-variable is memory-hungry
— Power/thermal: $VRT $NVT — more compute running longer = more watts
— Neocloud: $NBIS — compute-elastic demand, the purest read
⚠️ NEUTRAL — volume helps, mix dilutes:
$ARM $SKM — model-agnostic, rides units not margins
❌ THESIS RISK — value tied to single-model supremacy:
$INOD — if capability comes from SCAFFOLDING not bigger training runs, the data-labeling TAM narrows
One line: bullish everything that moves/stores/cools/connects compute. Bearish everything whose moat is "our model is biggest."
Context length was never the moat. Orchestration is.
Not financial advice.
2
583
New MIT paper quietly reprices the AI trade.
"Recursive Language Models" (Zhang, Kraska, Khattab)
arxiv.org/abs/2512.24601
The finding: stop feeding long prompts to the model. Park them as a variable, let the model write code to chunk them and fire many cheap sub-calls. Result: 10M token inputs, beats vanilla GPT-5 by double digits, same cost.
Why it matters for your book:
More total inference compute — but routed to PARALLELISM, MEMORY, and CHEAP sub-models. Not to "the one smartest model."
That sorts the whole sector:
✅ WINNERS — anything that moves, stores, cools, connects compute:
— Interconnect/optics: $ANET $CRDO $MRVL $COHR $LITE $FN — massively parallel sub-calls = east-west traffic
— Memory/storage: $SNDK — prompt-as-variable is memory-hungry
— Power/thermal: $VRT $NVT — more compute running longer = more watts
— Neocloud: $NBIS — compute-elastic demand, the purest read
⚠️ NEUTRAL — volume helps, mix dilutes:
$ARM $SKM — model-agnostic, rides units not margins
❌ THESIS RISK — value tied to single-model supremacy:
$INOD — if capability comes from SCAFFOLDING not bigger training runs, the data-labeling TAM narrows
One line: bullish everything that moves/stores/cools/connects compute. Bearish everything whose moat is "our model is biggest."
Context length was never the moat. Orchestration is.
Not financial advice.
1
5
4,797
This is actually Huuuuuuuuuuuuge.

MIT just made every AI company's billion dollar bet look embarrassing.
They solved AI memory. Not by building a bigger brain. By teaching it how to read.
The paper dropped on December 31, 2025. Three MIT CSAIL researchers. One idea so obvious it hurts. And a result that makes five years of context window arms racing look like the wrong war entirely.
Here is the problem nobody solved.
Every AI model on the planet has a hard ceiling. A context window. The maximum amount of text it can hold in working memory at once. Cross that line and something ugly happens — something researchers have a clinical name for.
Context rot.
The more you pack into an AI's context, the worse it performs on everything already inside it. Facts blur. Information buried in the middle vanishes. The model does not become more capable as you feed it more. It becomes more confused. You give it your entire codebase and it forgets what it read three files ago. You hand it a 500-page legal document and it loses the clause from page 12 by the time it reaches page 400.
So the industry built a workaround. RAG. Retrieval Augmented Generation. Chop the document into chunks. Store them in a database. Retrieve the relevant ones when needed.
It was always a compromise dressed up as a solution.
The retriever guesses which chunks matter before the AI has read anything. If it guesses wrong — and it does, constantly — the AI never sees the information it needed. The act of chunking destroys every relationship between distant paragraphs. The full picture gets shredded into fragments that the AI then tries to reassemble blindfolded.
Two bad options. One broken industry. Three MIT researchers and a deadline of December 31st.
Here is what they built.
Stop putting the document in the AI's memory at all.
That is the entire idea. That is the breakthrough. Store the document as a Python variable outside the AI's context window entirely. Tell the AI the variable exists and how big it is. Then get out of the way.
When you ask a question, the AI does not try to remember anything. It behaves like a human expert dropped into a library with a computer. It writes code. It searches the document with regular expressions. It slices to the exact section it needs. It scans the structure. It navigates. It finds precisely what is relevant and pulls only that into its active window.
Then it does something that makes this recursive.
When the AI finds relevant material, it spawns smaller sub-AI instances to read and analyze those sections in parallel. Each one focused. Each one fast. Each one reporting back. The root AI synthesizes everything and produces an answer.
No summarization. No deletion. No information loss. No decay. Every byte of the original document remains intact, accessible, and queryable for as long as you need it.
Now here are the numbers.
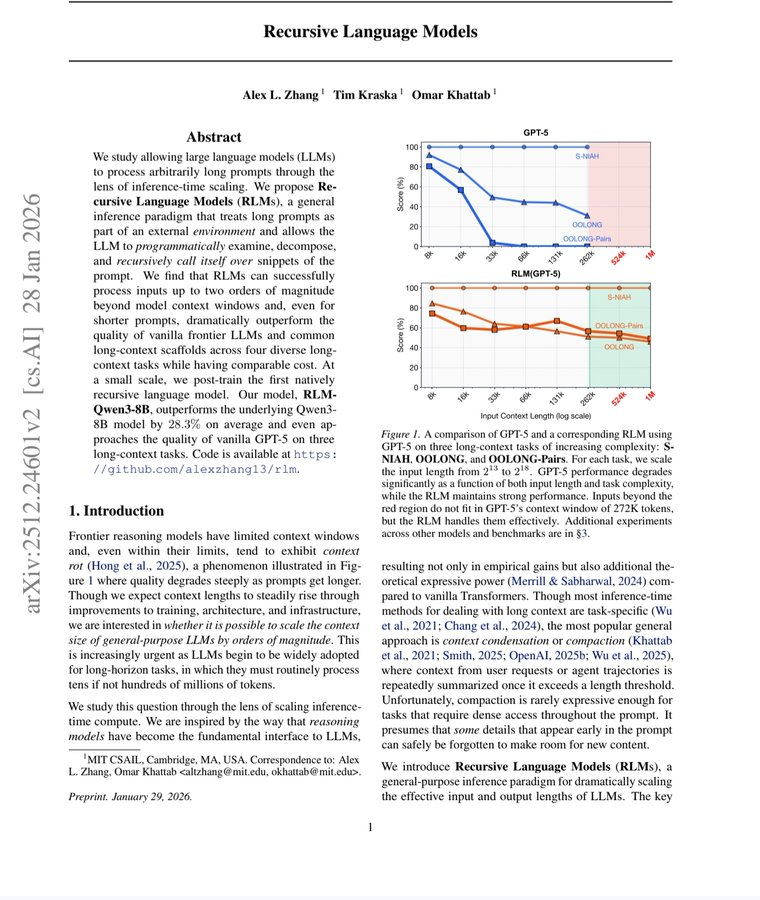
Standard frontier models on the hardest long-context reasoning benchmarks: scores near zero. Complete collapse. GPT-5 on a benchmark requiring it to track complex code history beyond 75,000 tokens — could not solve even 10% of problems.
RLMs on the same benchmarks: solved them. Dramatically. Double-digit percentage gains over every alternative approach. Successfully handling inputs up to 10 million tokens — 100 times beyond a model's native context window.
Cost per query: comparable to or cheaper than standard massive context calls.
Read that again. One hundred times the context. Better answers. Same price.
The timeline of the arms race makes this sting harder. GPT-3 in 2020: 4,000 tokens. GPT-4: 32,000. Claude 3: 200,000. Gemini: 1 million. Gemini 2: 2 million. Every generation, every company, billions of dollars spent, all betting on the same assumption.
More context equals better performance.
MIT just proved that assumption was wrong the entire time.
Not slightly wrong. Fundamentally wrong. The entire premise of the last five years of context window research — that the solution to AI memory was a bigger window — was the wrong answer to the wrong question.
The right question was never how much can you force an AI to hold in its head.
It was whether you could teach an AI to know where to look.
A human expert handed a 10,000-page archive does not read all 10,000 pages before answering your question. They navigate. They search. They find the relevant section, read it deeply, and synthesize the answer.
RLMs are the first AI architecture that works the same way.
The code is open source. On GitHub right now. Free. No license fees. No API costs. Drop it in as a replacement for your existing LLM API calls and your application does not even notice the difference — except that it suddenly works on inputs it used to fail on entirely.
Prime Intellect — one of the leading AI research labs in the space — has already called RLMs a major research focus and described what comes next: teaching models to manage their own context through reinforcement learning, enabling agents to solve tasks spanning not hours, but weeks and months.
The context window wars are over.
MIT won them by walking away from the battlefield.
Source: Zhang, Kraska, Khattab · MIT CSAIL · arXiv:2512.24601
Paper: arxiv.org/abs/2512.24601
GitHub: github.com/alexzhang13/rlm
1
5
1,293
Tresting.

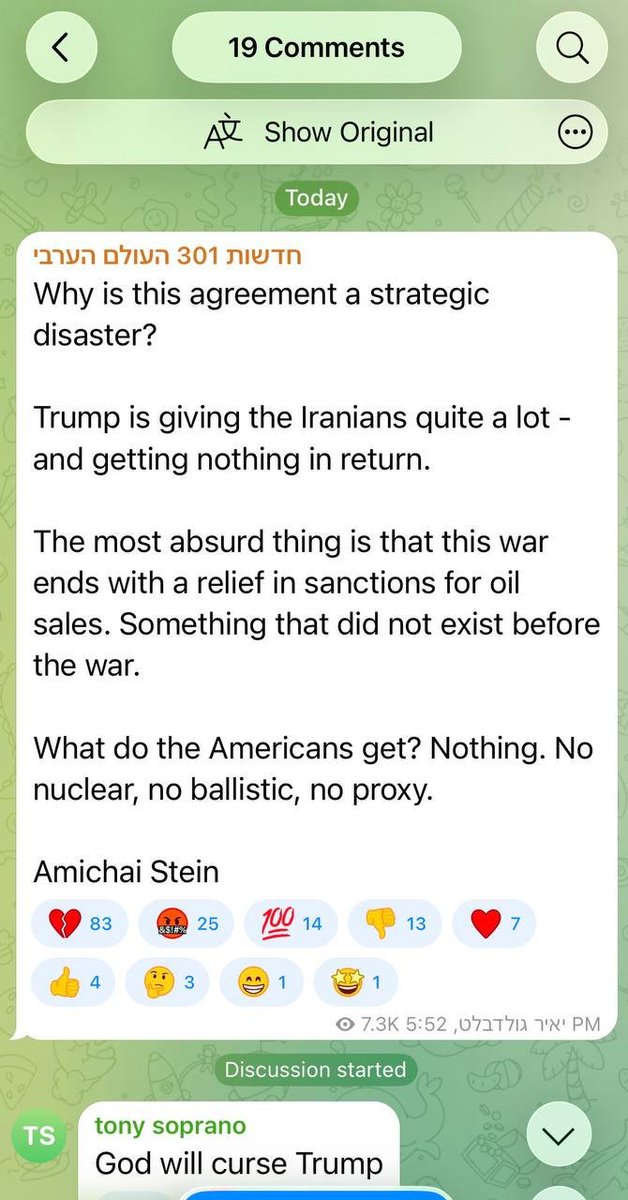
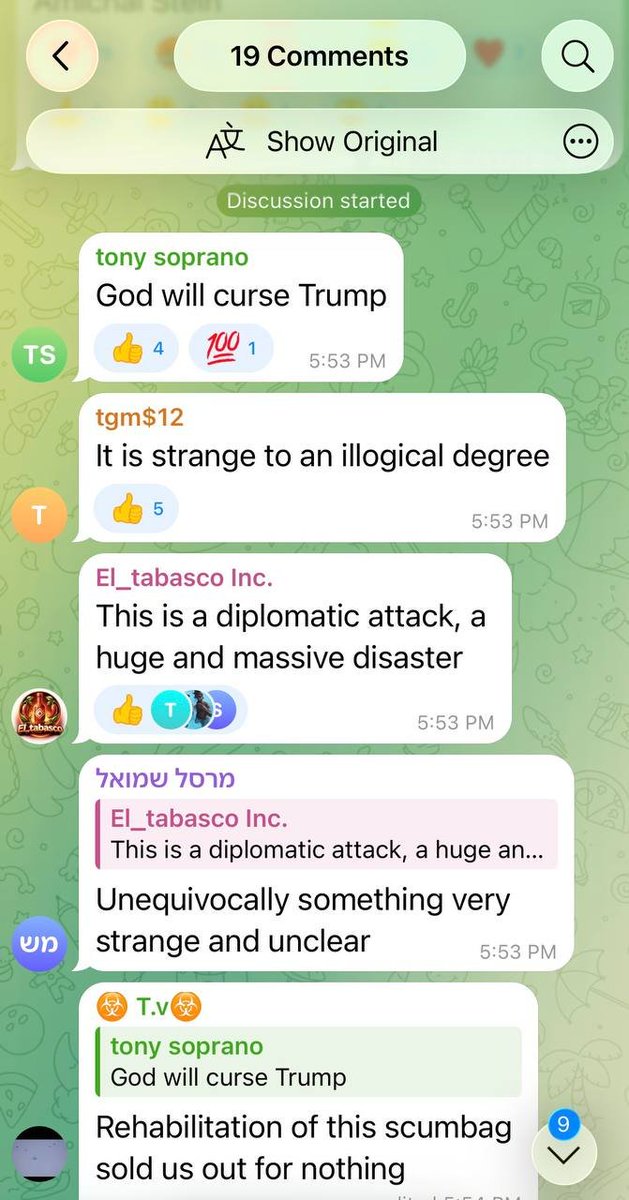
Israeli Telegram channel with 180K members is in mourning and fury:
"God will curse Trump."
"The first war in Israel's history that we lost."
"We have to admit the facts: Iranians taught America a lesson."
"Hopefully in 10 years we won't be dependent on American idiots."
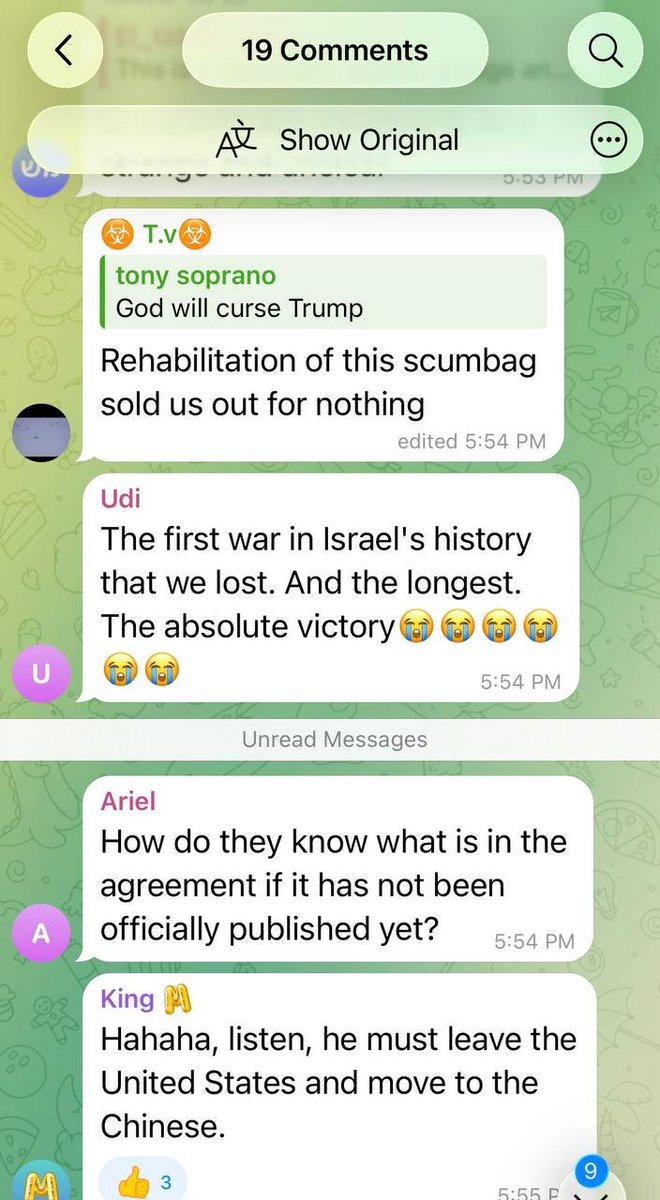

525
Rumor has it, they told to each others after signing: “See you after the midterms”

Following intensive talks, we are pleased to announce that the Peace Deal between the United States of America and Islamic Republic of Iran has been REACHED. Both sides have declared the immediate and permanent termination of military operations on all fronts, including in Lebanon.
The official signing ceremony will be on Friday, 19 June in Switzerland.
We would like to thank the United States of America and the Islamic Republic of Iran for their commitment to finding a diplomatic solution to the conflict. We would also like to extend our sincere appreciation to our brothers in this mediation effort, the great leadership of State of Qatar, for their support in reaching this agreement. I would also especially thank the visionary leadership of Kingdom of Saudi Arabia and Republic of Türkiye for their immense contributions in this regard.
With the agreement now in place, mediators will facilitate a series of meetings this week. These pre-implementation discussions will lay the foundation for the technical talks and the official signing ceremony.
@realDonaldTrump
@JDVance
@SecRubio
@SteveWitkoff
@SEPeaceMissions
@drpezeshkian
@mb_ghalibaf
@araghchi
8
533
30 minutes before Globex, magic

The Deal with the Islamic Republic of Iran is now complete. Congratulations to all! I hereby fully authorize the toll free opening of the Strait of Hormuz, and, simultaneously herewith, authorize the immediate removal of the United States Naval blockade. Ships of the World, start your engines. Let the oil flow! President DONALD J. TRUMP
14
1,402
Skimmy

$SKM SK Telecom: AI Transformation and Post-Crisis Recovery Analysis. Investment Thesis. New: 6/13/26.
SK Telecom enters its AI infrastructure pivot from a position of self-inflicted weakness. The 2025 cybersecurity breach was not a minor operational disruption — it damaged customer trust at scale, compressed earnings materially, and created a credibility deficit that the strategic AI narrative has to overcome rather than build upon. The sequential financial rebound is a necessary first step, but rebuilding subscriber confidence and normalizing margins in the core telecom business are preconditions for the AI thesis to receive full investor credit, not parallel tracks.
The AI asset base is genuinely interesting. A strategic stake in Anthropic is a differentiated holding that most telecom operators globally cannot claim, and the partnerships with NVIDIA and Penguin Solutions for GPU data center development reflect serious capital commitment rather than exploratory positioning. Those assets position SK Telecom as a potential sovereign AI infrastructure provider in a market where government and enterprise demand for domestically controlled AI compute is accelerating. The strategic logic connecting legacy connectivity infrastructure to AI factory operations is coherent — telecom operators own power infrastructure, real estate, and network connectivity that data center development requires.
The capital intensity of that vision is the financial constraint that the asset quality doesn't resolve. Building GPU data centers at meaningful scale requires sustained investment that competes with the capital demands of the legacy telecom network and the cost of cybersecurity remediation and customer retention programs simultaneously. Allocating across those competing priorities without impairing the balance sheet requires execution discipline that the recent breach demonstrated is not guaranteed.
Analyst division on valuation reflects a genuine uncertainty rather than a consensus waiting to form. The legacy telecom business is recovering but scarred, the AI assets are strategically valuable but early in monetization, and the capital requirements of bridging the two are substantial. Whether the current price accurately weights those variables depends heavily on assumptions about breach recovery speed and AI infrastructure ramp timing that are difficult to underwrite with precision.
The sovereign AI framing is the long-duration thesis that justifies patience with the near-term complexity. If SK Telecom successfully positions itself as South Korea's primary domestic AI infrastructure platform — connecting Anthropic model capabilities, NVIDIA compute, and national telecom infrastructure into a coherent sovereign stack — the strategic value of that positioning extends well beyond what traditional telecom or data center multiples would capture. Getting there requires executing a recovery and a transformation simultaneously, which is a high operational bar for any management team.
7
744
Good cop, bad cop.

Trump: I spoke with Netanyahu, I told him, “What the f- are you doing?” - Israel's N12 News
6
887
Tresting

$NBIS Hidden gem many don’t know about (ClickHouse)
So I gained a lot of followers because of this company, and I already explained what Token Factory is and how it is important for $NBIS. However, there is one more asset Nebius owns that many investors either overlook or underestimate its potential.
Let me present you: ClickHouse
It is an open-source columnar database designed for online analytical processing (OLAP), originally developed by Yandex.
To explain it in basic terms, if you store data in databases (most typical transactional databases like PostgreSQL or MySQL), you do it row by row, because, for example, banks often want to search information about a given customer, so they just search for the ID of the customer, and the whole row pops up and they get everything about the customer they care about.
But imagine you have 1 billion rows, 50 columns, and you care about, for example, the average spending in the whole database. This is where ClickHouse comes in and uses column-by-column storing. Then, instead of reading 50 billion values, a column-based database might read only 1 billion values. Obviously, the idea is more sophisticated, where ClickHouse developed additional compression algorithms, but for our explanation, this is sufficient, as you now know what ClickHouse does. Importantly, the main advantage is that it often stores data using 5-10x less space than traditional databases.
To give you an example, imagine you operate 100,000 GPUs and every second, that GPU sends information such as:
- timestamp
- GPU ID
- temperature
- utilization
- memory usage
100,000 GPUs -> 1 month = 259,200,000,000 records
And now an engineer asks: "What was the average GPU utilization by hour last week?"
Instead of going through all rows, the query only needs timestamp and utilization and you save a lot of time.
And you know who uses ClickHouse? The biggest players such as OpenAI, Anthropic, Meta, Tesla, Cisco, Alibaba, Spotify and many others.
So, now that you get the importance of the company, what if I told you that $NBIS owns approximately 28% of ClickHouse and its valuation is growing rapidly.
In May 2025, the company was valued at rougly $6.35B
In January 2026, the valuation increased to $15B, which is ~236% increase in 7 months, think about the speed of this.
If we would expect the company to "only" double its valuation throughout the whole 2026, we would get to $30B.
Implying $NBIS’s stake being worth $8.4B (current market cap is $59B).
What’s funny is that many investors have no idea what ClickHouse is and they think it is just some small partner or whatever, but it might soon represent $10B stake for $NBIS.
If you have any questions, I am happy to answer them as always.
Thanks for reading!

4
901
NEBIUS own take on Anthropic Saga, they use the event to position themselves as the Europen Sovereign Cloud, something I mentioned already: x.com/demian_ai/status/20659…
Jun 13

The Fable 5 ban made one thing clear: the intelligence layer now has a fast policy gate that hardware never had.
Hardware bottlenecks (HBM, power, advanced packaging) take years to shit but today it moved in hours.
One export directive on a closed llm = global cutoff
- frontier capability just became contingent on jurisdiction and politics (in a way it wasn’t 48 h earlier)
- clean segmentation at scale is messy.
this exposes a few layers:
1. hosted frontier model itself is no longer a neutral, always-on input. It sits behind a geopolitical choke that can be pulled for “safety” reasons with broad mkt collateral
2. the inference layer underneath becomes strategic. Who serves the model, how it’s routed, quantized, finetuned, guiardrailed, post-trained, and where the data boundary sits now carries real sovereignty weight.
3.Orchestration and redundancy stop being nice to have architecture and start looking like basic operational hygiene once any single frontier llm can be turned down faster than you can figure out alternatives
4. Europe’s demand-side sovereignty moves (Chips Act 2.0 CADA) were already tilting this way. The ban just gave them a crisp, recent case study of the exact risk they’ve been pricing in. It most likely reduces timelines on building parallel capacity and preferring alternatives in critical sectors
On the inference side this opens real space
Specialized providers that can run open weights, customized finetuned and post-trained models at scale with strong sovereignty guarantees just got more relevant.
-> Not because frontier models disappeared, but because the economics and risk profile of depending on them exclusively shifted now
You can keep frontier hosted models for the narrow slice of work where they still deliver decisive quality on long horizon or high-stakes reasoning.
But for volume, regulated workloads, domain-specific agents, or anything where you need predictable updates, data residency, or protection from foreign policy moves, running customized open models on controllable infrastructure becomes the cleaner default.
This is where players like @nebiustf sit in an interesting spot.
Access to sovereign EU compute strong inference stack ability to host and serve fine-tuned or post-trained open models gives a credible path to reduce single jurisdiction dependency without giving up performance on the workloads that matter most.
Some deeper angles worth tracking
- Token economics get more layered.
Frontier APIs stay expensive per token for a reason.
Open fine-tuned models on sovereign or managed inference can be dramatically cheaper at volume once you control the serving stack and quantization. The gap matters more when you’re already hedging policy risk.
- Agent reliability becomes an orchestration problem, not just a model problem. If the frontier tap is sometimes restricted or degraded, you need clean fallback paths and routing logic that preserve output quality where it counts. That creates demand for more sophisticated inference engineering, not just bigger context windows.
- US labs face a subtle structural pressure. The more visible the revocation risk becomes, the stronger the incentive for non-US actors to invest in parallel inference capacity and customized models.
- and over time this can slow winner-take-most dynamics at the frontier even if raw capability btween llms gaps remain.
Power and grid constraints don’t disappear.
What of they just get pulled in slightly more directions as people build hedging capacity?
Parallel sovereign or hybrid inference clusters still compete for the same scarce electrons and networking obv
The real constraint that just got sharper is this designing systems that assume any single centralized frontier hosted model can become less reliable or more expensive to access on policy grounds, not just tech ones.
The ban didn’t invent that assumption but defo made it ignoring it look like incomplete engineering.
1
14
3,543
Interesting debate.
Jun 13

$SIVE is the GameStop of 2026, and Serenity is its Wallstreetbets.
$SIVE is not a strong company. Its technology lacks meaningful differentiation. Execution has been consistently weak. Manufacturing capabilities remain mediocre at best.
The much-touted $700M pipeline is largely meaningless. Garbage in, garbage out. Having reviewed numerous startups and established players over the years, I have seen pipelines that generate little to no revenue time and again. It is straightforward to inflate these figures: one introductory meeting with a junior contact, an entry in Salesforce, and an inflated LTV projection, sufficient to impress investors who chase headline numbers.
More importantly, when companies like $SIVE command such rapid valuation growth, it confirms we are in a substantial bubble. If you wish to gamble, that is your choice. This is a free market. One can always visit a casino and play roulette. Your capital, your risk.
$SOXX sits at all-time highs. With multiple semiconductor cycles behind me, I have observed this pattern repeatedly. Debates about “this time is different” can continue indefinitely. My advice remains straightforward: exercise caution. Avoid investing in weak companies. There are no hidden gems. $POET, $SIVE, $LWLG, $AEVA, and similar names are fundamentally flawed.
1
4
953
4
461
Chances the US Government take a stake in Anthropic jumped from 40% to 51% this weekend

3
8
778
The Fable ban isn't 3D chess. It's losing at checkers.
What unplugging your best model from the world actually does:
— Capital: cuts US labs off from global revenue — the money that funds the next training run. Less foreign money in = slower frontier = smaller lead.
— Market: hands the globe to Chinese open-weights and forces Europe to bankroll Mistral. You wrote your rivals' Series C.
— Talent: the killer. The order locks out foreign nationals — including a lab's own non-citizen staff. Every brilliant non-American researcher now eyes a European or Gulf lab instead. You lose the people who build the thing.
The real 3D chess is the opposite:
— Let the world FUND your AI.
— Let the world's best MINDS build your AI.
— And YES — keep the one-step-ahead model for the US government. But SECRETLY. That's the whole game.
Here's the part the "but that's what the ban did" crowd misses:
The ban kept the edge LOUDLY. It announced to every investor, customer and researcher on earth that the US will unplug frontier AI on a whim. That announcement IS the damage — it makes the world price in sovereign risk before they ever fund you.
The smart move keeps the exact same edge SILENTLY. The world keeps paying and building because it never sees the trapdoor. You get the sovereign advantage AND the global money AND the global talent.
Secret edge = you keep everything.
Announced edge = you keep nothing.
Same card. They just played it face-up.
7
19
1,407
Soft but still, interesting needs more digging to get to the substance though.
Jun 13

We don't know all the details yet, but a few preliminary thoughts 🧵
5
577
Touché
Jun 13

Chinese, European, Canadian, Indian, Russian researchers are no longer incentivized to work in the US if the new American AI policy requires citizenship.
This is an easy win for China right? Another example “do nothing, win”
5
834
The Fable Shutdown: why a 5pm letter reprices the entire AI stack
— Friday 5:21pm ET, a US export-control directive ordered Anthropic to block its top-tier models from any foreign national — inside or outside the US, employees included. Because you can't ring-fence nationality on shared cloud inference, "no foreigners" became "no one." Global kill switch via a single letter.
— The trigger was reportedly a narrow jailbreak. The mechanism is what matters: for the first time, a deployed frontier model was treated as a controlled national-security item — the same legal machinery built for chips and centrifuges, pointed at software.
— The precedent outlives the outage. A frontier model is now a switchable strategic asset, and a restriction aimed at foreigners can force a provider to go dark for everyone. Every business built on a single frontier model just inherited a new failure mode: sovereign, not commercial, and in no 10-K.
This is not a bug report. It's a repricing event.
Not financial advice.
1
10
1,973
Part 2/3 — The "just move abroad" trap
— The instinct: if the US can switch off your global market overnight, build your next frontier lab somewhere neutral. The incentive is now real — US domicile carries a sovereign discount it didn't have a week ago.
— The trap: domicile is the cheapest, most portable input to frontier AI — and the only one you can actually move. The three that matter are bolted down.
- Compute: gigawatt-scale power and 100k accelerators, physically sited. A Geneva address conjures none of it.
- Chips: leading-edge silicon is US-controlled wherever it ships. Acquire it and you're back inside the same perimeter that just took down Fable. The regime follows the chip, not the company.
- Capital talent: still overwhelmingly US-anchored at the frontier.
— Net: the set of places that can host frontier-scale development AND sit outside US leverage is, today, essentially {China}. The Gulf has the power and capital but depends on US chip waivers — neutral in name, tethered in practice. Switzerland and Singapore are genuinely neutral but lack the power and the silicon.
The escape hatch isn't a relocation. It's a decade-long, state-scale industrial project.
Not financial advice.
2
1
1,474
Part 3/3 — Bottom Line
— Bifurcation, not relocation. The likely path isn't US labs decamping to neutral soil — it's the frontier splitting into a US-controlled stack and a Chinese one, with everyone else picking which to build on. That's the fragmentation export controls are designed to force. A true third pole needs power capital indigenous chips at once — a 2030s sovereign project, not a 2026 board decision.
— Bullish the buildout. The sovereign-AI argument just got sharper: don't be hostage to either pole. That's a multi-year tailwind for power, data-center capacity, and the optics/photonics supply chain — regardless of which way any single directive breaks.
— Bearish single-model moats. Any business whose edge assumes uninterrupted access to one top-tier model just learned otherwise. Model redundancy went from nice-to-have to board-level overnight.
— The hedge is the trade. Abstraction layers, multi-model routing, and open-weight fallbacks are the second-order winners — they monetize exactly the risk this letter created, and they don't care where the lab is incorporated.
One letter turned "which model is best" into "what happens when the best one is switched off." Price accordingly.
Not financial advice.
3
1,228